语音识别处理方法、装置、系统及车辆与流程
本发明涉及语音技术领域,尤其涉及一种语音识别处理方法、装置、系统及车辆。
背景技术:
目前市场上可供车载使用的语音识别平台越来越多,科大讯飞、百度、腾讯、云之声等几十家公司均可提供语音识别平台。不同公司提供的语音识别平台的识别率、识别效率、能够对接的系统各有不同。而作为车辆厂商,通常只能够通过供应商的描述对不同的语音识别平台进行主观评估,无法对不同的语音识别平台进行全面、客观的评估。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明的第一个目的在于提出一种语音识别处理方法,分析比较被测试方云平台对语音数据的语音识别结果和语音识别参数,生成测试结果,根据测试结果,可全面、客观的对被测试方云平台进行评估;同时,根据测试结果还可对被测试方云平台的平台参数进行优化调整。
本发明的第二个目的在于提出一种语音识别处理装置。
本发明的第三个目的在于提出一种语音识别处理系统。
本发明的第四个目的在于提出一种车辆。
为达上述目的,本发明第一方面实施例提出了一种语音识别处理方法,包括:
获取不同录音条件下不同用户的语音数据;
将所述语音数据输入至被测试方云平台;
获取所述被测试方云平台对所述语音数据的语音识别结果和语音识别参数;
对所述语音识别结果和所述语音识别参数进行分析比较,生成测试结果;
根据测试结果对所述被测试方云平台的平台参数进行优化调整,并返回执行所述将所述语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。
根据本发明实施例提出的语音识别处理方法,获取不同录音条件下不同用户的语音数据;将语音数据输入至被测试方云平台;获取被测试方云平台对语音数据的语音识别结果和语音识别参数;对语音识别结果和语音识别参数进行分析比较,生成测试结果;根据测试结果对被测试方云平台的平台参数进行优化调整,并返回执行将语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。根据测试结果,可全面、客观的对被测试方云平台进行评估;同时,根据测试结果还可对被测试方云平台的平台参数进行优化调整。
根据本发明的一个实施例,所述录音条件包括以下条件中的任意一种或多种的组合:语音内容、性别、车速、路段情报、口令和车型。
根据本发明的一个实施例,所述语音识别参数包括以下参数中的任意一种或多种的组合:启动时间、识别时间、cpu使用率和内存使用率。
根据本发明的一个实施例,所述测试结果包括功能测试结果和/或性能测试结果。
根据本发明的一个实施例,所述功能测试结果包括以下结果中的任意一种或多种的组合:对话能力、功能维度、记忆能力和学习能力;所述性能测试结果包括以下结果中的任意一种或多种的组合:识别率、识别速度、启动速度、内存消耗和cpu消耗。
根据本发明的一个实施例,该语音识别处理方法还包括:根据优化后的语音识别结果,确定出用户偏好;根据所述用户偏好向所述用户推送对应的内容数据。
根据本发明的一个实施例,所述内容数据包括以下数据中的任意一种或多种的组合:指令数据、语音数据和画面表示数据。
为达上述目的,本发明第二方面实施例提出了一种语音识别处理装置,包括:
第一获取模块,用于获取不同录音条件下不同用户的语音数据;
输入模块,用于将所述语音数据输入至被测试方云平台;
第二获取模块,用于获取所述被测试方云平台对所述语音数据的语音识别结果和语音识别参数;
生成模块,用于对所述语音识别结果和所述语音识别参数进行分析比较,生成测试结果;
调整模块,用于根据测试结果对所述被测试方云平台的平台参数进行优化调整,并触发所述输入模块重新执行所述将所述语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。
