一种声音处理系统、方法及声音识别装置和声音接收装置与流程
本发明涉及互联网通信领域,特别涉及一种声音处理系统、方法及声音识别装置和声音接收装置。
背景技术:
目前,在不同的智能设备间彼此对外交互方式,常见的交互方式包括:基于wifi的控制信令、基于蓝牙的控制信令、基于ibeacon的控制信令。但是,这三种对外交互方式,存在以下不足之处:
1.进行外部控制时,发送硬件与接收硬件成本较高;
2.同时交互连线的设备数量有一定限制;
3.无法有效定位于密闭空间中的接收设备、信号溢出;
4.当发送或接收设备功能模组故障或弱网环境时,安全保障易发生问题。
技术实现要素:
本发明主要解决的技术问题是提供一种声音处理系统、方法及声音识别装置和声音接收装置,通过声音传递信息与控制信令的方式,提升既有交互应用的限制。
为解决上述技术问题,本发明采用的一个技术方案是:一种声音处理系统,所述系统包括:声音识别装置,用于接收到指令或人声语音时,识别输入内容以产生对应的控制指令,对所述控制指令进行处理并与第一音频文件合成以得到包含对应声码的第二音频文件,并发送所述第二音频文件;声音接收装置,用于接收所述第二音频文件,检测所述第二音频文件是否包含声波信号,在确认包含声波信号时对所述第二音频文件进行解析以得到对应的声码,并对所述声码进行解码以得到对应的数据信息。
其中,所述声音识别装置包括:分析单元,用于接收到指令或人声语音时,识别输入内容以产生所述控制指令;编码单元,用于将所述控制指令进行编码以产生对应的声码;第一转换单元,用于将所述声码进行傅里叶正向变换以得到声波信号;音频处理单元,用于将所述声波信号与所述第一音频文件合成以得到包含所述声码的第二音频文件;其中,所述第一音频文件为高频文件;发送单元,用于发送所述音频处理单元生成的所述第二音频文件。
其中,所述声音接收装置包括:接收单元,用于接收由所述声音识别装置发送的所述第二音频文件;检测单元,用于分析并检测所述第二音频文件中是否包含声波信号;第二变换单元,用于在所述检测单元确认包含声波信号时对所述第二音频文件进行解析以得到对应的声波信号,并对所述声波信号进行傅里叶逆向变换以得到对应的声码;解码单元,用于对所述声码进行解码以得到对应的数据信息。
其中,所述声音接收装置还包括:指令处理单元,用于判断所述解码单元产生的所述数据信息为基本信息还是延伸信息:当确定所述数据信息为基本信息时,播放或显示所述数据信息的内容;当确定所述数据信息为延伸信息时,访问对应的地址,执行对应的指令;其中,所述基本信息至少包括指令或人声语音内容,所述延伸信息至少包括网页链接地址、执行指令、指令链接。
其中,所述系统还包括服务器;所述指令处理单元确定所述数据信息为延伸信息时,向所述服务器发送对应的指令信息;其中,所述指令信息为访问指令或网页链接地址;所述服务器用于响应所述指令信息以执行相应的功能或调用对应网页,以获取对应的延伸应用;所述声音接收装置还用于接收所述服务器响应所述指令信息的执行结果。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种声音处理方法,所述方法包括:声音识别装置接收到指令或人声语音时,识别输入内容以产生对应的控制指令,对所述控制指令进行处理并与第一音频文件合成以得到包含对应声码的第二音频文件,并发送所述第二音频文件;以及声音接收装置接收所述第二音频文件,检测所述第二音频文件是否包含声波信号,在确认包含声波信号时对所述第二音频文件进行解析以得到对应的声码,并对所述声码进行解码以得到对应的数据信息。
