一种基于临界频带的双耳语音分离方法与流程
本发明涉及声源定位和语音分离领域,具体涉及一种基于临界频带的双耳语音分离方法。
背景技术:
语音定位和分离技术是语音信号处理系统的前端,其性能对整个语音信号系统影响非常大。从数字通信时代开始,语音编解码、语音定位、语音分离、语音增强等语音处理技术都得到了迅速的发展,特别在当前的互联网浪潮中,语音助手将语音信号处理推向了一个新的高度。
未来多模态人机交互的发展,人机对话和语音识别离不开语音信号处理的研究和发展,所以语音分离技术作为语音处理系统的前端,直接关系到整个语音系统的性能和效果。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种基于临界频带的双耳语音分离方法,利用人耳听觉系统的分频处理机制,结合人耳的听觉掩蔽效应,模拟人耳的听觉特征,基于临界频带划分,对每一帧信号划分不同的子带获取准确的混合矩阵进行语音分离,改进了现有技术的不足。
技术方案:一种基于临界频带的双耳语音分离方法,其特征在于,该方法包括以下步骤:
1)参数训练阶段:
1.1)使用具有方向性的双耳白噪声信号进行训练,所述双耳白噪声信号为与头相关脉冲响应函数hrir数据与单声道白噪声信号卷积生成的方位已知的双耳信号,声源方位角θ定义为方向矢量在水平面的投影与中垂面的夹角,其范围为[-90°,90°],间隔为5°;
1.2)对已知方位信息的双耳白噪声信号进行预处理,所述预处理过程包括幅度归一化处理、分帧加窗,得到分帧后的单帧双耳声信号;
幅度归一化方法为:
xl=xl/maxvalue
xr=xr/maxvalue
其中xl和xr分别表示左耳声信号和右耳声信号;maxvalue=max(|xl|,|xr|)表示左耳、右耳声信号幅度的最大值。
分帧加窗使用汉明窗对分帧后的语音信号进行加窗处理,加窗后的第τ帧信号可以表示为:
xl(τ,n)=wh(n)xl(τn+n)0≤n<n
xr(τ,n)=wh(n)xr(τn+n)0≤n<n
其中xl(τ,n)、xr(τ,n)分别表示第τ帧的左、右耳声信号;n为一帧采样数据长度。
1.3)对步骤1.2)中得到的单帧双耳语音信号进行互相关函数运算,利用互相关函数计算单帧信号的耳间时间差itd估计值。同一方位所有帧itd估计值的均值作为该方位的itd训练值,记为δ(θ)。
建立方位角θ的itd模型的方法如下:
第τ帧信号的itd值为:
将该θ方位的双耳白噪声信号对应所有帧的itdτ求均值δ(θ),作为θ方位的训练itd参数:
其中framenum表示θ方位的双耳白噪声信号分帧后的总帧数,
这样建立了方位角θ与训练iid参数之间的模型。
1.4)对步骤1.1)中得到的单帧双耳语音信号进行短时傅里叶变换,将其变换到频域,计算左耳声信号和右耳声信号在每个频点幅度谱的比值,即耳间强度差iid矢量,同一方位所有帧iid估计值的均值作为该方位的iid训练值,记为α(θ,ω),ω表示傅里叶变换的频谱。
建立方位角θ的iid模型的方法如下:
第τ帧信号的iid值为:
其中,xl(τ,ω)和xr(τ,ω)分别xl(τ,m)、xr(τ,m)的频域表示,即短时傅里叶变换:
其中x(τ,n)表示第τ帧声信号,分别对左、右耳声信号进行傅里叶变换;ω表示角频率矢量,范围为[0,2π],间隔为2π/512;
将该θ方位的双耳白噪声信号所有帧的iid(τ,ω)求均值α(θ,ω),作为θ方位的训练iid参数:
其中framenum表示θ方位的双耳白噪声信号分帧后的总帧数,
这样建立了方位角θ与训练iid参数之间的模型。
2)基于临界频带和方位信息的双耳混合语音信号分离阶段:
2.1)测试过程中的双耳混合语音信号,包含多个声源,且每个声源对应不同的方位。双耳混合语音信号进行预处理,包括幅度归一化处理、分帧加窗;
2.2)对分帧之后的双耳混合声信号进行傅里叶变换,基于临界频带的频率范围,对频域进行子带划分,得到分帧后的子带信号;
