增强现实设备的语音控制方法、系统及存储介质与流程
本发明涉及增强现实设备技术领域,尤其涉及一种增强现实设备的语音控制方法、系统及存储介质。
背景技术:
随着增强现实设备技术的发展,增强现实设备被广泛应用于各行各业,尤其是在零售行业和教育行业。
现有的ar技术在实际应用中,更多是以手势控制的方式进行交互,必须要在增强现实眼镜前通过不同的手势,来对增强现实眼镜中的界面来进行控制,这种交互方式操作比较麻烦,而且成功率不高,有时候需要尝试很多次才能成功,视场受局限,使用手势跟踪会比较累而且不直观,没有反馈。
现有的一些语音控制方式,因为增强现实眼镜是以一个头戴式的方式固定在人的头部,对于麦克风的收声本来具有先天的局限性,声音的指向性不强,容易受到外界的噪声干扰,导致ar设备响应的指令不一定来自于佩戴者。且目前语音控制系统的指令呆板,无法灵活的在用户的正常语境中了解到用户的指令,并响应操作。
技术实现要素:
本发明的主要目的在于提出一种增强现实设备的语音控制方法、系统及存储介质,旨在解决现有技术中存在的技术问题,实现通过语音指令有效控制增强现实设备,提升用户体验。
为实现上述目的,本发明提供一种增强现实设备的语音控制方法,所述方法包括以下步骤:
在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息;
解析采集到的语音信息;
若解析成功,得到解析后的语音信息,则根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对,其中,所述语音特征数据库包括用户的身份信息、用户的语音特征、以及与所述用户的语音特征相对应的用户习惯数据;
若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,则从所述语音特征数据库中获取对应的用户习惯数据;
根据获取到的用户习惯数据向用户推送相应的服务信息。
本发明的进一步的技术方案是,所述解析采集到的语音信息的步骤之后还包括:
若解析不成功,则将所述采集到的语音信息上传至云端服务器进行解析;
接收所述云端服务器反馈的解析后的语音信息;
根据所述云端服务器反馈的解析后的语音信息向用户推送相应的服务信息。
本发明的进一步的技术方案是,接收所述云端服务器反馈的解析后的语音信息的步骤之后还包括:
将所述云端服务器反馈的解析后的语音信息存储于本地,并基于所述云端服务器反馈的解析后的语音信息更新所述语音特征数据库。
本发明的进一步的技术方案是,所述在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息的步骤之前包括:
获取用户的身份信息、以及与所述用户的身份信息相对应的语音特征;
基于所述用户的身份信息、与所述用户的身份信息相对应的语音特征建立语音特征数据库。
本发明的进一步的技术方案是,所述根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对之后包括:若在所述语音特征数据库中查找不到与所述解析后的语音信息对应的语音特征,则返回执行获取用户的身份信息、以及与所述用户的身份信息相对应的语音特征的步骤。
本发明的进一步的技术方案是,所述在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息的步骤之后包括:
对所述采集到的语音信息进行降噪处理,得到降噪后的语音信息;
所述解析采集到的语音信息的步骤包括:
解析降噪后的语音信息。
为实现上述目的,本发明还提出一种增强现实设备的语音控制系统,所述系统包括语音信息采集模块、控制网关模块,所述控制网关模块包括数据分析单元、身份比对单元、习惯数据获取单元、服务信息推送单元,其中,
所述语音信息采集模块用于在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息;
所述数据分析单元用于解析采集到的语音信息;
所述身份比对单元用于在解析成功,得到解析后的语音信息时,根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对,其中,所述语音特征数据库包括用户的身份信息、用户的语音特征、以及与所述用户的语音特征相对应的用户习惯数据;
