一种基于说话人语音特征的语音端点检测方法与流程
本发明涉及语音信息处理和模式识别技术领域,特别涉及一种基于说话人语音特征的语音端点检测方法。
背景技术
语音端点检测是语音分析、语音合成、语音编码、说话人识别中的一个重要环节。在语音识别和说话人识别中,通常是先根据一定的端点检测算法对语音信号中的有声段和无声段进行分割,再针对有声段,依据语音的某些特征进行识别。正确有效地语音端点检测可以减少计算量和缩短处理时间,而且能排除无声段的噪声干扰、提高语音识别和说话人识别的正确率。常用的语音端点检测方法有短时平均能量法、短时平均过零率法和短时能零积值法。
在低信噪比的情况下,传统的基于阈值的语音端点检测受噪声的影响准确度较低,尤其在多说话人识别场景中,有时会出现不同说话人话语衔接较为紧密的情况,一般的语音端点检测(voiceactivitydetection,简称vad)检测出的有音段可能包含不同说话人,不易检测出不同说话人的语音段。
在多说话人的识别场景中,传统基于阈值的语音端点检测方法检测的有音段可能包含不同的说话人,这就会影响后期说话人识别的正确率,正确的语音端点检测是提高说话人识别正确率的关键因素;因此需要一种能够在多人说话的复杂场景下更准确的检测出语音端点的方法,从而提高后期多说话人识别的准确率。
技术实现要素:
(一)要解决的技术问题
为了解决现有技术的上述问题,本发明提供一种基于说话人语音特征的语音端点检测方法。
(二)技术方案
为了达到上述目的,本发明采用的主要技术方案包括下步骤:
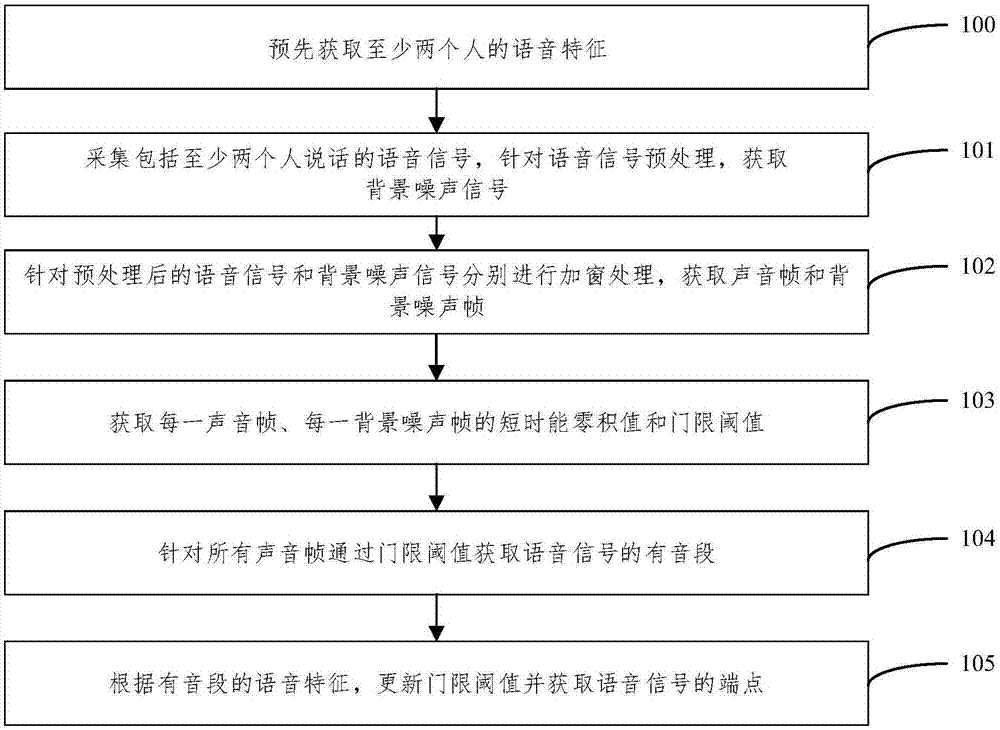
100、通过语音信息样本预先获取至少两个人的语音特征;
101、采集包括至少两个人说话的语音信号,针对语音信号预处理,将预处理后的语音信号的0-100ms作为背景噪声信号;
102、针对预处理后的语音信号和背景噪声信号分别进行加窗处理,获取与语音信号对应的至少两个声音帧和与背景噪声信号对应的至少一个背景噪声帧;
103、获取每一声音帧的短时能零积值、每一背景噪声帧的短时能零积值和门限阈值;
针对每一声音帧和每一背景噪声帧分别通过下述公式(1)和公式(2)获取平均能量en和短时平均过零率zn;
公式中的n表示窗口的长度,sw(k)表示加窗语音信号;
其中,短时能零积值为平均能量en和短时平均过零率zn的乘积;
门限阈值为所有背景噪声帧的短时能零积值的平均值与常数c相乘;
104、根据所有声音帧与语音信号的对应顺序,将第一个短时能零积值大于门限阈值的声音帧作为起始帧,将起始帧以后的声音帧中第一个短时能零积值小于门限阈值的声音帧作为终止帧;
起始帧到终止帧之间的所有声音帧为语音信号的有音段;
105、获取有音段中第一判断区的语音特征和第二判断区的语音特征,根据第一判断区的语音特征和第二判断区的语音特征更新门限阈值,获取语音信号的端点;
第一判断区为有音段的起始帧后至少一个声音帧,获取第一判断区的语音特征;
第二判断区为有音段的终止帧前至少一个声音帧,获取第二判断区的语音特征;
若第一判断区的语音特征和第二判断区的语音特征均与预先获取的至少两个人的语音特征中同一人的语音特征匹配,则将有音段的端点作为的语音信号的端点;
否则,将门限阈值增加预设值,更新门限阈值,并依据更新后的门限阈值执行步骤104获取更新后的有音段;
针对更新后的有音段执行步骤105获取对应的更新后的第一判断区和第二判断区,并进行语音特征的比较,重复更新预设次数,直至更新后的第一判断区和第二判断区均与预先获取的至少两个人的语音特征中的同一人的语音特征匹配,则将更新后的有音段的端点作为语音信号的端点。
可选地,语音信息样本包括:
至少两个语音信息且每一语音信息时长均在一分钟以上,所述每一语音信息均为不同人说话的语音信息;