其中,对所述控制指令进行处理并与第一音频文件合成以得到包含对应声码的第二音频文件,具体包括:将所述控制指令进行编码以产生对应的声码;将所述声码进行傅里叶正向变换以得到声波信号;以及将所述声波信号与所述第一音频文件合成以得到包含所述声码的第二音频文件;其中,所述第一音频文件为高频文件。
其中,在确认包含声波信号时对所述第二音频文件进行解析以得到对应的声码,具体包括:在所述检测单元确认包含声波信号时,对所述第二音频文件进行解析以得到对应的声波信号,并对所述声波信号进行傅里叶逆向变换以得到对应的声码。
其中,所述方法还包括:所述声音接收装置判断所述数据信息为基本信息还是延伸信息:其中,所述基本信息至少包括指令或人声语音内容,所述延伸信息至少包括网页链接地址、执行指令、指令链接;当确定所述数据信息为基本信息时,所述声音接收装置播放或显示所述数据信息的内容;当确定所述数据信息为延伸信息时,所述声音接收装置向一服务器发送对应的访问指令;所述服务器响应所述访问指令以执行相应的功能或调用对应网页,并向所述声音接收装置发送对应的执行结果。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种声音识别装置,所述装置包括:分析单元,用于接收到指令或人声语音时,识别输入内容以产生所述控制指令;编码单元,用于将所述控制指令进行编码以产生对应的声码;第一转换单元,用于将所述声码进行傅里叶正向变换以得到声波信号;音频处理单元,用于将所述声波信号与所述第一音频文件合成以得到包含所述声码的第二音频文件;其中,所述第一音频文件为高频文件;发送单元,用于发送所述音频处理单元生成的所述第二音频文件至一声音接收装置,使所述声音接收装置识别所述第二音频文件包含的声码所对应的数据信息。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种声音接收装置,所述装置包括:接收单元,用于接收一声音识别装置发送的第二音频文件;其中,所述第二音频文件为所述声音识别装置根据接收到的指令或人声语音而生成的包含对应声码的文件;检测单元,用于分析并检测所述第二音频文件中是否包含声波信号;第二变换单元,用于在所述检测单元确认包含声波信号,对所述第二音频文件进行解析得到声波信号,并对所述声波信号进行傅里叶逆向变换以得到对应的声码;以及解码单元,用于对所述声码进行解码以得到对应的数据信息。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种声音处理方法,所述方法包括:接收到指令或人声语音时,识别输入内容以产生对应的控制指令;将所述控制指令进行编码以产生对应的声码;将所述声码进行傅里叶正向变换以得到声波信号;将所述声波信号与所述第一音频文件合成以得到包含所述声码的第二音频文件;其中,所述第一音频文件为高频文件;以及发送所述第二音频文件,使一声音接收装置识别所述第二音频文件包含的声码所对应的数据信息。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种声音处理方法,所述方法包括:接收一声音识别装置发送的第二音频文件,检测所述第二音频文件是否包含声波信号;其中,所述第二音频文件为所述声音识别装置根据接收到的指令或人声语音而生成的包含对应声码的文件;在确认包含声波信号时对,对所述第二音频文件进行解析以得到对应的声波信号;对所述声波信号进行傅里叶逆向变换以得到对应的声码;以及对所述声码进行解码以得到对应的数据信息。