所述习惯数据获取单元用于在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征时,从所述数据库中获取对应的用户习惯数据;
所述服务信息推送单元用于根据获取到的用户习惯数据向用户推送相应的服务信息。
本发明的进一步的技术方案是,还包括云端服务器,所述数据分析单元还用于在解析不成功时,将所述采集到的语音信息上传至所述云端服务器进行解析;
所述服务信息推送单元还用于在接收所述云端服务器反馈的解析后的语音信息时,根据所述云端服务器反馈的解析后的语音信息向用户推送相应的服务信息。
本发明的进一步的技术方案是,还包括存储模块,所述存储模块用于将所述云端服务器反馈的解析后的语音信息存储于本地,并基于所述云端服务器反馈的解析后的语音信息更新所述语音特征数据库。
为实现上述目的,本发明还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有增强现实设备的语音控制程序,所述增强现实设备的语音控制程序被处理器执行时实现如上所述的增强现实设备的语音控制方法的步骤。
本发明增强现实设备的语音控制方法、系统及存储介质通过上述技术方案,在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息;解析采集到的语音信息;若解析成功,得到解析后的语音信息,则根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对;若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,则从所述数据库中获取对应的用户习惯数据;根据获取到的用户习惯数据向用户推送相应的服务信息,相对于现有技术,便于根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,实现了通过语音指令有效控制增强现实设备,提升了用户体验。
附图说明
图1为本发明增强现实设备的语音控制方法第一实施例的流程示意图;
图2为本发明增强现实设备的语音控制方法第二实施例的流程示意图;
图3为本发明增强现实设备的语音控制方法第三实施例的流程示意图;
图4为本发明增强现实设备的语音控制系统第一实施例的功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
请参照图1,图1为本发明增强现实设备的语音控制方法第一实施例的流程示意图。
如图1所示,本发明增强现实设备的语音控制方法第一实施例包括以下步骤:
步骤s10,在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息。
可以理解的是,本实施例提出的增强现实设备的语音控制方法应用于增强现实设备的语音控制系统,所述增强现实设备的语音控制系统包括语音信息采集模块、控制网关模块,所述控制网关模块包括数据分析单元、身份比对单元、习惯数据获取单元、服务信息推送单元。
本实施例中,所述增强现实设备例如为vr眼镜,本实施例以vr眼镜为例对本发明做详细阐述。
本实施例为了实现有效获取用户的语音指令,确保降低噪声影响,提高收声指向性,所述语音信息采集模块可以为在所述vr眼镜上设置的语音数据采集麦克风阵列,在侦测到用户开启vr眼镜的语音指令时,通过所述语音数据采集麦克风阵列采集用户的语音信息。
具体实施时,本实施例考虑到现有的增强现实设备本身的语音采集麦克风矩阵式设计,容易受制于增强现实设备本身的结构特殊性,因此,本实施例在vr眼镜的下方,设计了4个独立数字麦克风的语音采集麦克风矩阵,麦克风收声指向均为用户的口腔方向,同时,利用降噪预处理模块进行噪声处理,确保不会漏掉用户所有的语音指令。
步骤s20,解析采集到的语音信息。若解析成功,得到解析后的语音信息之后,则执行步骤s30。
具体地,当采集到用户的语音信息后,通过数据分析单元进行预处理分析,按照系统默认的指令分析模型将采集到的语音信息解析生成系统所能执行的语音信息。
