编辑支援装置、编辑支援方法以及程序与流程
本发明的实施方式涉及编辑支援装置、编辑支援方法以及程序。
背景技术:
以往,已知将输入的声音变换为字符串的声音识别技术。一般,在声音识别处理中,进行以下的处理(1)~(4)。(1)根据输入的声音计算声响特征量。(2)使用声响模型,将声响特征量变换为子词(音素)。(3)使用发音词典,将子词变换为单词。(4)使用语言模型,决定单词之间的联系最准确的迁移序列。
技术实现要素:
然而,在以往的技术中,难以具体地掌握利用追加到发音词典的单词的声音识别结果的影响范围。
实施方式的编辑支援装置具备抽出部、推测部、以及输出控制部。抽出部根据追加到在声音识别中使用的词典的单词的读音及记载的至少一方,从说话声音集合抽出与所述单词关联的关联说话声音。推测部推测调整所述单词的识别难易度的权重、和在被设定所述权重的情况下推测从所述关联说话声音识别的推测识别结果。输出控制部根据设定的所述权重,控制所述推测识别结果的输出。
根据上述编辑支援装置,能够具体地掌握利用追加到发音词典的单词的声音识别结果的影响范围。
附图说明
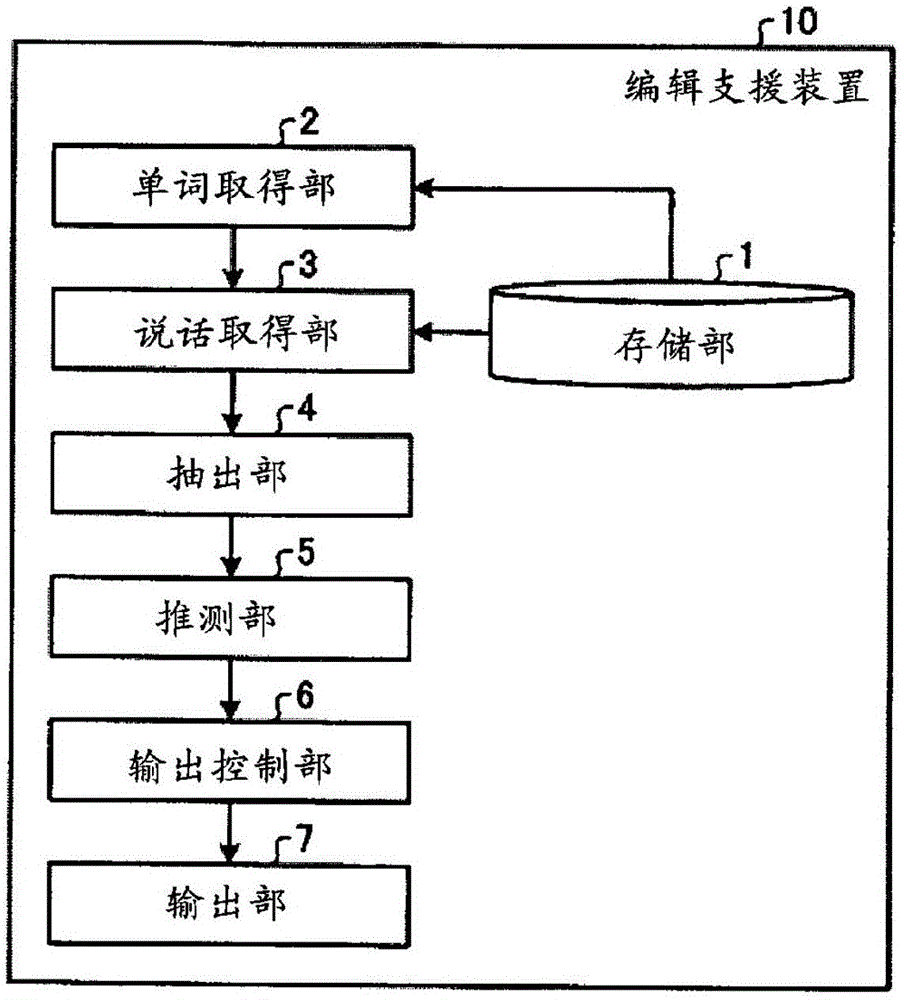
图1是示出第1实施方式的编辑支援装置的功能结构的例子的图。
图2a是示出第1实施方式的用户词典的例子(日语的情况)的图。
图2b是示出第1实施方式的用户词典的例子(英语的情况)的图。
图3a是示出第1实施方式的说话声音集合的例子(日语的情况)的图。
图3b是示出第1实施方式的说话声音集合的例子(英语的情况)的图。
图4a是示出第1实施方式的利用编辑距离的关联说话声音的抽出例(日语的情况)的图。
图4b是示出第1实施方式的利用编辑距离的关联说话声音的抽出例(英语的情况)的图。
图5a是示出第1实施方式的权重和推测识别结果的例子(日语的情况)的图。
图5b是示出第1实施方式的权重和推测识别结果的例子(英语的情况)的图。
图6a是示出第1实施方式的包括推测识别结果的输出信息的例子的图。
图6b是示出第1实施方式的包括推测识别结果的输出信息的例子的图。
图7是示出第1实施方式的编辑支援方法的例子的流程图。
图8是示出第2实施方式的编辑支援装置的功能结构的例子的图。
图9是示出第1实施方式的编辑支援装置的硬件结构的例子的图。
(附图标记说明)
1:存储部;2:单词取得部;3:说话取得部;4:抽出部;5:推测部;6:输出控制部;7:输出部;8:计算部;10:编辑支援装置;301:控制装置;302:主存储装置;303:辅助存储装置;304:显示装置;305:输入装置;306:通信装置;310:总线。
具体实施方式
以下,参照附图,详细说明编辑支援装置、编辑支援方法以及程序的实施方式。
(第1实施方式)
第1实施方式的编辑支援装置例如在能够编辑在声音识别中使用的词典的声音识别系统中使用。首先,说明第1实施方式的编辑支援装置的功能结构的例子。
[功能结构的例子]
图1是示出第1实施方式的编辑支援装置10的功能结构的例子的图。第1实施方式的编辑支援装置10具备存储部1、单词取得部2、说话取得部3、抽出部4、推测部5、输出控制部6以及输出部7。
存储部1存储信息。在存储部1中存储的信息是例如用户词典以及说话声音集合等。用户词典是能够由用户追加单词(追加单词)的词典(发音词典)。单词至少包括记载和读音。说话声音集合是说话数据的集合。说话数据包括至少说话声音。
图2a是示出第1实施方式的用户词典的例子(日语的情况)的图。第1实施方式的用户词典包括单词id、记载以及读音。单词id是识别单词的识别信息。记载是表示单词的字符、记号以及数字等。读音表示单词的发音。在图2a的例子中,例如,单词id为“1”的单词的记载是“(rdc)”,读音是“あーるでぃーしー”。此外,也可以如图2a所示,在单词的记载中,包括表示是例如部门名以及公司名等的()以及[]等。
图2b是示出第1实施方式的用户词典的例子(英语的情况)的图。第1实施方式的用户词典包括wordid(单词id)、surface(记载)以及phone(读音)。wordid是识别单词的识别信息。surface是表示单词的字符、记号以及数字等。phone表示单词的发音。在图2b的例子中,例如,wordid为“1”的单词的记载是“(rdc)”,读音是“aerdiisii”。