其中,所述方法还包括:判断所述数据信息为基本信息还是延伸信息;其中,所述基本信息至少包括指令或人声语音内容,所述延伸信息至少包括网页链接地址、执行指令、指令链接;当确定所述数据信息为基本信息时,播放或显示所述数据信息的内容;当确定所述数据信息为延伸信息时,向一服务器发送对应的访问指令,使所述服务器响应所述访问指令执行相应的功能或调用对应网页以及反馈对应的执行结果。
以上方案中,声音识别装置对接收到的指令,或人声语音进行声音编码,并嵌入高频声音文件中输出,使得声音接收装置能够在接收到该高频声音文件时识别出其包含的声码,从而进行解码以得到对应的信息或指令,实现通过高频声音文件进行指令、信息的传输,避免其他因素的干扰。
附图说明
图1是本发明第一实施方式中的一种声音处理系统的结构示意图;
图2是本发明实施方式中的声音识别装置的结构示意图;
图3是本发明实施方式中的声音接收装置的结构示意图;
图4是本发明第二实施方式中的一种声音处理系统的结构示意图;
图5是本发明第一实施方式中的一种声音处理方法的流程示意图;
图6是本发明第二实施方式中的一种声音处理方法的流程示意图;
图7是本发明第三实施方式中的一种声音处理方法的流程示意图;
图8是本发明第四实施方式中的一种声音处理方法的流程示意图;
图9是本发明第五实施方式中的一种音乐处理方法的流程示意图;
图10是本发明第六实施方式中的一种音乐处理方法的流程示意图;
图11是本发明第七实施方式中的一种音乐处理方法的流程示意图。
具体实施方式
首先对本发明实施方式所需引用的现有技术名词进行解释。
人工智能:是计算机科学的一个分支,企图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
智能识别:基于人工智能运算,对输入的内容进行以人类智能相似的转换、识别、分析、判断,所产生的输出结果。
内部控制指令:计算机或计算机装置内的指令信号,目的是触发装置的某项功能。
外部控制信令:建立于常见通信协议的外部通信讯号,可以由其它接收装置接收,例如基于wifi的控制信令、基于蓝牙的控制信令、基于ibeacon的控制信令、或其它以电磁波形式发送的控制信令。
触发响应内容:基于智能识别输入内容所做出的输出对应,例如文字、声音、语音、图像、网页链接、服务链接、控制信号、装置内部控制指令,或外部控制信令等。
音频:声音的频率。
声波信号:可以被接收并解析的音频所解析出的原始信号。
高频声音:超过大部份正常人耳可以听到音频的声音。
声码:声波信号进行傅里叶逆向变换后得到有意义的数据。
音频文档:可以播放或记录声音的文档或记忆格式,例如wav、mp3文档。
为详细说明本发明的技术内容、构造特征、所实现目的及效果,以下结合附图和实施例对本发明进行详细说明。
请参阅图1,为本发明实施方式的一种声音处理系统的结构示意图。该系统100包括声音识别装置10和声音接收装置20。在本实施方式中,该系统100包括一个声音识别装置10和一个声音接收装置20,即,声音识别装置10和声音接收装置20是一对一的网络连接关系。
该声音识别装置10用于接收到指令或人声语音时,识别输入内容以产生对应的控制指令,对该控制指令进行处理并与第一音频文件合成以得到包含对应声码的第二音频文件,并发送该第二音频文件。
该声音接收装置20用于接收该第二音频文件,检测该第二音频文件是否包含声波信号,在确认包含声波信号时对该第二音频文件进行解析以得到对应的声码,并对该声码进行解码以得到对应的数据信息。
