一种基于音频分类的音质设置方法与流程
本发明属于语音技术领域,具体涉及一种基于音频分类的音质设置方法。
背景技术
随着人工智能技术在各行各业的大力发展,已进入到人类生活的各个方面,电视行业也不例外。利用人工智能技术,使电视具备智能化,能更好的满足用户需求,改善用户的使用体验。
视频、音频等多媒体数据都是电视机中重要的信息媒体形式,其中音频信息占有很重要的地位。如何对音频信息进行处理、组织分析和利用是信息处理领域中的一个重要课题,而音频分类是其中的关键技术之一。不同场景的音频信息是有各自特点的,比如新闻类,抑扬顿挫,具备一定的语速是这类音频场景的特点;比如音乐类,高低音频兼备,且有一定节奏感是这类音频场景的特点。针对不同的音频场景,在电视上可以设置不同的音频模式来更好的适应不同的场景。
目前大部分产品的人工智能技术都是运行在互联网的云服务器端,因为搭载android系统本身的硬件条件限制,无法运行大规模的计算,也不能占据太多的资源,如cpu的占用。
技术实现要素:
本发明的目的在于提供一种基于音频分类的音质设置方法,具有对运行在arm板上的音频场景分类技术进行设计、优化和实现的优点。
本发明的上述目的是通过以下技术方案得以实现的:
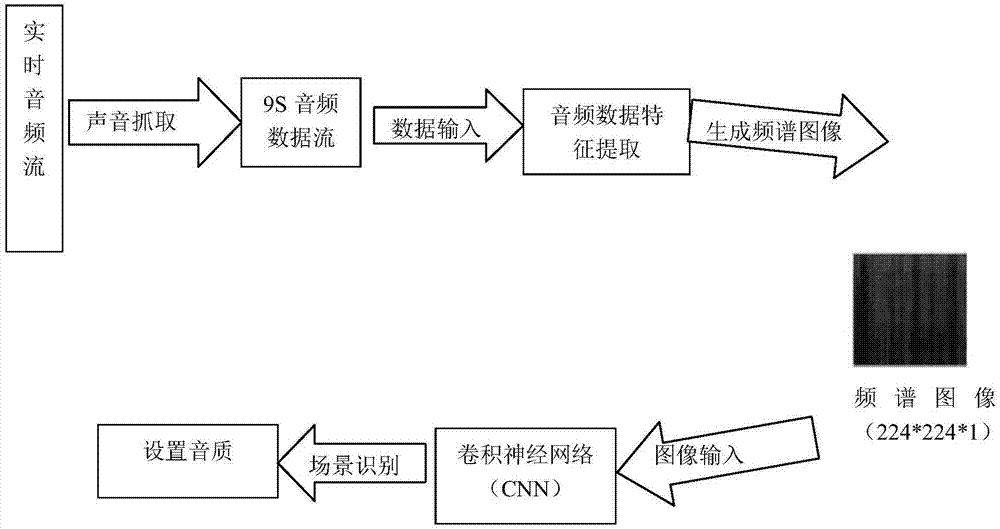
一种基于音频分类的音质设置方法,包括音频特征提取模块、音频分类模块和音频设置模块,还包括以下步骤:
s1、音频特征提取;
s11、预加重,将9s的语音数据通过高通滤波器,提升语音数据中的高频部分,使信号的频谱变得平坦;
s12、分帧,采样率为22.05khz,设置822个采样点为一帧,即一帧的时间为40ms,9s的语音数据分为225帧;
s13、加窗,将每一帧乘以汉明窗,增加左右两端的连续性;
s14、快速傅氏变换,对加窗后的每帧信号进行快速傅里叶变换,得到各帧的频谱,再对频谱取模平方,最后得到语音信号的功率谱;
s15、mel滤波,将信号的功率谱通过mel滤波器,将线形的自然频谱转换为体现人类听觉特性的mel频谱,仅取每一帧信号的前224个特征;
s16、取对数,对mel频谱取完对数,便可以得到225*224大小的频谱图,即横坐标为帧,纵坐标为mel特征,在实际计算中,会舍弃一帧数据,即采用224*224大小的频谱图去做分类,但是此刻的频谱图的值并不全在图像0~255的范围内,为了将频谱图的值映射到图像0~255取值的范围内,本发明做了以下的线性映射计算:
f(x)=1.5×(10x+80)(公式1)
经过公式1的计算,mel频谱图的值基本可以映射到图像0~255的取值范围中;
s2、音频分类;
s21、音频分类模块采用深度学习的cnn卷积神经网络——mobilenet分类网络来进行语音数据的分类;
s3、音质设置;
s31、对音乐类的语音数据,通过杜比音效的音频优化器功能衰减低频部分,提升人声对应频段,使用杜比音效语音清晰功能强化人声部分效果;
s32、对新闻类的语音数据,通过杜比音效智能eq功能勾画大致声音风格曲线,通过杜比音效重低音和环绕声等功能配合调节音效;
s33、对其他类的语音数据,默认标准模式参数。
综上所述,本发明具有以下有益效果:
(1)通过自动对不同音频场景进行识别和相应设置,使android智能电视更加智能,提升用户的使用体验,感受android智能电视带来的乐趣。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例的流程图。
具体实施方式
在下面的详细描述中,提出了许多具体细节,以便于对本发明的全面理解。但是,对于本领域技术人员来说很明显的是,本发明可以在不需要这些具体细节中的一些细节的情况下实施。下面对实施例的描述仅仅是为了通过示出本发明的示例来提供对本发明的更好地理解。
下面将结合附图,对本发明实施例的技术方案进行描述。
实施例:
如图1所示,一种基于音频分类的音质设置方法,包括音频特征提取模块、音频分类模块和音频设置模块,还包括以下步骤:
s1、音频特征提取;
s11、预加重,将9s的语音数据通过高通滤波器,提升语音数据中的高频部分,使信号的频谱变得平坦;
s12、分帧,采样率为22.05khz,设置822个采样点为一帧,即一帧的时间为40ms,9s的语音数据分为225帧;
s13、加窗,将每一帧乘以汉明窗,增加左右两端的连续性;
s14、快速傅氏变换,对加窗后的每帧信号进行快速傅里叶变换,得到各帧的频谱,再对频谱取模平方,最后得到语音信号的功率谱;
s15、mel滤波,将信号的功率谱通过mel滤波器,将线形的自然频谱转换为体现人类听觉特性的mel频谱,仅取每一帧信号的前224个特征;
s16、取对数,对mel频谱取完对数,便可以得到225*224大小的频谱图,即横坐标为帧,纵坐标为mel特征,在实际计算中,会舍弃一帧数据,即采用224*224大小的频谱图去做分类,但是此刻的频谱图的值并不全在图像0~255的范围内,为了将频谱图的值映射到图像0~255取值的范围内,本发明做了以下的线性映射计算:
f(x)=1.5×(10x+80)(公式1)
经过公式1的计算,mel频谱图的值基本可以映射到图像0~255的取值范围中;
s2、音质设置;
s21、音频分类模块采用深度学习的cnn卷积神经网络——mobilenet分类网络来进行语音数据的分类;
s3、音质设置;
s31、对音乐类的语音数据,通过杜比音效的音频优化器功能衰减低频部分,提升人声对应频段,使用杜比音效语音清晰功能强化人声部分效果;
s32、对新闻类的语音数据,通过杜比音效智能eq功能勾画大致声音风格曲线,通过杜比音效重低音和环绕声等功能配合调节音效;
s33、对其他类的语音数据,默认标准模式参数。
本发明是针对运行在arm板上的音频场景分类技术进行设计、优化和实现,通过自动对不同音频场景进行识别和相应设置,使android智能电视更加智能,提升用户的使用体验,感受android智能电视带来的乐趣。
以上实施例仅用以说明本发明的技术方案,而非对发明的保护范围进行限制。显然,所描述的实施例仅仅是本发明部分实施例,而不是全部实施例。基于这些实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明所要保护的范围。
尽管参照上述实施例对本发明进行了详细的说明,本领域普通技术人员依然可以在不冲突的情况下,不作出创造性劳动对本发明各实施例中的特征根据情况相互组合、增删或作其他调整,从而得到不同的、本质未脱离本发明的构思的其他技术方案,这些技术方案也同样属于本发明所要保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!