一种基于深度卷积生成对抗网络的语音生成方法与流程
本发明属于语音生成技术领域,尤其涉及一种基于深度卷积生成对抗网络的语音生成方法。
背景技术:
人机交互技术的研究是计算机技术研究领域的重要组成部分。使智能设备具有“说话”的功能,这在真正的“面对面人机交流”中扮演着很重要的角色。借助于语音生成系统,智能设备已经可以清晰、自然地说话,普通用户很容易听懂并接受。语音模仿作为人机语音交流的重要环节,一方面,需要在前期建立大量的语音库,另一方面,需要对大量语音信号的特征提取及训练最终生成接近原始学习内容的自然语音信号。
生成式对抗网络,是一种近年来大热的深度学习模型,其主要就是可以用tensorflow作为学习框架,训练一个生成器g,从随机噪声或者潜在变量中生成逼真的的样本,同时训练一个鉴别器d来鉴别真实数据和生成数据,两者同时训练,利用g和d构成动态“博弈过程”,直到达到一个纳什均衡,生成器生成的数据与真实样本无差别,鉴别器也无法正确的区分生成数据和真实数据。通过基于生成式对抗网络形成的语音信号,从而可以克服目前智能设备在人机对话时只能根据固定的语音库来发声及模式单调缺乏变化,不够自然等缺点。
技术实现要素:
本发明提出了一种基于深度卷积生成对抗网络的语音生成方法,目的在于克服目前智能设备在人机对话时只能根据固定的语音库来发声及模式单调缺乏变化的不足。
本发明实现的具体步骤如下:
步骤1,采集语音信号样本:随机采集m个(m一般取1000)具有相同内容的语音信号,作为语音训练样本和真实语音样本;
步骤2,语音信号的预处理:对步骤1中采集到的m个语音信号进行预处理;
步骤3,将语音数据样本输入深度卷积生成对抗网络:将步骤2中预处理后的m个语音训练样本数据和m个真实语音样本数据输入到深度卷积生成对抗网络;
步骤4,对输入的语音数据进行训练:采用深度卷积生成对抗网络对输入的m个语音训练样本数据和m个真实语音样本数据进行训练;
步骤5,生成接近真实语音内容的语音信号:利用深度卷积对抗生成网络对自回归生成模型得到的波形进行训练,最终生成全新的且接近真实语音样本的语音信号。
步骤1中所述随机采集m个具有相同内容的语音信号,其存储格式为wav格式。
步骤2包括如下步骤:
步骤2-1,对采集的语音信号样本做除杂的处理;
步骤2-2,对采集的语音信号样本进行滤波处理。
步骤2-1包括:利用audacity软件对采集的语音信号样本进行剪辑,过滤掉原始采集的波形中超出软件编辑范围的语音部分以及非语音信号的部分。
步骤2-2包括如下步骤:
步骤2-2-1,计算n时刻的误差信号ε(n):
其中,d(n)表示n时刻主信道输入的带噪语音信号,即为自适应滤波器的期望信号,主信道表示语音输入的通道,w(n)表示n时刻对应的权重系数矢量,x(n)表示在n时刻的语音矢量,h表示共轭转置;
步骤2-2-2,计算在n时刻的相关系数γ(n):
步骤2-2-3,计算n时刻的语音差异矢量u(n):
u(n)=x(n)-γ(n)x(n-1);
步骤2-2-4,通过如下公式计算迭代后每个时刻对应的权重系数矢量:
其中,μ表示自适应常数,δ>0,δ表示实数;
步骤2-2-5,计算最小方差
其中,n0表示主信道输入的语音信号,v表示主信道输入的噪声,y表示自适应滤波器的输出,ε表示误差信号,w表示某特定时刻自适应滤波器的权重矢量,使得方差
步骤2-2-6,将步骤2-2-4中得到的每个时刻的对应的权重系数矢量分别带入步骤2-2-5的公式中,计算最小方差
步骤4包括如下步骤:
步骤4-1,深度卷积生成对抗网络包括两个网络,一个是生成网络g,用于接收一个随机的噪声;一个是判别网络d,用于判别生成的数据是不是真实的;
步骤4-2,计算生成网络的损失函数:
(1-b)log(1-d(g(z))),
其中,z表示生成网络g接收的一个随机的噪声,b表示在真实语音样本数据输入参数c下得到的输出参数,g(z)表示生成网络g的输出,log表示以10为底对的对数操作,d(g(z))表示判别网络d判断生成网络g生成的语音数据为真实的概率;
步骤4-3,计算判别网络的损失函数:
-((1-b)log(1-d(g(z)))+blogd(c)),
其中,c表示真实语音样本数据作为输入参数,d(c)表示判别网络d的输出,即输入真实语音样本数据参数c为真实的概率;
步骤4-4,计算优化函数minmaxv(d,g):
其中,pz(z)表示随机噪声的概率密度,x表示真实语音样本数据,pdata(x)表示参数数据的概率密度;
步骤4-5,当判别网络d无法判定生成网络g所生成的语音数据是否真实时,d(g(z))=0.5,得到训练好的语音信号数据,否则,执行步骤4-6;
步骤4-6,利用随机梯度下降法计算判别网络d的梯度函数和生成网络g的梯度函数:
其中,θd表示在判别网络d方向上的梯度变化量,θg表示在生成网络g方向上的梯度变化量,i∈[1,m],m表示生成网络g接收随机噪声的个数,∈表示属于符号,将训练好的判别网络d和生成网络g带入步骤4-4中。
步骤5包括如下步骤:
步骤5-1,计算自回归生成模型:
其中,h表示步骤4中得到训练好的语音样本数据作为输入的参数,p(s|h)表示最有可行的波形输出向量,s(t)表示在时间点t的输出,t∈[1,t],t表示总时间,∈表示属于符号;
步骤5-2,采用步骤4中深度卷积生成对抗网络,对步骤5-1中生成波形进行学习,再经过自回归生成模型不断的反馈及输出,使得每一步当前输出的结果,只与之前的输出结果相关,当满足步骤4-5中d(g(z))=0.5时,最终生成全新的且接近真实语音样本的语音信号。
有益效果:与现有技术相比本发明具有以下优点:
第一,本发明主要优势在于智能设备不需要借助一个死板的语音库来实现人机交流,而是可以通过机器训练,让智能设备可以自主生成全新的语音,从而使智能设备可以清晰、自然地说话,普通用户也很容易听懂并接受。
第二,本发明是基于深度卷积生成对抗网络的语音生成技术,利用判别网络和生成网络所构成的动态“博弈过程”,最终得到语音训练数据,再利用自回归生成模型,将生成的语音波形转化为音频信号,从而生成接近真实语音内容的自然语音信号。本发明可用于根据样本训练后生成的语音完成人与智能设备之间的自然语音交流。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
图1是本发明流程图。
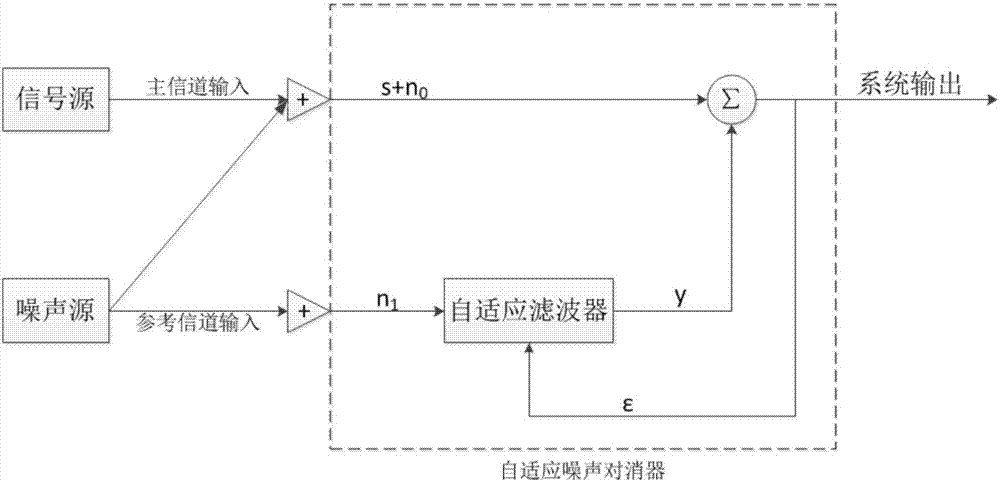
图2是自适应噪声滤波流程图。
图3是实施例生成(“你好”)语音波形图
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
参照图1,对本发明做进一步的详细描述:
步骤1,语音信号样本采集:
随机采集m个具有相同内容的语音信号分别作为语音训练样本和真实语音样本;
步骤2,语音信号的预处理:
(2a)将采集的语音信号做除杂的处理,保留完整的语音信号;
利用audacity软件对语音信号进行剪辑,过滤掉原始采集的波形中超出软件编辑范围的语音部分以及非语音信号的部分;
(2b)对完整的语音信号进行滤波处理,组成语音训练样本库和真实语音样本库,参照图2,具体步骤如下:
第1步,计算n时刻的误差信号ε(n):
其中,d(n)表示n时刻主信道输入的带噪语音信号,即为自适应滤波器的期望信号,主信道表示语音输入的通道,
第2步,计算在n时刻的相关系数γ(n):
第3步,计算n时刻的语音差异矢量u(n):
u(n)=x(n)-γ(n)x(n-1);
第4步,计算迭代后每个时刻的w(n):
其中,μ表示自适应常数,δ>0,δ表示实数,w(n)表示权重系数矢量;
第5步,计算最小方差
其中,n0表示主信道输入的语音信号,v表示主信道输入的噪声,y表示自适应滤波器的输出,ε表示误差信号,w表示某时刻自适应滤波器的权重矢量,使得方差e{ε2}最小;
第6步,将第4步中得到的每个时刻的w(n)分别带入第5步中,计算最小方差
步骤3,将语音数据样本输入深度卷积生成对抗网络;
将步骤2中预处理所得的m个语音训练样本数据和m个真实语音样本数据输入到深度卷积生成对抗网络;