图3a是示出第1实施方式的说话声音集合的例子(日语的情况)的图。第1实施方式的说话声音集合是包括说话id、字符串信息以及说话声音的说话数据的集合。说话id是识别说话的识别信息。
字符串信息表示:在调整单词的识别难易度的权重被设定成初始值(既定值)的状态下,该单词被声音识别的情况下的说话声音的声音识别结果。在作为字符串信息,使用声音识别结果的情况下,有包含识别错误的情况。在声音识别结果中包含识别错误的情况下,例如通过变更表示正确的识别结果的单词的权重的设定,得到正确的声音识别结果。此外,字符串信息也可以通过人工写入说话声音来得到。
说话声音是表示说话的声音。在图3a的例子中,作为说话声音,关联了声音数据。此外,作为说话声音,也可以并非声音数据自身,而关联有识别该声音数据的识别信息。
例如,说话id为“1”的说话数据的字符串信息是“最初に、rdcの今年度の目標についてお話します。”,说话声音被存储为“声音数据-1”。说话id为“1”的说话数据是正确的声音识别结果的例子。
另外,例如,说话id为“2”的说话数据的字符串信息是“次に、rtcの来年度の目標についてです。”,说话声音被存储为“声音数据-2”。说话id为“2”的说话数据是包含错误的声音识别结果的例子。在说话声音中被发音为“rdc”的部位被错误地声音识别为“rtc”。
另外,例如,说话id为“3”的说话数据的字符串信息是“最後に、ある弟子の今後の予定についてお話します。”,说话声音被存储为“声音数据-3”。说话id为“3”的说话数据是包含错误的声音识别结果的例子。在说话声音中被发音为“rdc”的部位被错误地声音识别为“ある弟子”。日语的“ある弟子”的发音与“rdc”类似,所以存在产生这样的声音识别差错的可能性。
图3b是示出第1实施方式的说话声音集合的例子(英语的情况)的图。第1实施方式的说话声音集合是包括spid、string(字符串)以及speech(说话声音)的说话数据的集合。spid是识别说话的识别信息。
string表示:在调整单词的识别难易度的权重被设定成初始值(既定值)的状态下,该单词被声音识别的情况下的speech的声音识别结果。在作为string使用声音识别结果的情况下,有包含识别错误的情况。在声音识别结果中包含识别错误的情况下,例如通过变更表示正确的识别结果的单词的权重的设定,得到正确的声音识别结果。此外,string也可以通过人工写入speech来得到。
speech是表示说话的声音。在图3b的例子中,作为speech,关联有speechdata。此外,作为speech,也可以并非speechdata自身,而关联有识别该speechdata的识别信息。
例如,spid为“1”的说话数据的string是“first,ispeakaboutthetargetinthecurrentyearofrdc.”,speech被存储为“speechdata-1”。spid为“1”的说话数据是正确的声音识别结果的例子。
另外,例如,spid为“2”的说话数据的string是“next,itisaboutthetargetofthenextyearofrtc.”,speech被存储为“speechdata-2”。spid为“2”的说话数据是包含错误的声音识别结果的例子。在speech中,被发音为“rdc”的部位被错误地声音识别为“rtc”。
另外,例如,spid为“3”的说话数据的string是“finally,ispeakaboutthefuturescheduleofadc”,speech被存储为“speechdata-3”。spid为“3”的说话数据是包含错误的声音识别结果的例子。在speech中,被发音为“rdc”的部位被错误地声音识别为“dc”。
返回到图1,首先,单词取得部2从存储部1取得单词的记载和读音。接下来,说话取得部3从存储部1取得说话声音集合。
接下来,抽出部4根据追加到在声音识别中使用的词典的单词的读音及记载的至少一方,从说话声音集合抽出与该单词关联的关联说话声音。关联说话声音的抽出方法可以任意。利用例如声响上的特征量以及语言上的特征量等,抽出关联说话声音。
<利用声响上的特征量的情况>
例如,抽出部4利用单词的读音,从说话声音集合抽出关联说话声音。具体而言,首先,抽出部4取得在上述说话数据中包含的字符串信息的读音。