步骤s30,根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对。其中,所述语音特征数据库包括用户的身份信息、用户的语音特征、以及与所述用户的语音特征相对应的用户习惯数据。
可以理解的是,本实施例根据用户使用增强现实设备的语音使用行为,记录用户对增强现实设备的操作行为,将记录的数据作为用户的行为习惯上报,记录用户语音指令习惯日志,存储在用户语音特征数据库,便于根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,用户体验更佳。
步骤s40,若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,则从所述语音特征数据库中获取对应的用户习惯数据。
需要说明的是,本实施例中,可以根据身份比对的结果判断用户是否为首次使用该增强现实设备。
若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,则身份比对通过,说明用户不是首次使用该增强现实设备,此时,即可以从所述语音特征数据库中获取对应的用户习惯数据。
步骤s50,根据获取到的用户习惯数据向用户推送相应的服务信息。
从所述语音特征数据库中获取对应的用户习惯数据后,根据所述用户习惯数据向用户推送与所述用户习惯数据相对应的服务信息,例如,用户关注的商品、图像信息或者与该类商品、图像相关的信息。
本实施例通过上述技术方案在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息;解析采集到的语音信息;若解析成功,得到解析后的语音信息,则根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对;若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,则从所述数据库中获取对应的用户习惯数据;根据获取到的用户习惯数据向用户推送相应的服务信息,相对于现有技术,便于根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,实现了通过语音指令有效控制增强现实设备,提升了用户体验。
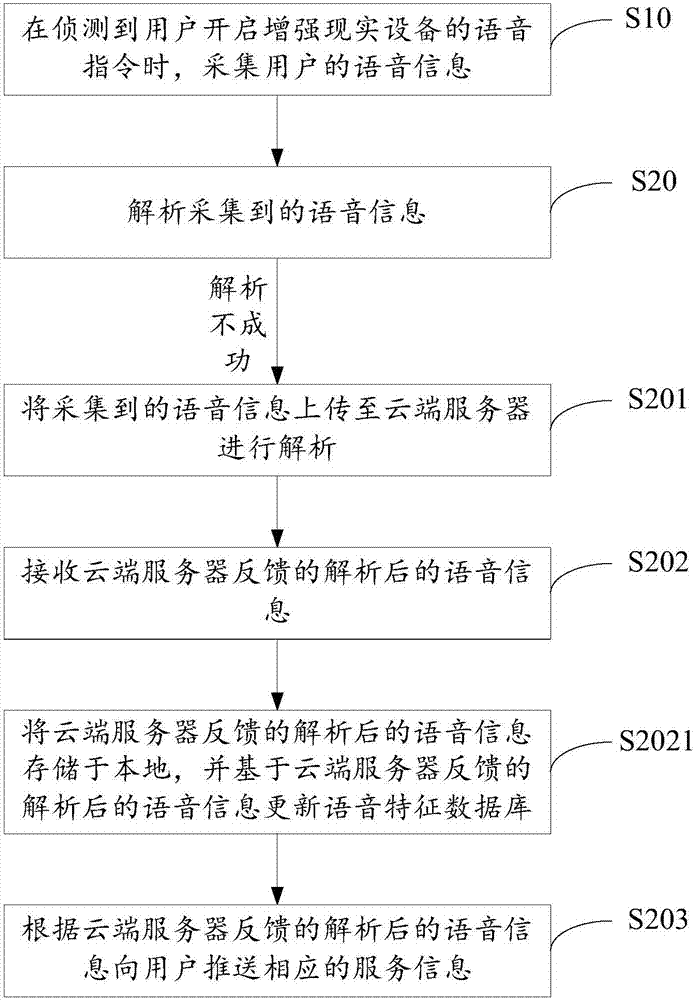
请参照图2,图2是本发明增强现实设备的语音控制方法第二实施例的流程示意图。
本实施例与基于图1所示的第一实施例的区别在于,所述增强现实设备的语音控制系统还包括云端服务器,上述步骤s20,解析采集到的语音信息的步骤之后还包括:
步骤s201,若解析不成功,则将所述采集到的语音信息上传至所述云端服务器进行解析;
步骤s202,接收所述云端服务器反馈的解析后的语音信息;
步骤s203,根据所述云端服务器反馈的解析后的语音信息向用户推送相应的服务信息。
具体地,本实施例中,所述增强现实设备的语音控制系统还包括云端服务器。当采集到用户的语音信息后,通过数据分析单元进行预处理分析,按照系统默认的指令分析模型将采集到的语音信息解析生成系统所能执行的语音信息,如果本地的数据分析单元无法成功解析采集到的语音信息,则将会将采集到的语音信息上传至所述云端服务器,进行大数据分析处理后确认用户真实意图,然后反馈下发至用户的增强现实设备上。
此外,本实施例在上述步骤s202,接收所述云端服务器反馈的解析后的语音信息的步骤之后还包括:
步骤s2021,将所述云端服务器反馈的解析后的语音信息存储于本地,并基于所述云端服务器反馈的解析后的语音信息更新所述语音特征数据库。
本实施例考虑到为了提高后续用户的语音控制的准确性,因此,在接收所述云端服务器反馈的解析后的语音信息之后,将所述云端服务器反馈的解析后的语音信息存储于本地,并基于所述云端服务器反馈的解析后的语音信息更新所述语音特征数据库,以进一步完善用户语音指令分析模型。
请参照图3,图3为本发明增强现实设备的语音控制方法第三实施例的流程示意图。
