一种语音信号处理方法及装置与流程
本发明涉及通信技术领域,特别是涉及一种适用于全双工通话的语音信号处理方法与装置。
背景技术:
全双工语音双向对讲不仅常见于免提通话、会议一体机等传统应用中,随着家用网络摄像机的普及,也开始出现于摄像机端与手机端的视频通话应用中,如儿童陪护机器以及可视门铃等。
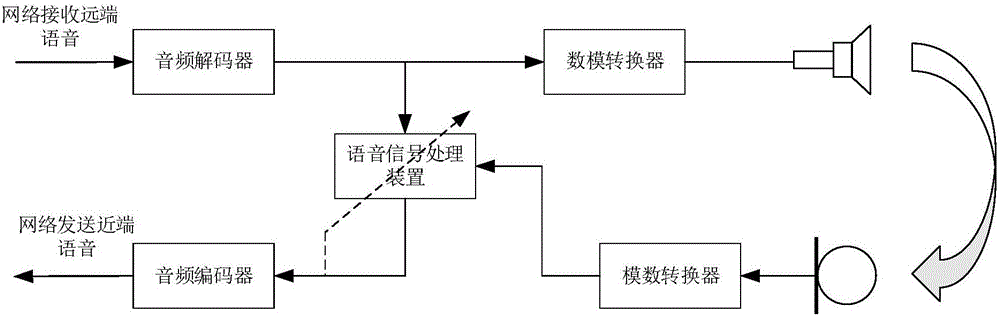
目前,上述应用场景一般如图1所示,其中,终端设备通过互联网接收远端语音信号,经过音频解码器单元解码后经过数字-模拟转换器转换为模拟信号,最后经过扬声器播放,同时终端设备的麦克风采集本地语音信号后经过模拟-数字转换器转换为数字信号,经过本地语音信号处理器单元处理后(消除回声、抑制噪声等)再经过音频编码器单元编码压缩打包后通过网络传输到远端。然后受限于终端设备体积,尤其是近年来家用网络摄像机的轻型化低功耗趋势,使得终端设备的麦克风与扬声器之间的距离较近;同时受限于成本,设备采用相对低廉的麦克风和扬声器的线性度较差,不仅回声消除后的残余回声较多,更容易发生啸叫,而且语音信号中的噪声也较严重。
现有技术如公开号为cn103037121a的中国专利申请,其检测到啸叫时就切换到半双工通话模式,以降低客户通话体验为代价,通过切断啸叫振荡回路达到抑制啸叫的目的,文献《apsychoacousticapproachtocombinedacousticechocancellationandnoisereduction》则介绍了一种同时抑制残余回声与噪声的后处理滤波器。
但是目前已公开的文献或专利中并没有给出如何在全双工通话中同时有效抑制回声、残余回声与啸叫以及噪声的方法和装置。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种语音信号处理方法及装置,以能够对全双工通话中的回声,残余回声,啸叫以及噪声进行抑制,能够以比较低的复杂度解决语音对讲中的回声、啸叫以及噪声等问题。
为达上述及其它目的,本发明提出一种语音信号处理方法,包括如下步骤:
步骤一,接收解码的远端信号,并于播放解码后的远端信号的同时采集近端信号;
步骤二,估计并补偿延迟,对远端及近端信号进行数据对齐操作;
步骤三,将对齐后的远端和近端信号送入带反馈的自适应回声抑制单元,抑制近端信号中的回声;
步骤四,抑制近端信号中的残余回声与啸叫;
步骤五,抑制近端信号中的噪声;
步骤六,将近端信号通过网络传输出去。
进一步地,步骤三进一步包括:
近端和远端信号分别进行离散傅立叶dft变换;
将经离散傅立叶dft变换后的远端和近端信号送入所述带反馈的自适应回声抑制单元,以抑制近端信号中的回声。
进一步地,步骤四进一步包括:
步骤s1,将步骤三的输出分为两路,一路计算不同频段下步骤三的输出与最近l帧远端信号的相似度;
步骤s2,得到回声输出信号在各频带下与最近l帧远端信号的相似度后,根据获得的相似度以及最近l帧远端信号加权得到残余回声估计;
步骤s3,将当前帧回声消除输出的幅值减去残余回声估计得到残余回声抑制后的输出幅值;
步骤s4,获得步骤三的另一路输出,计算特定频段下回声消除输出与啸叫信号的相似度;
步骤s5,将该相似度映射为幅度抑制因子,抑制特定频段幅度;
步骤s6,对步骤s3的输出与步骤s5的输出进行融合后输出。
进一步地,于步骤s1中,计算跨功率谱相关密度作为当前帧回声消除输出与最近l帧远端信号的相似度计算依据。
进一步地,于步骤s2中,将步骤s1中得到的相似度映射为权重,并利用最近l帧远端信号加权得到残余回声估计。
进一步地,于步骤s4中,所述特定频段指的是特定采样率下啸叫易发生频段,通过离线预先标定得到,所述相似度采用时-频域结合的判据来衡量。
进一步地,于步骤s6中,将步骤s3的输出与步骤s5的输出取最小值作为输出幅值,同时保留原始回声消除输出相位,作为融合后的输出。
