一种低信噪比环境下基于谱熵改进的语音端点检测方法与流程
本发明涉及语音信号处理领域,提出一种基于谱熵改进的语音端点检测方法。
背景技术:
语音端点检测是说话人识别中一个重要的步骤,有效的端点检测是说话人识别处理中首先要解决的问题。传统的端点检测算法如利用过零率、短时能量和自相关参数,在高信噪比环境下可以获得较好的检测效果,但在低信噪比环境下其检测性能却急剧下降。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种提出了准确率更高的基于谱熵改进的端点检测方法。本发明的技术方案如下:
一种低信噪比环境下基于谱熵改进的语音端点检测方法,其包括以下步骤:
步骤1:获取低信噪比环境下的语音信号,根据语音信号的高频信号在语音频谱中所占比重较小,及语音信号具有短时平稳性等特点,通常对其进行预处理,主要包括预加重、加窗分帧;
步骤2:对经过预处理的语音信号进行快速傅里叶变换,语音信号从时域数据变换到频域,变换得到线性频谱;
步骤3:根据语音信号每帧频带的划分,计算各子带频谱和子带能量,最终得到各子带能熵比;
步骤4:设置合适门限值,结合中值滤波处理得到最终的门限值,从而得到语音信号起止点。
进一步的,所述步骤1根据语音信号的高频信号在语音频谱中所占比重较小,及语音信号具有短时平稳性等特点,通常对其进行预加重、加窗分帧的具体步骤如下:
步骤A1:采用一阶高通滤波器即预加重滤波器,其传递函数为H(z)=1-az-1,a取值0.95;z表示在z域下的变换,H(z)表示滤波器传递函数,(H(z)=1-az-1这个函数是一阶高通滤波器,。
步骤A2:对含噪语音信号进行汉明窗加窗分帧处理后得到第i帧语音信号为xi(m),w(n)是窗函数。
进一步的,所述步骤2对经过预处理的语音信号进行快速傅里叶变换,语音信号从时域数据变换到频域,变换得到线性频谱具体包括:
通过FFT变换从时域变换到频域公式为它表示第i帧的第k个频域点的谱幅度值,N是每帧的采样点;
进一步的,所述步骤3根据语音信号每帧频带的划分,计算各子带频谱和子带能量,最终得到各子带能熵比的具体步骤如下:
步骤B1:根据步骤2得到的频谱幅度Xi(k),然后把每帧频带均匀地分成Nb个子带;
步骤B2:计算各个子带的频域能量SE(m,i),各子带谱熵Hb(i),将子带谱熵Hb(i)和子带的频域能量SE(m,i)相结合,对其进行改进结合成一个新的特征参数,即子带能熵比SEH(i),,即子带能熵比
进一步的,所述步骤B2中,计算各个子带的频域能量m表示第i帧的第m个子带能量要想得出各子带谱熵Hb(i),首先求出子带能量的概率b只是为了不与前面的N混淆而定义的Nb,继而子带谱熵为
进一步的,所述步骤4设置合适门限值,结合中值滤波平滑处理得到最终的门限值,从而得到语音信号起止点具体包括步骤:
设x(n)为输入信号,y(n)为中值滤波器的输出,采用一滑动窗,x(n)在n0处的输出值为y(n0),就是滑动窗的中心移动到n0处,y(n0)是取窗内输入样点的中值,,在n0点的左右各取L个样点连同在n0处的样点,共有(2L+1)个样值,把这(2L+1)个样值按大小次序排列,取此序列中的中间值作为平滑器的输出;根据优化后的参数设置合适的门限值T1和T2,当参数SEH(i)高于T2阈值时便肯定是语音,再根据SEH(i)从何时起高于T2来判决语音信号的端点,其中阈值T1、T2取经过平滑处理后的数值。