获取每一语音信息的高斯混合模型,得到每一语音信息对应的语音特征。
可选地,预处理包括:
针对语音信号滤波,滤波的上限截止频率的为3400hz,下限截止频率为60~100hz。
可选地,加窗处理包括:
在步骤102中,针对语音信号根据公式(3)分成至少两个声音帧;
其中,公式(3)中的n表示窗口的长度。
可选地,
语音信号对应的每一声音帧的帧长为10ms~30ms,相邻声音帧之间的帧移为帧长的一半;
背景噪声信号对应的每一背景噪声帧的帧长为10ms,相邻背景噪声帧之间的帧移为帧长的一半。
可选地,
在步骤105中,第一判断区和第二判断区的时长均为1s-3s。
可选地,
在步骤105中,针对有音段的第一判断区和第一判断区获取高斯混合模型;第一判断区的高斯混合模型为第一判断区的语音特征;
第二判断区的高斯混合模型为第二判断区的语音特征。
可选地,
在步骤105中,重复更新预设次数为10次。
可选地,
在步骤105中,将门限阈值增加预设值的方法为将门限阈值增加更新前的门限阈值的5%。
(三)有益效果
本发明的有益效果是:
本发明方法在传统的语音端点检测的基础上结合说话人识别,在考虑了噪声影响的同时,还针对说话人的特征进行提取和对比,使得语音端点检测更为准确,从而使多说话人识别更为准确。
附图说明
图1为本发明一实施例提供的一种基于说话语音人特征的语音端点检测方法流程示意图;
图2(a)为本发明一实施例提供的说话人a发音“0”时域图;
图2(b)为本发明一实施例提供的说话人a发音“0”频谱图;
图2(c)为本发明一实施例提供的说话人b发音“0”时域图;
图2(d)为本发明一实施例提供的说话人b发音“0”频谱图;
图3(a)为本发明一实施例提供的说话人语音信号图;
图3(b)为本发明一实施例提供的说话人语音信号短时能零积图;
图3(c)为本发明一实施例提供的说话人语音信号短时能零积值法的语音端点检测结果;
图4为本发明一实施例提供的说话人识别原理框图;
图5为本发明一实施例提供的语音端点检测流程图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
具体实施例
如图1所示,本发明方法,包括以下步骤:
100、通过语音信息样本预先获取至少两个人的语音特征;
语音信息样本包括:至少两个语音信息且每一语音信息时长均在一分钟以上,所述每一语音信息均为不同人说话的语音信息;
获取每一语音信息的高斯混合模型,得到每一语音信息对应的语音特征。举例来说,在本实施例中以说话人a和说话人b为例具体地,预先采集说话人a和说话人b的语音信息,并获取说话人a和说话人b的语音信息的高斯混合模型,并以高斯混合模型作为语音特征;
如图2(a)和2(b)所示,分别为说话人a发音“0”时域图和频谱图;
如图2(c)和2(d)所示,分别为说话人b发音“0”时域图和频谱图;
特殊说明,在本实施例中,本发明不对注册语音信息的内容进行限定,本实施例仅用于举例说明。
101、采集包括至少两个人说话的语音信号,针对语音信号预处理,将预处理后的语音信号的0-100ms作为背景噪声信号;
举例来说,由于录音开始阶段往往有一段无音区,所以通常取最开始的100ms信号作为对背景噪声的分析;
进一步地,针对语音信号进行滤波;
举例来说,滤波的上限截止频率的为3400hz,下限截止频率为60~100hz。
102、针对预处理后的语音信号和背景噪声信号分别进行加窗处理,获取与语音信号对应的至少两个声音帧和与背景噪声信号对应的至少一个背景噪声帧;
举例来说,通常语音信号具有时变性和短时平稳性,因此通常将语音信号分成若干个声音帧,以便获取语音信号的特征参数,在本实施例中,通过在语音信号上加窗函数,其中窗函数选用汉明窗,汉明窗如下述公式(1)所示;
其中,公式(1)中的n表示窗口的长度;