进一步地,于步骤五中,
在步骤四的基础上,分频段对带噪信号进行掩蔽,进一步抑制噪声,噪声幅值估计通过之前噪声能量估计与当前瞬时能量估计进行平滑来实现,平滑因子通过所述带反馈的自适应回声抑制单元中的滤波器更新步长进行辅助判断。
进一步地,于步骤六中,将经过噪声抑制后的语音经过反dft运算后输出。
为达到上述目的,本发明还提供一种语音信号处理装置,包括:
信号采集与处理单元,用于接收解码后的远端信号将其存放至缓冲区内,并于播放解码后的远端信号的同时采集近端信号,估计并补偿延迟,对远端及近端信号进行数据对齐操作;
第一dft运算单元,用于对对齐的近端信号进行离散傅立叶dft变换送入回声抑制单元;
第二dft运算单元,用于对对齐的远端信号进行离散傅立叶dft变换送入回声抑制单元;
带反馈的自适应回声抑制单元,用于抑制近端信号中的回声,并根据输出与远端信号的相关性自适应地调整滤波器更新步长;
残余回声与啸叫抑制单元,以所述带反馈的自适应回声抑制单元的输出作为输入,对可能存在啸叫的频段进行检测,进而决定抑制的幅度,同时对残余回声进行抑制;
噪声抑制单元,用于在残余回声与啸叫抑制单元的输出基础上估计噪声,以抑制近端信号中的噪声;
反dft运算单元,用于将所述噪声抑制单元输出的语音经过反dft运算后输出。
与现有技术相比,本发明提出一种语音信号处理方法及装置,能够对全双工通话中的回声、残余回声、啸叫以及噪声进行抑制,能够以比较低的复杂度解决语音对讲中的回声、啸叫以及噪声等问题,同时给出了一种噪声能量估计中平滑因子的快速更新算法。
附图说明
图1为本发明典型应用场景示意图;
图2为本发明一种语音信号处理方法的步骤流程图;
图3为本发明具体实施例中步骤204的细部流程图;
图4为本发明一种语音信号处理装置的系统结构图;
图5为本发明具体实施例中残余回声与啸叫抑制单元的细部结构图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图2为本发明一种语音信号处理方法的步骤流程图。如图2所示,本发明一种语音信号处理方法,包括如下步骤:
步骤201,接收解码远端信号将其存放至缓冲区内,播放解码后的远端信号的同时采集近端信号。在本发明中,被扬声器播放的远端信号经过机壳、墙壁等反射后变成回声信号和本地语言信号以及环境噪声一起也被麦克风采集,通称为近端信号。
步骤202,估计并补偿延迟,对远端及近端信号进行数据对齐操作。由于声音传输以及数据接收到播放的延迟等原因,此时麦克风采集到的回声信号与接收的远端信号之间存在延迟,因此在回声抵消之前需要估计并补偿延迟,达到数据对齐的目的,在本发明具体实施例中,延迟可以通过标定预先设置,也可以通过在线实时估计的方法得到,后者可以通过计算当前帧近端信号与缓冲区中最近几帧的远端信号的相似度来实现。
步骤203,将对齐后的远端和近端信号送入带反馈的自适应回声抑制单元,抑制近端信号中的回声。
具体地,步骤203进一步包括:
步骤s31,对近端和远端信号分别进行离散傅立叶dft变换。
具体地,假设远端信号已经进行过延迟补偿操作,当前语音帧为第t帧,t≥l,分别对近端和远端信号的数据加窗后进行离散傅立叶(dft)正变换,变换后的频域结果分别表示为d(ωk,t)和x(ωk,t),其中
步骤s32,将经离散傅立叶dft变换后的远端和近端信号送入回声抑制单元,抑制近端信号中的回声。
具体地,将上述频域结果输入回声抑制单元,其输出记为e(ωk,t),所述回声抑制单元可以利用频域自适应滤波算法实现,如归一化最小均方自适应滤波器nlms。
步骤204,抑制近端信号中的残余回声与啸叫。
具体地,如图3所示,步骤204进一步包括:
步骤s41,将步骤203的输出分为两路,一路计算不同频段下步骤103的输出与最近l帧远端信号的相似度。在本发明具体实施例中,相似度可以采用跨功率谱相关密度或其它近似算法实现。
