基于LSTM循环神经网络的基频提取模型及训练方法与流程
本发明涉及语音信号处理技术领域,尤其涉及基于LSTM(长短时记忆)循环神经网络的基频提取模型及训练方法。
背景技术:
基频是语音信号的基本参数之一,在语音信号处理中具体着重要的作用,可应用于语音识别、语音压缩编码、语音分离以及语音合成等领域。
虽然,在这个领域已经有很多的研究工作,其中自相关法和倒谱法是两种比较成熟的方法。近年来,许多新方法也运用到了基频提取中,但这些方法大都是从纯信号处理的角度对语音信号的基频进行提取,且其提取精度仍然没有得到很好的解决。主要体现在以下几点:1、现有的基频提取方法从纯信号处理的角度对语音信号的基频进行提取,这个提取过程是逐帧进行的,因而对基频前后帧之间的关联性考虑不足,进而导致最终提取的基频存在较为严重的半倍频现象。2、基频提取算法的鲁棒性又是一个较为棘手的问题,现有的基频提取方法要么在纯净语音中精度较佳,要么在带噪语音中表现较佳,而不能同时兼顾在纯净和带噪语音中的性能要求。因此,为了提高基频提取的精度和鲁棒性,有必要加强对基频建模及其鲁棒性的研究,进一步提高基频提取的精度和鲁棒性。
技术实现要素:
本发明的目的是针对现有技术存在的上述问题,提出一种基 于长短时记忆循环神经网络的基频提取方法、模型及其训练方法,以提高基频提取的精度和鲁棒性。
本发明的基于长短时记忆循环神经网络的基频提取模型的训练方法包括下述步骤:从语音波形信号中抽取声学特征;采用多任务学习的双向长短时记忆循环神经网络,通过所述声学特征,训练生成基于多任务学习的双向长短时记忆循环神经网络的基频提取模型。
进一步地,所述声学特征抽取包括下述步骤:将所述语音波形信号分割成多个语音帧;计算每个语音帧的短时对数功率谱;利用长时平均对数功率谱对所述短时对数功率谱进行归一化处理;通过梳状滤波器对归一化后的所述短时对数功率谱进行谐波结构增强,以得到具有鲁棒性的声学特征。
进一步地,归一化的短时对数功率谱Xt'(q)为: 其中,Xt(q)表示短时对数功率谱,L(q)表示长时平均对数功率谱,为经过21点平滑处理的长时平均对数功率谱。
进一步地,所述梳状滤波器为:
其中,q=logf,f为语音波形信号的频带,系数β通过∫h(q)dq=0确定,系数γ=1.8。
进一步地,对所述梳状滤波器h(q)处理后的特征进行扩帧处理,得到更具有鲁棒性的声学特征向量:
进一步地,用于所述基频提取模型的训练的语音信号的清浊和基频值序列通过至少两种基频提取方法取平均值并人工标注得到。
进一步地,对所述语音信号的轻音帧进行线性插值处理。
本发明的基于长短时记忆循环神经网络的基频提取模型为通过本发明的上述方法训练得到的基于双向长短时记忆循环神经网络的基频提取模型。
本发明的基于长短时记忆循环神经网络的基频提取方法,包括下述步骤:从语音信号中抽取声学特征;基于所述声学特征,通过本发明的基频提取模型提取所述语音信号的基频。
进一步地,在所述基频提取方法中,通过下述步骤抽取所述声学特征:将所述语音信号分割成多个语音帧;计算每个语音帧的短时对数功率谱;对所述短时对数功率谱进行归一化处理;通过梳状滤波器对归一化后的所述短时对数功率谱进行谐波结构增强,以得到具有鲁棒性的声学特征。
本发明中,在基频提取的建模方法上,抛弃了传统的纯信号处理的方法,采用了基于统计学习的方法。具体地采用基于多任务学习的双向长短时记忆循环神经网络来对基频提取进行建模,建立起从抽取的声学特征参数到基频序列和清浊序列之间的映射关系,从而将基频提取和清浊判断统一在同一框架当中。基于多任务学习的双向长短时记忆循环神经网络的基频提取模型能够很好的考虑上下文信息,实现了基频提取的高精度和高鲁棒性。
本发明能够在语音分离、语音合成等领域起到很好的作用。
