一种基于互联网的真实人声的采集系统的制作方法
本发明涉及语音采集技术领域,具体涉及一种基于互联网的真实人声的采集系统。
背景技术:
基于深度神经网络的语音识别技术在近年得到了快速的发展并得到了大量应用。这种技术需要将事先标记好的语音数据(即具备文字-语音对照的数据)输入到一个神经网络当中,对神经网络进行训练。标记好的语音数据的数量和质量对于语音识别的效果至关重要,标记好的数据越多,训练的效果越好。标记好的语音数据质量越高,越接近真实的人类语音,训练出来的深度神经网络对真实人类语音的识别效果就越好。
目前,深度学习方面使用的标记语音数据集的主要获取来源包括以下几个方面:
a.专门招募人员朗读文本材料并进行录音,以采集人声样本;
b.利用公开领域的音频文件以获得人声样本;
c.开发语音输入法,采集用户的人声样本,如讯飞语音输入法;
d.提供操作系统的语音助手,通过客户与其互动,采集人声样本,如微软公司win10桌面版的cortana和苹果公司的siri;
e.利用语音合成技术按照文本材料直接合成。
上述的人声采集技术存在如下问题:
1.招募人朗读文本材料的方式,采集到的音频文件必须通过后期分割成10秒左右的小文件,并且需要分割文本材料与之对应,这些都需要大量的后期处理和校对工作。而且采集的范围小,每次能采集到的样本数量有限;
2.利用公开领域的音频文件的方式,通常这些音频文件都缺乏相对应的文本材料,文件大小通常也过大,需要大量的后期文字听写,分割处理和校对工作;
3.用语音输入法采集的方式,采集到的人声样本并不能保证带有准确的文字与之对应。同时,采集到的人声样本长短不齐,也有大量无用的样本混杂期间,样本质量无法保证,需要大量的后期处理和校对工作;
4.用语音助手的方式,缺点与用语音输入法采集的方式相同;
5.用语音合成技术的方式,合成的语音与真实人声有较大区别,不利于深度神经网络对真实语音的学习。
技术实现要素:
本申请提供一种基于互联网的真实人声的采集系统,包括服务器和客户端;
服务器和客户端网络连接;
服务器执行:
将预存的文本材料分割为其长度适用于深度神经网络训练的语句文本;
向获取客户端访问权限的非特定的用户发送待朗读的语句文本;
接收与语句文本对应的语音数据;
客户端执行:
向服务器发起语句文本的朗读请求和接收待朗读的语句文本;
采集用户朗读语句文本的语音数据,并将采集到的语音数据传送至服务器。
一种实施例中,还包括语音评价模块,语音评价模块执行对所述语音数据进行评价。
一种实施例中,语音评价模块执行语音数据进行评价,具体为:根据噪音水平及用户是否按照语句文本进行朗读计算所述语音数据的评分。
一种实施例中,语音评价模块集成于服务器,服务器还执行:对语音数据进行评价,将通过评价的语音数据进行有效标记并将其保存至与其相对应的语句文本的存储体中,否则,将未通过评价的语音数据进行无效标记。
一种实施例中,语音评价模块集成于客户端,客户端还执行:对语音数据进行评价,将通过评价的语音数据进行有效标记并将其传送至服务器,否则,将未通过评价的语音数据进行无效标记。
一种实施例中,还包括第三方检测平台,第三方检测平台分别与客户端和服务器网络连接;
客户端执行:
将采集到的语音数据传送至第三方检测平台;
第三方检测平台内置有语音评价模块,第三方检测平台执行:
对语音数据进行评价,将通过评价的语音数据进行有效标记并将其传输至服务器,否则,将未通过评价的语音数据进行无效标记。
一种实施例中,服务器集成有抽查模块,服务器还执行:对保存的有效的语音数据进行随机人工抽查。
一种实施例中,客户端执行的程序至少依附于其中之一:智能设备、个人电脑和浏览器网页。
依据上述实施例的采集系统,由于将预存的文本材料分割为其长度适用于深度神经网络训练的语句文本,根据用户的朗读请求向其发送待朗读的语句文本,对用户朗读语句文本的语音进行采集,本例的真实人声的采集方式与现有的语音采集方式相比:本例不需要对采集的音频文件进行后期分割、不需要大量的后期处理和校对工作,而且,采集的音频文件与朗读的文本材料相对应;另外,通过对采集的语音数据进行评价,将评价通过的语音数据进行存储和有效的标记,进一步,实现了真实人声的高质量采集。
附图说明
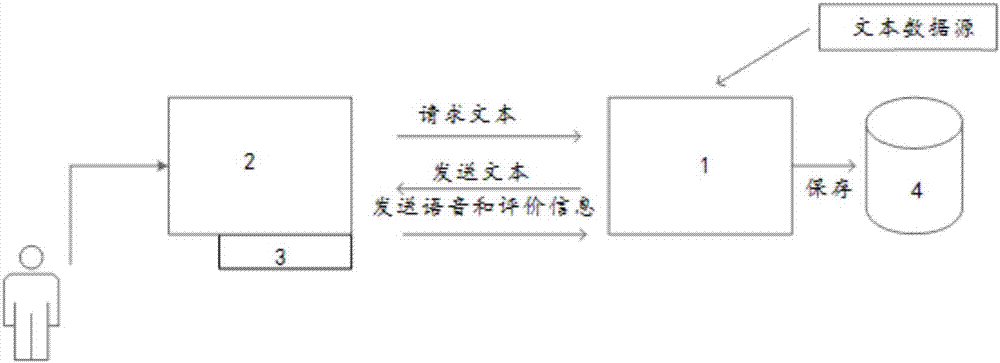
图1为实施例一的采集系统工作示意图;
图2为实施例二的采集系统工作示意图;
图3为实施例三的采集系统工作示意图。
具体实施方式
下面通过具体实施方式结合附图对本发明作进一步详细说明。
在本发明实施例中,为解决目前用于训练深度神经网络的带标记的真实人声语音数据样本较少,语音数据样本获取成本较高的问题,本例提供一种基于互联网的真实人声的采集系统,其采集的语音数据可以在简单处理后用于深度学习神经网络的训练、验证和测试。
实施例一:
本例的基于互联网的真实人声的采集系统包括服务器1和客户端2,其工作示意图如图1所示,服务器1和客户端2基于互联网建立网络连接,客户端2对非特定用户朗读的语句文本进行录音,并将录音发送至服务器1,以实现真实人声的采集,其中,非特定用户指的是任何一个用户,即,任何一个用户通过注册,均可以向服务器1请求朗读语句文本,由此,扩展了语音采样的范围。
具体的,为了避免对采集的音频文件进行分割处理,更为了方便采集的音频文件适用于深度神经网络语音识别的样本,服务器1将预存的大量的文本材料分割为其长度适用于深度神经网络训练的语句文本,如,语句文本的长度大约等于10秒左右的朗读时间。
当非特定用户通过客户端2注册一账号后,即可成为朗读语句文本的特定用户,如,当非特定用户根据客户端2的注册提示,逐步同意客户端2应用使用条款后,该非特定用户就能获取客户端2的访问权限,然后,用户就能通过客户端2向服务器1发起朗读语句文本的请求,客户端2接收待朗读的语句文本,用户朗读获取的语句文本,此时,客户端2附带的录音硬件设备被触发,对用户朗读的真实人声进行录音,待用户朗读完毕后,客户端2将采集到的语音数据传送至服务器1,服务器1接收并存储该语音数据,从而使服务器1能够采集到和文字对应的语音信息。
为了保证获取语音信息的有效性,避免获得无用的样本,针对每一个采集到的语音数据进行自动检测并给出评价分数,只有评价分数超过预设数值的语音数据才会被存储到服务器1。本例还包括语音评价模块3,语音评价模块3对语音数据进行评价,根据评价分数判断采集到的语音数据是否符合要求,其中,评价语音数据的要素包括噪音水平和用户是否按照语句文本进行朗读,因此,语音评价模块3根据噪音水平及用户是否按照语句文本进行朗读计算语音数据的评分。