字符串信息的读音的取得方法可以任意。例如,也可以在存储部1中,作为说话声音的声音识别结果,不仅存储字符串信息,而且还存储包括表示该字符串信息的读音的音素列的说话声音集合。然后,抽出部4也可以取得通过对在说话声音集合中包含的说话声音进行声音识别而得到的音素列,将在该音素列中包括从单词的读音变换的音素列的一部分或者全部的说话声音,作为关联说话声音抽出。
此外,抽出部4也可以通过根据在说话数据中包含的字符串信息(参照图3a)推测该字符串信息的读音,取得该字符串信息的读音。
另外,例如,在抽出部4中,如果在说话数据中包含的字符串信息的读音、和单词的读音的编辑距离是阈值以下,则抽出与该字符串信息关联起来的说话声音,作为关联说话声音。在此,说明通过编辑距离的阈值判定抽出关联说话声音的例子。
图4a是示出第1实施方式的利用编辑距离的关联说话声音的抽出例(日语的情况)的图。图4a的例子示出与用户词典(参照图2a)的单词id为“1”的单词“(rdc)”关联的关联说话声音的抽出例。图4a的说话id与识别在说话声音集合(参照图3a)中存储的说话数据的说话id对应。读音表示在说话数据中包含的字符串信息的读音。
编辑距离在说话数据中包含的字符串信息的读音中包括与用户词典的单词的读音类似的类似部位的情况下,表示对该类似部位的读音进行几个字符的编辑时与该单词的读音一致。另外,编辑距离在说话数据中包含的字符串信息的读音中不包括与用户词典的单词的读音类似的类似部位的情况下,表示该字符串信息的长度(字符数)。
例如,在说话id为“1”的读音中包含的类似部位101a与单词“(rdc)”的读音一致,所以编辑距离成为“0”。另外,例如,在说话id为“2”的读音中包含的类似部位102a与单词“(rdc)”的读音相异1个字符,所以编辑距离成为“1”。另外,例如,在说话id为“3”的读音中包含的类似部位103a与单词“(rdc)”的读音相异4个字符,所以编辑距离成为“4”。更具体而言,在类似部位103a的情况下,相比于单词“(rdc)”的读音,4个字符量的读音不足,所以编辑距离成为“4”。
在说话id为“4”的说话数据中包含的字符串信息的读音不包括与单词“(rdc)”的读音类似的类似部位,所以编辑距离成为该字符串的字符数“26”。同样地,在说话id为“5”的说话数据中包含的字符串信息的读音不包括与单词“(rdc)”的读音类似的类似部位,所以编辑距离成为该字符串的字符数“28”。
在图4a的例子中,在例如编辑距离的阈值是5的情况下,作为单词“(rdc)”的关联说话声音,通过抽出部4抽出说话id为“1”~“3”的说话声音。
<利用语言上的特征量的情况>
另外,例如,抽出部4将通过对在说话声音集合中包含的说话声音进行声音识别而得到的声音识别结果中包括单词的记载的一部分或者全部的说话声音,作为关联说话声音抽出。在第1实施方式中,通过对说话声音进行声音识别而得到的声音识别结果是上述图3a的字符串信息。例如,抽出部4在单词id为“2”的“[总务]”的情况下,在说话id为“4”的字符串信息中包括“总务”,所以将说话id为“4”的说话声音作为关联说话声音抽出。
此外,也可以与利用上述声响上的特征量的情况同样地,抽出部4在与说话数据关联起来的字符串信息中包含的记载、和单词的记载的编辑距离是阈值以下的情况下,将与该字符串信息关联起来的说话声音作为关联说话声音抽出。
另外,抽出部4也可以计算基于上述声响上的特征量(单词的读音等)、和上述语言上的特征量(单词的记载等)这两方的关联度,根据该关联度抽出关联说话声音。关于关联度,使用例如基于上述单词的读音的编辑距离、以及基于上述单词的记载的编辑距离,用以下的式(1)的关联度r定义。在该情况下,抽出部4将关联度r是预先设定的阈值以上的说话声音作为关联说话声音抽出即可。
关联度r=α×r_phone+β×r_surface…(1)
在此,r_phone设为基于声响上的特征量(单词的读音等)的关联度,r_surface设为基于语言上的特征量(单词的记载等)的关联度,分别用以下的式(2)以及(3)定义。
r_phone=1/(2×基于声响上的特征量的编辑距离)…(2)
r_surface=1/(2×基于语言上的特征量的编辑距离)…(3)
