一种基于Kullback-Leibler差异的语音增强方法与流程
本发明涉及一种基于kullback-leibler(kl)差异的语音增强方法,应用于无线电话通信、场景录音和军事窃听等技术领域。
背景技术:
语音信号处理的目的是要得到某些语音特征参数以便高效的传输或存储,或者是通过某种处理运算可以达到某种用途的要求,例如人工语音合成、辨别出讲话者,讲话的内容等。语音增强是语音信号处理的一个重要方面。语音增强的一个主要目的是从混杂着噪声的语音信号中尽可能地提取出纯净的原始语音信号,然而,由于在通常情况下干扰都是随机的,从混杂着噪声的语音信号中提取出完全纯净的语音信号几乎是不可能的,尤其是在低信噪比的情况下更是十分困难。在这种情况下,语音增强的目的主要有两个:一是改进语音质量,消除背景噪声,使听者乐于接受;二是,提高语音的可懂度,使说话人易于辨识。
近年来语音增强算法层出不穷,也得到了普遍的应用。这些方法主要是利用语音信号的某些特性,对其参数进行相关处理以达到消除噪声,逼近纯净语音信号的功能。现有已经提出来的语音增强方法主要包括:傅里叶变换及在其基础上衍生出来的短时傅里叶变换、小波变换。
传统的傅里叶变换去噪方法是将一个信号分离为无穷多正弦信号的叠加。它将含有噪声的语音信号从时域变换到频域,然后对频域信号进行相关处理,用滤波器将噪声信号的频率进行滤除,保留剩余成分,然后对其做傅里叶逆变换便得到降噪后的语音信号。但是傅里叶变换对信号的要求十分严格,通常它只能对线性平稳的信号有较好的处理效果,而语音信号一般都是非线性和非平稳的,因此得不到理想的降噪效果。
为了克服傅里叶变换不适合于非线性非稳定信号的缺点,衍生出了短时傅里叶变换的方法。短时傅里叶变换是常用的一种时频分析方法。它主要是通过对语音信号加上窗函数来使非平稳信号在一段时间内变的相对平稳,之后对加窗后的分段信号分别做傅里叶变换,方法同传统的傅里叶变换方法一致。在短时傅里叶变换过程中,窗的长度决定了频谱图的时间分辨率和频率分辨率,窗越长,截取的信号越长,傅里叶变换后频率分辨率越高,时间分辨率越差;相反,窗越短,截取的信号越短,变换后的频率分辨率越差,时间分辨率越好。测不准原理指出:不可能在时间和频率两个空间同时以任意精度逼近被测信号,因此在信号处理时必须对时间或频率精度进行取舍。所以,在短时傅里叶变换进行降噪过程中,频率分辨率和时间分辨率不能兼得。
小波变换在短时傅里叶变换的时间分辨率和频率分辨率不能兼得的情况下应运而生。小波变换在语音增强过程中的步骤主要分为:首先选择一个小波基函数并确定一个小波分解的层次n,并对信号进行n层小波分解计算;然后对第一层到第n层的每一层高频系数,选择一个阈值进行阈值量化处理;最后便是小波的重构,根据小波分解的第n层的低频系数和经过量化处理后的第一层到第n层的高频系数进行信号的小波重构。至此便可以得到增强后的语音信号。在该语音增强方法中,小波基函数、阈值选取和分解层数的选择都对信号的降噪效果有着十分重要的影响。不同的语音信号的最佳小波基函数也不尽相同,而找到适合的基函数在现实中也相对比较困难;另外,阈值是另一个影响降噪效果的因素,如果阈值选取过小则会造成信号中有用信息的丢失,而如果阈值选取过大则会依然保留噪声导致降噪效果不明显;其次,降噪的好坏还和分解层数的选择有密切的关系,分解层数过少时将不能得到最好的降噪效果,但是分解层数过多时则会增加计算量,信号处理变慢。在增强过程中,这些参数的选择通常都是根据经验来进行选择,这就增加了很多人为因素并且往往初次选择这些参数可能是不准确的。另外,该方法在低信噪比的情况下降噪性能并不理想,在这一方面还有待提高。
技术实现要素:
针对现有技术的不足,本发明的目的是提出一种基于kullback-leibler差异的语音增强方法,并且确定该方法的最佳分解次数,该方法克服传统方法低信噪比情况下降噪性能差、参数过多依赖经验选择的缺点,显著的提高了低信噪比情况下的降噪性能,自适应的选择参数而不依赖人为因素,并选择出最佳分解次数,降低了计算量。
为了实现上述目的,本发明的构思是:
首先对含有噪声的语音信号进行分帧处理;然后对每一帧进行kl差异算法分析,利用kl差异选择原理选出最佳原子,并用该原子计算每次分解的有理正交基将其作为基函数;随后利用权重系数与基函数重构出纯净的语音信号;另外,利用代价函数来计算分解终止条件,得到最佳分解次数避免增加计算量。
具体是首先将含有噪声的语音信号进行分帧处理,每一帧的长度大约为20~30ms;再分别对每一帧作分析处理,然后在给定的原子选择区间内,利用kl差异选择原理使得kl值最小依次选出最佳的原子a1,a2,...ak。根据这些选出的最佳原子构造出此次分解的最佳有理正交基函数bk,并与权重系数相组合得到此次分解的重构信号
