基于模式匹配的哭声识别方法及智能看护系统与流程
本发明涉及一种基于模式匹配的哭声识别方法及智能看护系统,属于智能家居领域。
背景技术:
随着物联网技术的高速发展,智能家居已经越来越多的出现在人们的生活中,使人们的生活起居越来越便捷,大大提升了用户的体验。
随着工作压力越来越大,年轻父母在外忙碌的时间越来越多,对自己孩子的照顾主要依赖雇佣保姆或交给家中老人照看,保姆的人力成本太高,而老人因年纪原因可能出现婴儿哭闹没有被及时护理等现象。因此,赋予智能家居以婴儿看护的功能,将极大解决大多工作族的烦恼。
但当今市场上,具有婴儿看护功能的智能家居设备还较为少见,大多婴儿看护产品仅仅停留在远程视频监控功能上,若没有一直监视画面,亦不能及时发现婴儿的哭闹,看护效果并不理想。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于模式匹配的哭声识别方法及智能看护系统。该方法首先,建立婴儿哭声数据库;其次,实时采集当前环境中的语音信息,经过预处理成语音特征向量序列,与哭声数据库进行特征匹配,并将匹配的结果进行哭声判决。若识别结果为哭声语音,则立即触发报警指令。智能看护系统一方面会向用户发送婴儿哭闹报警信号;另一方面,通过播放预先录制的具有安抚婴儿情绪功能的语音,对婴儿进行情绪安抚。本发明提出的哭声识别方法及智能看护系统能及时发现婴儿哭闹,解决部分家长的看护难题。此外,还为智能家居实现智能看护功能提供了解决方案。
本发明为解决上述技术问题采用以下技术方案:
一方面,本发明提供一种基于模式匹配的哭声识别方法,包括以下具体步骤:
步骤1,采集婴儿哭声语音信号,建立哭声数据库,具体为:
s101,采集若干婴儿哭声语音信号,并将其分别转换成数字语音信号;
s102,在设定的时间窗内,对s101中的数字语音信号进行分帧加窗处理,得到多帧语音信号;对每帧语音信号分别提取12维的梅尔频率倒谱系数mfcc作为其特征向量,从而得到多帧语音信号对应的特征向量序列;
s103,采用k-means算法对s102中得到的若干特征向量序列进行聚类,并对聚类后每类中的特征向量序列求取平均值后,存入哭声数据库;
步骤2,实时采集当前环境中的语音信号并转换成数字语音信号,根据s102中的方法对提取实时数字语音信号的特征向量序列;
步骤3,将步骤2中提取的实时数字语音信号的特征向量序列与步骤1中聚类后每类特征向量序列的均值进行逐帧匹配,将每帧匹配到的相似度最大的类别作为该帧的识别结果;
步骤4,根据步骤3中得到的每帧的识别结果,判断实时语音信号是否为哭声,完成识别;具体为:
s401,统计实时数字语音信号的特征向量序列中识别结果为第i类的帧数si,其中,1≤i≤n,n为聚类的类别总数;
s402,选取s401中得到的si的最大值
s403,判断
作为本发明的进一步优化方案,该方法还包括将步骤4中判定结果为哭声的特征向量序列加入哭声数据库中,通过k-means算法对哭声数据库进行重新聚类。
作为本发明的进一步优化方案,步骤s102中对数字语音信号进行分帧加窗处理之前,还包括对数字语音信号依次进行归一化和预加重处理。
作为本发明的进一步优化方案,步骤s102中设定的时间窗为5s。
作为本发明的进一步优化方案,步骤s102中分帧加窗处理具体为:每帧长度为20ms,窗函数为汉明窗,前后相邻两帧具有半帧的重叠区。
另一方面,本发明还提供一种基于上述基于模式匹配的哭声识别方法的智能看护装置,包括:
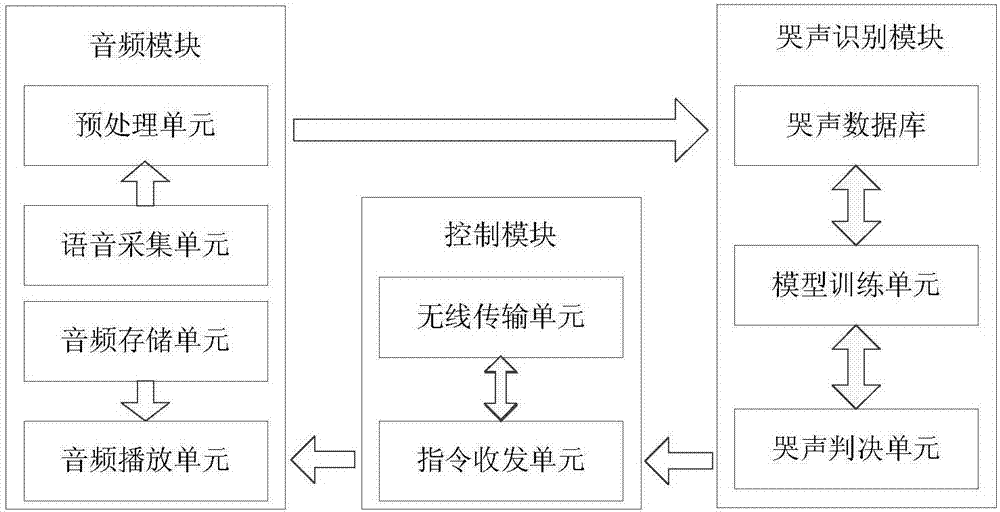
音频模块,用于实时采集当前环境中的语音信号,并对实时语音信号进行预处理;根据控制模块的指令播放预存的语音;