例如,在基于声响上的特征量的编辑距离是1的情况下,r_phone=1/2。另外,例如,在基于语言上的特征量的编辑距离是2的情况下,r_surface=1/4。但是,在基于声响上的特征量的编辑距离是0的情况下,将r_phone设为1,同样地,在基于语言上的特征量的编辑距离是0的情况下,将r_surface设为1。
在此,上述式(1)的α、β是表示针对关联度r,分别对声响上的特征量和语言上的特征量造成何种程度的影响的值(0以上)。例如,在上述图3a的字符串信息是人工写入的字符串的情况下,相比于读音,记载正确的可能性更高,所以以相比于声响上的特征量,语言上的特征量向关联度r的影响更大的方式,设定α和β(α<β)。另一方面,在上述图3a的字符串信息是声音识别结果的情况下,相比于记载,读音(音素列)正确的可能性更高,所以以相比于语言上的特征量,声响上的特征量向关联度的影响更大的方式,设定α和β(α>β)。
图4b是示出第1实施方式的利用编辑距离(editdistance)的关联说话声音的抽出例(英语的情况)的图。图4b的例子示出与用户词典(参照图2b)的wordid为“1”的单词“(rdc)”关联的关联说话声音的抽出例。图4b的spid与识别在说话声音集合(参照图3b)中存储的说话数据的spid对应。读音表示在说话数据中包含的string的读音。
editdistance在说话数据中包含的string的读音中包括与用户词典的单词的读音类似的类似部位的情况下,表示对该类似部位的读音进行几个字符的编辑时与该单词的读音一致。另外,editdistance在说话数据中包含的string的读音中未包括与用户词典的单词的读音类似的类似部位的情况下,表示该string的长度(字符数)。
例如,在spid为“1”的读音中包含的类似部位101b与单词“(rdc)”的读音一致,所以editdistance成为“0”。另外,例如,在spid为“2”的读音中包含的类似部位102b与单词“(rdc)”的读音相异1个字符,所以editdistance成为“1”。另外,例如,在spid为“3”的读音中包含的类似部位103与单词“(rdc)”的读音相异3个字符,所以editdistance成为“3”。更具体而言,在类似部位103b的情况下,相比于单词“(rdc)”的读音,3个字符量的读音不足,所以editdistance成为“3”。
在spid为“4”的说话数据中包含的string的读音不包括与单词“(rdc)”的读音类似的类似部位,所以editdistance成为该字符串的字符数“50”。同样地,在spid为“5”的说话数据中包含的string的读音不包括与单词“(rdc)”的读音类似的类似部位,所以editdistance成为该字符串的字符数“48”。
在图4b的例子中,在例如editdistance的阈值是5的情况下,作为单词“(rdc)”的关联说话声音,通过抽出部4,抽出spid为“1”~“3”的说话声音。
<利用语言上的特征量的情况>
另外,例如,抽出部4将通过对在说话声音集合中包含的说话声音进行声音识别而得到的声音识别结果中包括单词的记载的一部分或者全部的说话声音,作为关联说话声音抽出。在第1实施方式中,通过对说话声音进行声音识别而得到的声音识别结果是上述图3b的string。例如,抽出部4在wordid为“2”的“[admindiv.]”的情况下,由于在spid为“4”的string中包括“[admindiv.]”的phone(参照图2b),所以将spid为“4”的说话声音作为关联说话声音抽出。
此外,也可以与上述利用声响上的特征量的情况同样地,抽出部4在与说话数据关联起来的string中包含的记载、和单词的记载的editdistance是阈值以下的情况下,将与该string关联起来的说话声音作为关联说话声音抽出。
返回到图1,推测部5推测调整单词的识别难易度的权重、和在被设定该权重的情况下推测从关联说话声音识别的推测识别结果。权重表示例如越大,越易于识别单词。
图5a是示出第1实施方式的权重和推测识别结果的例子(日语的情况)的图。图5a的例子是单词id为“1”的单词“(rdc)”的推测识别结果的例子。说话id为“1”的说话声音在权重的设定为“1”的情况下,表示单词“(rdc)”包含于推测识别结果。说话id为“2”的说话声音在权重的设定为“2”的情况下,表示单词“(rdc)”包含于推测识别结果。说话id为“3”的说话声音在权重的设定为“5”的情况下,表示单词“(rdc)”包含于推测识别结果。
