一种阵列语音增强算法的制作方法
本发明涉及语音处理技术领域,具体为一种阵列语音增强算法。
背景技术:
语音作为最基本的交流媒介在日常生活中扮演重要角色,随着科技飞速发展,作为人机交互的一个重要入口,高准确度,低误识的语音识别日益受到业界的广泛关注,其中输入语音的清晰度对识别性能的提升至关重要。然而在现实环境中,语音不可避免的会受到周围复杂噪声环境的影响,语音内容的可懂度降低,导致语音识别的性能急剧恶化。
技术实现要素:
针对背景技术中存在的问题,本发明提供了一种阵列语音增强算法。
为实现上述目的,本发明提供如下技术方案:一种阵列语音增强算法,包括以下步骤:
s10噪声估计:通过定义接收到的音频信号,利用对每个频带跟踪带噪语音功率的最小值来实现对该频带的噪声的粗略估计;
s20时频掩蔽估计:通过定义某个时频点上语音出现的后验概率为当前时频点的掩蔽系数,用于估计噪声和语音在语谱图上存在的概率;
s30阵列mvdr权系数向量估计:通过定义多路输入信号每帧的频域向量,用于估计目标声源的具体方位。
作为本发明一种优选的技术方案,于步骤s10中定义接收到的音频信号表示为:y(k,l)=x(k,l)+d(k,l),其中x(k,l)表示语音信号,d(k,l)表示噪声信号频谱,然后定义语音功率谱为λx(k,l),噪声功率谱为λd(k,l),通过递归平均方法估计λd。
作为本发明一种优选的技术方案,利用递归平均方法估计λd的具体执行如下:
a、不考虑噪声不存在概率时,可以通过递归平均估算噪声功率谱:
λd=αdλd+(1-αd)||y(k,l)||2,为简化表示,此处λd=λd(k,l)表示第l帧第k个频点上的噪声功率;
b、考虑噪声不存在的情况下:
(1)、估计时频点功率:sf=|y|2
(2)、功率谱沿时间平滑:s=λss+(1-λs)sf
(3)、累积实时记录最小功率值smin,通过当前帧功率与加权后smin值比较估计当前时频点为语音的概率if(0,1分布),该概率实时平均结果ps作为当前点的语音mask,其中:
smin=min(smin,s)
if=s>smin·δs
ps=λpps+(1-λp)if
(4)、ps=1即当前时频点很可能是语音信号时,不更新噪声谱;只有在当前帧有可能是噪声信号时才会利用当前功率跟新噪声谱,由此以软判决方式估计当前时频点的功率值:λd=psλd+(1-ps)(αdλd+(1-αd)|y|2);
c、噪声跟踪实时处理:
在累积记录最小功率值时,为保证最小功率跟踪的实时性,每跨越若干帧,及时修正最小功率,具体实现如下:
(1)、定义矩阵sw用于存储n_win(=8)次累积的nfft_bins个频点的最小功率值;
(2)、累积记录跨越的帧数,当计数到v_win(=15)帧时,存入当前v_win帧的功率最小值stmp=min(stmp,s),同时将stmp重新初始化:stmp=s;当存满n_win帧时,每次存入新数据的同时剔除最早存储的那个最小功率;
(3)、修正后的最小功率值为:smin=min(sw)。
作为本发明一种优选的技术方案,于步骤s20中定义某个时频点上语音出现的后验概率为当前时频点的掩蔽系数,为此做如下相关参数定义:
a、h1表示语音存在、h0表示语音不存在;
b、输入信号的各个时频点上语音存在的后验概率p=p(h1|y);
c、语音不存在的先验概率可表示为q=p(h0),
