一种速记系统和方法与流程
本发明涉及语音识别技术,具体涉及一种对语音识别结果进行修正使之结合成为一种可行的速记系统和方法。
背景技术:
语音识别就是把人的语音识别成文字的过程,由于人的发音可能不准确,也可能由于录音环境等其他问题,使得语音识别的结果直接拿来作为速记结果可能存在诸多错误。在存在识别错误情况下,对于识别文字使用者如果不再现场或没有记住说话者的语音的情况下,无法识别和修正这些错误的识别。当速记的容量大,说话者的发音不准的情况下,无法快捷获得一个正确的可以使用的速记结果。
技术实现要素:
本发明要解决技术问题在于,提供一种对语音识别结果进行脱机或/和非现场人员的修正的速记系统和方法,通过本发明的系统和方法,让机器速记成为可能的传统速记替代方法。
本发明上述技术问题这样解决,构造一种速记系统,包括:
用于响应网络上请求对收到语音数据进行识别,转化成文字数据的服务器;
用于以声音采集装置采集语音数据并以连网数据传输单元将语音数据传输到所述服务器的采访装置;
用于通信连接所述服务器,并从所述服务器上接收带语音的文字复合数据并对其进行处理的编辑装置,连接有显示器、指点设备和扬声器,其中,所述复合数据包括时间序保存的间有分段标记的文字数据和语音数据,当在显示器上显示编辑文字数据同时显示所述分段标记,当检测到所述分段标记被所述指点设备选中点击时,从复合数据包中读出对应的语音数据并以声音通过扬声器加以重放以便对文字校验处理。
在本发明上述速记系统中,所述服务器按照原始语音录音的时间长度为单位在复合数据上生成标记,所述时间长度大于2秒,小于30秒。
在本发明上述速记系统中,所述服务器根据在语音识别出所产生的文字/字符的长度间隔为间隔在复合数据上生成标记,所述长度间隔为5-30个字符。
在本发明上述速记系统中,所述服务器在原始录音的语音间隔中,在复合数据对应时点上生成标记。
在本发明上述速记系统中,每个采访装置(200)有一个id,每个编辑装置有一个id,在所述服务器上,为每个登记的采访装置记录其id以及对应的编辑装置id。
按照本发明提供的一种速记方法,包括以下步骤:
采集语音信号,传送到服务器;
服务器将接收到语音信号按时间顺序进行识别,产生文字数据;
按照预定方式在产生的语音文字数据上设置标记,同时在对应的文字数据的位置上设置标记,两者之间有唯一对应关系;
从服务器上下载包含带标记的文字数据和语音数据;
将带标记的文字数据显示在显示器上;
当标记被指点操作时,从语音数据上对应标记处重放一段语音从扬声器出来;
根据重放的语音对文字数据进行编辑和修改。
在本发明上述速记方法中,所述预定方式是所述服务器按照原始语音录音的时间长度为单位在复合数据上生成标记,所述时间长度大于2秒,小于30秒。
在本发明上述速记方法中,所述预定方式是所述服务器根据在语音识别出所产生的文字/字符的长度间隔为间隔在复合数据上生成标记,所述长度间隔为5-30个字符。
在本发明上述速记方法中,所述预定方式是所述服务器在原始录音的语音间隔中,在复合数据对应时点上生成标记。
在本发明上述速记方法中,每个采访装置有一个id,每个编辑装置有一个id,在所述服务器上,为每个登记的采访装置记录其id以及对应的编辑装置id。
实施本发明提供的速记系统和方法,克服了现有技术存在的靠人工听力记忆进行及时修正的成本高、效率低的问题,提供了一种快速对转换文本错误进行修正的途径,在语音识别不能保证100%正确前提下,解决了人工校验的效率低、成本高的问题。
附图说明
图1是本发明速记系统第一实施例的结构示意图;
图2是本发明速记系统实施例中第二种终端设备300的结构示意图;