子带划分的的方法如下:
对步骤2.1)所得的多帧信号按帧进行短时傅里叶变换,转换到时频域,获得双耳声信号时频域的分帧信号xl(τ,ω)和xr(τ,ω)。
同时根据临界频带的划分方法,对频点进行进行子带划分:
其中c表示临界频带的个数,ωc_low、ωc_high分别表示第c个临界频带的低频和高频范围。
2.3)根据混合声源信号包含的声源个数和方位信息,以及步骤1.3)和步骤1.4)建立的方位声信号itd、iid参数,在步骤2.2)得到的每帧、每个临界频带内,基于左、右耳声信号的相似度,进行声源的分类;
2.4)对步骤2.3)所得的临界频带分类结果与步骤2.1)中获得的分帧后的时频信号相乘,获得每个声源所对应的时频域信号;
2.5)对步骤2.4)所得的每个声源对应的时频域信号进行傅里叶逆变换,转换为时域信号,进行去加窗,合成为每个声源的分离语音。
有益效果:本发明与现有的基于频点的语音分离技术相比,本发明基于人耳听觉系统的分频处理机制,结合人耳的听觉掩蔽效应,在定位阶段准确获取了声源方位后,对每一帧内不同子带进行分离,将声源定位和临界频带分离技术相结合,在多个说话人分离方面,其分离性能:snr(sourcetonoiseratio)、sdr(sourcetodistortionratio)、sar(sourcestoartifactsratio)、pesq(perceptualevaluationofspeechquality)得到有效提高。
附图说明
图1为本发明声源定位和语音分离的平面空间示意图;
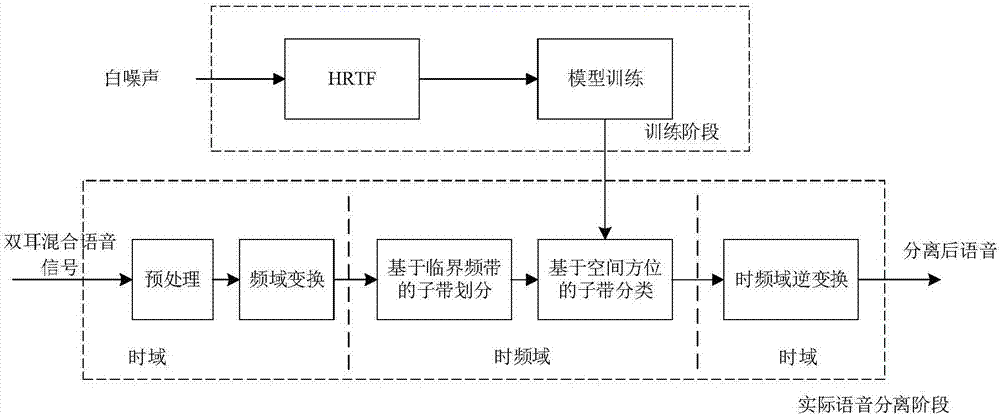
图2为本发明系统框图
具体实施方式
下面结合附图对本发明作更进一步的说明。
本发明先进行数据训练,将各方位耳间时间差itd(interauraltimedifference)和耳间强度差iid(interauralintensitydifference)的均值作为声源方位的定位特征线索,建立方位映射模型;实际声源定位时,根据双耳混合声信号所有帧方位的直方图,估计最终的声源个数及方位。在声源分离阶段,首先对双耳混合声信号进行基于临界频带的子带划分,结合语音定位后的方位信息,在每一个临界频带内对频域信号进行分类,最后通过傅里叶逆变换将时频域上各声源的时频点恢复到时域。
图1为本发明声源定位和语音分离的平面空间示意图,以2个声源为例。2个麦克风位于双耳处,在本发明中,声源空间位置由声源的方位角θ表示,方向角-180°≤θ≤180°为方向矢量在水平面的投影与中垂面的夹角。水平面上,θ=0°表示正前方,沿顺时针方向θ=90°、180°和-90°分别表示正右方、正后方、正左方。图1以2个声源(本实施例的声源为说话人发出的声音)为例,其方向角分别为-30°、30°。
图2为本发明的系统框图,本发明方法包括模型训练、时频变换、临界频带划分和子带的声源分类,下面结合附图对本发明技术方案的具体实施方式进行详细说明:
步骤1)数据训练:
1.1)图2给出整体系统框图中,在训练阶段,与头相关传递函数hrtf(headrelatedtransferfunction),对应时域的与头相关冲激响应函数hrir(headrelatedimpulseresponse)用于生成特定方位的双耳声信号。本发明使用麻省理工学院媒体实验室测量的hrir数据,将θ=-90°~90°(间隔5°)的hrir数据与白噪声卷积生成对应方位的双耳声信号。
1.2)对给定方位θ的双耳白噪声信号进行预处理,本方法的预处理包括:幅度归一化、分帧及加窗。
幅度归一化方法为:
xl=xl/maxvalue
xr=xr/maxvalue
其中xl和xr分别表示左耳声信号和右耳声信号;maxvalue=max(|xl|,|xr|)表示左耳、右耳声信号幅度的最大值。
本实施例使用汉明窗对分帧后的语音信号进行加窗处理,加窗后的第τ帧信号可以表示为:
xl(τ,n)=wh(n)xl(τn+n)0≤n<n
xr(τ,n)=wh(n)xr(τn+n)0≤n<n
其中xl(τ,n)、xr(τ,n)分别表示第τ帧的左、右耳声信号;n为一帧采样数据长度,本实施例中,语音信号采样率为16khz,帧长为32ms,帧移为16ms,这样n=512;wh(n)为汉明窗窗函数,表达式为:
1.3)建立方位角θ的itd模型。
第τ帧信号的itd值为:
将该θ方位的双耳白噪声信号对应所有帧的itdτ求均值δ(θ),作为θ方位的训练itd参数:
其中framenum表示θ方位的双耳白噪声信号分帧后的总帧数。
这样建立了方位角θ与训练iid参数之间的模型。
1.4)建立方位角θ的iid模型:
第τ帧信号的iid值为:
其中,xl(τ,ω)和xr(τ,ω)分别xl(τ,m)、xr(τ,m)的频域表示,即短时傅里叶变换:
其中x(τ,n)表示第τ帧声信号,分别对左、右耳声信号进行傅里叶变换;ω表示角频率矢量,范围为[0,2π],间隔为2π/512。
将该θ方位的双耳白噪声信号所有帧的iid(τ,ω)求均值α(θ,ω),作为θ方位的训练iid参数:
其中framenum表示θ方位的双耳白噪声信号分帧后的总帧数。
这样建立了方位角θ与训练iid参数之间的模型。
步骤2)基于临界频带和方位信息的双耳混合声信号分离阶段。
2.1)对应图1中的预处理模块,对包含方位不同的多个声源的双耳混合声信号进行与上述步骤1.2)中相同的预处理,包括幅度归一化、分帧和加窗,采取帧长为32ms,帧移为16ms,加汉明窗。
2.2)对应图1中的频域变换,对步骤2.1)所得的多帧信号按帧进行短时傅里叶变换,转换到时频域,获得双耳声信号时频域的分帧信号xl(τ,ω)和xr(τ,ω)。
同时根据临界频带的划分方法,对频点进行子带划分:
其中c表示临界频带的个数,ωc_low、ωc_high分别表示第c个临界频带的低频和高频范围。
临界频带的划分范围,即每个临界频带的低频、高频和带宽如下表所示:
2.3)对应图1中的基于空间方位的子带分类。这里我们假设已知双耳混合语音信号中包含的声源个数和对应的空间方位角。目前有不少算法通过双耳声信号对声源的个数和方位信息进行估计,这里不对声源定位进行描述,也同样不对声源定位的算法进行限制。只讨论在声源定位之后,如何根据不同声源的空间方位信息进行分离。
根据人耳听觉系统的掩蔽效应,通常在某一帧的某个临界频带内,只有一个声源信号占主导,这样在基于空间方位的语音分离,利用耳间时间差iid与耳间强度差itd为空间线索,通过两个声道间的最大相似度计算掩膜函数,在每一临界频带内进行声源的分类,这里我们假设双耳混合声信号中包含l个声源,每个声源的方位角θl(1≤l≤l):
其中xl(τ,ω)、xr(τ,ω)分别为第τ帧的左、右耳频域信号,ωc表示第c个临界频带的频谱范围;θl为第l个声源对应的方位角;α(θl,ω)为第l个声源对应空间方位θl在ω频点上的iid参数,δ(θl)为第l个声源对应方位的itd参数。
j(τ,c)实际上是在每一个临界频带内利用方位信息对声源进行了分类。
随即,对每个声源所对应的临界频带进行二进制掩码标记:
这样ml(τ,ω)表示第l个声源在第c个临界频带内的二进制掩膜。
2.4)根据二进制掩码,对每帧、每个频点的双耳声信号进行分类,得到第l个声源对应的时频点信号:
其中
这里我们用左耳声信号和掩码相乘,得到各个声源的时频数据,实际上也可以利用右耳声信号得到各个声源的时频数据。
2.5)对应图1中的时频域逆变换,对分离后的第l个声源的频域信号进行逆短时傅里叶变换,得到声源l的第τ帧时域信号
转换为时域信号后,进行去加窗,去加窗后的第τ帧信号可以表示为:
其中
将去加窗后的各帧语音进行重叠相加,从而得到混合声源信号分离后的第l个声源信号sl,从而实现不同方位声源信号的分离。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!