图5b是示出第1实施方式的权重(weight)和推测识别结果(asr(automaticspeechrecognition)result)的例子(英语的情况)的图。图5b的例子是wordid为“1”的单词“(rdc)”的asrresult的例子。spid为“1”的说话声音在weight的设定为“1”的情况下,表示单词“(rdc)”包含于asrresult。spid为“2”的说话声音在weight的设定为“2”的情况下,表示单词“(rdc)”包含于asrresult。spid为“3”的说话声音在weight的设定为“5”的情况下,表示单词“(rdc)”包含于asrresult。
说明推测部5的具体的处理。在此,作为推测用于得到推测识别结果的权重的方法,说明利用声音识别处理的推测方法。首先,推测部5取得由抽出部4从说话声音集合抽出的关联说话声音。接下来,推测部5通过将权重设定为规定的初始值来进行关联说话声音的声音识别处理,取得声音识别结果。
接下来,推测部5判定在取得的声音识别结果中,是否包括识别对象的单词。推测部5在包括识别对象的单词的情况下,将声音识别结果作为推测识别结果,如上述图5a,与单词id、说话id以及权重一起存储。推测部5在未包括识别对象的单词的情况下,增加权重,再次进行声音识别处理,判定在声音识别结果中是否包括识别对象的单词。推测部5直至在声音识别结果中包括识别对象的单词、或者权重成为预先决定的范围外,反复进行声音识别处理。
此外,权重的初始值可任意。权重的初始值也可以是例如与推测识别结果关联起来而已经存储的权重的平均。通过将在推测识别结果中包括识别对象的单词的情况下的权重的平均设定为初始值,能够更高效地进行关联说话声音的声音识别处理。
另外,在声音识别结果中未包括识别对象的情况下的权重的增加量可任意。权重的增加量也可以根据例如单词的读音、和在说话声音的读音中包含的类似部位的编辑距离决定。推测部5也可以例如编辑距离越大,越增加权重的增加量。
返回到图1,输出控制部6根据由用户设定(指定)的权重,控制推测识别结果的输出。输出部7输出由输出控制部6输出的推测识别结果。输出部7由例如液晶显示器等来实现。
图6a是示出第1实施方式的包括推测识别结果的输出信息110a的例子的图。图6a的例子示出作为识别对象,选择单词“(rdc)”,权重的设定为“1”的情况。输出信息110a包括单词显示区域111、权重设定接口112以及关联说话显示区域113。关联说话显示区域113通过分隔线114,被分隔为上部的显示区域和下部的显示区域。
在单词显示区域111中,显示在用户词典(参照图2a)中存储的单词的记载、读音以及权重。权重显示当前对单词设定的设定值。
权重设定接口112是设定(指定)权重的接口。在图6a的例子中,权重设定接口112是能够在1~10的范围中设定权重的滑动条,通过该滑动条将权重设定为“1”。
此外,也可以与通过权重设定接口112设定权重连动地,变更在单词显示区域111中显示的权重的设定(实际的设定值)。另外,关于在单词显示区域111中显示的权重的设定(实际的设定值),也可以不与通过权重设定接口112设定权重连动,而用户用其他手段进行设定。
在比分隔线114更上部的显示区域中,显示包括单词“(rdc)”的推测识别结果。在图6a的例子中,通过权重设定接口112设定的权重为“1”,所以说话id为“1”的说话声音的推测识别结果显示于分隔线114的上部的显示区域。
另一方面,在比分隔线114更下部的显示区域中,显示不包括单词“(rdc)”的推测识别结果。在图6a的例子中,通过权重设定接口112设定的权重为“1”,所以说话id为“2”以及“3”的说话声音的推测识别结果显示于分隔线114的下部的显示区域。
此外,在作为利用权重设定接口112的权重设定的用户支援,以设定的权重进行了声音识别的情况下,也可以将显示包括识别对象的单词的推测识别结果的显示件数的区域设置到输出信息110a。
根据在单词显示区域111中选择出的单词、和在权重设定接口112中设定(指定)的权重,变更在关联说话显示区域113中显示的信息。例如,通过将利用权重设定接口112的权重设定设定为“2”以上,在关联说话显示区域113中显示的类似部位115a被显示为单词“(rdc)”(参照图6b)。
