语音情绪辨识系统与方法以及使用其的智能机器人与流程
本发明乃涉及一种语音情绪辨识系统与方法,以及使用其的智能机器人,特别涉及一种通过声纹比对以进行语音情绪辨识的语音情绪辨识系统与方法,以及使用此种语音情绪辨识系统与方法的智能机器人。
背景技术:
一般来说,机器人所指的能自动执行任务的机器装置,由简单的逻辑电路或是更高阶的计算机程序来控制。因此,通常机器人是个高度机电整合的装置。近年来,机器人领域的相关技术发展越来越多元,如:工业型机器人、服务型机器人等。
由于大众对于生活便利的追求,服务型机器人开始被越来越多人接受。服务型机器人的种类很多,应用范围也很广泛。服务型机器人,如:专业服务机器人(professionalservicerobot)、个人/家庭用服务机器人(personal/domesticuserobot)等等,由于服务型机器人需与一般大众接触与互动,故其需具备对环境的感测与辨识能力。常见地,个人/家庭用服务机器人能够辨识使用者的语意,并根据用户的指令提供服务或与用户互动。然而,此类型的机器人多半只能根据用户的语音指令提供服务或与用户互动,而无法将使用者当前的情绪纳为提供服务或与使用者互动的根据。
技术实现要素:
为改善前述缺点,本发明提供了一种能根据一声音信号辨识出一情绪状态的语音情绪辨识系统与方法,以及使用此种语音情绪辨识系统与方法的智能机器人。
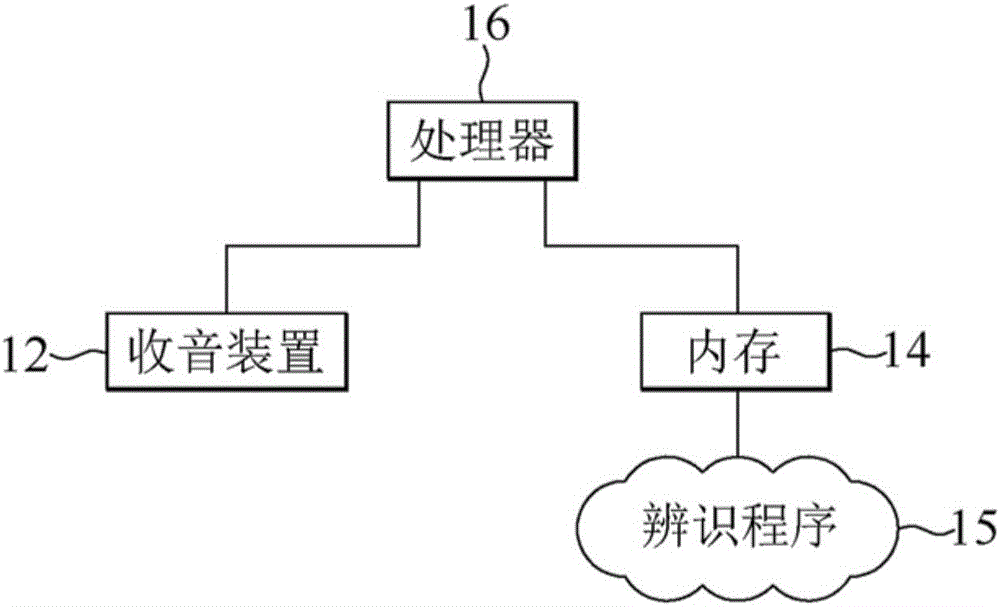
本发明所提供的语音情绪辨识系统包括收音装置、内存与处理器。收音装置设置以接收声音信号。内存设置以储存一辨识程序、一默认情绪数据库与多个个体情绪数据库,其中不同的个体情绪数据库对应于不同的个体。处理器连接于收音装置与内存,且设置以执行所述辨识程序以执行以下操作:将所述声音信号进行信号处理以获得一声纹文件,并根据所述声纹文件识别发出所述声音信号的一个体的身份;判断与所述个体对应的个体情绪数据库的完成度是否大于等于一预设百分比;将所述声纹文件与一预设声纹作比对,以获取出多个特征值;将所述多个特征值与储存于个体情绪数据库或默认情绪数据库的多组样本特征值作比对,并辨识出一情绪状态;以及将所述情绪状态与所述多个特征值的一对应关系新增至所述个体情绪数据库。
须说明的是,若处理器判断所述个体对应的个体情绪数据库的完成度大于等于所述预设百分比,则选择对应所述个体的个体情绪数据库作为辨识所述声纹文件的依据,而若处理器判断所述个体对应的个体情绪数据库的完成度小于所述预设百分比,则选择默认情绪数据库作为辨识所述声纹文件的依据。另外,储存于所述多个个体情绪数据库与默认情绪数据库的多组样本特征值分别对应于不同的情绪状态。
再者,本发明所提供的语音情绪辨识方法适用于前述的语音情绪辨识系统。本发明所提供的语音情绪辨识方法主要是以前述的语音情绪辨识系统中的辨识程序来实现。除此之外,本发明所提供的智能机器人主要包括中央处理器与前述的语音情绪辨识系统,以具备能根据一声音信号辨识出一情绪状态的功能。须说明的是,本发明所提供的智能机器人中的中央处理器会根据语音情绪辨识系统所辨识出的情绪状态产生一控制指令,使得智能机器人整体根据所述控制指令执行一动作。
由于本发明所提供的语音情绪辨识系统与方法,以及使用其的智能机器人能够根据使用者所发出的声音信号辨识出用户当前的情绪状态,因此能够将使用者当前的情绪纳为提供服务或与使用者互动的根据。相较于只能根据用户的语音指令提供服务或与用户互动的机器人装置,本发明所提供的语音情绪辨识系统与方法,以及使用其的智能机器人能够为使用者提供更符合其心境的服务与互动。
