对话策略优化的冷启动系统和方法与流程
本发明涉及的是一种智能人机对话领域的技术,具体是一种对话策略优化的冷启动系统和方法。
背景技术:
智能人机对话系统是能与用户进行对话交互的智能系统。其中,对话策略是整个系统中决定如何回复用户的模块。对话策略的最早设计方法是设计者根据不同的用户输入设计不同的逻辑规则。这种方法的缺点是对话策略不能随着用户的反馈不断进行优化,增强对用户和环境的自适应能力。
近年来,深度强化学习方法逐渐被用于对话策略的优化中。在此方法中,对话策略用一个神经网络来表示,并利用奖励信号(reward)进行强化训练,此方法的好处是随着用户的不断使用,系统的性能(例如对话成功率)会不断提高。但是也有两大缺点:一是,在训练的初期,系统的性能很差,会导致用户流失;二是,如果要使系统达到一定的性能,需要大量的对话数据进行训练。
技术实现要素:
本发明针对现有技术在训练初期,系统性能很差,且需要大量的对话数据进行训练以提高性能的缺陷,提出一种对话策略优化的冷启动系统和方法,能够显著提高对话策略在强化学习在线训练初期的性能;提高对话策略的学习速度,即减少其达到一定性能所用的对话数量。
本发明是通过以下技术方案实现的:
本发明涉及一种对话策略优化的冷启动系统,包括:用于接收用户输入的用户输入模块、用于解析当前用户输入的语义并根据对话上下文进行对话状态跟踪,即理解用户的意图的对话状态跟踪模块、根据设计好的基于规则的对话策略决策出在当前状态下的回复动作的教师决策模块、根据策略网络决策出当前状态的回复动作并估计当前决策的确定度的学生决策模块、从教师决策模块和学生决策模块产生的回复动作中随机选择一个最终的回复动作的动作选择模块、将最终的回复动作转换成更自然的表达并展现给用户的输出模块、将对话经验(transition)存储到经验池中并采样固定数量的经验,根据深度q网络(dqn)算法进行网络参数更新的策略训练模块以及在对话的每一个轮回计算对话的奖励回报(reward)并输出至策略训练模块的奖励函数模块。
所述的用户输入包括但不限于语音、图像或者文本。
所述的策略网络采用但不限于q-网络。
所述的随机选择中,选择学生决策模块产生的回复动作的确定度由q-网络dropout(在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃)带来的不确定性定义,具体为:q-网络的每一个隐层后设有一dropout层,在决策时,由于dropout层每次将隐层节点置0的位置不同,对于同一对话状态输入,网络的输出也会不同,重复输入n次,得到n个动作,其中占比最大的动作为最终的决策动作astu,同时对应的占比即为决策的确定度ct。
所述在第e个对话时,动作选择模块的具体选择步骤如下:
1)根据如下公式计算当前对话前连续w个对话决策的平均确定度
2)根据单调递增函数ptea(δce)计算选择教师决策模块产生的回复动作atea作为最终决策动作的概率ptea,其中:δce=max(0,cth-ce),cth是确定度界限,例如0.7;
3)依概率ptea进行伯努利采样,如果为1,则选择教师决策模块产生的回复动作atea,否则选择学生决策模块产生的回复动作astu;
4)当连续k个对话下平均确定度ce都大于cth,则从此时开始最终的决策动作at都选择astu,此时刻即为干预结束点。
所述的单调递增函数可以但不限于
所述的奖励回报,通过以下方式得到:
①在每一个对话轮回产生一个负数奖励;当对话结束时,如果输出模块回复的内容满足用户要求,则视为成功完成了用户任务,则产生一个正奖励;
②在干预结束点之前,在每一轮对话,如果at与atea不同,则产生一个负数奖励,否则产生一个正奖励。
所述的输出模块进行的更自然的表达,其包括但不限于:声音、图像或文本。
所述的对话经验(transition)包括:当前轮对话状态st、对话动作at、下一个对话状态st+1及当前轮奖励rt。
所述的经验池包括:教师经验池和学生经验池,当动作选择模块取自教师决策模块产生的回复动作atea,则当前的对话经验放入教师经验池中,否则放入学生经验池中。
所述的网络参数更新是指:首先依概率ptea进行伯努利采样,如果为1,则选择教师经验池,否则选择学生经验池,然后从选择的经验池中采样固定数量的经验用于q-网络参数的更新。
技术效果
与现有技术相比,本发明将基于逻辑规则的对话策略与基于强化学习的对话策略结合起来,提高了整个对话策略在训练初期的性能,避免了传统的基于强化学习的对话策略在训练初期因性能较差而导致用户流失;同时,随着用户的不断使用,即训练数据的增多,本发明系统的性能能够比基于传统方法的系统性能更快地收敛到较高水平。
