面向智能家居场景的语音识别控制系统及方法与流程
本发明涉及一种面向智能家居场景的语音识别控制系统及方法,属于智能家居技术领域。
背景技术:
据了解,智能家居是利用先进的计算机技术、网络通讯技术、综合布线技术,将与家居生活有关的各种子系统,有机地结合在一起,通过统筹管理,让家居生活更加舒适、安全、有效。近年来,随着人们生活水平的提高以及计算机技术、通信技术和网络技术的发展,智能家居逐渐成为未来家居生活的发展方向。因此,在实现智能控制的同时,研制一个成本低、实用性强的智能家居系统便显得非常有必要。
技术实现要素:
本发明所要解决的技术问题是,克服现有技术的不足而提供成本低、实用性强的面向智能家居场景的语音识别控制系统,同时给出了其控制方法。
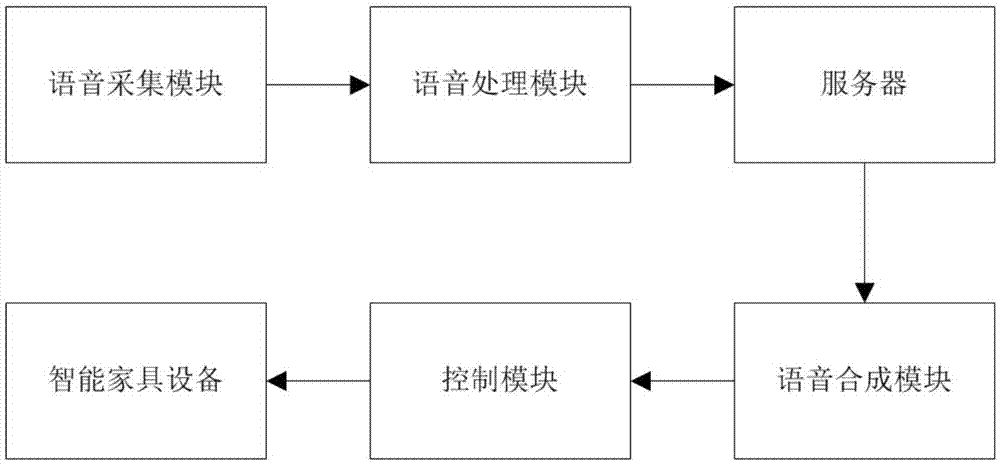
本发明提供一种面向智能家居场景的语音识别控制系统,包括语音采集模块、语音处理模块、服务器、语音合成模块、控制模块和智能家居设备;
所述语音采集模块,用于采集用户输入的语音指令;
所述语音处理模块,用于对语音采集模块采集的语音信号进行去噪处理,并将处理后的信号输出到具有语音识别库的服务器中;
所述服务器,用于对语音处理模块处理后的信号进行匹配以得到相应的反馈信号;
所述语音合成模块,用于对服务器输出的反馈信号进行处理生成命令字符;
所述控制模块,用于根据语音合成模块输出的命令字符对智能设备进行控制;
所述智能家居设备,用于响应控制模块输入的命令,并反馈其响应情况至控制模块。
作为本发明的进一步技术方案,一种面向智能家居场景的语音识别控制方法,包括以下步骤:
s1、语音采集模块采集用户输入的语音指令;转至步骤s2;
s2、语音处理模块对语音采集模块采集的语音信号进行去噪处理,并发送到具有语音识别库的服务器中;转至步骤s3;
s3、服务器根据语音识别库对语音处理模块处理后的信号进行匹配得到相应的反馈信号;转至步骤s4;
s4、语音合成模块对服务器输出的反馈信号进行处理生成命令字符;转至步骤s5;
s5、控制模块根据语音合成模块输出的命令字符对智能设备进行控制;转至步骤s6;
s6、智能家居设备响应控制模块输出的执行命令并反馈其响应情况。
步骤s2中,语音处理模块基于先验信噪比的变形谱减法对语音信号进行去躁处理,具体方法如下:
s201、输入麦克风拾取的声音信号;转至步骤s202;
s202、选择切比雪夫带通滤波留下[300,3400]频段的信号;转至步骤s203;
s203、对留取的频段信号进行分帧,帧长320,帧移160,即每帧20ms;转至步骤s204;
s204、对每帧信号进行加窗处理,采用矩形窗或汉明窗;转至步骤s205;
s205、求出带噪语音的短时能量和短时平均过零率,并求出门限初值;转至步骤s206;
s206、对每帧信号的语音和噪声做出首次判断,然后将连续6帧低于门限初值的帧判为噪声帧,并赋0,其余判为语音帧voice_frame;转至步骤s207;
s207、对语音帧voice_frame做fft变换(傅里叶变换);转至步骤s208;
s208、求出先验信噪比snrprio;转至步骤s209;
s209、计算出增益g(w),然后乘上判为语音帧的带噪语音信号,得出语音估计;转至步骤s210;
s210、对fft变换的语音帧voice_frame恢复相位,并做ifft变换(傅里叶逆变换);转至步骤s211;
s211、对ifft变换的语音帧进行去重叠处理,然后从增强后的重叠信号中抽取出最终的纯净语音信号估计,输出纯净语音。
步骤s208中,根据下式求出先验信噪比snrprio,
其中,s(ω)表示语音信号的短时谱,
步骤s209中,采用直接判断法对snrprio进行估计:
其中,
然后重新列出增益型谱减法的公式如下:
现在要把增益g(ω,i)用先验信噪比snrprio来表示,因为
snrpost(ω,i)=1+snrprio(ω,i)
因此,根据下式计算增益g(w,i),
其中,snrprio(w,i)为先验信噪比,i为帧数。
步骤s209中,根据下式计算语音估计值
其中,g(ω)为增益,|y(ω)|为语音帧的带噪语音信号。
