一种语音分离方法及装置与流程
本发明涉及一种语音处理方法及装置,更具体涉及一种语音分离方法及装置。
背景技术
在语音处理领域,通常会遇到对多人同时说话的语音信号进行语音分离处理,进而得到每个人的语音信号,如何获得更好的声源分离的效果,即分离后的其他说话人的残留语音更少。这一问题在学术上称为“鸡尾酒会问题”,是长久以来困扰人机语音交互应用的难题,迄今仍没有在实际环境中稳定可用的产品或者方案。
目前,常用的语音分离的算法主要包括:神经网络算法、最大熵算法、最小互信息算法、最大似然算法、独立分量分析算法、遗传算法、机器学习、基于麦克风阵列的波束形成算法等。
但是,由于现有算法的基础理论限制,导致现有算法普遍分离效果不理想,交叉信号残留较大。
技术实现要素:
本发明所要解决的技术问题在于提供了一种语音分离方法及装置,以解决现有技术中交叉信号残留较大的技术问题。
本发明是通过以下技术方案解决上述技术问题的:
本发明实施例提供了一种语音分离方法,所述方法包括:
获取各个信号通道的待分离语音数据,其中,所述待分离语音数据含有至少两个人同时说话时产生的语音数据;
针对每一预设的采样时刻,利用盲源分离算法对所述待分离语音数据进行分离处理,得到p个分离信号;
针对每一个分离信号,计算当前分离信号与所述p个分离信号中除所述当前分离信号之外的其他分离信号之间的交叉残留系数;并判断所述交叉残留系数是否小于第一预设阈值;
若否,利用回声消除算法对所有交叉残留系数不小于第一预设阈值的分离信号,进行回声消除处理,并将处理后的分离信号与所有交叉残留系数小于第一预设阈值的分离信号的集合作为目标分离信号;
若是,将所述分离信号作为目标分离信号。
可选的,所述盲源分离算法包括:非线性主分量分析、独立分量分析、神经网络算法、最大熵算法、最小互信息算法、最大似然算法中的一种或多个的组合。
可选的,所述利用盲源分离算法对所述待分离语音数据进行分离处理,包括:
针对各个所述待分离语音数据,利用npca准则建立针对所述待分离语音数据的代价函数
j(w)为第t时刻的分离矩阵的代价;e{.}为期望运算函数;x(t)为各个麦克风对应的信号通道所观测到的观测信号;w为分离矩阵;(.)t为转置运算;
对所述代价函数进行最小化处理,得到分离矩阵的迭代估计为:
w(t+1)=w(t)+θ*z(t)[xt(t)-zt(t)w(t)],其中,
w(t+1)为第t+1时刻的分离矩阵;w(t)为第t时刻的分离矩阵;θ为迭代步长,且
利用公式,w(t+1)=w(t)+θ*z(t)[xt(t)-zt(t)w(t)],迭代计算下一时刻的分离矩阵,直至所述分离矩阵收敛,得到各个待分离语音数据的目标分离矩阵;
利用公式,y(t)=wx(t),得到所述待分离语音数据的分离后的信号,其中,y(t)为当前观测信号的分离后的信号。
可选的,所述计算当前分离信号与所述p个分离信号中除所述当前分离信号之外的其他分离信号之间的交叉残留系数,包括:
利用公式,
可选的,所述利用回声消除算法对所有交叉残留系数不小于第一预设阈值的分离信号,进行回声消除处理,包括:
针对所有交叉残留系数不小于第一预设阈值的分离信号中的每一分离信号,将当前分离信号作近端信号;将交叉残留系数不小于第一预设阈值的分离信号中除所述当前分离信号之外的其他信号作为远端信号;
利用公式,
利用公式,
μ(n)为第n次迭代时的迭代步长;
