一种基于神经网络模型的会议终端语音降噪方法与流程
本发明涉及语音处理和通信技术领域,尤其涉及一种基于神经网络模型的会议终端语音降噪方法。
背景技术
语音降噪技术是指将带噪的音频信号中去掉噪声部分,拥有广泛的应用,如应用在移动终端、会议终端设备。语音降噪技术的研究,由来已久,单声道语音降噪是非常具有挑战性的课题。只用一个麦克风进行语音降噪,不仅可以降低设备成本,而且在实际的使用中更加方便。
现有技术中是以原始的幅度谱作为神经网络的输入,输入节点过多导致计算量偏大,影响实时语音通讯,需要对幅度谱进一步压缩。以幅度谱增益为神经网络的输出,输出节点越多,计算量越大,由于人耳对信号的感知特性,通过频谱分段,提取特征,减小输出节点数,然后由神经网络的输出增益差值扩展得到整个幅度谱增益。输出节点越少,计算量越小,但同时导致差值扩展时误差越大,尤其是当信噪比较低时,一些较弱的语音信号会明显抑制导致声音断续。
技术实现要素:
本发明要解决的技术问题,在于提供一种基于神经网络模型的会议终端语音降噪方法,通过会议终端设备的单麦克风采集音频信号源,提取音频特征,通过神经网络强大的特征学习能力,生成降噪的语音信号特征,加上原始语音信号的相位信息,通过傅里叶逆变换还原成语音信号,发送给接收端,达到实时降噪的目的。
本发明的问题是这样实现的:
一种基于神经网络模型的会议终端语音降噪方法,包括如下步骤:
步骤1、会议终端设备对音频文件进行采集,生成时域的数字音频信号,该时域的数字音频信号混有语音信号和噪声信号;
步骤2、将该时域的数字音频信号分帧并进行短时傅里叶变换后由时域转到频域;
步骤3、根据人的听觉特性,将频域的幅度谱映射到频带中,进而求其梅尔倒谱系数;
步骤4、利用梅尔倒谱系数计算出一阶差分系数以及二阶差分系数,在每个频带上计算出基音相关系数,再提取时域的数字音频信号的基音周期特征和vad特征,将梅尔倒谱系数、一阶差分系数、二阶差分系数、基音相关系数、基音周期特征和vad特征作为音频的输入特征参数;
步骤5、将音频的输入特征参数作为神经网络模型的输入,将一阶差分系数、二阶差分系数、基音相关系数、基音周期特征和vad特征用来离线训练神经网络,使其学习到生成降噪语音的频带增益,训练好的权重固化出来,供每次算法调用;
步骤6、使用具有长短期记忆的神经网络模型学习后产生频带增益并输出,将输出的频带增益通过线性插值的方式映射到频谱,并得到频谱上每个频点的增益,再加上时域的数字音频信号的相位信息,通过傅里叶逆变换,最终还原成降噪后的语音信号。
进一步地,所述步骤2具体为:
将该时域的数字音频信号进行分帧,设置每10ms为一帧,共n帧,n为正整数;在第1帧前面设置第0帧作为补偿帧,在第n帧后面设置第n+1帧作为补偿帧,从第1帧开始至第n帧每次处理当前帧和前一帧共20ms的数字音频信号,相邻帧之间具有10ms的重叠,从第1帧至第n帧的每一帧都进行短时傅里叶变换处理两次以加强算法的可靠性,第1帧至第n帧都处理完毕后就完成了由时域的数字音频信号到频域的数字音频信号的转变。
进一步地,所述步骤3具体为:
使用梅尔尺度模拟人耳对频带的非线性感知,从低频到高频这一段频带内按临界带宽的大小由密到稀安排一组带通滤波器,每个带通滤波器对输入的频域的数字音频信号进行滤波;将每个带通滤波器输出的信号能量作为频域的数字音频信号的基本特征,对该基本特征计算其梅尔倒谱系数。
进一步地,所述步骤4中利用梅尔倒谱系数计算出一阶差分系数以及二阶差分系数,具体为:
一阶差分系数的计算可以采用公式(1):