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
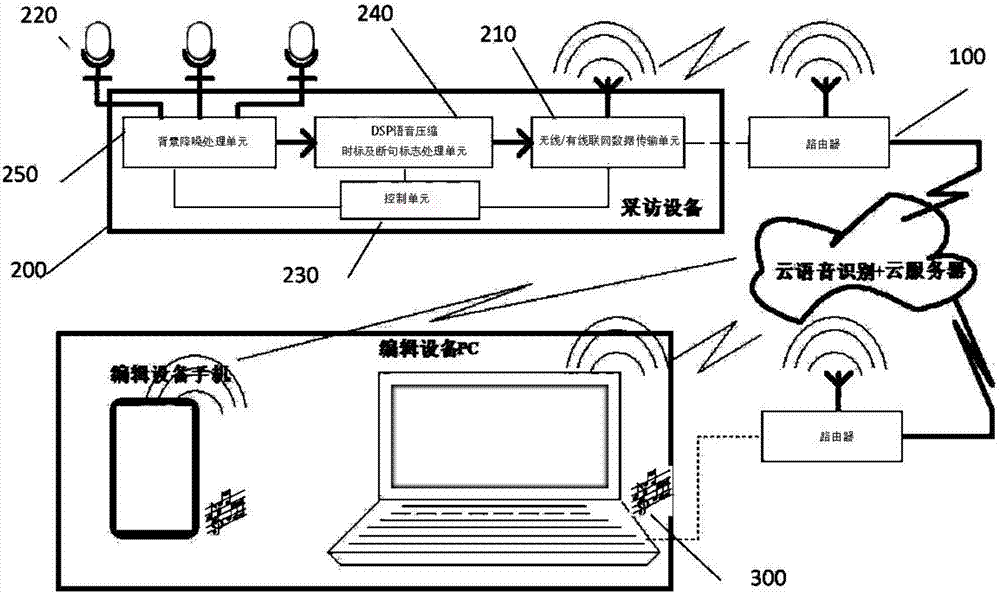
在图1示出本发明系统的实施例中,包括:服务器100,可以是网络上的云端服务器,用于响应网络上来自第一种终端设备200请求,对从第一种终端设备200上收到语音数据进行语音识别,将语音数据提供模式识别转化成文字数据,其中,这个转换过程预先设置好语音数据的语种和文字数据的语种,语种不同时构成了从一种语言的语音数据转换成另一种语音的文字数据的翻译过程。本实施例仅仅考虑同种语言的语音数据转换为文字数据的过程,对于服务器,从第一种终端设备通信输入的是来自所连接第一种终端设备200的语音数据,对接收到的语音数据进行语音识别产生文字/字符数据,在本系统中,服务器100可以将识别结果保存在云端服务器上,响应第二种终端设备300的请求,向第二种终端设备300传输的数据除了包括识别/速记形成的文字数据外,还包括经过标记的原始语音数据。
在如图1的本实施例中,第一种终端设备200可以是一种采访装置,这个采访装置200包括与服务器100通信连接的连网数据传输单元210、用于采集速记语音的话筒220、背景降噪处理单元250、dsp语音压缩时标处理单元240以及连接并控制连网数据传输单元210和话筒220的语音处理单元230,处理单元230内含或外接语音存储单元。换言之,采访装置的处理单元用于将话筒220采集的经过背景降噪和dsp压缩处理250的语音数据由连网数据传输单元210通过网络通信方式将语音数据传输到预置的服务器100。
在本实施例中,第二种终端设备300可以是编辑装置,这个编辑装置300如图2所示,含有或连接有显示器310、指点设备320和扬声器330以及连接控制上述显示器310、指点设备320、扬声器330、连网数据传输单元340的处理单元350,其中,指点设备320和显示器310可以组合成触屏,在便携终端上应用;当应用于非便携设备时,指点/输入设备320可以是鼠标器和键盘,其中,连网数据传输单元340用于无线通信连接访问服务器100。换言之,编辑装置300中的处理单元350用于通过连网数据传输单元340通信连接服务器100,并从所述服务器100上接收带语音的文字复合数据并可对显示器310上显示的文字数据通过指点/输入设备340进行编辑处理,将修正的文字数据加以保存,保存在处理单元350内含或外接才存储单元中。
在本发明上述实施例中,采访装置200用于采集语音数据,连接服务器100后发送语音数据到服务器100,服务器100对采访装置200采集的语言数据进行识别,将识别出的文字数据和语音数据组合成复合数据,等待编辑装置300下载。由于服务器100对来自采访装置200的语音数据的语音识别是由服务器100自动处理的,未经人工校验,其文字数据与现场录下的语音数据或存在差错。在本实施例中,服务器100识别出的文字数据由编辑装置300进行人工校验,具体来讲,编辑装置300通过连网数据传输单元340从服务器100下载复合数据,将复合数据中的文字/字符数据显示在编辑装置300的显示器310上,本发明系统的核心特征在于在显示器310上除了显示文字/字符本身外,还会在显示的成串的文字/字符中分布显示标记符,当用户发现错误的或不通顺的文字时,可以通过指点设备320点击对应位置的标记符,此处,处理单元350调出复合数据中的语音部分,通过扬声器330重放相应的语音,让编辑装置300的校验者根据重放的语音对标记段的文件进行人工修改编辑,实现便利的速记修正和完善,整个文字/字符校验完成,保存即得经过人工校验的速记文字。