本实施例与基于图1所示的第一实施例的区别在于,上述步骤s10,在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息的步骤之前包括:
步骤s01,获取用户的身份信息、以及与所述用户的身份信息相对应的语音特征;
步骤s02,基于所述用户的身份信息、与所述用户的身份信息相对应的语音特征建立语音特征数据库。
具体地,本实施例中,所述增强现实设备的麦克风矩阵会指向性拾取用户的语音控制信息,通过降噪预处理模块对拾取到的语音信息进行降噪处理,提取用户的有效语音信息,获取用户的语音特征,从而根据用户的身份信息、与所述用户的身份信息相对应的语音特征建立语音特征数据库,以便于用户下次使用该增强现实设备时进行身份比对,根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,实现通过语音指令有效控制增强现实设备,进一步提升用户体验。
此外,作为一种实施方式,本实施例在上述步骤s30,根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对的步骤之后包括:若在所述语音特征数据库中查找不到与所述解析后的语音信息对应的语音特征,则返回执行获取用户的身份信息、以及与所述用户的身份信息相对应的语音特征的步骤。
需要说明的是,如果在所述语音特征数据库中查找不到与所述解析后的语音信息对应的语音特征,则可以判断为身份比对不通过,也就是说,该用户为首次使用该增强现实设备。
具体地,若该用户为首次使用该增强现实设备,则执行以下步骤:
1)录入用户身份信息;
2)记录用户的语音特征;
3)开始语音特征校准;
4)校准结束后,得到用户语音特征校准文件,与语音特征及用户身份信息关联建立语音特征数据库,并进行存储;
5)存储完成后,对用户的语音信息进行采集分析;
6)根据对用户的语音信息的不断采集分析,根据不同的语音信息尤其是连续长时间对语音信息的数据分析模型进行新数据录入,模型更新优化中,计算分析用户的真实指令目的,让语音控制系统更加智能化,拟人化,能够“听懂”用户的日常语音信息并且给出正确的反馈,避免出现信息的僵化呆板。
此外,作为一种实施方式,本实施例中,上述步骤s10,在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息的步骤之后包括:对所述采集到的语音信息进行降噪处理,得到降噪后的语音信息。上述步骤s20,解析采集到的语音信息的步骤包括:解析降噪后的语音信息。
通过对语音信息的降噪处理,能有效抑制环境噪音,抓取关键语音信息,最大程度上保证了语音指令的准确性,可确保后续语音识别能够不断升级,越来越精准。
综上所述,本发明增强现实设备的语音控制方法,在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息;解析采集到的语音信息;若解析成功,得到解析后的语音信息,则根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对;若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,则从所述数据库中获取对应的用户习惯数据;根据获取到的用户习惯数据向用户推送相应的服务信息,相对于现有技术,便于根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,实现了通过语音指令有效控制增强现实设备,提升了用户体验。
此外,本发明还提出一种增强现实设备的语音控制系统,请参照图4,图4为本发明增强现实设备的语音控制系统第一实施例的功能模块示意图。
如图4所示,所述系统包括语音信息采集模块10、控制网关模块20,所述控制网关模块20包括数据分析单元201、身份比对单元202、习惯数据获取单元203、服务信息推送单元204,其中,所述语音信息采集模块10用于在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息。
本实施例中,所述增强现实设备例如为vr眼镜,本实施例以vr眼镜为例对本发明做详细阐述。