其中,针对用户是否按照语句文本进行朗读,具体的评价方式是,语音评价模块3将采用该语句文本对应的参考语音,该参考语音可以是已有的采集的标记语音,也可以是合成人工语音,语音评价模块3比较参考语音和采集的语音的相似度,根据相似度进行评分。
比较参考语音和采集的语音的相似度的实现方式是:先使用动态时间规整算法找到采集的语间与参考语间的特征的最佳对齐,然后使用levenshtein距离算法来计算这两个序列之间的距离,通过距离得到两个语间之间的相似度,根据该相似度进行评分。
本例中,语音评价模块3集成于服务器1,服务器1接收到语句文本对应的语音数据后,服务器1通过语音评价模块3对语音数据进行评价,服务器1将通过评价的语音数据进行有效标记并将其保存至与其相对应的语句文本的存储体4中,否则,将未通过评价的语音数据进行无效标记,服务器1可以将无效标记的语音数据保存到服务器1中的存储体4中,也可以将其丢弃。
进一步,为了保证上传的有效标记语音数据的质量,服务器1集成有抽查模块,服务器1通过抽查模块对已保存在存储体4中的有效标记的语音数据进行随机人工抽查,以获取相关信息用于调整语音数据的评价参数,并能够剔除自动检测所未能发现的无效样本,进一步提高真实人声样本集的质量。
需要说明的是,为了扩展真实人声样本集的采样范围,本例的客户端2执行的程序的存在形态可以是手机、平板电脑、个人电脑上的独立应用程序,也可以是集成在其他应用程序里面的专用功能模块程序,也可以是浏览器网页应用程序,也可以是定制的专用硬件的执行程序,即,客户端执行的程序至少依附于其中之一:智能设备、个人电脑和浏览器网页,其中,智能设备包括但不限于:智能手机、平板电脑、智能手表、游戏机、专用的录音器、智能家居控制器等。相应的,服务器1执行的程序可以部署在实体服务器上,也可以部署在云端,即服务器1可以是云端服务器,也可以是一般的服务器。
实施例二:
基于实施例一,本例与实施例一不同的是:本例将语音评价模块3集成于客户端2,其工作示意图如图2所示,客户端2采集用户朗读语句文本的语音数据后,还要通过语音评价模块3对语音数据进行评价,将通过评价的语音数据进行有效标记并将其传送至服务器1,服务器1将通过评价的语音数据进行有效标记并将其保存至与其相对应的语句文本的存储体4中,否则,将未通过评价的语音数据进行无效标记,客户端2可以将未通过评价的语音数据直接丢弃,也可以将其传输并保存到服务器1中的存储体4内。
实施例三:
基于实施例一,本例与实施例一不同的是,本例还包括第三方检测平台5,第三方检测平台5分别与客户端2和服务器1网络连接,其工作示意图如图3所示,客户端2将采集到的语音数据直接传送至第三方检测平台5;第三方检测平台5内置有语音评价模块3,由第三方检测平台5通过语音评价模块3对语音数据进行评价,将通过评价的语音数据进行有效标记并将其传输至服务器1,服务器1将通过评价的语音数据进行有效标记并将其保存至与其相对应的语句文本的存储体4中,否则,将未通过评价的语音数据进行无效标记,第三方检测平台5可以将未通过评价的语音数据直接丢弃,也可以将其传输并保存到服务器1中的存储体4中。
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
- 还没有人留言评论。精彩留言会获得点赞!