为使能更进一步了解本发明的特征及技术内容,请参阅以下有关本发明的详细说明与附图,但是这些说明与附图说明书附图仅用来说明本发明,而非对本发明的权利要求作任何的限制。
附图说明
图1为根据本发明一例示性实施例示出的语音情绪辨识系统的方框图;
图2为根据本发明一例示性实施例示出的语音情绪辨识方法的流程图;以及
图3为根据本发明另一例示性实施例示出的语音情绪辨识方法的流程图。
具体实施方式
在下文将参看说明书附图更充分地描述各种例示性实施例,在说明书附图中展示一些例示性实施例。然而,本发明概念可能以许多不同形式来体现,且不应解释为限于本文中所阐述的例示性实施例。确切而言,提供这些例示性实施例使得本发明将为详尽且完整,且将向熟习此项技术者充分传达本发明概念的实施方式。在诸附图中,类似数字始终指示类似组件。
大体而言,本发明所提供的语音情绪辨识系统与方法,以及使用其的智能机器人最大的特点及在于能够将使用者当前的情绪纳为提供服务或与使用者互动的根据,以为使用者提供更符合其心境的服务与互动。以下将以数个实施例来说明本发明所提供的语音情绪辨识系统与方法,以及使用其的智能机器人。
[语音情绪辨识系统的一实施例]
首先说明本发明的语音情绪辨识系统的架构,请参照图1,图1为根据本发明一例示性实施例示出的语音情绪辨识系统的方框图。
如图1所示,本实施例所提供的语音情绪辨识系统包括收音装置12、内存14与处理器16。收音装置12设置以接收声音信号。内存14设置以储存一辨识程序15、一默认情绪数据库、多个个体情绪数据库与一默认声纹数据库。本实施例所提供的语音情绪辨识系统中的收音装置12可以一麦克风装置来实现,且内存14与处理器16可以固件的形式来实现,或者由任何适合的硬件、固件、软件、及/或软件、固件及硬件的组合来实现。
须说明的是,储存于内存14中的多个个体情绪数据库分别对应不同个体的身份,且每个个体情绪数据库中针对特定个体储存有数笔情绪状态与样本特征值之间的对应关系,其中一组样本特征值对应一种情绪状态,但不同组的样本特征值可能对应到同一种情绪状态。再者,储存于内存14中的默认情绪数据库则是针对不特定个体储存有数笔情绪状态与样本特征值之间的对应关系,其中一组样本特征值对应一种情绪状态,但不同组的样本特征值可能对应到同一种情绪状态。较详细的说,默认情绪数据库中的储存的数笔情绪状态与样本特征值之间的对应关系是由系统建置者针对不特定个体预先收集来。另外,默认声纹数据库则储存有多笔样本声纹与多个个体的身份之间的对应关系。
[语音情绪辨识方法的一实施例]
请参照图2,图2为根据本发明一例示性实施例示出的语音情绪辨识方法的方框图。
本实施例所提供的语音情绪辨识方法是由图1所示出的语音情绪辨识系统中的处理器16执行储存于内存14中的一辨识程序15来实现,故请同时参照图1与图2以利了解。如图2所示,大体而言,本实施例所提供的语音情绪辨识方法包括以下步骤:将声音信号进行信号处理以获得声纹文件,并根据声纹文件识别发出声音信号的个体的身份(步骤s210);判断与个体对应的个体情绪数据库的完成度是否大于等于预设百分比(步骤s220);选择个体情绪数据库作为辨识声纹文件的依据(步骤s230a);选择默认情绪数据库作为辨识声纹文件的依据(步骤s230b);将声纹文件与预设声纹作比对,以获取出多个特征值(步骤s240);将所述多个特征值与储存于个体情绪数据库或默认情绪数据库的多组样本特征值作比对,并辨识出情绪状态(步骤s250);以及将情绪状态与所述多个特征值的对应关系新增至个体情绪数据库与默认情绪数据库(步骤s260)。