在服务器100提供的复合数据中,包括时间序保存的间有分段标记的文字数据和语音数据,当在编辑装置300显示器310上显示编辑文字数据同时显示分段标记,当检测到所述分段标记被所述指点设备如鼠标或触屏上点触选中点击时,从复合数据包中读出对应的语音数据并以声音通过扬声器330加以重放以便对文字校验处理。
在本发明第二实施例中,编辑装置300和采访装置200可以是智能手机上的一个app来实现,此时,话筒220、扬声器330就是智能手机上的话筒和扬声器,采访装置200中的连网数据传输单元210和编辑装置300的连网数据传输单元340可以同为智能手机上的通信模块,例如,本地连网数据传输单元wifi或3g或4g移动通信模块。编辑装置300的显示器310和指点/输入设备320由智能手机上的触屏来实现。换言之,编辑装置300的处理单元350和采访装置200的处理单元230要实现的功能由智能手机中的app来实现。
在本发明另一个实施例中,服务器可以按照原始语音录音的时间长度为单位在复合数据上生成标记,例如,每隔10秒附加一个标记;也可以根据在语音识别出,产生的文字/字符的长度为间隔在复合数据上生成标记,例如,每10个文字/字符附加一个标记;另一种产生标记的方式是在原始录音的语音间隔中,在复合数据上生成标记,例如,人在说话时会有间隔,在一定间隔内没有声音时即可在复合数据上添加标记。
在本发明的另一实施例中,每个采访装置200有一个id,每个编辑装置300有一个id,在服务器100上,为每个登记的采访装置记录其id以及允许下载的对应的编辑装置id。这样,可以保证速记内容的安全性。
在本发明速记方法在实施例中,包括以下步骤:
由一个或多个麦克风220采集语音信号,对采集到语音信号进行背景降噪处理后由连网数据传输单元传送到服务器;
服务器100将接收到语音信号按时间顺序进行语音识别,产生文字数据;
按照预定方式在产生的语音文字数据上设置标记,同时在对应的文字数据的位置上设置标记,两者之间有唯一对应关系,其中时间标记可以由采访装置中的dsp处理单元进行设置;
编辑装置300从服务器100上下载包含带标记的文字数据和语音数据;
将带标记的文字数据显示在显示器310上,此时,可以在文字行走方向上均匀或不均匀地设置诸如扬声器图形的标记,便于指点设备点击;
当看起来逻辑错误或含义错误的文字串时,其最近的一个诸如扬声器的标记被指点设备320(鼠标或触屏)指点操作时,程序会从标记所指错误文字串所对应语音数据上对应标记处重放一段语音,从扬声器330重放出来;
用户听到录音时,可根据重放的语音对文字数据进行编辑和修改,如没有听清楚,可以再次点击,重复听,帮助对文本进行修改。
文本修改正确后,可以进行云同步或/和云分享。
其中,预定方式一种是服务器按照原始语音录音的时间长度为单位在复合数据上生成标记,时间长度大于2秒,小于30秒,也可以在采访设备上生产相应的标记;预定方式另一种也可以是服务器或采访设备根据在语音识别出所产生的文字/字符的长度间隔为间隔在复合数据上生成标记,所述长度间隔为5-30个字符;所述预定方式还可以是所述服务器在原始录音的语音间隔中,在复合数据对应时点上生成标记。
其中,每个采访装置200有一个id,每个编辑装置有一个id,在所述服务器上,为每个登记的采访装置记录其id以及对应的编辑装置id。通过对下载id进行权限管理,保证数据安全。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!