利用公式,
利用公式,d(n)=v(n)+∑kwk(n)x(n-k),计算第n次迭代时的期望信号,其中,v(n)为近端信号;wk(n)为第n次迭代时第k个采样点对应的滤波器系数的理论值;x(n-k)为第n-k次迭代时的观测信号;
判断第n次迭代时的期望信号是否收敛,若是,返回执行所述将当前分离信号作近端信号的步骤;若否,将所述第n次迭代时的期望信号作为消除回声后的信号。
本发明实施例提供了一种语音分离装置,所述装置包括:
第一获取模块,用于获取各个信号通道的待分离语音数据,其中,所述待分离语音数据含有至少两个人同时说话时产生的语音数据;
第二获取模块,用于针对每一预设的采样时刻,利用盲源分离算法对所述待分离语音数据进行分离处理,得到p个分离信号;
计算模块,用于针对每一个分离信号,计算当前分离信号与所述p个分离信号中除所述当前分离信号之外的其他分离信号之间的交叉残留系数;并判断所述交叉残留系数是否小于第一预设阈值;
消除模块,用于在所述计算模块的计算结果为否的情况下,利用回声消除算法对所有交叉残留系数不小于第一预设阈值的分离信号,进行回声消除处理,并将处理后的分离信号与所有交叉残留系数小于第一预设阈值的分离信号的集合作为目标分离信号;
设置模块,用于在所述计算模块的计算结果为是的情况下,将所述分离信号作为目标分离信号。
可选的,所述盲源分离算法包括:非线性主分量分析、独立分量分析、神经网络算法、最大熵算法、最小互信息算法、最大似然算法中的一种或多个的组合。
可选的,所述第二获取模块,还用于:
针对各个所述待分离语音数据,利用npca准则建立针对所述待分离语音数据的代价函数
j(w)为第t时刻的分离矩阵的代价;e{.}为期望运算函数;x(t)为各个麦克风对应的信号通道所观测到的观测信号;w为分离矩阵;(.)t为转置运算;
对所述代价函数进行最小化处理,得到分离矩阵的迭代估计为:
w(t+1)=w(t)+θ*z(t)[xt(t)-zt(t)w(t)],其中,
w(t+1)为第t+1时刻的分离矩阵;w(t)为第t时刻的分离矩阵;θ为迭代步长,且
利用公式,w(t+1)=w(t)+θ*z(t)[xt(t)-zt(t)w(t)],迭代计算下一时刻的分离矩阵,直至所述分离矩阵收敛,得到各个待分离语音数据的目标分离矩阵;
利用公式,y(t)=wx(t),得到所述待分离语音数据的分离后的信号,其中,y(t)为当前观测信号的分离后的信号。
可选的,所述计算模块,还用于:
利用公式,
可选的,所述消除模块,还用于:
针对所有交叉残留系数不小于第一预设阈值的分离信号中的每一分离信号,将当前分离信号作近端信号;将交叉残留系数不小于第一预设阈值的分离信号中除所述当前分离信号之外的其他信号作为远端信号;
利用公式,
利用公式,
μ(n)为第n次迭代时的迭代步长;
利用公式,
利用公式,d(n)=v(n)+∑kwk(n)x(n-k),计算第n次迭代时的期望信号,其中,v(n)为近端信号;wk(n)为第n次迭代时第k个采样点对应的滤波器系数的理论值;x(n-k)为第n-k次迭代时的观测信号;
判断第n次迭代时的期望信号是否收敛,若是,返回执行所述将当前分离信号作近端信号的步骤;若否,将所述第n次迭代时的期望信号作为消除回声后的信号。
本发明相比现有技术具有以下优点:
应用本发明实施例,可以将分离后的信号中残留的交叉信号可以看作是其他声源的回声,再使用回声消除算法对各个分离信号进行回声消除处理,从而可以达到改善分离效果,进而降低目标信号中的交叉信号残留。
附图说明
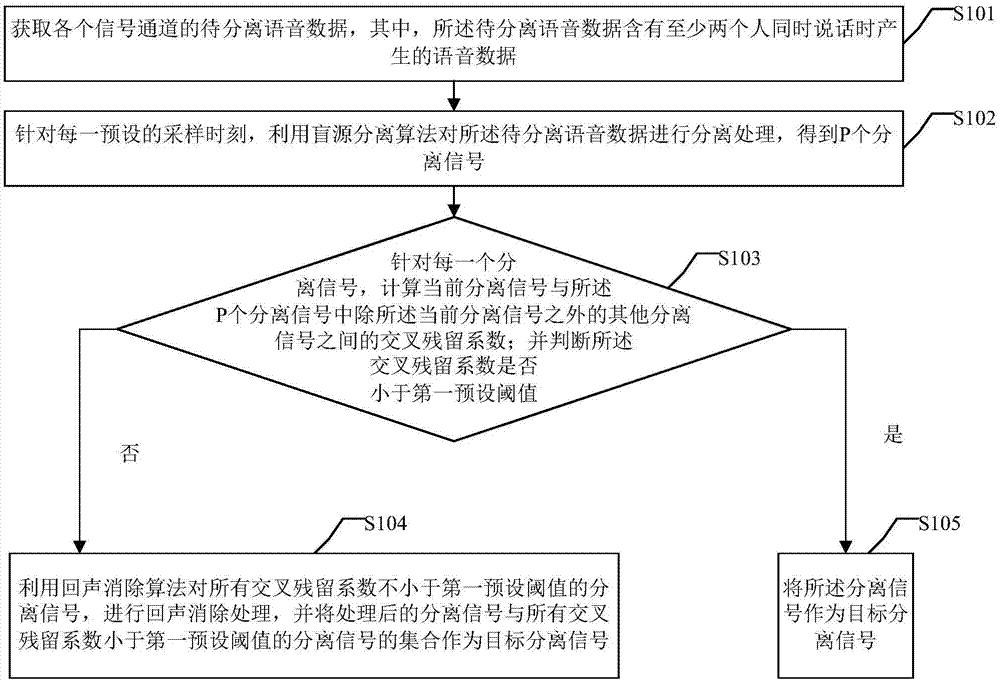
图1为本发明实施例提供的一种语音分离方法的流程示意图;
图2为本发明实施例提供的一种语音分离装置的结构示意图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
本发明实施例提供了一种语音分离方法及装置,下面首先就本发明实施例提供的一种语音分离方法进行介绍。
首先需要说明的是,本发明实施例具有广泛的应用场景,比如:(1)传统上对于公共场合的监控只有视频监控,无法做到声音监控,因为公共场合中可能存在多个说话人同时说话,另外还会存在各种环境噪声、背景音乐等。应用本发明实施例可以在安防监控领域实现语音和视频的同时监控。(2)目前业内出现了用于实时完成会议纪要的会议转写系统,从而高效地完成会议纪要的功能,但是这一系统对于出现多人同时发言(如果会议讨论过程中出现激烈争论时)的情况就会失效,现有的语音识别系统完全无法应对多说话人语音识别的场景。应用本发明实施例,可以应用于智能会议系统。(3)可以应用于通用的语音降噪场景,通过声源分离,保留有用户正常话音的通道,去掉没有正常话音的通道,即可实现语音降噪。
图1为本发明实施例提供的一种语音分离方法的流程示意图,如图1所示,所述方法包括:
s101:获取各个信号通道的待分离语音数据,其中,所述待分离语音数据含有至少两个人同时说话时产生的语音数据。
具体的,使用至少两个设置在不同位置的麦克风,获取两个,或者两个的人以上同时说话时的语音数据,其中一个麦克风获得一路待分离语音数据,例如,麦克风-1获取的待分离语音数据-1、麦克风-2获取的待分离语音数据-2、麦克风-3获取的待分离语音数据-4、麦克风-1获取的待分离语音数据-5。
可以理解的是,一路待分离语音数据即对应一个信号通道。
s102:针对每一预设的采样时刻,利用盲源分离算法对所述待分离语音数据进行分离处理,得到p个分离信号。
具体的,所述盲源分离算法包括:非线性主分量分析、独立分量分析、神经网络算法、最大熵算法、最小互信息算法、最大似然算法中的一种或多个的组合
具体的,以s101步骤中的各路待分离语音数据位输入,利用如下方法,可以得到每一个预设的采样时刻对应的p路分离信号。可以针对各个所述待分离语音数据,利用npca(nonlinearprinciplecomponentanalysis,非线性主分量分析)准则建立针对所述待分离语音数据的代价函数:
对所述代价函数进行最小化处理,得到分离矩阵的迭代估计为:
w(t+1)=w(t)+θ*z(t)[xt(t)-zt(t)w(t)],其中,
w(t+1)为第t+1时刻的分离矩阵;w(t)为第t时刻的分离矩阵;θ为迭代步长,且
利用公式,w(t+1)=w(t)+θ*z(t)[xt(t)-zt(t)w(t)],迭代计算下一时刻的分离矩阵,直至所述分离矩阵收敛,得到各个待分离语音数据的目标分离矩阵;
利用公式,y(t)=wx(t),得到所述待分离语音数据的分离后的信号,其中,y(t)为当前观测信号的分离后的信号。
例如,第1个采样时刻可以得到p路分离信号、第2个采样时刻可以得到p路分离信号、···、第n个采样时刻可以得到p路分离信号。
