自动切割、传输、保存的语音识别方法与流程
本发明属于语音切割技术领域,特别是涉及一种自动切割、传输、保存的语音识别方法。
背景技术:
长期以来,人们在工作和生活中习惯用笔和纸手写记录文字,形成纸质文件,再通过抄写修改和发表。随着社会的发展和电脑的应用,打字记录文字,及时准确,方便查询,保存时间长,占用空间小、能修改又环保等优势表现出来,电脑文字技术的出现,使人们工作生活方式发生了改变,近年来,随着政府企事业单位的会议越来越多、新闻采访、课堂笔记需要及时形成文字,供用户参考和发表,为了更好地解决这个问题,语音速记本通过录入会议、新闻采访、课堂笔记的录音,利用语音识别技术,及时转换成文字,同步上传到云端服务器分类储存,供用户查询修改和使用。
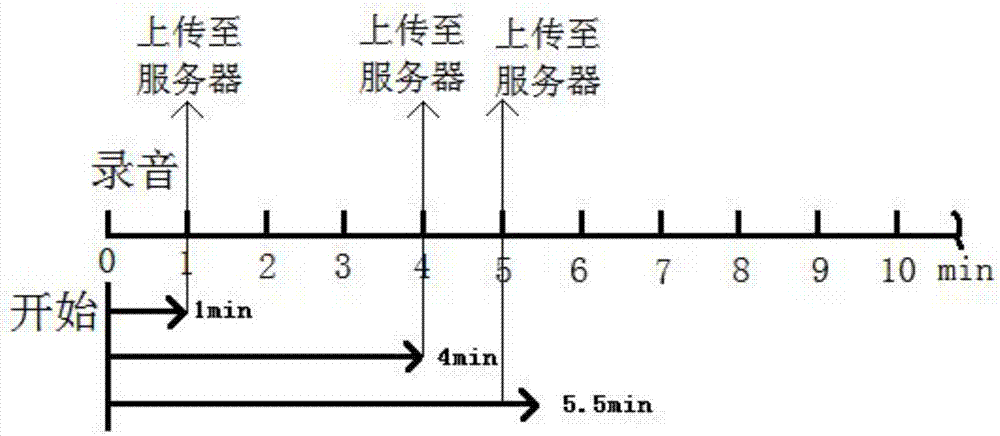
公文速记本改变传统的手工记录文字方式,通过采集语音、图像等输入信息,快速将讲话、发言、口述语音和正版文字稿件转写成新的电子文稿。根据公文基本要素、格式和文体的规范要求,通过模板对电子文字信息进行加工,自动生成各种规范的电子公文,如图2所示,采集语音时,传统的语音切割时,将对应的音频按时间长度平均分成一定长度的小段,分段上传至服务器,服务器将文字返回至公文速记本,易造成掉包现象,因此,提供一种自动切割、传输、保存的语音识别方法,解决上述问题。
技术实现要素:
本发明的目的在于提供一种自动切割、传输、保存的语音识别方法,通过判断语音解码返回数据的时间差,对语音自动切割上传,解决了现有语音识别时语音文字掉包、语音转文字的正确性和连续性低的问题。
为解决上述技术问题,本发明是通过以下技术方案实现的:
本发明为自动切割、传输、保存的语音识别方法,包括如下步骤:
步骤一:通过麦克风实时采集音频信息;
步骤二:音频信息以流媒体的形式传输至速记终端的音频切割模块;
步骤三:音频切割模块根据语音解码返回数据的时间差自动切割音频,获取到分段音频信息;
步骤四:音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存分段音频信息;
步骤五:音频切割模块通过音频传输模块将分段音频信息传输到语音识别服务器;
步骤六:语音识别服务器自动识别分段音频信息并将其转换成文字信息;
步骤七:语音识别服务器将文字信息依次返回至速记终端,并通过显示装置进行显示。
进一步地,所述速记终端包括麦克风、音频切割模块、音频保存模块和音频传输模块;其中,所述麦克风通过信号分析处理及转换传输模块与音频切割模块相联;其中,所述音频切割模块与音频保存模块电连接,所述音频保存模块与音频传输模块相联:其中,所述音频传输模块与语音识别服务器通信连接。
进一步地,所述自动切割音频的方法包括如下步骤:
ss01:音频切割模块对语音解码返回数据的时间差进行判断;
ss02:当音频信息出现20ms及以上的停顿时,音频切割模块对音频进行自动切割,并将分段音频信息上传至语音识别服务器;
ss03:继续录音,重复步骤ss01~ss02。
本发明具有以下有益效果:
本发明通过麦克风实时采集音频信息,音频信息以流媒体的形式传输至速记终端的音频切割模块,音频切割模块根据语音解码返回数据的时间差自动切割音频,获取到分段音频信息,音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存分段音频信息,语音识别服务器自动识别分段音频信息并将其转换成文字信息,实现了对音频的自动切割上传,保证了语音文字不掉包,实现语音转文字的连续性和正确性,从而解决了语音转文字时间控制的问题。
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中速记终端的结构示意图;
图2为传统语音切割方法的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1所示,本发明为自动切割、传输、保存的语音识别方法,包括如下步骤:
步骤一:通过麦克风实时采集音频信息;
步骤二:音频信息以流媒体的形式传输至速记终端的音频切割模块;
步骤三:音频切割模块根据语音解码返回数据的时间差自动切割音频,获取到分段音频信息;
步骤四:音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存分段音频信息;
步骤五:音频切割模块通过音频传输模块将分段音频信息传输到语音识别服务器;
步骤六:语音识别服务器自动识别分段音频信息并将其转换成文字信息;
步骤七:语音识别服务器将文字信息依次返回至速记终端,并通过显示装置进行显示。
其中,速记终端包括麦克风、音频切割模块、音频保存模块和音频传输模块;其中,麦克风通过信号分析处理及转换传输模块与音频切割模块相联;其中,音频切割模块与音频保存模块电连接,音频保存模块与音频传输模块相联:其中,音频传输模块与语音识别服务器通信连接。