图6b是示出第1实施方式的包括推测识别结果的输出信息110b的例子的图。图6b的例子示出作为识别对象,选择单词“(rdc)”,权重的设定为“2”的情况。输出信息110b包括单词显示区域111、权重设定接口112以及关联说话显示区域113。关联说话显示区域113通过分隔线114,被分隔为上部的显示区域和下部的显示区域。
单词显示区域111的说明与图6a相同,因此省略。
权重设定接口112是设定权重的接口。在图6b的例子中,权重设定接口112是能够在1~10的范围内设定权重的滑动条,通过该滑动条将权重设定为“2”。
在比分隔线114更上部的显示区域中,显示包括单词“(rdc)”的推测识别结果。在图6b的例子中,通过权重设定接口112设定的权重为“2”,所以说话id为“1”以及“2”的说话声音的推测识别结果显示于分隔线114的上部的显示区域。特别,说话id为“2”的说话声音的类似部位115a(参照图6a)被变更为识别为单词“(rdc)”的部位115b。另外,说话id为“2”的说话声音的推测识别结果的显示位置从分隔线114的下部的显示区域被变更为上部的显示区域。
另一方面,在比分隔线114更下部的显示区域中,显示不包括单词“(rdc)”的推测识别结果。在图6b的例子中,通过权重设定接口112设定的权重为“2”,所以说话id为“3”的说话声音的推测识别结果显示于分隔线114的下部的显示区域。
此外,在图6b的例子中,还示出在作为利用权重设定接口112的权重设定的用户支援,以设定的权重进行了声音识别时,显示包括识别对象的单词的推测识别结果的显示件数的情况下的例子。在图6b的例子中,在权重设定接口112的下部,设置有显示包括识别对象的单词的推测识别结果的显示件数的区域。在图6b的例子中,示出在例如单词“(rdc)”的权重被设定为5的情况下,包括单词“(rdc)”的推测识别结果的显示件数是20件。
在此,说明能够进行上述图6a的输出信息110a、以及上述图6b的输出信息110b的输出控制的输出控制部6的具体的动作例。输出控制部6在由用户选择单词显示区域111的单词,并用权重设定接口112设定权重时,进行以下的处理。
首先,输出控制部6取得调整由用户选择的单词的识别难易度的权重、在被设定该权重的情况下推测从关联说话声音识别的推测识别结果、以及作为该推测识别结果的识别源数据的说话声音的说话id的组(参照图5a)。接下来,输出控制部6比较由用户设定的权重、和与取得的推测识别结果关联起来的权重。
输出控制部6在由用户设定的权重是与取得的推测识别结果关联起来的权重以上的情况下,作为包括由用户选择的单词的推测识别结果(第1推测识别结果),将该推测识别结果(参照图5a)显示于关联说话显示区域113的比分隔线114更上部的显示区域。
另一方面,输出控制部6在由用户设定的权重小于与取得的推测识别结果关联起来的权重的情况下,作为不包括由用户选择的单词的推测识别结果(第2推测识别结果),将与取得的说话id关联起来的字符串信息(参照图3a)显示于关联说话显示区域113的比分隔线114更下部的显示区域。
接下来,参照流程图,说明第1实施方式的编辑支援方法的例子。
[编辑支援方法]
图7是示出第1实施方式的编辑支援方法的例子的流程图。首先,单词取得部2从存储部1取得单词的记载和读音(步骤s1)。接下来,说话取得部3从存储部1取得说话声音集合(步骤s2)。
接下来,抽出部4根据通过步骤s1的处理取得的单词的记载以及读音的至少一方,从通过步骤s2的处理取得的说话声音集合抽出与该单词关联的关联说话声音(步骤s3)。
接下来,推测部5推测调整单词的识别难易度的权重、和在被设定该权重的情况下推测从关联说话声音识别的推测识别结果(步骤s4)。
接下来,输出控制部6根据由用户设定(指定)的权重,控制推测识别结果的输出(步骤s5)。
如以上说明,在第1实施方式的编辑支援装置10中,抽出部4根据追加到在声音识别中使用的词典(在第1实施方式中是用户词典)的单词的读音以及记载的至少一方,从说话声音集合抽出与该单词关联的关联说话声音。推测部5推测调整单词的识别难易度的权重、和在被设定该权重的情况下推测从关联说话声音识别的推测识别结果。然后,输出控制部6根据被设定的权重,控制推测识别结果的输出。