具体地,利用如下公式(1)计算跨功率谱相关密度pex(ωk,ti),作为当前帧回声消除输出e(ωk,t)与第t-i帧远端信号x(ωk,t-i)的相似度计算依据
pex(ωk,ti)=|e(ωk,t)||x(ωk,t-i)|(1)
其中,其中0≤i≤l,操作符||代表取复数幅值运算。
当然上述相似度计算依据除了使用跨功率谱相关密度,也可以使用其它近似算法,如统计不同频带下当前帧与第t-i帧远端信号能量或幅值的直方图分布相似情况,本发明不以此为限。
步骤s42,得到回声输出信号在各频带下与最近l帧远端信号的相似度后,根据获得的相似度以及最近l帧远端信号加权得到残余回声估计。
具体地,将步骤s41中得到的相似度映射为权重,并利用最近l帧远端信号加权得到残余回声估计,在本发明具体实施例中,采用如下公式(2)加权得到第t帧残余回声估计
上述归一化权重可以将公式1计算得到的相似度为索引,查表得到;也可以直接使用公式(3)将相似度归一化后得到:
步骤s43,将当前帧回声消除输出的幅值|e(ωk,t)|减去残余回声估计
步骤s44,获得步骤203的另一路输出,计算特定频段下回声消除输出e(ωk,t)与啸叫信号的相似度。所述特定频段指的是特定采样率下啸叫易发生频段,可以通过离线预先标定得到,所述相似度采用时-频域结合的判据来衡量。
步骤s45,将该相似度映射为幅度抑制因子,抑制特定频段幅度。
由于正常语音或音乐信号会在基频和谐波上都有能量分布,而啸叫信号不存在此特点,因此可以统计基频与对应谐波能量比大于预设定阈值的次数。上述基频指的是特定频段附近的频率,上述谐波指的是频率是基频整数倍的频率。同时可以再统计时域上前k帧特定频段能量大于预设定阈值的次数,通过查表将上述两统计值映射为该频段下回声消除输出e(ωk,t)与啸叫信号的相似度或置信度,再将上述相似度查表得到该频段幅度抑制因子,乘到抑制该频段幅度上,得到啸叫抑制的输出幅值e2(ωk,t)。上述基频与对应谐波能量比采用公式(4)计算得到:
其中ωj为特定采样率下啸叫易发生频点附近频段,当采样率为8khz时,一个典型的啸叫易发生频点为1.15khz,m一般为2。
步骤s46,将步骤s43的输出与步骤s45的输出取最小值作为输出幅值,同时保留原始回声消除输出e(ωk,t)相位,作为融合后的输出。当然,上述融合方法也可以取步骤s43的输出与步骤s45的输出的平均值作为输出幅值,或者与前一帧的估计值做一阶平滑后作为输出幅值。
步骤205,抑制近端信号中的噪声。
在步骤204的基础上,可以分频段对带噪信号进行掩蔽,进一步抑制噪声。需要注意的是,这里的噪声抑制一般需要通过近端语音信号的幅值或能量大小判断是否有人说话,从而决定是否更新噪声估计的能量或幅值。噪声幅值估计算法一般采用类似公式(5)的一阶平滑来实现。
其中n(ωk,t)为平滑后的噪声能量估计,
此时可以通过回声抑制单元中的滤波器更新步长进行辅助判断,回声抵消滤波器步长较小时,近端信号存在说话人概率较大,此时可以减小λ降低噪声更新速度;当回声抵消滤波器步长较大时,近端信号存在说话人概率较小,此时可以增加λ加快噪声更新速度。
步骤206,将经过噪声抑制后的语音经过反dft运算后输出。由于反det运算采用的是现有技术,在此不予赘述。
通过上述步骤,能够对全双工通话中的回声,残余回声,啸叫以及噪声进行抑制,能够以比较低的复杂度解决语音对讲中的回声,啸叫以及噪声等问题。
图4为本发明一种语音信号处理装置的系统结构图。如图4所示,本发明一种语音信号处理装置,包括:
信号采集与处理单元40,用于接收解码后的远端信号将其存放至缓冲区内,并于播放解码后的远端信号的同时采集近端信号,估计并补偿延迟,对远端及近端信号进行数据对齐操作。在本发明中,被扬声器播放的远端信号经过机壳、墙壁等反射后变成回声信号和本地语言信号以及环境噪声一起也被麦克风采集,通称为近端信号。