另外,该方法的分解收敛次数通过代价函数来确定。在每次分解后计算出信号的最小均方误差(rmse),下一次分解时将本次的rmse与上一次分解的rmse作差值,当该差值大于0时则停止分解,则上一次分解的次数即为最佳的分解次数。本方法采用kl差异原理自适应的选择原子并能在低信噪比时得到更好的降噪性能,并自适应的选出最佳分解次数避免过多分解增加计算量,降低处理速度。
根据上述发明构思,本发明采用的技术方案是:
一种基于kullback-leibler差异的语音增强方法,包括以下步骤:
1)、对含有噪声的语音信号进行分帧,将每一帧信号看作稳态信号;
2)、对处理后的每一帧语音信号分别进行分析处理,利用kl差异选择原理依次选出最佳的原子a1,a2,...ak,用选出的最佳原子计算有理正交基函数bk,然后用权重系数与该基函数组合得到增强后的重构信号;
3)、将n次分解后得到的重构信号叠加得到增强后的纯净语音信号;
4)、根据代价函数得到最佳分解次数。
本发明方法与现有技术相比,具有如下的优点:
本方法利用kl差异选择原则,自适应的选出最佳原子并构造基函数,极大的减少了人为选择参数导致不确定性的缺陷,在低信噪比时有更好的降噪性能。其次,根据代价函数确定最佳分解次数,有效的降低了计算复杂度,提高了信号的处理速度。该方法可广泛的应用于语音信号处理降噪等领域。
附图说明
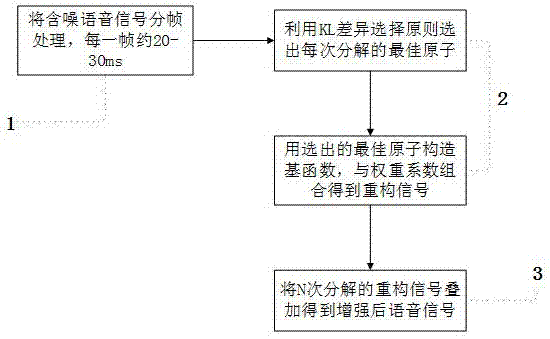
图1为本发明一种基于kullback-leibler差异的语音增强方法的流程图。
图2为本发明的通过代价函数选出最佳分解次数的示意图。
具体实施方式
为了更好地理解本发明的技术方案,以下结合附图对本发明作进一步的详细描述:
本方法的流程参见图1,一种基于kullback-leibler差异的语音增强方法,利用kl差异选择原理在每一次分解中选出一个使得kl差异值最小的模小于1的原子,并通过选出的原子构建有理正交基函数,再由基函数与权重系数组合重构纯净的语音信号,完成语音增强。另外,根据代价函数选择最佳分解次数。具体实施步骤如下:
1)、对原始语音信号作分帧处理,得到每一帧的长度大约为20~30ms,将该区间内的信号看作稳态信号;
2)、根据kl差异选择原则选出最佳原子并重构每次分解后的信号,其具体如下:
对于含有噪声的原始语音信号f(t)可以表示为如下形式:
f(t)=s(t)+n(t),(1)
其中,s(t)为纯净语音信号,即需要重构得到的信号,n(t)为噪声信号,以下用f替代f(t)。
对于第一次分解,令f1=f,分解后得到重构信号
其中
为点ak的l2单位模化了的
根据公式(2)和(4),f2可表示为:
f2即作为第二次分解时的输入信号,并对f2重复上述分解过程得到重构信号:
以此类推,经过第k次分解后,重构信号
其中bk(z)即为有理正交基函数,可表示为:
从公式(7)和(8)可以看出,该分解算法的核心是选取最佳的原子ak。在每一次分解中,我们利用kl差异选择原理来选取最佳原子,kl差异的定义为:
其中yi为原始信号,
其中c为可供选择原子的集合,即:
δm是等间隔划分区间(-1,1)的步长。
至此,我们已经选取出了最佳的原子,之后便是利用这些最佳原子重构出增强后的信号。通常情况下,我们取公式(7)右边的前半部分作为重构信号,舍弃后半部分的标准误差,则每次分解后的重构信号可用如下形式表示:
3)、将n次分解后得到的重构信号叠加得到增强后的纯净语音信号,其过程具体如下:
基函数与权重系数组合得到的重构信号如公式(12)所示,权重系数即为
4)、根据代价函数得到最佳分解次数,具体如下:
在步骤2)、3)过程中另一个关键因素就是分解次数的选择,次数过少会导致降噪效果不理想,次数过多又会导致过大的计算量。因此,我们用代价函数来确定最佳的分解次数。
均方根误差(rmse)是观测值与真实值偏差的平方和观测次数比值的平方根,它能够很好的反映出测量的精密程度,其定义如下:
其中n为数据长度。
本发明利用每次分解的rmse衰减差值作为代价函数确定最佳分解次数,即:
其中i表示分解次数。由公式(14)可以得出rmse越小,信号重构越精确,所以当δri小于0时,则表明重构越接近原始信号。因此,使信号持续分解直到δri大于0则停止分解,此时的分解次数i即为最佳分解次数,此时得到的重构信号也是最纯净的语音信号。
- 还没有人留言评论。精彩留言会获得点赞!