接着要说明的是本实施例所提供的语音情绪辨识方法中各步骤的细节。
在收音装置12接收到一声音信号后,于步骤s210中,处理器16会将此声音信号进行信号处理以获得一声纹文件。举例来说,处理器16可将所接收的声音信号转换成声谱图(spectrogram),以获取声谱图中的特征值作为声纹文件。接着,通过默认声纹数据库,处理器16便能识别发出声音信号的个体的身份。
识别发出声音信号的个体的身份后,于步骤s220中,处理器16会根据此个体的身份找出与此个体对应的个体情绪数据库,并判断此个体情绪数据库的完成度是否大于等于一预设百分比。若处理器16判断此个体情绪数据库的完成度大于等于一预设百分比,则表示此个体情绪数据库中的数据量与数据完整度应足够用以作为辨识声纹文件的依据,于此情况下便会进入步骤s230a,以选择使用与此个体对应的个体情绪数据库作为辨识声纹文件的依据。另一方面,若处理器16判断此个体情绪数据库的完成度小于所述预设百分比,则表示此个体情绪数据库中的数据量与数据完整度尚不足以作为辨识声纹文件的依据,于此情况下便会进入步骤s230b,以选择使用默认情绪数据库作为辨识声纹文件的依据。
在决定选择使用个体情绪数据库或默认情绪数据库作为辨识声纹文件的依据后,于步骤s240中,处理器会先将声纹文件与一预设声纹作比对。须说明的是,此预设声纹预先储存于默认情绪数据库与每个个体情绪数据库。由于储存于每个个体情绪数据库的默认声纹是由特定个体在无情绪起伏下所发出的声音信号所获得,而储存于默认情绪数据库的默认声纹则是由不特定个体在无情绪起伏下所发出的声音信号所获得,因此处理器将声纹文件与预设声纹作比对后,便能获取出能用以辨识此个体当前的情绪状态的多个特征值。
每个个体情绪数据库中针对特定个体储存有数笔情绪状态与样本特征值之间的对应关系,且默认情绪数据库针对不特定个体也储存有数笔情绪状态与样本特征值之间的对应关系,且于默认情绪数据库与每个个体情绪数据库中,一组样本特征值对应一种情绪状态,但不同组的样本特征值可能对应到同一种情绪状态。因此于步骤s250中,处理器16将所获取到的所述多个特征值与储存于个体情绪数据库或默认情绪数据库的多组样本特征值作比对后,便能辨识出此个体当前最有可能的情绪状态。
值得注意的是,于步骤s250中,处理器16是通过搜寻算法来将所述多个特征值与储存于个体情绪数据库或默认情绪数据库的多组样本特征值作比对,并判断出一情绪状态。也就是说,处理器16是使用搜寻算法来找出个体情绪数据库或默认情绪数据库中与所述多个特征值最相似的一组样本特征值。举例来说,处理器16所使用的搜寻算法可为顺序搜索法(sequentialsearch)、二分搜寻法(binarysearch)、二元树搜寻法(treesearch)、内插搜寻法(interpolationsearch)、哈希搜寻法(hashingsearch)等,本发明对于处理器16所使用的搜寻算法并不限制。
最后,于步骤s260中,处理器16会将所辨识出的情绪状态与所述多个特征值的对应关系同时新增至默认情绪数据库以及与此个体对应的个体情绪数据库。也就是说,处理器16会将所述多个特征值新增为新的一组样本特征值并至储存至默认情绪数据库以及与此个体对应的个体情绪数据库,同时也会将所辨识出的情绪状态与这组新的样本特征值的对应关系一并新增至默认情绪数据库以及与此个体对应的个体情绪数据库。因此,步骤s260即可视为本实施例所提供的语音情绪辨识系统的学习(learning)功能,通过此种学习功能,个体情绪数据库与默认情绪数据库的完成度便能不断地被优化。
[语音情绪辨识方法的另一实施例]