需要强调的是,前述观测信号是指,每一路的待分离语音数据。
s103:针对每一个分离信号,计算当前分离信号与所述p个分离信号中除所述当前分离信号之外的其他分离信号之间的交叉残留系数;并判断所述交叉残留系数是否小于第一预设阈值;若否,执行s104步骤;若是,执行s105步骤。
具体的,可以用si(n)表示得到的每一个分离信号,其中,i为该分离信号对应的信号通道序号,即麦克风的序号;n为每一个信号通道中的采样时刻的序号。发明人发现,在实际应用中,任何一个分离信号可以看作是同时刻的其他p-1路交叉残留信号混合而成的,因此,可以利用公式,
当交叉残留系数不小于第一预设阈值,如0.0125时,执行s104步骤;若交叉残留系数小于第一预设阈值,执行s105步骤。
在实际应用中,可以使用ti(n)表示需要进行回声消除处理的分离信号,其中,i为该分离信号对应的信号通道序号,即麦克风的序号;n为每一个信号通道中的采样时刻的序号,且i∈(1,2,...,q),q≤p。
s104:利用回声消除算法对所有交叉残留系数不小于第一预设阈值的分离信号,进行回声消除处理,并将处理后的分离信号与所有交叉残留系数小于第一预设阈值的分离信号的集合作为目标分离信号。
具体的,所述回声消除算法,包括:频域mdf算法。在实际应用中,依次将需要进行回声消除处理的分离信号ti(n)依次作为近端信号,其他的需要进行回声消除处理的分离信号作为远端信号,分别使用回声消除算法进行处理。
具体的,所述利用回声消除算法对所有交叉残留系数不小于第一预设阈值的分离信号,进行回声消除处理,包括:
针对所有交叉残留系数不小于第一预设阈值的分离信号中的每一分离信号,将当前分离信号作近端信号;将交叉残留系数不小于第一预设阈值的分离信号中除所述当前分离信号之外的其他信号作为远端信号;
利用公式,
利用公式,
μ(n)为第n次迭代时的迭代步长;
利用公式,
利用公式,d(n)=v(n)+∑kwk(n)x(n-k),计算第n次迭代时的期望信号,其中,v(n)为近端信号;wk(n)为第n次迭代时第k个采样点对应的滤波器系数的理论值;x(n-k)为第n-k次迭代时的观测信号;
判断第n次迭代时的期望信号是否收敛,若是,返回执行所述将当前分离信号作近端信号的步骤;若否,将所述第n次迭代时的期望信号作为消除回声后的信号。
将进行回声消除处理后的分离信号与所有交叉残留系数不小于第一预设阈值的分离信号,即不需要进行回声消除处理的分离信号的集合作为目标分离信号。
s105:将所述分离信号作为目标分离信号。
将交叉残留系数不小于第一预设阈值的分离信号,即不需要进行回声消除处理的分离信号的集合作为目标分离信号。
需要说明的是,针对第n+1时刻的p个分离信号也按照上述方法进行处理。最后得到了各个时刻的目标分离信号。
应用本发明图1所示实施例,可以将分离后的信号中残留的交叉信号可以看作是其他声源的回声,再使用回声消除算法对各个分离信号进行回声消除处理,从而可以达到改善分离效果,进而降低目标信号中的交叉信号残留。
另外,如果对盲源分离后的各分离信号全部采用回声消除进行后处理,又会带来极大的额外计算量,应用本发明实施例,可以有效判断哪些经盲源分离后的信号适合采用回声消除处理改善分离效果,进而有效提升整个系统的工作效率。
与本发明图1所示实施例相对应,本发明实施例还提供了一种语音分离装置。