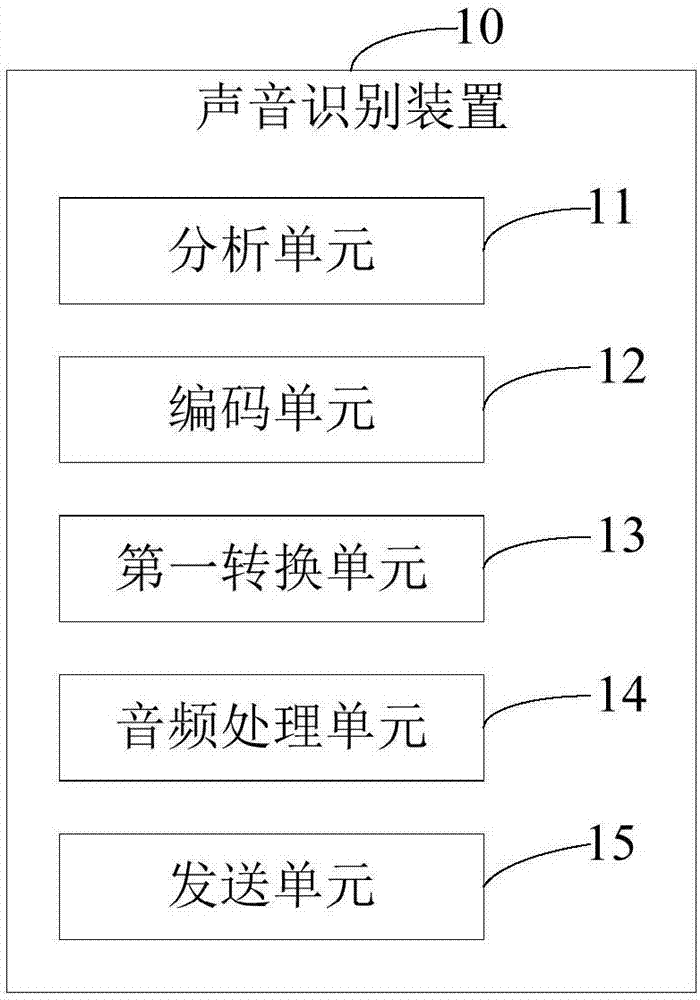
具体地,请同时参阅图2,为本发明实施方式中的声音识别装置的结构示意图。在本实施方式中,该声音识别装置10可以是智能移动设备、计算机等,具有诸如话筒,用于获取人声语音、音乐等音频信息。
该声音识别装置10包括分析单元11、编码单元12、第一转换单元13、音频处理单元14以及发送单元15。
该分析单元11用于接收到指令或人声语音时,识别输入内容以产生该控制指令。其中,该指令可以是该声音识别装置10响应用户的操作而产生的对应操作指令,还可以是该声音识别装置10来自于其他终端、设备发送的操作指令、控制指令等。
该编码单元12用于将该控制指令进行编码以产生对应的声码。
该第一转换单元13用于将编码单元12生成的声码进行傅里叶正向变换以得到声波信号。
该音频处理单元14用于将第一转换单元13生成的声波信号与第一音频文件合成,以得到包含该声码的第二音频文件。
其中,该第一音频文件为高频文件。在一实施方式中,该音频处理单元14将声波信号以多个连续间隔的方式与第一音频文件合成,形成第二音频文件。由于人耳听不到高于一定频率范围的声波信号,因此,第一音频文件为高频文件。当传送音频文件时,由于人们听不到携带声码的高频文件,完全感觉不到有声音存在,因此在进行音频传输时不会对用户或环境造成影响。
该发送单元15用于发送该音频处理单元14生成的第二音频文件。
请同时参阅图3,为本发明实施方式中的声音接收装置20的结构示意图。在本实施方式中,该声音识别装置20可以是智能移动设备、计算机等,具有诸如麦克风,用于获取音频文件。具体地,该声音接收装置20包括接收单元21、检测单元22、第二变换单元23以及解码单元24。
该接收单元21用于接收由声音识别装置10发送的第二音频文件。
该检测单元22用于分析并检测该第二音频文件中是否包含声波信号。具体地,该检测单元22通过对第二音频文件进行频谱分析以判断第二音频文件中是否包含声波信号。
该第二变换单元23用于在检测单元22确认包含声波信号时,对该第二音频文件进行解析以得到对应的声波信号,并对该声波信号进行傅里叶逆向变换以得到对应的声码。
该解码单元24用于对该第二变换单元23生成的声码进行解码,以得到对应的数据信息。
在本实施方式中,该数据信息包含控制指令的基本信息以及延伸信息。其中,基本信息至少包括指令或人声语音的内容,人声语音的内容为“开启***购物网页”。关联信息至少包括:网页链接地址、执行指令、指令链接。例如,网页链接地址为“***购物网页”的地址。
在其他实施方式中,该声音识别装置10还包括声音接收装置20的各个功能单元,该声音接收装置20还包括声音识别装置10的各个功能单元,这样,该声音识别装置10在识别处理接收到的指令或人声语音的同时,还可以对接收到的音频文件进行识别处理以得到对应的数据信息,同样地,该声音接收装置20在识别处理接收到的音频文件以得到对应的数据信息的同时,还可以对接收到的指令或人声语音进行识别处理并形成携带声码的音频文件。具体工作原理如上所述,在此不加赘述。
进一步地,该声音接收装置20还包括指令处理单元25,用于判断该解码单元24产生的数据信息类别,并根据判断结果执行相应的指令。具体地,该数据信息包含基本信息和延伸信息。该指令处理单元25判断产生的数据信息为基本信息还是延伸信息:
当确定数据信息为基本信息时,该声音接收装置20播放或显示该数据信息的内容;