公式(1)中,dt表示第t个一阶差分系数;ct表示第t个梅尔倒谱系数;ct+1表示第t+1个梅尔倒谱系数;ct-1表示第t-1个梅尔倒谱系数;ct-k表示第t-k个梅尔倒谱系数;q表示梅尔倒谱系数的阶数,取1;k表示一阶导数的时间差;k表示求和公式的一个遍历值;
二阶差分系数的计算可以采用公式(2):
公式(2)中,nt表示第t个二阶差分系数;dt表示第t个一阶差分系数;dt+1表示第t+1个一阶差分系数;dt-1表示第t-1个一阶差分系数;dt-k表示第t-k个一阶差分系数;q表示梅尔倒谱系数的阶数,取2;k表示二阶导数的时间差;k表示求和公式的一个遍历值。
进一步地,所述步骤5中将一阶差分系数、二阶差分系数、基音相关系数、基音周期特征和vad特征用来离线训练神经网络,使其学习到生成降噪语音的频带增益,训练好的权重固化出来,供每次算法调用具体为:
在神经网络模型的训练阶段,采用大量的语音文件和噪声文件,其中包括90个不同的人的发声的语音文件以及28个常见的噪声文件,结合一阶差分系数、二阶差分系数、基音相关系数、基音周期特征和vad特征通过混合方式产生数千小时的训练集,通过神经网络的前向传播,输出预测值,比较预测值与正确值计算出误差,将误差反向传播调整神经网络的权重和偏置,最终神经网络达到全局最优解,神经网络模型训练完成;
在神经网络模型的测试阶段,只需把神经网络模型中的权重固化出来,每次计算的时候调用即可完成输出。
进一步地,所述步骤6之后还包括:
步骤7、对降噪后的语音信号进行vad检测,当检测到当前信号为语音信号时,结合当前信噪比修正幅度谱增益,减小对弱语音信号的抑制,信噪比越大,幅度谱增益系数越大,信噪比即当前信号幅度与噪声幅度的比值;当检测到当前信号为非语音信号时,更新噪声幅度为:n(n)=a*n(n-1)+(1-a)*x(n),其中n(n)为噪声幅度,x(n)为当前信号幅度,a为衰减系数。
本发明的优点在于:通过神经网络模型的强大的特征学习能力,对音频特征进行学习,回归训练出降噪语音的音频特征,另外通过提取高级语义表达的音频特征,进一步减少了神经网络的计算量,保证了该算法的实时性。
附图说明
下面参照附图结合实施例对本发明作进一步的说明。
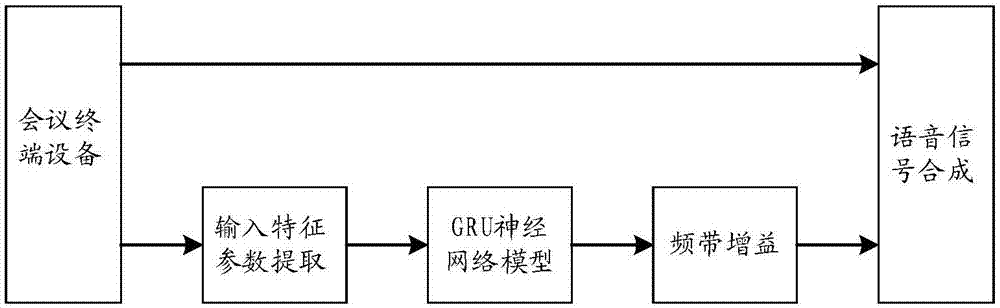
图1为本发明一种基于神经网络的会议终端语音降噪方法的执行流程图。
图2为本发明的神经网络模型框架图。
具体实施方式
为使得本发明更明显易懂,现以一优选实施例,并配合附图作详细说明如下。
如图1所示,本发明的一种基于神经网络模型的会议终端语音降噪方法,包括如下步骤:
步骤1、一个单麦克风的会议终端设备对音频文件进行采集,生成时域的数字音频信号,该时域的数字音频信号混有语音信号和噪声信号;
步骤2、将该时域的数字音频信号分帧并进行短时傅里叶变换后由时域转到频域;具体为:
将该时域的数字音频信号进行分帧,设置每10ms为一帧,共n帧,n为正整数;在第1帧前面设置第0帧作为补偿帧,在第n帧后面设置第n+1帧作为补偿帧,从第1帧开始至第n帧每次处理当前帧和前一帧共20ms的数字音频信号,相邻帧之间具有10ms的重叠,从第1帧至第n帧的每一帧都进行短时傅里叶变换处理两次以加强算法的可靠性,第1帧至第n帧都处理完毕后就完成了由时域的数字音频信号到频域的数字音频信号的转变;
步骤3、根据人的听觉特性,将频域的幅度谱映射到频带中,进而求其梅尔倒谱系数;具体为:
使用梅尔尺度模拟人耳对频带的非线性感知,从低频到高频这一段频带内按临界带宽的大小由密到稀安排一组带通滤波器,每个带通滤波器对输入的频域的数字音频信号进行滤波;将每个带通滤波器输出的信号能量作为频域的数字音频信号的基本特征,对该基本特征计算其梅尔倒谱系数(mfcc);上述带通滤波器一般取22个左右,但是实验过程中发现取22个频带,信噪比低下,导致部分语音信息被压制,损伤音质,据此,本发明取40个频带,采用40个带通滤波器(可选范围35-40个),40个带通滤波器产生40个梅尔倒谱系数,压缩输入信息的同时减少了对音质的影响;
在语音识别(speechrecognition)和话者识别(speakerrecognition)方面,最常用到的语音特征就是梅尔倒谱系数(mel-scalefrequencycepstralcoefficients,简称mfcc)。根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度。从200hz到5000hz的语音信号对语音的清晰度影响对大。两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,这种现象称为掩蔽效应。由于频率较低的声音在内耳蜗基底膜上行波传递的距离大于频率较高的声音,故一般来说,低音容易掩蔽高音,而高音掩蔽低音较困难。在低频处的声音掩蔽的临界带宽较高频要小。所以,人们从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波。将每个带通滤波器输出的信号能量作为信号的基本特征,对此特征经过进一步处理后就可以作为语音的输入特征。由于这种特征不依赖于信号的性质,对输入信号不做任何的假设和限制,又利用了听觉模型的研究成果。因此,这种参数比基于声道模型的lpcc相比具有更好的鲁邦性,更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。
步骤4、利用梅尔倒谱系数计算出一阶差分系数以及二阶差分系数,在每个频带上计算出基音相关系数,并计算离散傅里叶变化,取前6个基音相关系数;再提取时域的数字音频信号的基音周期特征和vad特征,将梅尔倒谱系数、一阶差分系数、二阶差分系数、基音相关系数、基音周期特征和vad特征作为音频的输入特征参数;由于标准的梅尔倒谱系数mfcc只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述,把动、静态特征结合起来能有效提高系统的识别性能。一阶差分系数和二阶差分系数的计算采用下面的公式,其中,一阶差分系数的计算可以采用公式(1):
公式(1)中,dt表示第t个一阶差分系数;ct表示第t个梅尔倒谱系数;ct+1表示第t+1个梅尔倒谱系数;ct-1表示第t-1个梅尔倒谱系数;ct-k表示第t-k个梅尔倒谱系数;q表示梅尔倒谱系数的阶数,取1;k表示一阶导数的时间差;k表示求和公式的一个遍历值;
二阶差分系数的计算可以采用公式(2):
公式(2)中,nt表示第t个二阶差分系数;dt表示第t个一阶差分系数;dt+1表示第t+1个一阶差分系数;dt-1表示第t-1个一阶差分系数;dt-k表示第t-k个一阶差分系数;q表示梅尔倒谱系数的阶数,取2;k表示二阶导数的时间差;k表示求和公式的一个遍历值;
根据人耳对频带的敏感度,选取前10个一阶差分系数和前10个二阶差分系数;
步骤5、将音频的输入特征参数作为神经网络模型的输入(将40个梅尔倒谱系数、10个一阶差分系数、10个二阶差分系数、6个基音相关系数、1个基音周期特征和1个vad特征,总用68个输入特征参数输入到神经网络模型中),将10个一阶差分系数、10个二阶差分系数、6个基音相关系数、1个基音周期特征和1个vad特征用来离线训练神经网络,使其学习到生成降噪语音的频带增益,训练好的权重固化出来,供每次算法调用;