本实施例为了实现有效获取用户的语音指令,确保降低噪声影响,提高收声指向性,所述语音信息采集模块10可以为在所述vr眼镜上设置的语音数据采集麦克风阵列,在侦测到用户开启vr眼镜的语音指令时,通过所述语音数据采集麦克风阵列采集用户的语音信息。
具体实施时,本实施例考虑到现有的增强现实设备本身的语音采集麦克风矩阵式设计,容易受制于增强现实设备本身的结构特殊性,因此,本实施例在vr眼镜的下方,设计了4个独立数字麦克风的语音采集麦克风矩阵,麦克风收声指向均为用户的口腔方向,同时,利用降噪预处理模块进行噪声处理,确保不会漏掉用户所有的语音指令。
所述数据分析单元201用于解析采集到的语音信息。
具体地,当采集到用户的语音信息后,通过数据分析单元201进行预处理分析,按照系统默认的指令分析模型将采集到的语音信息解析生成系统所能执行的语音信息。
所述身份比对单元202用于在解析成功,得到解析后的语音信息时,根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对,其中,所述语音特征数据库包括用户的身份信息、用户的语音特征、以及与所述用户的语音特征相对应的用户习惯数据。
可以理解的是,本实施例根据用户使用增强现实设备的语音使用行为,记录用户对增强现实设备的操作行为,将记录的数据作为用户的行为习惯上报,记录用户语音指令习惯日志,存储在用户语音特征数据库,便于根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,用户体验更佳。
所述习惯数据获取单元203用于在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征时,从所述数据库中获取对应的用户习惯数据。
需要说明的是,本实施例中,可以根据身份比对的结果判断用户是否为首次使用该增强现实设备。
若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,则身份比对通过,说明用户不是首次使用该增强现实设备,此时,即可以从所述语音特征数据库中获取对应的用户习惯数据。
所述服务信息推送单元204用于根据获取到的用户习惯数据向用户推送相应的服务信息。
从所述语音特征数据库中获取对应的用户习惯数据后,根据所述用户习惯数据向用户推送与所述用户习惯数据相对应的服务信息,例如,用户关注的商品、图像信息或者与该类商品、图像相关的信息。
本实施例通过语音信息采集模块10在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息;数据分析单元201解析采集到的语音信息;若解析成功,得到解析后的语音信息,身份比对单元202则根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对;若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,习惯数据获取单元203则从所述数据库中获取对应的用户习惯数据;服务信息推送单元204根据获取到的用户习惯数据向用户推送相应的服务信息,相对于现有技术,便于根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,实现了通过语音指令有效控制增强现实设备,提升了用户体验。
作为一种实施方式,所述增强现实设备的语音控制系统还包括云端服务器,所述数据分析单元201还用于在解析不成功时,将所述采集到的语音信息上传至云端进行解析;所述服务信息推送单元204还用于在接收云端反馈的解析后的语音信息时,根据所述云端服务器反馈的解析后的语音信息向用户推送相应的服务信息。
具体地,本实施例中,所述增强现实设备的语音控制系统还包括云端服务器。当采集到用户的语音信息后,通过数据分析单元201进行预处理分析,按照系统默认的指令分析模型将采集到的语音信息解析生成系统所能执行的语音信息,如果本地的数据分析单元201无法成功解析采集到的语音信息,则将会将采集到的语音信息上传至所述云端服务器,进行大数据分析处理后确认用户真实意图,然后反馈下发至用户的增强现实设备上。再由所述服务信息推送单元204根据所述云端服务器反馈的解析后的语音信息向用户推送相应的服务信息。