由于声音传输以及数据接收到播放的延迟等原因,此时麦克风采集到的回声信号与接收的远端信号之间存在延迟,因此在回声抵消之前需要估计并补偿延迟,达到数据对齐的目的,在本发明具体实施例中,延迟可以通过标定预先设置,也可以通过在线实时估计的方法得到,后者可以通过计算当前帧近端信号与缓冲区中最近几帧的远端信号的相似度来实现。
第一dft运算单元41,用于对对齐的近端信号进行离散傅立叶dft变换送入回声抑制单元43。
第二dft运算单元42,用于对对齐的远端信号进行离散傅立叶dft变换送入回声抑制单元43。
具体地,dft运算单元用于将输入信号从时域变换至频域,假设远端信号已经进行过延迟补偿操作,当前语音帧为第t帧,t≥l,分别对近端和远端信号的数据加窗后进行离散傅立叶(dft)正变换,变换后的频域结果分别表示为d(ωk,t)和x(ωk,t),其中
带反馈的自适应回声抑制单元43,用于抑制近端信号中的回声,并根据输出与远端信号的相关性自适应地调整滤波器更新步长。具体地,将上述第一dft运算单元31与第二dft运算单元42的频域结果输入带反馈的自适应回声抑制单元以抑制近端信号中的回声,其输出记为e(ωk,t),所述回声抑制单元43可以利用频域自适应滤波算法实现,如归一化最小均方自适应滤波器nlms,根据输出与远端信号的相关性自适应地调整滤波器更新步长。
残余回声与啸叫抑制单元44,以所述带反馈的自适应回声抑制单元43的输出作为输入,对可能存在啸叫的频段进行检测,进而决定抑制的幅度,同时对残余回声进行抑制。
具体地,如图5所示,残余回声与啸叫抑制单元44进一步包括:
残余回声相似度计算单元441,用于计算不同频段下带反馈的自适应回声抑制单元43的输出与最近l帧远端信号的相似度。也就是说,残余回声相似度计算单元441从缓存单元15中得到前l帧远端信号并分别计算与其输入信号的相似度,在本发明具体实施例中,相似度可以采用跨功率谱相关密度或其它近似算法实现。
残余回声估计单元442,于得到回声输出信号在各频带下与最近l帧远端信号的相似度后,根据获得的相似度以及最近l帧远端信号加权得到残余回声估计。具体地,残余回声估计单元442将相似度映射为权重并分配给缓存单元15中得到的前l帧远端信号,加权平均后得到残余回声估计。
第一抑制单元443,将当前帧的回声抑制单元输出减去残余回声估计得到第一抑制单元443的输出。
啸叫相似度计算单元444,用于计算当前帧的回声抑制单元输出在特定频段下和啸叫信号的相似度;
第二抑制单元445,用于将相似度映射为幅值调整因子,并调整特定频段幅度,得到第二抑制单元445的输出。
融合输出单元446,用于将第一抑制单元443、第二抑制单元445的输出取最小值作为输出幅值,同时保留原始回声消除输出相位,作为融合后的输出。当然,上述融合方法也可以取第一抑制单元443的输出与第一抑制单元443的输出的平均值作为输出幅值,或者与前一帧的估计值做一阶平滑后作为输出幅值。
噪声抑制单元45,用于在残余回声与啸叫抑制单元44的输出基础上估计噪声,以抑制近端信号中的噪声。
在残余回声与啸叫抑制单元44的基础上,可以分频段对带噪信号进行掩蔽,进一步抑制噪声。需要注意的是,这里的噪声抑制一般需要通过近端语音信号的幅值或能量大小判断是否有人说话,从而决定是否更新噪声估计的能量或幅值。在本发明具体实施例中,可以通过带反馈的自适应回声抑制单元43中的滤波器更新步长辅助判定噪声估计平滑因子。
反dft运算单元36,用于将噪声抑制单元45输出的语音经过反dft运算后输出。由于反det运算采用的是现有技术,在此不予赘述。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 还没有人留言评论。精彩留言会获得点赞!