本发明的优点及有益效果如下:
针对低信噪比环境下的说话人识别率低的问题,本发明在谱熵算法的基础上进行了改进,主要方法是根据子带谱熵和子带能量的各自优缺点进行结合改进对语音的端点检测,方法简便,检测的准确率高。具体思想是:(1)利用子带谱熵在非稳定的噪声环境下的高识别率和子带能量的加性性质,进行结合更好的检测语音的起止点;(2)在设置门限值时进行中值滤波,以更好的优化整个检测过程,去除不稳定因素造成的影响。
附图说明
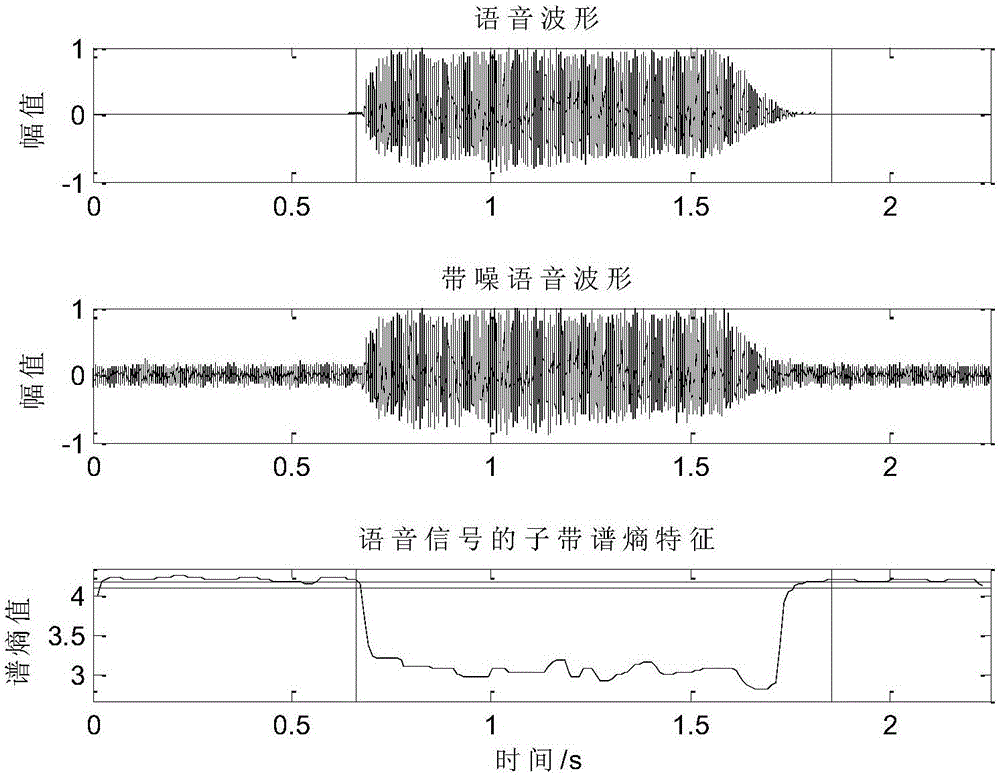
图1是本发明提供优选实施例语音信号的子带谱熵特征图;
图2:语音信号的子带能量特征图;
图3:基于谱熵改进的语音端点检测算法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是,
设含有噪声的语音信号的时域波形是x(n)。
步骤1:采用一阶高通滤波器即预加重滤波器,其传递函数为H(z)=1-az-1,由多次实验得出a取值0.95。然后对含噪语音信号进行加窗分帧处理后得到的语音信号为sw(n)=x(n)×w(n)。
步骤2:经过预处理之后,对每一帧语音信号进行快速傅里叶变换,语音信号从时域数据变换到频域,得到语音线性频谱它表示第i帧的第k个频域点的谱幅度值,N是每帧的采样点;
步骤3:把每帧频带均匀地分成Nb个子带,计算各个子带的频域能量要想得出各子带谱熵Hb(i),首先求出子带能量的概率继而子带谱熵为子带谱熵在低噪声环境下能很好的检测语音的起止点,但是在高噪声环境下就会出现漏音、误判等现象,从而使识别结果不准确。子带能量在非稳定的噪声环境下,很难区分语音和不可预测的背景噪声,而子带谱熵却可以做到,且子带能量有一个很好的加性性质,即语音加噪声的能量要大于噪声的能量,因此可以解决子带谱熵的这种不稳定。为了克服子带谱熵算法在低信噪比环境下检测效果较差的缺陷,在此将子带谱熵和子带能量相结合,对其进行改进结合成一个新的特征参数,即子带能熵比
步骤4:为得到更好的特征参数,有效地去除噪声影响下产生的少量的杂点,进行中值滤波处理。设x(n)为输入信号,y(n)为中值滤波器的输出。采用一滑动窗,x(n)在n0处的输出值为y(n0),就是滑动窗的中心移动到n0处,y(n0)是取窗内输入样点的中值。详细说,在n0点的左右各取L个样点连同在n0处的样点,共有(2L+1)个样值,把这(2L+1)个样值按大小次序排列,取此序列中的中间值作为平滑器的输出。中值平滑的优点是既可以有效地去除少量的野点,又不会破坏数据在两个平滑段之间的阶跃变化。
步骤5:根据优化后的参数设置合适的门限值T1和T2,当参数max SEH(i)高于T2阈值时便肯定进入语音段,当参数max SEH(i)小于T1则为结束点,其中阈值T1、T2取经过平滑处理后的数值。
从附图1、图2中可以看出,在语音中的有话区间能量是向上凸起的,而子带谱熵正相反,在有话区间向下凹陷。这表明,有话区间子带能量的数值大,而子带谱熵数值小;在噪声区间子带能量的数值小,而子带谱熵数值大,所以本发明中把子带能量除以子带谱熵,则可以更突出有话区间的数值,噪声区间的数值变得更小,拉开了有话区间和噪声区间的数值差距,更容易检测出语音的端点。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!