根据本发明实施例提出的语音识别处理装置,获取不同录音条件下不同用户的语音数据;将语音数据输入至被测试方云平台;获取被测试方云平台对语音数据的语音识别结果和语音识别参数;对语音识别结果和语音识别参数进行分析比较,生成测试结果;根据测试结果对被测试方云平台的平台参数进行优化调整,并返回执行将语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。根据测试结果,可全面、客观的对被测试方云平台进行评估;同时,根据测试结果还可对被测试方云平台的平台参数进行优化调整。
为达上述目的,本发明第三方面实施例提出了一种语音识别处理系统,包括:车机录音设备和如本发明第二方面实施例所述的语音识别处理装置;所述语音识别处理装置通过所述车机录音设备获取所述语音数据。
为达上述目的,本发明第四方面实施例提出了一种车辆,包括:如本发明第三方面实施例所述的语音识别处理系统。
附图说明
图1是根据本发明一个实施例的语音识别处理方法的流程图;
图2是根据本发明一个实施例的获取语音数据的原理图;
图3是根据本发明一个实施例的语音识别处理方法的系统工作原理图;
图4是根据本发明另一个实施例的语音识别处理方法的流程图;
图5是根据本发明另一个实施例的语音识别处理方法的系统工作原理图;
图6是根据本发明一个实施例的语音识别处理装置的结构图;
图7是根据本发明一个实施例的语音识别处理系统的结构图;
图8是根据本发明一个实施例的车辆的结构图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面结合附图来描述本发明实施例的语音识别处理方法、装置、系统及车辆。
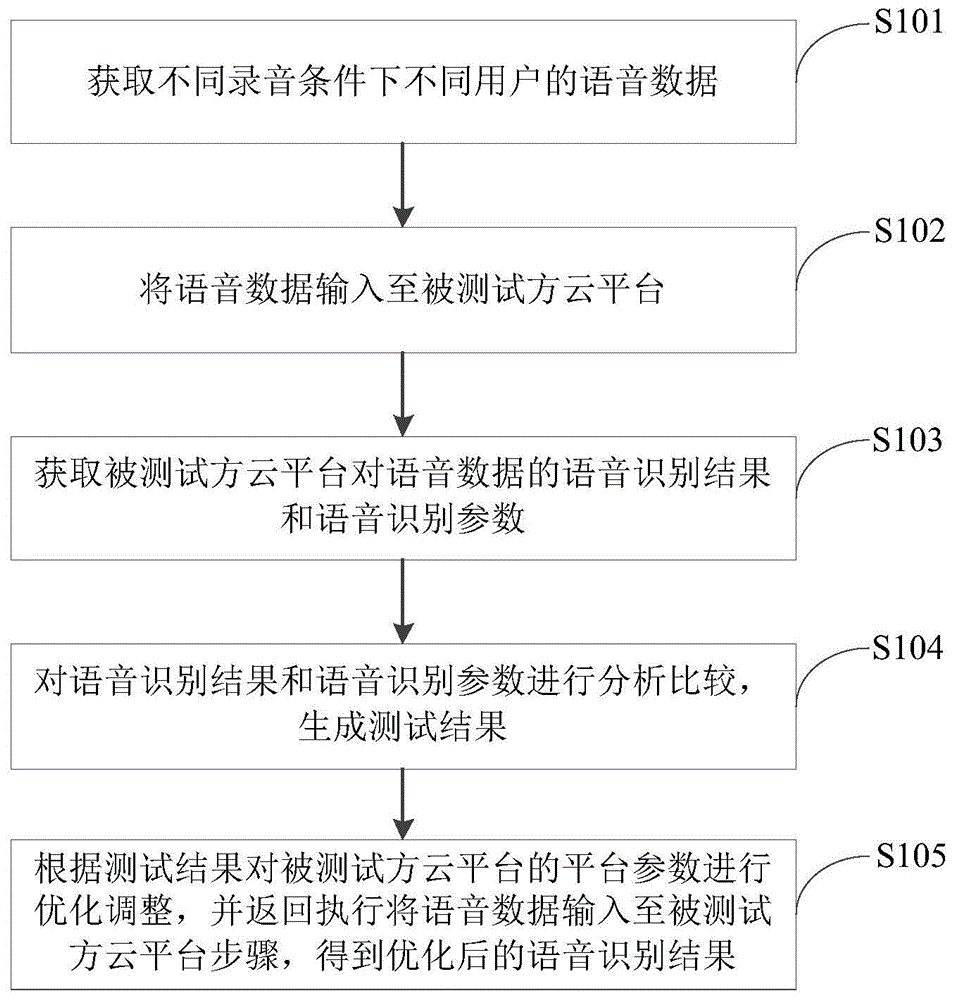
图1是根据本发明一个实施例的语音识别处理方法的流程图,如图1所示,该方法包括:
s101,获取不同录音条件下不同用户的语音数据。
本发明实施例中,可通过车机录音设备,例如麦克风等,获取不同录音条件下不同用户的语音数据。其中,录音条件可包括语音内容、性别、车速、路段情报、口令和车型中任意一种或多种的组合。
具体的,可如图2所示,语音数据可为语音数据库形式,根据录音条件、录音方法及语音模板生成。其中,录音方法即录音采用的方式,例如,采用实际车机麦克风进行录音,并采用同样的平台对录音进行去噪去回声处理;语音模板即输入文本,例如与功能控制或聊天等相关的文本。
s102,将语音数据输入至被测试方云平台。
本发明实施例中,将语音数据输入至被测试方云平台。具体的,可如图3所示,通过测试平台中的语音输入输出控制接口将语音数据输入至被测试方云平台。
s103,获取被测试方云平台对语音数据的语音识别结果和语音识别参数。
本发明实施例中,获取被测试方云平台对语音数据的语音识别结果和语音识别参数,具体的,可通过如图3所示的识别结果取得接口获取。其中,语音识别参数包括以下参数中的任意一种或多种的组合:启动时间、识别时间、cpu使用率和内存使用率。cpu使用率和内存使用率可通过如图3所示的测试平台中的第三方软件开发工具包(softwaredevelopmentkit,简称sdk)计算得到。
s104,对语音识别结果和语音识别参数进行分析比较,生成测试结果。
本发明实施例中,对语音识别结果和语音识别参数进行分析比较,生成测试结果。其中,测试结果可包括功能测试结果和/或性能测试结果,功能测试结果又可包括以下结果中的任意一种或多种的组合:对话能力、功能维度、记忆能力和学习能力;性能测试结果又可包括以下结果中的任意一种或多种的组合:识别率、识别速度、启动速度、内存消耗和cpu消耗。
s105,根据测试结果对被测试方云平台的平台参数进行优化调整,并返回执行将语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。