步骤4,对输入的语音数据进行训练;
采用深度卷积生成对抗网络对输入的m个语音训练样本数据和m个真实语音样本数据进行训练,具体步骤如下:
第1步,深度卷积生成对抗网络包括两个网络,一个是生成网络g,用于接收一个随机的噪声;一个是判别网络d,用于判别生成的数据是不是真实的;
第2步,计算生成网络的损失函数:
(1-b)log(1-d(g(z)))
其中,z表示生成网络g接收的一个随机的噪声,b表示第3步中在真实语音样本数据输入参数c下得到的输出参数,g(z)表示生成网络g的输出,log表示以10为底对的对数操作,d(g(z))表示判别网络d判断生成网络g生成的语音数据为真实的概率;
第3步,计算判别网络的损失函数:
-((1-b)log(1-d(g(z)))+blogd(c))
其中,c表示真实语音样本数据作为输入参数,d(c)表示判别网络d的输出,即输入真实语音样本数据参数c为真实的概率;
第4步,计算优化函数minmaxv(d,g):
其中,pz(z)表示随机噪声的概率密度,x表示真实语音样本数据,pdata(x)表示参数数据的概率密度;
第5步,当判别网络d无法判定生成网络g所生成的语音数据是否真实时,d(g(z))=0.5,得到训练好的语音数据,否则,执行第6步;
第6步,利用随机梯度下降法计算d和g网络的梯度函数:
其中,θd表示在判别网络d方向上的梯度变化量,θg表示在生成网络g方向上的梯度变化量,i∈[1,m],m表示生成网络g接收随机噪声的个数,∈表示属于符号,将训练好的d和g带入第4步中;
步骤5,生成接近真实语音内容的语音信号;
利用深度卷积对抗生成网络对自回归生成模型得到的波形进行训练,最终生成全新的且接近真实语音样本的语音信号,具体步骤如下:
第1步,计算自回归生成模型:
其中,h表示步骤4第5步中得到训练好的语音数据作为输入的参数,p(x|h)表示最有可行的波形输出向量,s(t)表示在时间点t的输出,t∈[1,t],t表示总时间,∈表示属于符号;
第2步,采用步骤4中深度卷积生成对抗网络,对第一步中生成的波形进行学习,再经过自回归生成模型不断的反馈及输出,使得每一步当前输出的结果,只与之前的输出结果相关,当满足步骤4第5步中d(g(z))=0.5时,最终生成全新的且接近真实语音样本的语音信号。
实施例
一种基于深度卷积生成对抗网络的语音生成方法,其主要方法的流程图如图1所示,具体包括以下步骤:
(1)采集语音信号样本:随机采集1000个具有相同内容(“你好”)语音信号分别作为语音训练样本和真实语音样本;
(2)语音信号的预处理:对步骤1中采集到的1000个(“你好”)语音信号进行预处理。首先,利用audacity软件对1000个(“你好”)语音信号进行剪辑,过滤掉原始采集的波形中超出软件编辑范围的语音部分以及非语音信号的部分;其次,进行语音滤波处理:通过滤波算法计算n个时刻的误差信号、相关系数、语音差异矢量,由迭代方法计算出每个时刻的权重系数矢量,通过自适应滤波器调整其下一时刻权重矢量求出最小方差,从而进行滤波处理,便可得到滤波后的语音信号;
(3)将语音数据样本输入深度卷积生成对抗网络:将(2)中预处理都所得的1000个(“你好”)语音训练样本数据和真实语音样本数据输入到深度卷积生成对抗网络;
(4)对输入的语音数据进行训练:采用深度卷积生成对抗网络对输入的1000个(“你好”)语音训练样本数据和真实语音样本数据进行训练,在该网络下,分别计算生成网络g和判别网络d损失函数,再利用随机梯度下降算法来训练d和g,最终求得最优函数,得到训练好的(“你好”)语音数据;
(5)生成接近真实语音内容的语音信号:将训练好的(“你好”)语音数据带入自回归生成模型得到波形,再利用深度卷积对抗生成网络对自回归生成模型得到的波形进行训练,得到训练后的语音波形图,如图3所示,最终可生成全新的且接近真实(“你好”)语音样本的语音信号。
本发明提供了一种基于深度卷积生成对抗网络的语音生成方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!