其中,自动切割音频的方法包括如下步骤:
ss01:音频切割模块对语音解码返回数据的时间差进行判断;
ss02:当音频信息出现20ms及以上的停顿时,音频切割模块对音频进行自动切割,形成序列号,并将分段音频信息依次上传至语音识别服务器;
ss03:继续录音,重复步骤ss01~ss02。
具体实施例一:
录音开始,通过麦克风实时采集音频信息,音频信息以流媒体的形式传输至速记终端的音频切割模块,当声音在58秒出现停顿,且停顿时间为25毫秒时;音频切割模块自动切割音频,获取到分段音频信息,同时继续录音;音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存0-57秒的音频信息;音频切割模块通过音频传输模块将0-57秒的音频信息传输到语音识别服务器,语音识别服务器自动识别0-57秒的音频信息并将其转换成第一段文字信息;语音识别服务器将第一段文字信息返回至速记终端,并通过显示装置进行显示;
当声音在1分20秒出现停顿,且停顿时间为20毫秒时;音频切割模块自动切割音频,获取到分段音频信息,同时继续录音;音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存57秒-1分20秒的音频信息;音频切割模块通过音频传输模块将57秒-1分20秒的音频信息传输到语音识别服务器,语音识别服务器自动识别57秒-1分20秒的音频信息并将其转换成第二段文字信息;语音识别服务器将第二段文字信息返回至速记终端,并通过显示装置进行显示;
当声音在2分钟出现停顿,且停顿时间为23毫秒时;音频切割模块自动切割音频,获取到分段音频信息,同时继续录音;音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存1分20秒-2分钟的音频信息;音频切割模块通过音频传输模块将1分20秒-2分钟的音频信息传输到语音识别服务器,语音识别服务器自动识别1分20秒-2分钟的音频信息并将其转换成第三段文字信息;语音识别服务器将第三段文字信息返回至速记终端,并通过显示装置进行显示。
具体实施例二:
录音开始,通过麦克风实时采集音频信息,音频信息以流媒体的形式传输至速记终端的音频切割模块,当声音在1分钟出现停顿,且停顿时间为20毫秒时;音频切割模块自动切割音频,获取到分段音频信息,同时继续录音;音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存0-1分钟的音频信息;音频切割模块通过音频传输模块将0-1分钟的音频信息传输到语音识别服务器,语音识别服务器自动识别0-1分钟的音频信息并将其转换成第一段文字信息;语音识别服务器将第一段文字信息返回至速记终端,并通过显示装置进行显示;
当声音在1分48秒出现停顿,且停顿时间为10毫秒时,不进行切割,继续录音;
当声音在1分53秒出现停顿,且停顿时间为23毫秒时,音频切割模块自动切割音频,获取到分段音频信息,同时继续录音;音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存60秒-1分53秒的音频信息;音频切割模块通过音频传输模块将60秒-1分53秒的音频信息传输到语音识别服务器,语音识别服务器自动识别60秒-1分53秒的音频信息并将其转换成第二段文字信息;语音识别服务器将第二段文字信息返回至速记终端,并通过显示装置进行显示。
具体实施例三:
录音开始,通过麦克风实时采集音频信息,音频信息以流媒体的形式传输至速记终端的音频切割模块;
当声音在1分钟出现停顿,且停顿时间为15毫秒时,不进行切割,继续录音;
当声音在1分25秒出现停顿,且停顿时间为30毫秒时,音频切割模块自动切割音频,获取到分段音频信息,同时继续录音;音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存0-1分25秒的音频信息;音频切割模块通过音频传输模块将0-1分25秒的音频信息传输到语音识别服务器,语音识别服务器自动识别0-1分25秒的音频信息并将其转换成第一段文字信息;语音识别服务器将第一段文字信息返回至速记终端,并通过显示装置进行显示;
当声音在1分55秒出现停顿,且停顿时间为19毫秒时,不进行切割,继续录音;
当声音在2分40秒出现停顿,且停顿时间为45毫秒时,音频切割模块自动切割音频,获取到分段音频信息,同时继续录音;音频切割模块将分段音频信息传输到音频保存模块,音频保存模块保存1分25秒-2分40秒的音频信息;音频切割模块通过音频传输模块将1分25秒-2分40秒的音频信息传输到语音识别服务器,语音识别服务器自动识别1分25秒-2分40秒的音频信息并将其转换成第二段文字信息;语音识别服务器将第二段文字信息返回至速记终端,并通过显示装置进行显示。
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!