假定语音与噪声幅度谱均服从均值为0的高斯分布,即:x(k,l)~n(0,λx),d(k,l)~n(0,λd),且语音与噪声相互独立,由此可以得到噪声以及语音的条件概率分布函数;
d、定义先验信噪比:
可以通过贝叶斯公式以及高斯分布函数得到语音存在的后验概率表示如下:
其中
估算的得到当前帧先验信噪比后,通过对当前帧信噪比与固定阈值的对比判断当前帧信号是否为噪声信号,从而估算出当前帧噪声存在的先验概率
为简化计算量,可直接利用ps=λpps+(1-λp)if得到的结果作为语音存在概率p(k,l)的粗略估计。
作为本发明一种优选的技术方案,于步骤s30中定义多路输入信号每帧的频域向量如下:
(1)相关矩阵估计
对相关矩阵的估计,单一帧的相关矩阵无法满足满秩且不具有统计特性。为此我们取8~10帧相关帧的平均作为最终的输入信号相关矩阵
(2)导向向量
当前假定仅存在一个有效目标方向语音,不存在相干噪声的情况下,基于理想情况下,导向向量与语音自相关矩阵rs的导向向量方向一致的基础(
作为本发明一种优选的技术方案,还包括后滤波处理步骤,该步骤使用基于ml的谱增益系数递归计算,即定义后验snr:
作为本发明一种优选的技术方案,基于谱减给出后滤波权系数为:
作为本发明一种优选的技术方案,通过添加调节系数,更新权增益系数为:
与现有技术相比,本发明的有益效果是:本发明在最小畸变的条件下最大程度的提升有效语音,使经多路增强后的语音信号识别率得到明显提升,增强语音信号的信噪比,大大增强了语音的可懂度。
附图说明
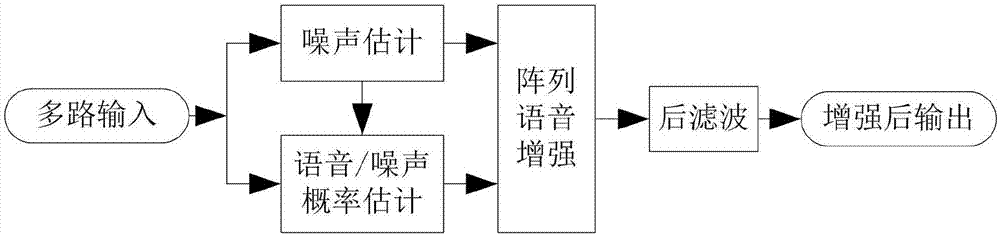
图1为本发明提供的一种阵列语音增强算法流程示意图;
图2为本发明提供的一种阵列语音增强算法中权系数评估框图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种阵列语音增强算法,包括以下步骤:
s10噪声估计:通过定义接收到的音频信号,利用对每个频带跟踪带噪语音功率的最小值来实现对该频带的噪声的粗略估计;
s20时频掩蔽估计:通过定义某个时频点上语音出现的后验概率为当前时频点的掩蔽系数,用于估计噪声和语音在语谱图上存在的概率;
s30阵列mvdr权系数向量估计:通过定义多路输入信号每帧的频域向量,用于估计目标声源的具体方位。
在对于音频信号处理方式中,我们一般视为短时平稳(约30ms以内视为平稳信号),为了提升处理的效果与速度,一般会经过短时傅里叶变换将其转换至频域处理,在处理完成得到最终的增强后的频域信号后,在经过短时傅里叶反变换,将处理后的信号重新拼接回时域,在本发明中通过对频域信号频谱信息的分析,以及阵列信号空间特征信息的处理得到经过频域加权后的系统输出。
对于信号的时频相互转换,常用的即为分帧,加窗的短时处理后,执行傅里叶变换进入频域,为了高效快速的拼接,以及简化处理过程,本发明采用最为常用的帧移为帧长一半的处理方案,这样拼接得到的时域信号更接近原始信号的幅度分布,该本发明种未经特殊说明,均是对分帧后的信号频谱(语谱图)做的处理,帧长为10毫秒。
本发明中假定目标语音为单个声源,噪声与语音信号均服从高斯分布,且相互不相关,对多路输入信号,通过噪声跟踪以及信号高斯分布的假定估计出语音以及噪声在每个时频点上出现的概率;估计噪声相关矩阵;基于阵列拓扑结构以及声源方位计算导向向量或通过语音相关矩阵估算导向向量(通过计算evd后的主特征向量模拟导向向量);在此基础上,利用mvdr的阵列语音增强架构估计增益系数向量。