哭声识别模块,用于建立哭声数据库,并对预处理后的实时语音信号进行匹配,判断该语音是否为哭声;
控制模块,用于接收哭声识别模块的识别结果,若结果是哭声,则向用户端发送报警信号,同时向音频模块发送指令以播放预存的语音;接收用户端发送的指令,直接控制音频模块播放预存的语音。
作为本发明的进一步优化方案,音频模块包括:
语音采集单元,用于实时采集当前环境中的语音信号;
预处理单元,用于将实时语音信号转换成数字语音信号后,在设定的时间窗内对数字语音信号依次进行归一化、预加重、分帧、加窗处理,并提取实时语音特征向量序列,将特征向量序列发送至哭声数据库存储;
音频存储单元,用于存储具有安抚婴儿情绪功能的语音数据;
音频播放单元,用于接收控制模块发送的播放指令,从音频存储单元获取语音数据,并解码播放。
作为本发明的进一步优化方案,哭声识别模块包括:
哭声数据库,用于存储哭声语音信号对应的语音特征向量序列;
模型训练单元,用于对哭声数据库中存储的哭声特征向量序列,使用k-means算法进行聚类,并对聚类后每类中的特征向量序列求取平均值后存入哭声数据库中;
哭声判决单元,用于将提取的实时数字语音信号的特征向量序列与哭声数据库进行逐帧匹配,按照基于模式匹配的哭声识别方法判断实时语音信号是否为哭声,并将识别结果发送至控制单元,且若是哭声则将实时数字语音信号的特征向量序列存入哭声数据库。
作为本发明的进一步优化方案,控制模块包括:
指令收发单元,用于接收来自哭声识别模块的识别结果和来自用户端的指令,根据识别结果向音频模块发送控制指令和向用户端发出报警信号;
无线传输单元,用于用户端与指令收发单元之间的通信。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明一种基于模式匹配的哭声识别方法及智能看护系统,该方法首先建立婴儿哭声数据库;其次,实时采集当前环境中的语音信息,经过预处理成语音特征向量序列,与哭声数据库进行特征匹配,并将匹配的结果进行哭声判决。若识别结果为哭声语音,则立即触发报警指令。智能看护系统一方面会向用户发送婴儿哭闹报警信号;另一方面,通过播放预先录制的具有安抚婴儿情绪功能的语音,对婴儿进行情绪安抚。本发明提出的哭声识别方法及智能看护系统能及时发现婴儿哭闹,解决部分家长的看护难题。此外,还为智能家居实现智能看护功能提供了解决方案。
附图说明
图1为本发明提供的一种基于模式匹配的哭声识别方法流程图;
图2为本发明提供的基于模式匹配的智能看护系统模块化结构示意图。
具体实施方式
下面结合附图以及具体实施例对本发明的技术方案做进一步的详细说明:
图1显示了本发明提出的一种基于模式匹配的哭声识别方法流程图,具体执行步骤如下:
步骤s101,采集若干婴儿哭声语音信号,并将其分别转换成数字语音信号,得到若干完整语音段。
步骤s102,在设定的时间窗内,对每段语音依次进行归一化、预加重、分帧、加窗处理后,得到多帧语音信号;固设定的时间窗大小取5s;归一化的目的是为了减小音量大小不同对识别结果的影响;预加重的目的是提升高频部分,使信号频谱变得平坦,可通过传递函数为h(z)=1-az-1的预加重滤波器实现。根据哭声的短时平稳特性,每帧大小取20ms,为了相邻两帧之间能够平滑过度,取半帧帧移。
步骤s103,对每帧语音信号提取哭声特征向量,得到哭声特征向量序列,存入哭声数据库中;所述哭声特征向量为12维的梅尔频率倒谱系数mfcc;具体如下:
由于人耳对不同的频率声音具有不同的感知能力,在1000hz以下,感知能力与频率成线性关系;在1000hz以上,感知能力与频率成对数关系,而mel频率尺度与人耳的感知特性成线性关系。频率f与mel频率b之间的转换公式如下:
103-1:原始语音信号经过预加重、分帧、加窗处理后得到每个语音帧的时域信号x(n);
103-2:将时域信号经过快速傅里叶变换(fft)后得到线性频谱x(k);
103-3:将上述线性频谱x(k)通过mel滤波器组得到mel频率。滤波器组中滤波器的个数取值在24-40之间,本例取m=25;
103-4:计算mel滤波器的对数能量s(m),并对其做离散余弦变化(dct)就得到了mel频率倒谱系数c(n):
其中,l表示mel频率倒谱系数的阶数,本例取l=12;m为mel滤波器组中滤波器的总个数;m表示滤波器组的滤波器序号,0≤m≤m;n表示mel频率倒谱系数c(n)的维度序号,1≤n≤l。
步骤s104,根据s103获取的哭声特征序列,所述哭声特征向量序列,采用k-means算法对s103中获得的若干特征向量序列进行聚类,并对聚类后每类中的特征向量序列求取平均值后,存入哭声数据库。
步骤s105,实时采集当前环境中的语音信号并转换成数字语音信号,按照步骤s102、s103的方式进行处理,得到实时语音特征向量序列;
步骤s106,根据步骤s105获取的实时语音特征向量序列与步骤1中聚类后每类特征向量序列的均值进行逐帧匹配,每帧匹配到的相似度最大的类别作为该帧识别结果。
步骤s107,根据步骤s106获取的每帧的识别结果,判断实时语音信号是否为哭声,完成识别。具体为:
s107-1,统计特征向量序列中每帧对应的识别结果的数量si;其中,i表示k-means聚类后的第i个类别的序号,i=1,2,....,n;n为聚类的类别总数;
s107-2,取si中最大值
s107-3,判断
图2显示了本发明提供的基于模式匹配的智能看护系统模块化结构示意图,包括音频模块、控制模块、哭声识别模块。
其中,音频模块,用于采集语音数据,并对数据进行预处理;此外,还将存储用户预先录制的语音,用于安慰哭闹的婴儿。其中,音频模块具体包括:语音采集单元,用于采集当前环境中的语音信号;预处理单元,用于对采集的语音信号进行模数变换,转换成数字信号后,在在固定时间窗内,对所述数字信号依次进行归一化、预加重、分帧、加窗处理,并提取实时语音特征向量序列,将特征向量序列发送至哭声数据库存储;音频存储单元,用于存储用来具有安抚婴儿情绪功能的语音数据;音频播放单元,接收控制模块发送的播放指令,从音频存储单元获取语音数据,并解码播放。
其中,控制模块,用于接收哭声识别模块的识别结果,若结果是哭声,则向用户端发送报警信号,同时向音频模块发送指令以播放预存的语音;接收用户端发送的指令,直接控制音频模块播放预存的语音。其中,控制模块具体包括:指令收发单元,接收来自哭声识别模块的报警指令和来自用户的直接播放指令,若是报警指令,则还需要无线传输单元和音频模块发送报警信号,否则直接向音频模块发送报警信号;无线传输单元,与用户手机端通过wifi技术传输报警信号和接收直接播放指令。
其中,哭声识别模块,用于建立哭声数据库,使用k-means算法进行聚类,并对实时采集的语音数据进行匹配,判断该段语音是否为哭声。其中,哭声识别模块具体包括:哭声数据库,接收来自音频模块的语音特征向量序列,对于哭声特征向量序列则存储入库,对于实时采集的语音特征向量序列则进行缓存;模型训练单元,对哭声数据库中存储的哭声特征向量序列,使用k-means算法训练哭声分类模型,并存储入库;哭声判决单元,针对哭声数据库中缓存的语音特征向量序列,进行逐帧匹配,按照哭声识别方法进行判断此段语音特征向量序列,是否为哭声特征向量序列;若是,则存储到哭声数据库,并向控制模块发送哭声报警指令;否则直接清空缓存区。
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!