附图说明
图1为本发明系统示意图;
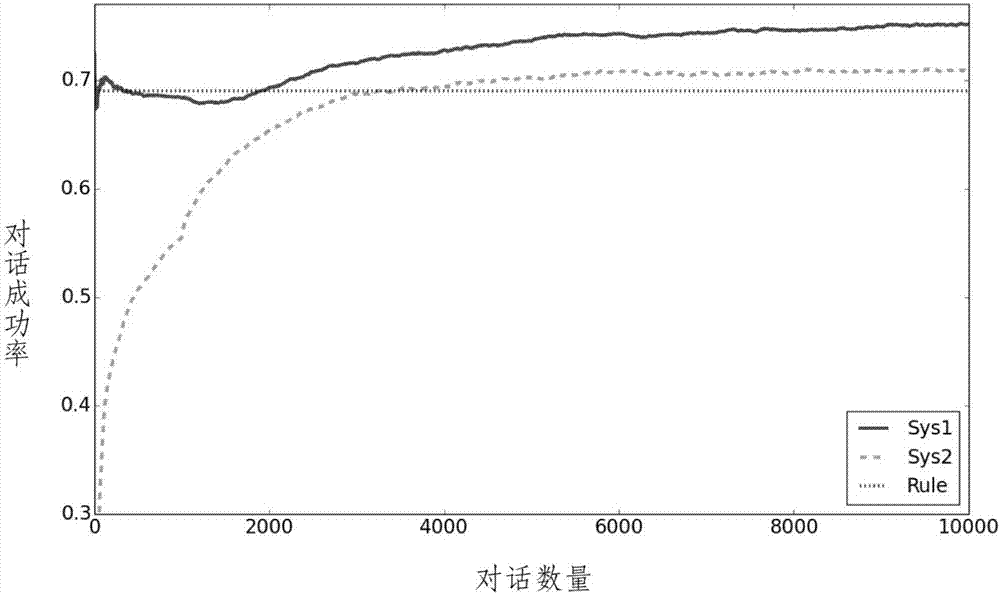
图2为实施例效果示意图。
具体实施方式
本实施例涉及对话策略优化的冷启动系统,包括:
用户输入模块101:用于接收用户的输入,用户的输入可以是语音、图像或者文本。
对话状态跟踪模块102:用于解析当前用户输入的语义,同时根据对话上下文进行对话状态跟踪,即理解用户的意图。
教师决策模块103:根据设计好的基于规则的对话策略决策出在当前状态st下的回复动作atea。
学生决策模块104:根据策略网络(q-网络)决策出当前状态st的回复动作astu,同时估计当前决策的确定度。
动作选择模块105:根据一个随机函数从上述两个决策模块产生的回复动作中选择一个最终的回复动作at。
输出模块106:将最终的回复动作转换成更自然的表达并展现给用户。
奖励函数模块107:在对话的每一个轮回计算对话的奖励回报(reward),并提供给策略训练模块。
策略训练模块108:存储对话经验(transition)到经验池中,同时采样固定数量的经验并根据深度q-网络(dqn)算法进行网络参数更新。
本实施例涉及上述系统的对话策略优化的冷启动实现方法,包括以下步骤:
步骤1)接收用户的输入信息ot,包括输入的文本、语音或图像信息;
步骤2)根据当前的输入信息ot以及上一轮对话状态st-1,将对话状态更新到st;
步骤3)根据设计好的基于规则的对话策略决策出在当前状态st下的回复动作atea;
步骤4)根据策略网络(q-网络)决策出当前状态st的备选回复动作astu,同时估计当前决策的确定度ct。
子步骤4-1)具体地,q-网络中每一个隐层后设有一dropout层,dropout的丢失隐层比例可以设为0.2;在决策时,由于dropout层每次将隐层中节点置为0的位置不同,对于同一对话状态输入st,网络的输出决策结果ai也会不同,重复输入n次,得到n个候选动作{a1,…,an},其中占比最大的动作为最终的决策动作ai,同时对应的占比即为决策的确定度ct。
步骤5)根据一个随机函数从上述两个决策模块产生的回复动作中选择一个最终的回复动作at:
子步骤5-1)根据如下公式计算当前对话前连续w个对话决策的平均确定度
子步骤5-2)根据单调递增函数ptea(δce)计算选择回复动作atea作为最终决策动作的概率ptea,其中:δce=max(0,cth-ce),cth是确定度界限,例如0.7;
具体地,所述的单调递增函数可以是
子步骤5-3)依概率ptea进行伯努利采样,如果为1,则选择回复动作atea,否则选择备选回复动作astu;
子步骤5-4)当连续k个对话下平均确定度ce都大于cth,则从此时开始最终的决策动作at都选择astu,此时刻即为干预结束点。
步骤6)将最终的回复动作at转换成更自然的表达并展现给用户。
步骤7)奖励函数模块计算当前轮的奖励(reward)rt:
子步骤7-1)产生一个负数奖励,例如-0.05;
子步骤7-2)如果当前对话为最后一个对话轮回,且输出模块回复的内容满足用户要求,即系统成功完成了用户任务,则产生一个正奖励,例如1.0,否则奖励为0.0;
子步骤7-3)在干预结束点之前,在每一轮对话,如果at与atea不同,则产生一个负数奖励,例如-0.05,否则产生一个正奖励,例如0.05;
子步骤7-4)将上述三种奖励加起来作为当前轮的奖励rt。
步骤8)强化学习训练模块存储对话经验(transition)到经验池中,同时采样固定数量的经验并根据深度q-网络(dqn)算法进行网络参数更新:
子步骤8-1)按回复动作或备选回复动作分类存储对话经验(st-1,at-1,st,rt-1);;
子步骤8-2)首先依概率ptea行伯努利采样,当采样值为1,则选择回复动作,否则选择备选回复动作,然后从选择的回复动作中采样固定数量的经验用于q-网络参数的更新。
步骤9)回到步骤1),直到整个对话结束。
按上述具体实施方式进行实验,结果如图2所示。横轴表示强化学习训练所用的对话数量,纵轴表示对话成功率。sys1代表我们的系统,sys2代表传统的基于深度强化学习的系统,rule代表完全基于逻辑规则的系统。结果表明,sys1在训练数据较少时,能够拥有接近rule系统的性能,而sys2在训练数据较少时,对话成功率很低;同时随着训练数据的增多,sys1的性能能够逐渐超过rule的性能,且相较于sys2,能够更块地收敛到较高的成功率。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 还没有人留言评论。精彩留言会获得点赞!