接下来请参照图3,图3为根据本发明另一例示性实施例示出的语音情绪辨识方法的流程图。
本实施例所提供的语音情绪辨识方法也是由图1所示出的语音情绪辨识系统中的处理器16执行储存于内存14中的一辨识程序15来实现,故请同时参照图1与图3以利了解。
本实施例所提供的语音情绪辨识方法中s320、s330a和s330b、s340a和s340b以及s350与图2所示出的实施例所提供的语音情绪辨识方法中步骤s220~s260类似,因此关于本实施例所提供的语音情绪辨识方法中步骤s320、s330a和s330b、s340a和s340b以及s350的细节可参照关于图2所示出的实施例所提供的语音情绪辨识方法中步骤s220~s260的描述,以下将仅就本实施例所提供的语音情绪辨识方法中其他步骤的细节作说明。
在收音装置12接收到一声音信号后,与图2所示出的实施例类似地,于步骤s310中,处理器16会将此声音信号进行信号处理以获得一声纹文件。举例来说,处理器16可将所接收的声音信号转换成声谱图(spectrogram),以获取声谱图中的特征值作为声纹文件,但本发明于此并不限制处理器16由声音信号中取得声纹文件的信号处理方式。
然而,差别在于,如图3所示,处理器16会进一步执行步骤s312~s316。由于默认声纹数据库储存有多笔样本声纹与多个个体的身份之间的对应关系,故于步骤s312中,处理器16会将声纹文件与默认声纹数据库中的所述多个样本声纹作比对,以判断是否存在有一样本声纹能够与声纹文件匹配。举例来说,处理器16在判断是否存在有一样本声纹能够与声纹文件匹配,可根据样本声纹能够与声纹文件之间的相似度来做判断。若某一样本声纹与声纹文件之间的相似度达到系统建置者所设定的一标准值,处理器16便能判断此样本声纹与声纹文件匹配。
当处理器16找出有一样本声纹能够与声纹文件匹配时,便进入步骤s314,以判断发出声音信号的个体就是与所述样本声纹相对应的个体。相反地,当处理器16找不到有一样本声纹能够与声纹文件匹配时,便表示默认声纹数据库中并没有与此个体相对应的样本声纹,于是在步骤s316中,处理器16会将此声纹文件新增至默认声纹数据库中作为一个新的样本声纹,并将这个新的样本声纹与此个体的身份间的对应关系一并储存至默认声纹数据库中。此外,处理器16还会在内存14中针对此个体新增一个体情绪数据库。
于本实施例中,在确认发出声音信号的个体的身份后,于步骤s320、s330a与s330b里,若内存14中储存有对应于此个体的个体情绪数据库,则处理器16便会判断此个体情绪数据库的完成度是否大于等于一预设百分比。若此个体情绪数据库的完成度大于等于预设百分比,则处理器16便会选择使用与此个体对应的个体情绪数据库作为辨识声纹文件的依据;然而,若此个体情绪数据库的完成度小于默认百分比,则处理器16便会选择使用默认情绪数据库作为辨识声纹文件的依据。另一方面,若内存14中未储存有对应于此个体的个体情绪数据库,则处理器16便会选择使用默认情绪数据库作为辨识声纹文件的依据。
首先,要说明的是处理器16使用与此个体对应的个体情绪数据库来辨识声纹文件的流程。
于处理器16选择使用与此个体对应的个体情绪数据库作为辨识声纹文件的依据后,于步骤s332a中,处理器16会将声纹文件与预设声纹作比对,以获取出多个特征值。此步骤类似于图2所示的实施例中的步骤s240,故关于此步骤的细节请参照前述针对图2所示的实施例中的步骤s240所做的说明。接着于步骤s334a中,处理器16会将所获取出的所述多个特征值与储存于个体情绪数据库的多组样本特征值作比对,并产生一相似度百分比。举例来说,处理器16从声纹文件中所获取出的所述多个特征值可为音高(pitch)、共振峰(formant)、音框能量(frameenergy)等等,其中音高与人类对音符基频(fundamentalfrequency)的感受有关,共振峰与声纹文件中能量较集中的频率位置有关,音框能量与声音的强度变化有关,但本发明不限制处理器16从声纹文件中所获取出的特征值的类型。
