基于语音识别的人工智能学习方法与流程
本发明涉及语音识别技术及文本分析与匹配的技术领域,更具体地,涉及基于语音识别的人工智能学习方法。
背景技术:
如何通过多媒体技术和人工智能技术丰富学习学习交互模式并提高学员学习的效率和积极性,是目前学习工作的一项重要任务。
面对丰富而又深邃的学习知识,仅仅通过“眼”和“手”进行学习,很难深刻记忆并理解知识内涵和文化精神。自然语言处理技术是一种通过机器学习算法将自然语言转变为机器能够理解的知识形态,也是人机语音交互的核心技术。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供基于语音识别的人工智能学习方法,本发明通过终端的收音设备、语音识别技术、文本分析以及后台知识库的匹配技术,实现学习者能与终端进行友好的、有效的互动,提升学习的趣味性、有效性和能动性。本发明在学习领域,实现了学员与学习系统双向互动,解决传统学习工作中学习效率低下、学习过程没有反馈问题,从本质上提高学员自主学习的积极性;语音交互降低了用户的使用门槛,亦可提升用户个人的使用效率。
本发明的技术方案是:基于语音识别的人工智能学习方法,其中,包括语音输入模块,语音识别模块,智能问答模块和学习系统输出模块;包括以下步骤:
s1.用户面对学习终端以语音的形式输入问题,终端的收音设备得到实时音频数据;
s2.通过音频特征提取器,对原始语音进行预处理,特征提取等操作;
s3.利用语音识别技术将音频转化为文本;
s4.对文本进行语义分析并将其发送至智能学习知识库模块进行答案匹配,同时记录学员的提出的问题;
s5.通过上一步骤得到答案,对答案进行语音合成,并将音频、文本形式的答案发送至学习交互模块向学习者。
本发明主要解决的技术问题是:针对学习工作中,学习者通过机器终端学习时,缺少交互手段的问题,提出一种基于终端机器上的收音设备,利用语音识别技术、文本匹配等技术,实现学习者能与终端进行友好的、有效的互动,提升学习的趣味性、有效性和能动性。
与现有技术相比,有益效果是:本发明致力于通过语音识别技术、自然语言处理技术以及其他机器学习算法打造一款新型的学习学习系统。新型学习系统将支持学员对学习学习终端进行语音提问和交流。
丰富学员在学习系统学习交互的手段,使得学习知识的学习方式多维化,自然化;
对比其他学习学习系统的交互模块,本发明让学员的“口”和“耳”也参与学习学习和政治思想提升,提高学员学习的效率和积极性,也实现了学员与学习系统双向互动。
基于语音识别的学习学习系统可自主的或交互的进行一系列拟人化服务,应对更多鼠标交互或者触控屏交互不能响应的场景。将学习设备更加智能化。
附图说明
图1是本发明整体模块示意图。
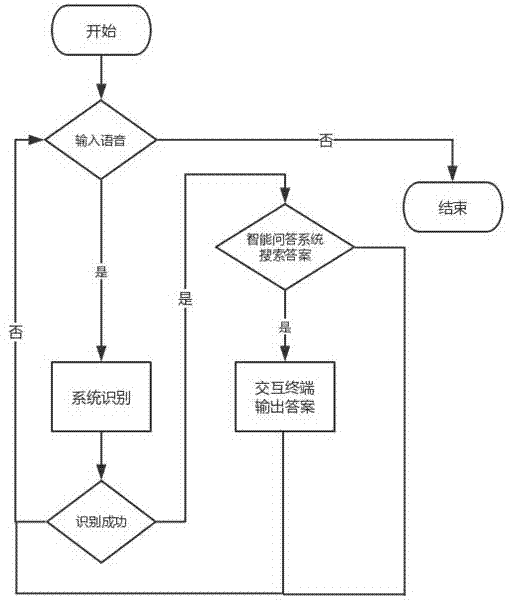
图2是本发明整体流程示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本专利的限制。
基于语音识别的人工智能学习方法,其中,包括语音输入模块,语音识别模块,智能问答模块和学习系统输出模块;包括以下步骤:
s1.用户面对学习终端以语音的形式输入问题,终端的收音设备得到实时音频数据;
s2.通过音频特征提取器,对原始语音进行预处理,特征提取等操作;
s3.利用语音识别技术将音频转化为文本;
s4.对文本进行语义分析并将其发送至智能学习知识库模块进行答案匹配,同时记录学员的提出的问题;
s5.通过上一步骤得到答案,对答案进行语音合成,并将音频、文本形式的答案发送至学习交互模块向学习者。
所述的步骤s2中,其语音数据预处理和特征提取的具体步骤如下:
s21.预加重:
为更好消除"唇齿效应"以识别语音,只保留一定频率范围的信号,步骤如下:
s′n=sn-k*sn-1
其中,s′n为处理后的信号,sn为原始信号,本发明的k参数取0.9;
s22.分帧:
对原始语音信号采取分帧操作,使得每一帧都可以认为是一段平稳随机过程;为了保证语音信号的连续性,每一帧之间有重叠部分,占帧长的1/2;采用汉明窗进行处理:
s23.提取mfcc特征:
首先对信号进行快速傅里叶变换,使得时域信号转为频域信号;其公式如下:
其中,n为采样点数量,s是计算出来的信号s的连续频谱;接着,对幅度谱加mel滤波器组,对所有的滤波器输出做对数运算,再进一步做离散余弦变换后均值方差归一化可得mfcc特征。
所述的步骤s3中,分别由声学模型建模,语言模型建模,和解码三部分构成;其中声学模型用来模拟发音的概率分布,语言模型用来模拟词语之间的关联关系。
其中本发明的声学模型采用隐马尔科夫模型+深度神经网络模型,得到与有关学习问题匹配的答案,并将结果输出至语音合成器生成音频,最终发送至学习系统的终端交互板块。终端交互板块将以音频,视频,文本等形式向学员展示有关问题的答案,完成语音交互的过程。
图1是本发明的系统示意图,图2是用户使用的流程图。其中,学习系统的模块被分为终端交互模块、语音识别模块、智能问答模块,以及语音合成模块。终端交互模块负责与用户的语音输入信息读取以及基于屏幕、播放器等交互设备的信息输出。语音识别模块可细分为音频特征提取模块和识别分类器模块,前者负责将学员的音频转换为机器可识别的信号特征,后者利用经过大量训练数据训练的隐马尔科夫模型和卷积神经网络模型进行语音识别,生成文本序列。智能问答模块负责在预先存好的知识库中搜索与用户输入问题相对应的答案文本,并将文本数据发送至语音合成模块,同时将学员输入的语音保存至学习数据分析中心,以记录其学习成果。语音合成模块负责将答案数据从文本转换为音频,终端交互模块最终以文本、视频、音频等形式将答案输出至学员。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!