由此,根据第1实施方式的编辑支援装置10,能够具体地掌握追加到词典的单词所起到的声音识别结果的影响范围。例如,追加到词典的单词还有对声音识别的结果造成恶劣影响的可能性,但根据第1实施方式的编辑支援装置10,能够在改变调整单词的识别难易度的权重的同时,具体地掌握追加到词典的单词对声音识别的结果造成的影响。由此,例如用户能够高效地编辑用户词典,在声音识别时能够低成本地取得用户期望的识别结果。
(第2实施方式)
接下来,说明第2实施方式。在第2实施方式的说明中,省略与第1实施方式同样的说明,说明与第1实施方式不同的部位。
[功能结构的例子]
图8是示出第2实施方式的编辑支援装置10-2的功能结构的例子的图。第2实施方式的编辑支援装置10-2具备存储部1、单词取得部2、说话取得部3、抽出部4、推测部5、输出控制部6-2、输出部7以及计算部8。即,第2实施方式的编辑支援装置10-2是在第1实施方式的编辑支援装置10的结构中还追加有计算部8。另外,在第2实施方式的编辑支援装置10-2中,输出控制部6-2的动作从第1实施方式的动作进行了变更。
计算部8根据已经由用户设定(决定)的单词的权重,计算尚未由用户设定权重的单词的权重的推荐值。具体而言,首先,计算部8通过下述式(4),计算基于用户的识别容许值。
(识别容许值)=(包括识别对象的单词的声音识别结果的数量)/(识别对象的单词的关联说话声音的数量)…(4)
在此,说明识别容许值的具体例。例如,单词id为“1”的单词“(rdc)”的关联说话声音的数量是3个(参照图4a)。此时,在由用户将单词“(rdc)”的权重设定为例如“2”时,包括单词“(rdc)”的声音识别结果(第1推测识别结果)的数量成为2个(参照图5a以及6b)。因此,单词“(rdc)”的识别容许值(第1识别容许值)成为2/3。
接下来,计算部8计算作为已经设定了权重的单词(第1单词)的识别容许值的平均值的平均识别容许值。然后,计算部8根据平均识别容许值,计算尚未由用户设定权重的单词(第2单词)的权重的推荐值。具体而言,计算部8根据尚未设定权重的单词的识别容许值(第2识别容许值)成为平均识别容许值以上的权重,计算该单词的权重的推荐值。
输出控制部6-2将在例如上述单词显示区域111中包括由计算部8计算出的推荐值的输出信息110a(110b)输出到输出部7。此外,输出信息110a(110b)也可以包括将由计算部8计算出的推荐值一并地设定为尚未设定权重的单词的权重的按钮等用户接口等。
如以上说明,在第2实施方式的编辑支援装置10-2中,输出控制部6-2将由计算部8计算出的推荐值输出到输出部7。由此,根据第2实施方式的编辑支援装置10-2,能够得到与第1实施方式同样的效果,并且用户能够更高效地设定追加到在声音识别中使用的词典的单词的权重。即,根据第2实施方式的编辑支援装置10-2,用户能够比以往更容易(更低成本)地得到期望的声音识别结果。
最后,说明第1实施方式的编辑支援装置10的硬件结构的例子。此外,第2实施方式的编辑支援装置10-2的硬件结构的例子的说明也与第1实施方式的编辑支援装置10的硬件结构的说明相同。
[硬件结构的例子]
图9是示出第1实施方式的编辑支援装置10的硬件结构的例子的图。第1实施方式的编辑支援装置10具备控制装置301、主存储装置302、辅助存储装置303、显示装置304、输入装置305以及通信装置306。控制装置301、主存储装置302、辅助存储装置303、显示装置304、输入装置305以及通信装置306经由总线310连接。
控制装置301执行从辅助存储装置303读出到主存储装置302的程序。控制装置301是例如cpu等1个以上的处理器。主存储装置302是rom(readonlymemory,只读存储器)、以及ram(randomaccessmemory,随机存取存储器)等存储器。辅助存储装置303是存储卡、以及hdd(harddiskdrive,硬盘驱动器)等。
显示装置304显示信息。显示装置304是例如液晶显示器。上述输出部7通过例如显示装置304实现。输入装置305受理信息的输入。输入装置305是例如键盘以及鼠标等。此外,显示装置304以及输入装置305也可以是兼具显示功能和输入功能的液晶触摸面板等。通信装置306与其他装置进行通信。