接下来,于步骤s336a中,处理器16会判断于步骤s334a中所得到的相似度百分比是否大于等于一门坎百分比。于此步骤中,会先找出是否存在相似度百分比大于等于一门坎百分比的一或多组样本特征值。若存在相似度百分比大于等于一门坎百分比的一组样本特征值,则于步骤s340a中,处理器16便会根据所述组样本特征值判断出对应的一情绪状态。再者,若存在相似度百分比大于等于一门坎百分比的多组样本特征值,则于步骤s336a中,处理器16便会进一步将相似度百分比大于等于一门坎百分比的多组样本特征值作排序,以找出相似度百分比最高的所述组样本特征值。接着,于步骤s340a中,处理器16便会根据相似度百分比最高的所述组样本特征值判断出对应的一情绪状态。最后,于步骤s350中,处理器16会将所判断出的情绪状态与所述组特征值的对应关系新增至所述个体的个体情绪数据库与默认情绪数据库中。
另一方面,于步骤s336a中,若所述个体的个体情绪数据库不存在相似度百分比大于等于一门坎百分比的一或多组样本特征值,则会到步骤s330b,处理器16另行选择默认情绪数据库作为辨识声纹文件的依据。
因此,接着要说明的是处理器16使用默认情绪数据库来辨识声纹文件的流程。
于步骤s332b中,处理器16会将声纹文件与预设声纹作比对,以获取出多个特征值。此步骤类似于图2所示的实施例中的步骤s240,故关于此步骤的细节请参照前述针对图2所示的实施例中的步骤s240所做的说明。接着于步骤s340b中,处理器16会将所获取出的所述多个特征值与储存于默认情绪数据库的所述多个样本特征值作比对,并产生一相似度百分比。于此步骤中,本发明同样不限制处理器16从声纹文件中所获取出的特征值的类型;也就是说,处理器16从声纹文件中所获取出的所述多个特征值可为前述举例的特征值,如:音高(pitch)、共振峰(formant)、音框能量(frameenergy)等等。
接下来,处理器16会判断所得到的相似度百分比是否大于等于一门坎百分比。同样地,处理器16会先找出是否存在相似度百分比大于等于一门坎百分比的一或多组样本特征值。若存在相似度百分比大于等于一门坎百分比的一组样本特征值,则处理器16便会根据所述组样本特征值判断出对应的一情绪状态。再者,若存在相似度百分比大于等于一门坎百分比的多组样本特征值,则处理器16便会进一步将相似度百分比大于等于一门坎百分比的多组样本特征值作排序,以找出相似度百分比最高的所述组样本特征值。接着,处理器16便会根据相似度百分比最高的所述组样本特征值判断出对应的一情绪状态。
较不同于使用默认情绪数据库来辨识声纹文件的流程的是,当处理器16于步骤340b中辨识出一情绪状态后,会进入步骤s342b,以对所述个体发出一语音信号,来确认步骤340b中辨识出的情绪状态是否为个体当前的情绪状态。此时,若处理器16根据收音装置12所获取到的一语音信息判断出步骤340b中辨识出的情绪状态确实为个体当前的情绪状态,则进入步骤s350,以将所辨识出的情绪状态与所述组特征值的对应关系新增至所述个体的个体情绪数据库与默认情绪数据库中。然而,若处理器16根据收音装置12所获取到的一语音信息判断出步骤340b中辨识出的情绪状态并非个体当前的情绪状态,则回到步骤s340b,以找出相似度百分比次高的所述组样本特征值,根据相似度百分比次高的所述组样本特征值判断出对应的一情绪状态,并继续前述的步骤s342b与步骤s350。