在神经网络模型的训练阶段,采用大量的语音文件和噪声文件,其中包括90个不同的人的发声的语音文件以及28个常见的噪声文件,结合一阶差分系数、二阶差分系数、基音相关系数、基音周期特征和vad特征通过混合方式产生数千小时的训练集,通过神经网络的前向传播,输出预测值,比较预测值与正确值计算出误差,将误差反向传播调整神经网络的权重和偏置,最终神经网络达到全局最优解,神经网络模型训练完成;
在神经网络模型的测试阶段,只需把神经网络模型中的权重固化出来,每次计算的时候调用即可完成输出;
步骤6、使用具有长短期记忆的神经网络模型学习后产生40个频带增益(频带增益和梅尔倒谱系数个数相同)并输出,将输出的频带增益通过线性插值的方式映射到整个频谱,并得到频谱上每个频点的增益,再加上时域的数字音频信号的相位信息,通过傅里叶逆变换,最终还原成降噪后的语音信号;
步骤7、在语音通讯中,语音的完整性比噪声更重要,当有语音时,优先保证语音完整性。对降噪后的语音信号进行vad检测,基于vad检测,当检测到当前信号为语音信号时,结合当前信噪比修正幅度谱增益,减小对弱语音信号的抑制,信噪比越大,幅度谱增益系数越大,信噪比即当前信号幅度与噪声幅度的比值;在实际应用中,一般噪声不会突变,可通过vad检测,粗略计算噪声幅度,当检测到当前信号为非语音信号时,更新噪声幅度为:n(n)=a*n(n-1)+(1-a)*x(n),其中n(n)为噪声幅度,x(n)为当前信号幅度,a为衰减系数。
本发明中的神经网络模型采用的是gru门控递归网络,该神经网络中加入了时间这一维度信息,可以有效的利用和学习过去帧中的信息,与传统的rnn相比,gru引入了重置门和更新门,有效的缓解了训练过程中的梯度消失或是梯度爆炸的问题。具体地,gru的计算公式如下所示:
zt=σ(wz·[ht-1,xt])
rt=σ(wr·[ht-1,xt])
其中,rt为重置门,用于控制前一时刻隐藏层单元ht-1对当前输入xt的影响,如果ht-1对xt不重要,即从当前输入xt开始表述了新的意思,与上文无关,那么rt开关可以打开,使得ht-1对xt不产生影响。更新门zt:zt用于决定是否忽略当前输入xt。zt可以判断当前输入xt对整体意思的表达是否重要。当zt开关接通时,我们将忽略当前词xt,同时构成了从ht-1到ht的“短路连接”。
具体地,本发明的神经网络模型结构如图2所示,神经网络模型包括3个gru门控递归网络层,每层的神经元个数分别如图2所示。
在神经网络模型的训练阶段,采用大量的语音文件和噪声文件,其中包括90个不同的人的发声的语音文件以及28个常见的噪声文件,结合一阶差分系数、二阶差分系数、基音相关系数、基音周期特征和vad特征通过混合方式产生数千小时的训练集,通过神经网络的前向传播,输出预测值,比较预测值与正确值计算出误差,将误差反向传播调整神经网络的权重和偏置,最终神经网络达到全局最优解,神经网络模型训练完成;
在神经网络模型的测试阶段,只需把神经网络模型中的权重固化出来,每次计算的时候调用即可完成输出。
具体地,从带噪音频特征估计频带增益,用频带增益来达到抑制噪声,保留语音。具体步骤:从上述提取的带噪音频特征,作为神经网络模型的输入,神经网络模型学习并回归出频带增益,通过频带增益映射到频谱,加上原始的带噪语音信号的相位信息,合成降噪后的语音信号。
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!