图2为本发明实施例提供的一种语音分离装置的结构示意图,如图2所示,所述装置包括:
第一获取模块201,用于获取各个信号通道的待分离语音数据,其中,所述待分离语音数据含有至少两个人同时说话时产生的语音数据;
第二获取模块202,用于针对每一预设的采样时刻,利用盲源分离算法对所述待分离语音数据进行分离处理,得到p个分离信号;
计算模块203,用于针对每一个分离信号,计算当前分离信号与所述p个分离信号中除所述当前分离信号之外的其他分离信号之间的交叉残留系数;并判断所述交叉残留系数是否小于第一预设阈值;
消除模块204,用于在所述计算模块的计算结果为否的情况下,利用回声消除算法对所有交叉残留系数不小于第一预设阈值的分离信号,进行回声消除处理,并将处理后的分离信号与所有交叉残留系数小于第一预设阈值的分离信号的集合作为目标分离信号;
设置模块205,用于在所述计算模块的计算结果为是的情况下,将所述分离信号作为目标分离信号。
应用本发明图2所示实施例,可以将分离后的信号中残留的交叉信号可以看作是其他声源的回声,再使用回声消除算法对各个分离信号进行回声消除处理,从而可以达到改善分离效果,进而降低目标信号中的交叉信号残留。
在本发明实施例的一种具体实施方式中,所述盲源分离算法包括:非线性主分量分析、独立分量分析、神经网络算法、最大熵算法、最小互信息算法、最大似然算法中的一种或多个的组合。
在本发明实施例的一种具体实施方式中,所述第二获取模块202,还用于:
针对各个所述待分离语音数据,利用npca准则建立针对所述待分离语音数据的代价函数
j(w)为第t时刻的分离矩阵的代价;e{.}为期望运算函数;x(t)为各个麦克风对应的信号通道所观测到的观测信号;w为分离矩阵;(.)t为转置运算;
对所述代价函数进行最小化处理,得到分离矩阵的迭代估计为:
w(t+1)=w(t)+θ*z(t)[xt(t)-zt(t)w(t)],其中,
w(t+1)为第t+1时刻的分离矩阵;w(t)为第t时刻的分离矩阵;θ为迭代步长,且
利用公式,w(t+1)=w(t)+θ*z(t)[xt(t)-zt(t)w(t)],迭代计算下一时刻的分离矩阵,直至所述分离矩阵收敛,得到各个待分离语音数据的目标分离矩阵;
利用公式,y(t)=wx(t),得到所述待分离语音数据的分离后的信号,其中,y(t)为当前观测信号的分离后的信号。
在本发明实施例的一种具体实施方式中,所述计算模块203,还用于:
利用公式,
在本发明实施例的一种具体实施方式中,所述消除模块204,还用于:
针对所有交叉残留系数不小于第一预设阈值的分离信号中的每一分离信号,将当前分离信号作近端信号;将交叉残留系数不小于第一预设阈值的分离信号中除所述当前分离信号之外的其他信号作为远端信号;
利用公式,
利用公式,
μ(n)为第n次迭代时的迭代步长;
利用公式,
利用公式,d(n)=v(n)+∑kwk(n)x(n-k),计算第n次迭代时的期望信号,其中,v(n)为近端信号;wk(n)为第n次迭代时第k个采样点对应的滤波器系数的理论值;x(n-k)为第n-k次迭代时的观测信号;
判断第n次迭代时的期望信号是否收敛,若是,返回执行所述将当前分离信号作近端信号的步骤;若否,将所述第n次迭代时的期望信号作为消除回声后的信号。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!