当确定数据信息为延伸信息时,该声音接收装置20访问对应的地址,执行对应的指令。例如,该数据信息为网页链接地址时,该声音接收装置20通过该网页链接地址访问对应的网页。
请参阅图4,为本发明第二实施方式中的声音处理系统的结构示意图。该系统300包括声音识别装置31、声音接收装置32以及服务器33。
当该声音接收装置32确定该数据信息为延伸信息时,向该服务器33发送对应的指令信息。其中,该指令信息为访问指令或网页链接地址。
该服务器33用于响应该指令信息以执行相应的功能或调用对应的网页,以获取延伸应用。
进一步地,该服务器33还用于将执行结果反馈至声音接收装置32。
下面将结合具体应用场景对本发明进行举例说明。
应用场景一,在本应用场景中,服务器33为一网站服务器。
当声音识别装置31接收到“开启***购物网页”的指令或人声语音时,识别输入内容以产生对应的“开启***购物网页”的控制指令,对该控制指令进行如上所述的处理后得到包含对应声码的第二音频文件,并发送将该第二音频文件。
声音接收装置32接收到第二音频文件后,检测该音频文件包含声波信号时,对该第二音频文件进行解析、处理以得到对应的数据信息,该数据信息包括***购物网页的链接地址以及开启该链接地址的控制指令。然后,声音接收装置32响应该控制指令向服务器33发送访问***购物网页的请求。
服务器33响应该访问请求调用***购物网页的内容,使得声音接收装置32能够显示***购物网页的内容。
进一步地,声音识别装置31接收到“购买**”的指令或人声语音时,识别输入内容以产生对应的“购买**”的控制指令,对该控制指令进行如上所述的处理后得到包含对应声码的第二音频文件,并发送将该第二音频文件。
声音接收装置32接收到第二音频文件后,检测该音频文件包含声波信号时,对该第二音频文件进行解析、处理以得到对应的数据信息,该数据信息包括购买**控制指令。然后,声音接收装置32响应该控制指令向服务器33发送购买**的请求。
服务器33响应该请求对服务器所保存的数据进行相应的处理以执行**被购买的功能,即,完成网络下单。
声音识别装置31接收到“输入密码******”的指令或人声语音时,识别输入内容以产生对应的“输入密码******”的控制指令,对该控制指令进行如上所述的处理后得到包含对应声码的第二音频文件,并发送将该第二音频文件。
声音接收装置32接收到第二音频文件后,检测该音频文件包含声波信号时,对该第二音频文件进行解析、处理以得到对应的数据信息,该数据信息包括输入密码的控制指令以及密码为******。然后,声音接收装置32响应该控制指令向服务器33发送输入密码的指令,接收服务器33反馈的付款指令链接,并输入密码******,完成支付。
应用场景二,在本应用场景中,该服务器33为一银行系统服务器。
声音识别装置31接收到“转账**元给**”的指令或人声语音时,识别输入内容以产生对应的“转账**元给**”的控制指令,对该控制指令进行如上所述的处理后得到包含对应声码的第二音频文件,并发送将该第二音频文件。
声音接收装置32接收到第二音频文件后,检测该音频文件包含声波信号时,对该第二音频文件进行解析、处理以得到对应的数据信息,该数据信息包括转账指令、转账金额以及转账对象。然后,声音接收装置32响应该转账令向服务器33发送该请求。
服务器33响应该请求对服务器所保存的数据进行相应的处理以执行转账,即,完成电子银行转账信息的填写,并向该声音接收装置32反馈相应的转账确认页面。
该声音识别装置31接收到“输入密码****”的指令或人声语音时,识别输入内容以产生对应的“输入密码****”的控制指令,对该控制指令进行如上所述的处理后得到包含对应声码的第二音频文件,并发送将该第二音频文件。