举例来说,经过加窗处理后的语音信号对应的每一声音帧的帧长为10ms~30ms,相邻声音帧之间的帧移为帧长的一半。
经过加窗处理后的背景噪声信号对应的每一背景噪声帧的帧长为10ms,相邻背景噪声帧之间的帧移为帧长的一半。
103、获取每一声音帧的短时能零积值、每一背景噪声帧的短时能零积值和门限阈值;
针对每一声音帧和每一背景噪声帧分别通过下述公式(2)和公式(3)获取平均能量en和短时平均过零率zn;
公式中的n表示窗口的长度,sw(k)表示加窗语音信号;
其中,短时能零积值为平均能量en和短时平均过零率zn的乘积;
门限阈值为所有背景噪声帧的短时能零积值的平均值与常数c相乘,举例来说c依据经验值取1.2;
在本实施例中,由于在步骤102中进行了加窗处理,原本的语音信号转换成了相应的声音帧,因此在本实施例中将背景噪声以10m为一帧处理;
104、根据所有声音帧与语音信号的对应顺序,将第一个短时能零积值大于门限阈值的声音帧作为起始帧,将起始帧以后的声音帧中第一个短时能零积值小于门限阈值的声音帧作为终止帧;
起始帧到终止帧之间的所有声音帧作为语音信号的有音段;
举例来说,如图3(a)所示,本实施例采集了一段说话人的语音信号,3(b)示出了该说话人语音信号的短时能零积,图3(c)示出了利用短时能零积值法的语音端点检测结果图;
105、获取有音段中第一判断区的语音特征和第二判断区的语音特征,根据第一判断区的语音特征和第二判断区的语音特征更新门限阈值,获取语音信号的端点;
第一判断区为有音段的起始帧后至少一个声音帧,获取第一判断区的语音特征;
第二判断区为有音段的终止帧前至少一个声音帧,获取第二判断区的语音特征;
如图4所示,图4为示出了本实施例中利用说话人识别原理框图
具体地,举例来说其中,第一判断区为有音段的起始帧后的1s-3s对应的全部声音帧,并通过获取第一判断区的高斯混合模型获取第一判断区的语音特征;
第二判断区为有音段的终止帧前的1s-3s对应的多个声音帧,并通过获取第一判断区的高斯混合模型获取第一判断区的语音特征;
具体地,如图5所示,若第一判断区的语音特征和第二判断区的语音特征均与预先获取的至少两个人的语音特征中同一人的语音特征匹配,则将有音段的端点作为的语音信号的端点;
举例来说,第一判断区的语音特征与说话人a的语音特征匹配,第二判断区的语音特征也与说话人a的语音特征匹配时,则将有音段的端点作为的语音信号的端点;此处仅用于举例说明并不对预先获取的语音特征进行限定,相应的第一判断区的语音特征和第二判断区的语音特征也可以和说话人b的语音特征匹配。
否则,将门限阈值增加预设值,举例来说,将门限阈值增加预设值的方法为将门限阈值增加更新前的门限阈值的5%,更新门限阈值,并依据更新后的门限阈值执行步骤104获取更新后的有音段;
举例来说,第一判断区的语音特征与说话人a的语音特征匹配,第二判断区的语音特征也与说话人b的语音特征匹配时,则更新门限阈值,相应的依据更新后的门限阈值执获取更新后的有音段;
针对更新后的有音段执行步骤105获取对应的更新后的第一判断区和第二判断区,并进行语音特征的比较,重复更新预设次数,举例来说,设置重复更新的次数为10次,直至更新后的第一判断区和第二判断区均与预先获取的至少两个人的语音特征中的同一人的语音特征匹配,则将更新后的有音段的端点作为语音信号的端点。
本发明方法在传统的语音端点检测的基础上结合说话人识别,在考虑了噪声影响的同时,还针对说话人的特征进行提取和对比,使得语音端点检测更为准确,从而使多说话人识别更为准确。
最后应说明的是:以上所述的各实施例仅用于说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或全部技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!