在具体实施过程中,于步骤s10中定义接收到的音频信号表示为:y(k,l)=x(k,l)+d(k,l),其中x(k,l)表示语音信号,d(k,l)表示噪声信号频谱,然后定义语音功率谱为λx(k,l),噪声功率谱为λd(k,l),通过递归平均方法估计λd,利用递归平均方法估计λd的具体执行如下:
a、不考虑噪声不存在概率时,可以通过递归平均估算噪声功率谱:
λd=αdλd+(1-αd)||y(k,l)||2,为简化表示,此处λd=λd(k,l)表示第l帧第k个频点上的噪声功率;
b、考虑噪声不存在的情况下:
(1)、估计时频点功率:sf=|y|2
(2)、功率谱沿时间平滑:s=λss+(1-λs)sf
(3)、累积实时记录最小功率值smin,通过当前帧功率与加权后smin值比较估计当前时频点为语音的概率if(0,1分布),该概率实时平均结果ps作为当前点的语音mask,其中:
smin=min(smin,s)
if=s>smin·δs
ps=λpps+(1-λp)if
(4)、ps=1即当前时频点很可能是语音信号时,不更新噪声谱;只有在当前帧有可能是噪声信号时才会利用当前功率跟新噪声谱,由此以软判决方式估计当前时频点的功率值:λd=psλd+(1-ps)(αdλd+(1-αd)|y|2);
c、噪声跟踪实时处理:
在累积记录最小功率值时,为保证最小功率跟踪的实时性,每跨越若干帧,及时修正最小功率,具体实现如下:
(1)、定义矩阵sw用于存储n_win(=8)次累积的nfft_bins个频点的最小功率值;
(2)、累积记录跨越的帧数,当计数到v_win(=15)帧时,存入当前v_win帧的功率最小值stmp=min(stmp,s),同时将stmp重新初始化:stmp=s;当存满n_win帧时,每次存入新数据的同时剔除最早存储的那个最小功率;
(3)、修正后的最小功率值为:smin=min(sw)。
在具体实施过程中,于步骤s20中定义某个时频点上语音出现的后验概率为当前时频点的掩蔽系数,为此做如下相关参数定义:
a、h1表示语音存在、h0表示语音不存在;
b、输入信号的各个时频点上语音存在的后验概率p=p(h1|y);
c、语音不存在的先验概率可表示为q=p(h0),
假定语音与噪声幅度谱均服从均值为0的高斯分布,即:x(k,l)~n(0,λx),d(k,l)~n(0,λd),且语音与噪声相互独立,由此可以得到噪声以及语音的条件概率分布函数;
d、定义先验信噪比:
可以通过贝叶斯公式以及高斯分布函数得到语音存在的后验概率表示如下:
其中
估算的得到当前帧先验信噪比后,通过对当前帧信噪比与固定阈值的对比判断当前帧信号是否为噪声信号,从而估算出当前帧噪声存在的先验概率
为简化计算量,可直接利用ps=λpps+(1-λp)if得到的结果作为语音存在概率p(k,l)的粗略估计。
在具体实施过程中,于步骤s30中定义多路输入信号每帧的频域向量如下:
(1)相关矩阵估计
对相关矩阵的估计,单一帧的相关矩阵无法满足满秩且不具有统计特性。为此我们取8~10帧相关帧的平均作为最终的输入信号相关矩阵
(2)导向向量
当前假定仅存在一个有效目标方向语音,不存在相干噪声的情况下,基于理想情况下,导向向量与语音自相关矩阵rs的导向向量方向一致的基础(
在具体实施过程中,还包括后滤波处理步骤,该步骤使用基于ml的谱增益系数递归计算,即定义后验snr:
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!