声音接收装置32接收到第二音频文件后,检测该音频文件包含声波信号时,对该第二音频文件进行解析、处理以得到对应的数据信息,该数据信息包括输入密码以及密码内容。然后,声音接收装置32响应该输入密码指令向服务器33发送该请求,以使服务器33完成转账密码的输入,执行转账。
应用场景三
声音识别装置31接收到“接收**ppt”的指令或人声语音时,识别输入内容以产生对应的“接收**ppt”的控制指令,对该控制指令进行如上所述的处理后得到包含对应声码的第二音频文件,并发送将该第二音频文件。
声音接收装置32接收到第二音频文件后,检测该音频文件包含声波信号时,对该第二音频文件进行解析、处理以得到对应的数据信息,该数据信息包括接收ppt以及ppt文件。然后,声音接收装置32响应该指令下载、接收**ppt,完成文件的分享。
在其他实施方式中,该系统100还可以包括一个声音识别装置10以及多个声音接收装置20,即,声音识别装置10和声音接收装置20为一对多的网络连接关系。工作原理相同,在此不加赘述。
再一实施方式中,该系统100还可以包括多个声音识别装置10以及多个声音接收装置20,即,声音识别装置10和声音接收装置20为多对多的网络连接关系。工作原理相同,在此不加赘述。
再一实施方式中,该系统100还可以包括一个声音识别装置10、多个声音接收装置20以及一个服务器,即,声音识别装置10和声音接收装置20为一对多的网络连接关系,声音接收装置20与服务器为多对一的网络连接关系。工作原理相同,在此不加赘述。
再一实施方式中,该系统100还可以包括一个声音识别装置10、多个声音接收装置20以及多个服务器,即,声音识别装置10和声音接收装置20为一对多的网络连接关系,多个服务器可以是相同的服务器,也可以是不同的服务器。同样地,当该系统100包括多个声音识别装置10和多个声音接收装置20时,每个声音接收装置20可以与一个或多个服务器进行通信连接。工作原理相同,在此不加赘述。
请参阅图5,为本发明第一实施方式中的一种声音处理方法的流程示意图,该实施方式示出的方法应用于如上所述的声音处理系统。该方法包括:
步骤s50,声音识别装置接收到指令或人声语音时,识别输入内容以产生对应的控制指令,对该控制指令进行处理并与第一音频文件合成以得到包含对应声码的第二音频文件,并发送该第二音频文件。
请同时参阅图6,具体地:
步骤s501,接收到指令或人声语音时,识别输入内容以产生对应的控制指令;
步骤s502,将该控制指令进行编码以产生对应的声码;
步骤s503,将该声码进行傅里叶正向变换以得到声波信号。
步骤s504,将该声波信号与第一音频文件合成以得到包含该声码的第二音频文件;其中,该第一音频文件为高频文件。
步骤s51,声音接收装置接收第二音频文件,检测该第二音频文件是否包含声波信号,在确认包含声波信号时对该第二音频文件进行解析以得到对应的声码,并对该声码进行解码以得到对应的数据信息。
请同时参阅图7,具体地:
步骤s511,接收该第二音频文件,检测该第二音频文件是否包含声波信号;若是,进入步骤s512;否则,流程结束。
步骤s512,对该第二音频文件进行解析以得到对应的声波信号;
步骤s513,将该声波信号进行傅里叶逆向变换以得到对应的声码;
步骤s514,对该声码进行解码以得到对应的数据信息。
其中,该数据信息至少包含控制指令的基本信息以及延伸信息;该基本信息至少包括指令或人声语音内容,该延伸信息至少包括网页链接地址、执行指令、指令链接。