此外,本实施例中,所述增强现实设备的语音控制系统,还包括存储模块,所述存储模块用于将云端反馈的解析后的语音信息存储于本地,并基于所述云端反馈的解析后的语音信息更新所述语音特征数据库。
本实施例考虑到为了提高后续用户的语音控制的准确性,因此,在接收所述云端服务器反馈的解析后的语音信息之后,通过所述存储模块将所述云端服务器反馈的解析后的语音信息存储于本地,并基于所述云端服务器反馈的解析后的语音信息更新所述语音特征数据库,以进一步完善用户语音指令分析模型。
此外,本实施例提出的增强现实设备的语音控制系统还包括获取模块、降噪预处理模块、语音特征数据库建立模块,其中,所述获取模块用于在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息之前获取用户的身份信息、以及与所述用户的身份信息相对应的语音特征。
所述语音特征数据库建立模块用于基于所述用户的身份信息、与所述用户的身份信息相对应的语音特征建立语音特征数据库。
具体地,本实施例中,所述增强现实设备的麦克风矩阵会指向性拾取用户的语音控制信息,通过降噪预处理模块对拾取到的语音信息进行降噪处理,提取用户的有效语音信息,获取用户的语音特征,从而根据用户的身份信息、与所述用户的身份信息相对应的语音特征建立语音特征数据库,以便于用户下次使用该增强现实设备时进行身份比对,根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,实现通过语音指令有效控制增强现实设备,进一步提升用户体验。
通过对语音信息的降噪处理,能有效抑制环境噪音,抓取关键语音信息,最大程度上保证了语音指令的准确性,可确保后续语音识别能够不断升级,越来越精准。
此外,作为一种实施方式,如果所述身份比对单元202在所述语音特征数据库中查找不到与所述解析后的语音信息对应的语音特征,则再次通过所述获取模块获取用户的身份信息、以及与所述用户的身份信息相对应的语音特征。
需要说明的是,如果在所述语音特征数据库中查找不到与所述解析后的语音信息对应的语音特征,则可以判断为身份比对不通过,也就是说,该用户为首次使用该增强现实设备。
具体地,若该用户为首次使用该增强现实设备,则执行以下步骤:
1)录入用户身份信息;
2)记录用户的语音特征;
3)开始语音特征校准;
4)校准结束后,得到用户语音特征校准文件,与语音特征及用户身份信息关联建立语音特征数据库,并进行存储;
5)存储完成后,对用户的语音信息进行采集分析;
6)根据对用户的语音信息的不断采集分析,根据不同的语音信息尤其是连续长时间对语音信息的数据分析模型进行新数据录入,模型更新优化中,计算分析用户的真实指令目的,让语音控制系统更加智能化,拟人化,能够“听懂”用户的日常语音信息并且给出正确的反馈,避免出现信息的僵化呆板。
综上所述,本发明增强现实设备的语音控制系统通过语音信息采集模块10在侦测到用户开启增强现实设备的语音指令时,采集用户的语音信息;数据分析单元201解析采集到的语音信息;若解析成功,得到解析后的语音信息,身份比对单元202则根据所述解析后的语音信息查找预设的语音特征数据库进行身份比对;若在所述语音特征数据库中查找到与所述解析后的语音信息对应的语音特征,习惯数据获取单元203则从所述数据库中获取对应的用户习惯数据;服务信息推送单元204根据获取到的用户习惯数据向用户推送相应的服务信息,相对于现有技术,便于根据用户历史的语音行为习惯预测性分析用户未来的行为习惯,使增强现实设备和用户的连接更加紧密,实现了通过语音指令有效控制增强现实设备,提升了用户体验。
此外,本发明还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有增强现实设备的语音控制程序,所述增强现实设备的语音控制程序被处理器执行时实现如上各实施例所述的增强现实设备的语音控制方法的步骤,这里不再赘述。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!