附图说明
图1是本发明实施例的一种基于双向长短时记忆循环神经网络的基频提取方法的方法流程图;
图2是本发明实施例的从语音波形信号中抽取具有鲁棒性的声学特征的方法流程图;
图3是本发明实施例的训练生成基于多任务学习的双向长短时记忆循环神经网络的基频提取模型的方法流程图;
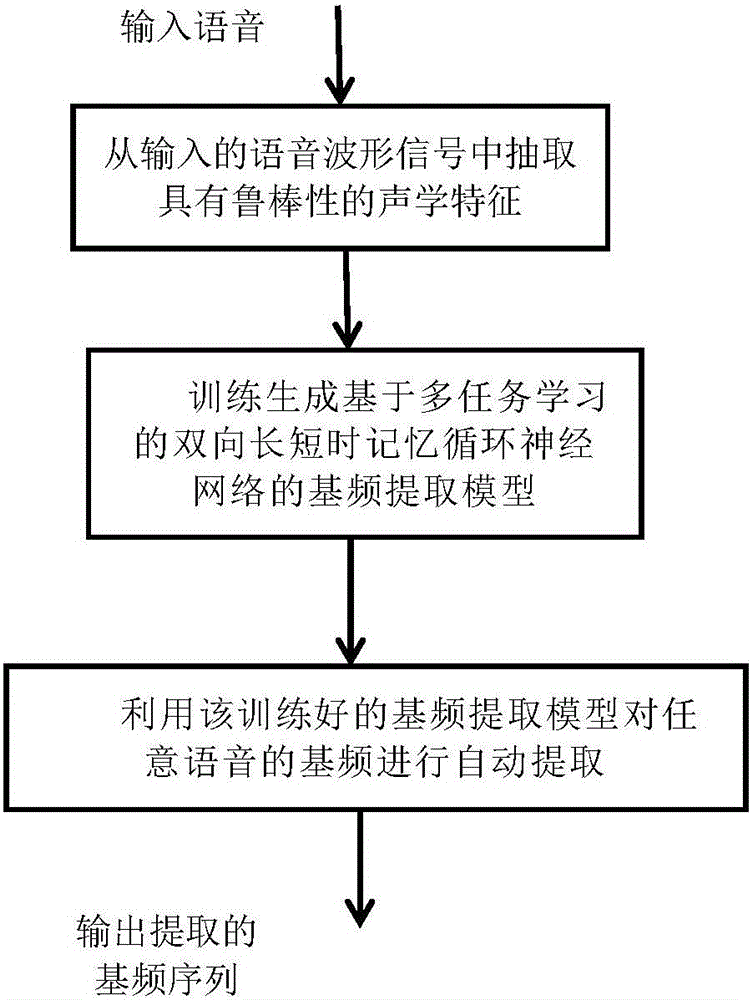
图4是本发明实施例的利用该训练好的基频提取模型对任意语音的基频进行自动提取的方法流程图。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
图1是本发明实施例的一种基于双向长短时记忆循环神经网络的基频提取方法的方法流程图。如图1所示,该方法采用基于多任务学习的双向长短时记忆循环神经网络对语音基频进行建模和提取,包括基频提取模型的训练和基频提取两个阶段。
所述基频提取模型的训练方法包括下述步骤:
步骤101:从用作训练样本的语音波形信号中抽取声学特征;
步骤102:采用多任务学习的双向长短时记忆循环神经网络,通过所述声学特征,训练生成基于多任务学习的双向长短时记忆循环神经网络的基频提取模型。
图2示例性地示出了本发明实施例的从语音波形信号中抽取具有鲁棒性的声学特征的方法流程图。如图2所示,声学特征的抽取包括下述步骤:将原始的语音信号以一定的帧移、帧长分割成若干语音帧,例如,帧移为5ms、帧长为25ms;求得每个语音帧的短时对数功率谱;利用长时平均对数功率谱归一化所述短时对数功率谱;通过梳状滤波器对归一化后的短时对数功率谱进行谐波结构增强,以得到更加具有鲁棒性的声学特征。
具体地,用Xt(f)表示第t帧语音信号在第f频带上的短时功率谱,那么其对应的短时对数功率谱可以表示为Xt(q),这里q=logf。然后用长时平均对数功率谱对该短时对数功率谱进行归一化处理,得到归一化的短时对数功率谱Xt'(q):这里,L(q)表示长时平均对数功率谱,表示经过21点平滑处理的长时平均对数功率谱。由于Xt'(q)考虑了长时特性的影响,能够对语音信号中的噪声信号起到很好的 抑制作用,因而具有一定的鲁棒性。最后,归一化后的短时对数功率谱Xt'(q)再通过一个梳状滤波器h(q)进行处理,以对其谐波结构进行增强。梳状滤波器h(q)如下:
其中,系数β通过∫h(q)dq=0确定,而系数γ=1.8。经过梳状滤波器h(q)处理后的特征可以表示为进一步地,还可以对梳状滤波器h(q)处理后的特征进行扩帧处理,得到更具有鲁棒性的声学特征向量:
本发明实施例中,采用长时平均对数功率谱对原始语音信号中提取得到的短时对数功率谱进行归一化,并用梳状滤波器对归一化后的功率谱进行谐波结构增强,进而得到具有鲁棒性的声学特征。这样的声学特征一方面能够很好地保留原始语音信号中的谐波结构信息,又能够对噪声具有一定的鲁棒性。此外,在具有鲁棒性的声学特征提取中,仅需要一些本领域技术人员熟知的简单的数字信号处理的计算,而不需要传统基于纯信号处理的方法那样复杂的数字信号处理知识,大大降低了系统实现的复杂度和人工参与程度。
图3示例性地示出了本发明实施例的训练生成基于多任务学习的双向长短时记忆循环神经网络的基频提取模型的方法流程图。在图3所示的实施例中,首先进行训练数据准备,包括两部分:一是输入数据准备,另外一个是输出数据准备。输入数据是从训练数据的语音波形信号中抽取的声学特征得到,而其对应的输出数据,即语音信号的清浊和基频值序列通过例如RAPT、YIN、SWIPE、SHR等多种基频提取方法取平均值并人工标注得到的。从而得到训练数据的清浊判断序列和基频序列。此外,还可对语音信号中轻音帧进行线性插值处理,使得到的训练 数据更加适合于基于多任务学习的双向长短时记忆循环神经网络的学习。在基频提取模型建模方面,可将基频提取分为两个任务,任务一是对基频序列值进行预测,任务二是对清浊序列进行预测,并利用基于多任务学习的双向长短时记忆循环神经网络将两个任务统一在同一框架中。在训练过程中,任务一和二的权重也可通过优化得到。