请参阅图8,为本发明第四实施方式中的声音处理方法的流程示意图,在对该声码进行解码以得到对应的数据信息之后,该方法还包括:
步骤s63,该声音接收装置判断该数据信息为基本信息还是延伸信息:若为基本信息,则进入步骤s64;若为延伸信息,则进入步骤s65。
其中,该基本信息至少包括指令或人声语音内容,该延伸信息至少包括网页链接地址、执行指令、指令链接。
步骤s64,当确定该数据信息为基本信息时,该声音接收装置播放或显示该数据信息的内容;然后,流程结束。
步骤s65,当确定该数据信息为延伸信息时,该声音接收装置向一服务器发送对应的访问指令。
步骤s66,该服务器响应该访问指令以执行相应的功能或调用对应网页,并向该声音接收装置发送对应的执行结果。然后,流程结束。
请参阅图9,为本发明第五实施方式中的音乐处理方法的流程示意图,该实施方式示出的方法应用于如上该的声音识别装置,包括:
步骤s70,接收到指令或人声语音时,识别输入内容以产生对应的控制指令;
步骤s71,将该控制指令进行编码以产生对应的声码;
步骤s72,将该声码进行傅里叶正向变换以得到声波信号;
步骤s73,将该声波信号与该第一音频文件合成以得到包含该声码的第二音频文件;其中,该第一音频文件为高频文件;以及
步骤s74,发送该第二音频文件,使一声音接收装置识别该第二音频文件包含的声码所对应的数据信息。
请参阅图10,为本发明第六实施方式中的声音处理方法的流程示意图,该实施方式示出的方法应用于如上该的声音接收装置,包括:
步骤s81,接收第二音频文件,判断该第二音频文件是否包含声波信号。若是,则进入步骤s82;否则,流程结束。
其中,该第二音频文件为一声音识别装置根据接收到的指令或人声语音而生成的携带对应声码的文件。
步骤s82,对该第二音频文件进行解析以得到对应的声波信号;
步骤s83,对该声波信号进行傅里叶逆向变换以得到对应的声码;
步骤s84,对该声码进行解码以得到对应的数据信息。
请参阅图11,为本发明第七实施方式中的声音处理方法的流程示意图,该实施方式示出的方法应用于如上所述的声音接收装置,包括:
步骤s91,接收第二音频文件,判断该第二音频文件是否包含声波信号。若是,则进入步骤s92;否则,进入步骤s95。
其中,该第二音频文件为一声音识别装置根据接收到的指令或人声语音而生成的携带对应声码的文件。
步骤s92,对该第二音频文件进行解析以得到对应的声波信号;
步骤s93,对该声波信号进行傅里叶逆向变换以得到对应的声码;
步骤s94,对该声码进行解码以得到对应的数据信息。
步骤s95,判断该数据信息为基本信息还是延伸信息:若为基本信息,则进入步骤s96;若为延伸信息,则进入步骤s97。
其中,该基本信息至少包括指令或人声语音内容,该延伸信息至少包括网页链接地址、执行指令、指令链接。
步骤s96,当播放或显示该数据信息的内容;然后,流程结束。
步骤s97,向一服务器发送对应的访问指令,使该服务器响应该访问指令以执行相应的功能或调用对应网页,并反馈对应的执行结果。然后,流程结束。
本发明实施方式中,声音识别装置对接收到的指令,或人声语音进行声音编码,并嵌入高频声音文件中输出,使得声音接收装置能够在接收到该高频声音文件时识别出其包含的声码,从而进行解码以得到对应的信息或指令,实现通过高频声音文件进行指令、信息的传输,避免其他因素的干扰。
以上所述仅为本发明的实施方式,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!