本发明实施例中,根据测试结果对被测试方云平台的平台参数进行优化调整,并返回步骤s102执行将语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。例如,当测试结果中的某个词条的识别率较低时,对被测试方云平台的平台参数进行优化调整,以提高该词条的识别率。
根据本发明实施例提出的语音识别处理方法,获取不同录音条件下不同用户的语音数据;将语音数据输入至被测试方云平台;获取被测试方云平台对语音数据的语音识别结果和语音识别参数;对语音识别结果和语音识别参数进行分析比较,生成测试结果;根据测试结果对被测试方云平台的平台参数进行优化调整,并返回执行将语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。根据测试结果,可全面、客观的对被测试方云平台进行评估;同时,根据测试结果还可对被测试方云平台的平台参数进行优化调整。
进一步的,如图4所示,图4是根据本发明另一个实施例的语音识别处理方法的流程图,该方法还可包括:
s201,根据优化后的语音识别结果,确定出用户偏好。
本发明实施例中,根据优化后的语音识别结果,确定出用户偏好。
s202,根据用户偏好向用户推送对应的内容数据。
本发明实施例中,根据用户偏好向用户推送对应的内容数据。其中,内容数据包括以下数据中的任意一种或多种的组合:指令数据、语音数据和画面表示数据。
具体的,可如图5所示,统一第三方云平台,并且加入车辆厂商内部云平台,车辆厂商内部云平台可收集并存储用户偏好,车辆厂商内部云平台从车机获取车辆情报及录音数据,并上传至第三方云平台,获取识别结果,根据识别结果及用户偏好,推送对应的内容数据至车机。同时,还可不对车机做任何修改的前提下,自动切换识别引擎公司提供的算法,降低研发成本。
根据本发明实施例提出的语音识别处理方法,可根据优化后的语音识别结果,确定出用户偏好,并根据用户偏好向用户推送对应的内容数据。
图6是根据本发明一个实施例的语音识别处理装置的结构图,如图6所示,该装置包括:
第一获取模块21,用于获取不同录音条件下不同用户的语音数据;
输入模块22,用于将语音数据输入至被测试方云平台;
第二获取模块23,用于获取被测试方云平台对语音数据的语音识别结果和语音识别参数;
生成模块24,用于对语音识别结果和语音识别参数进行分析比较,生成测试结果;
调整模块25,用于根据测试结果对被测试方云平台的平台参数进行优化调整,并触发输入模块22重新执行将语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。
需要说明的是,前述对语音识别处理方法实施例的解释说明也适用于该实施例的语音识别处理装置,此处不再赘述。
根据本发明实施例提出的语音识别处理装置,获取不同录音条件下不同用户的语音数据;将语音数据输入至被测试方云平台;获取被测试方云平台对语音数据的语音识别结果和语音识别参数;对语音识别结果和语音识别参数进行分析比较,生成测试结果;根据测试结果对被测试方云平台的平台参数进行优化调整,并返回执行将语音数据输入至被测试方云平台步骤,得到优化后的语音识别结果。根据测试结果,可全面、客观的对被测试方云平台进行评估;同时,根据测试结果还可对被测试方云平台的平台参数进行优化调整。
为了实现上述实施例,本发明实施例还提出一种语音识别处理系统30,如图7所示,包括:车机录音设备31和如上述实施例所示的语音识别处理装置32。
为了实现上述实施例,本发明实施例还提出一种车辆33,如图8所示,包括:如上述实施例所示的语音识别处理系统30。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!