本发明中,在基频提取的建模方法上,抛弃了传统的纯信号处理的方法,采用了基于统计学习的方法。具体地采用基于多任务学习的双向长短时记忆循环神经网络来对基频提取进行建模,建立起从抽取的声学特征参数到基频序列和清浊序列之间的映射关系,从而将基频提取和清浊判断统一在同一框架当中。基于多任务学习的双向长短时记忆循环神经网络的基频提取模型能够很好的考虑上下文信息,实现了基频提取的高精度和高鲁棒性。利用本发明,能够大大提高基频提取的精度和鲁棒性,特别是很好地解决了基频提取中的半倍频现象,能够在语音分离、语音合成等领域起到很好的作用。
图4示例性地示出了本发明实施例利用训练好的本发明的基频提取模型对任意语音信号的基频进行自动提取的方法流程图。如图4所示,对于任意输入语音信号,首先从输入的语音波形信号中抽取声学特征,得到声学特征向量。在此,优选地通过图2所示的方法步骤得到具有鲁棒性的声学特征。将原始的语音信号以一定的帧移、帧长分割成若干语音帧,例如,帧移为5ms、帧长为25ms;求得每个语音帧的短时对数功率谱;归一化所述短时对数功率谱;通过一个梳状滤波器对归一化后的短时对数功率谱进行谐波结构增强,以得到具有鲁棒性的声学特征。在此,也可如上所述地,利用长时平均对数功率谱对已经得到的短时对数功率谱进行归一化处理,得到最终的具有鲁棒性的声学特征向量。
具体地,用Xt(f)表示第t帧语音信号在第f频带上的短时功率谱,那么其对应的短时对数功率谱可以表示为Xt(q),这里q=logf。然 后用长时平均对数功率谱对该短时对数功率谱进行归一化处理,得到归一化的短时对数功率谱X′t(q):这里,L(q)表示长时平均对数功率谱,表示经过21点平滑处理的长时平均对数功率谱。由于X′t(q)考虑了长时特性的影响,能够对语音信号中的噪声信号起到很好的抑制作用,因而具有一定的鲁棒性。最后,归一化后的短时对数功率谱X′t(q)再通过一个梳状滤波器h(q)进行处理,以对其谐波结构进行增强。梳状滤波器h(q)如下:
其中,系数β通过∫h(q)dq=0确定,而系数γ=1.8。经过梳状滤波器h(q)处理后的特征可以表示为进一步地,还可以对梳状滤波器h(q)处理后的特征进行扩帧处理,得到更具有鲁棒性的声学特征向量:
然后,将该具有鲁棒性的声学特征向量作为已训练好的基于多任务学习的双向长短时记忆神经网络基频提取模型的输入,得到对应的语音信号的基频序列和清浊判断序列。然后通过清浊判断序列将基频序列中对应的清音帧置零,以得到最终提取的基频。因而该方法能够对任意输入的语音信号进行基频的自动提取。
基于以上步骤,能够输出任意输入语音信号所对应的基频值,该基频值能够在语音分离、语音合成等领域起到很好的作用。
通过上述实施例可以看出,本发明主要通过特征层面和模型层面对音素时长建模和预测进行了改善。在特征层面,利用长时平均对数功率谱和梳状滤波器对原始的短时对数功率谱进行处理。在模型层面,采用基于多任务学习的双向长短时记忆循环神经网络对基频提取进行序列建模。从而大大提高了基频提取的精度和鲁棒性,特别是很好地解决 了基提取中的半倍频现象,能够在语音分离、语音合成等领域起到很好的作用。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征做出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!