将由第1实施方式的编辑支援装置10执行的程序,以可安装的形式或者可执行的形式的文件,存储到cd-rom、存储卡、cd-r、以及dvd(digitalversatiledisk,数字多功能盘)等可由计算机读取的存储介质,作为计算机程序产品提供。
另外,也可以构成为通过将由第1实施方式的编辑支援装置10执行的程序储存到与因特网等网络连接的计算机上,并经由网络下载来提供。另外,也可以构成为不下载而经由因特网等网络提供第1实施方式的编辑支援装置10执行的程序。
另外,也可以构成为将由第1实施方式的编辑支援装置10执行的程序预先嵌入到rom等来提供。
由第1实施方式的编辑支援装置10执行的程序成为第1实施方式的编辑支援装置10的功能结构中的、包括能够通过程序实现的功能的模块结构。
关于通过程序实现的功能,通过控制装置301从辅助存储装置303等存储介质读出并执行程序,将利用程序实现的功能装载到主存储装置302。即,在主存储装置302上生成利用程序实现的功能。
此外,也可以通过ic(integratedcircuit,集成电路)等硬件,实现第1实施方式的编辑支援装置10的功能的一部分。ic是执行例如专用的处理的处理器。
另外,在使用多个处理器实现各功能的情况下,各处理器既可以实现各功能中的1个,也可以实现各功能中的2个以上。
另外,第1实施方式的编辑支援装置10的动作方式可任意。也可以使第1实施方式的编辑支援装置10作为例如网络上的云系统动作。
虽然说明了本发明的几个实施方式,但这些实施方式仅为例示,未意图限定发明的范围。这些新的实施方式能够以其他各种方式实施,能够在不脱离发明的要旨的范围内,进行各种省略、置换、变更。这些实施方式、其变形包含于发明的范围、要旨,并且包含于与权利要求书记载的发明和其均等的范围。
此外,能够将上述实施方式总结为以下的技术方案。
技术方案1.一种编辑支援装置,具备:
抽出部,根据追加到在声音识别中使用的词典的单词的读音及记载的至少一方,从说话声音集合抽出与所述单词关联的关联说话声音;
推测部,推测调整所述单词的识别难易度的权重、和在被设定所述权重的情况下推测出从所述关联说话声音识别的推测识别结果;以及
输出控制部,根据被设定的所述权重,控制所述推测识别结果的输出。
技术方案2.根据技术方案1所述的编辑支援装置,其中,
所述抽出部取得通过对在所述说话声音集合中包含的说话声音进行声音识别而得到的音素列,抽出在所述音素列中包括从所述单词的读音变换的音素列的一部分或者全部的说话声音,作为关联说话声音。
技术方案3.根据技术方案1所述的编辑支援装置,其中,
所述抽出部抽出通过对在所述说话声音集合中包含的说话声音进行声音识别而得到的声音识别结果中包括所述单词的记载的一部分或者全部的说话声音,作为关联说话声音。
技术方案4.根据技术方案1所述的编辑支援装置,其中,
所述输出控制部通过将区分包括所述单词的第1推测识别结果、和不包括所述单词的第2推测识别结果的输出信息输出到输出部,控制所述推测识别结果的输出。
技术方案5.根据技术方案4所述的编辑支援装置,其中,
还具备计算部,该计算部根据已经由用户设定的第1单词的权重,计算尚未由用户设定权重的第2单词的权重的推荐值,
所述输出控制部还控制所述推荐值的输出。
技术方案6.根据技术方案5所述的编辑支援装置,其中,
所述计算部关于所述第1单词,计算将所述第1推测识别结果的数量除以所述关联说话声音的数量而得到的第1识别容许值,计算所述第2单词的第2识别容许值成为所述第1识别容许值的平均值以上的权重,作为所述第2单词的权重的推荐值。
技术方案7.一种编辑支援方法,包括:
根据追加到在声音识别中使用的词典的单词的读音及记载的至少一方,从说话声音集合抽出与所述单词关联的关联说话声音的步骤;
推测调整所述单词的识别难易度的权重、和在被设定所述权重的情况下推测出从所述关联说话声音识别的推测识别结果的步骤;以及
根据被设定的所述权重,控制所述推测识别结果的输出的步骤。
技术方案8.一种存储介质,存储有用于使计算机作为如下部件发挥功能的程序:
抽出部,根据追加到在声音识别中使用的词典的单词的读音及记载的至少一方,从说话声音集合抽出与所述单词关联的关联说话声音;
推测部,推测调整所述单词的识别难易度的权重、和在被设定所述权重的情况下推测出从所述关联说话声音识别的推测识别结果;以及
输出控制部,根据被设定的所述权重,控制所述推测识别结果的输出。
- 还没有人留言评论。精彩留言会获得点赞!