另一方面,于步骤s340b中,若不存在相似度百分比大于等于一门坎百分比的一或多组样本特征值,则处理器16还是会根据相似度百分比最高的所述组样本特征值判断出对应的一情绪状态,并继续前述的步骤s342b与步骤s350。
最后值得注意的是,于步骤s334a与步骤s340b中,处理器16是通过搜寻算法来将所述多个特征值与储存于个体情绪数据库或默认情绪数据库的多个样本特征值作比对,并判断出一情绪状态。也就是说,处理器16是使用搜寻算法来找出个体情绪数据库或默认情绪数据库中与所述多个特征值最相似的一组样本特征值。举例来说,处理器16所使用的搜寻算法可为顺序搜索法(sequentialsearch)、二分搜寻法(binarysearch)、二元树搜寻法(treesearch)、内插搜寻法(interpolationsearch)、哈希搜寻法(hashingsearch)等,本发明对于处理器16所使用的搜寻算法并不限制。
[智能机器人的一实施例]
本实施例所提供的智能机器人包括中央处理器以及如前述任一实施例所描述的语音情绪辨识系统。举例来说,本实施例所提供的智能机器人可由一个人/家庭用服务机器人来实现。本实施例所提供的智能机器人由于设置有如前述任一实施例所描述的语音情绪辨识系统,因此能根据用户所发出的声音信号辨识出用户当前的情绪状态。此外,在根据用户所发出的声音信号辨识出用户当前的情绪状态后,本实施例所提供的智能机器人中的中央处理器便会根据语音情绪辨识系统所辨识出的情绪状态产生一控制指令,使得智能机器人根据此控制指令执行一动作。
举例来说,若使用者以低落的语气说出「播放音乐」,于本实施例中,智能机器人中的语音情绪辨识系统便能根据用户所发出的声音信号辨识出「低落」的情绪状态。由于语音情绪辨识系统所辨识出的情绪状态为「低落」,因此智能机器人中的中央处理器便产生一控制指令来使得智能机器人发出一语音信号,如:「要不要听点轻松的音乐」,以确认是否播放轻松的音乐。
[实施例的可能技术效果]
首先,于本发明所提供的语音情绪辨识系统与方法中,处理器会将所辨识出的情绪状态与个体声纹的特征值的对应关系新增至默认情绪数据库以及与此个体对应的个体情绪数据库。也就是说,本发明所提供的语音情绪辨识系统具有学习(learning)功能,通过此种学习功能,个体情绪数据库与默认情绪数据库的完成度便能不断地被优化。
再者,由于本发明所提供的语音情绪辨识系统与方法是使用搜寻算法来找出个体情绪数据库或默认情绪数据库中与个体声纹的特征值最相似的一组样本特征值,因此能够较快捷地找出个体情绪数据库或默认情绪数据库中与个体声纹的特征值最相似的一组样本特征值。
此外,因为本发明所提供的语音情绪辨识系统与方法,以及使用期的智能机器人能够根据使用者所发出的声音信号辨识出用户当前的情绪状态,因此能够将使用者当前的情绪纳为提供服务或与使用者互动的根据。相较于只能根据用户的语音指令提供服务或与用户互动的机器人装置,本发明所提供的语音情绪辨识系统与方法,以及使用其的智能机器人能够为使用者提供更符合其心境的服务与互动。
最后须说明地是,于前述说明中,尽管已将本发明技术的概念以多个示例性实施例具体地示出与阐述,然而在此项技术的领域中技术人员将理解,在不背离由以下权利要求所界定的本发明技术的概念的范围的条件下,可对其作出形式及细节上的各种变化。
- 还没有人留言评论。精彩留言会获得点赞!