步骤s204中,加窗处理后对每一帧加过窗函数的信号进行有声/无声判决,具体方法如下:
判断每帧信号是否为有声信号,若是有声信号,则将该帧信号转至步骤s205进行处理,若是无声信号,则更新噪声谱,然后将该帧信号转至步骤s208进行处理。
步骤s205中,步骤s205中,根据下式计算带噪语音的短时能量qn,
其中,x(m)为带噪语音信号序列,并且当t[x(m)]=x2(m)时,通过上式计算带噪语音的短时能量,当t[x(m)]=|sgn[x(m)]-sgn[x(m-1)]|,且
设s(i)为带噪语音的某一帧信号,则其短时能量为
根据下式计算门限初值h1,
h1=a1×max(ff)+a2×min(ff)
ff=ln(amp/zcr)
其中,a1+a2=1,且a1>0,a2>0,通过调节a1和a2,以使得h1达到最佳门限以判定该帧是语音信号还是噪声。
步骤s206中,对语音和噪声做出首次判断的方法如下:
根据前面设定的门限值,对语音和噪声进行比较,然后对连续6帧低于门限的帧判为噪声帧,并赋0。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明通过麦克风拾取声音信号,并经过语音处理模块对采集的声音信号进行去噪处理,将处理后的语音信号发送到具有语音识别库的服务器得到相应的反馈信号,语音合成模块根据反馈信号生成对应的命令字符,控制模块根据命令字符对智能设备进行控制,智能家居设备反馈其响应情况。总之,本发明能够有效的消除语音命令中的杂音,并且以语音命令代替手动控制和遥控控制,简化了人们的操作,方便了人们的生活方式。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明的系统框图。
图2为本发明中语音处理模块的流程示意图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本实施例提出了一种面向智能家居场景的语音识别控制系统,如图1所示,包括语音采集模块、语音处理模块、服务器、语音合成模块、控制模块和智能家居设备。语音采集模块,用于采集用户输入的语音指令;语音处理模块,用于对语音采集模块采集的语音信号进行去噪处理,并将处理后的信号输出到具有语音识别库的服务器中;服务器,用于对语音处理模块处理后的信号进行匹配以得到相应的反馈信号;语音合成模块,用于对服务器输出的反馈信号进行处理生成命令字符;控制模块,用于根据语音合成模块输出的命令字符对智能设备进行控制;智能家居设备,用于响应控制模块输入的命令,并反馈其响应情况至控制模块。
一种面向智能家居场景的语音识别控制方法,包括以下步骤:
s1、语音采集模块采集用户输入的语音指令;转至步骤s2;
s2、语音处理模块对语音采集模块采集的语音信号进行去噪处理,并发送到具有语音识别库的服务器中;转至步骤s3;
s3、服务器根据语音识别库对语音处理模块处理后的信号进行匹配得到相应的反馈信号;转至步骤s4;
s4、语音合成模块对服务器输出的反馈信号进行处理生成命令字符;转至步骤s5;
s5、控制模块根据语音合成模块输出的命令字符对智能设备进行控制;转至步骤s6;
s6、智能家居设备响应控制模块输出的执行命令并反馈其响应情况。
步骤s2中,语音处理模块基于先验信噪比的变形谱减法对语音信号进行去躁处理,具体方法如下:
s201、输入麦克风拾取的声音信号;转至步骤s202;
s202、选择切比雪夫带通滤波留下[300,3400]频段的信号;转至步骤s203;
s203、对留取的频段信号进行分帧,帧长320,帧移160,即每帧20ms;转至步骤s204;
s204、对每帧信号进行加窗处理,采用矩形窗或汉明窗;转至步骤s205;
s205、求出带噪语音的短时能量和短时平均过零率,并求出门限初值;转至步骤s206;
s206、对每帧信号的语音和噪声做出首次判断,然后将连续6帧低于门限初值的帧判为噪声帧,并赋0,其余判为语音帧voice_frame;转至步骤s207;
s207、对语音帧voice_frame做fft变换(傅里叶变换);转至步骤s208;
s208、求出先验信噪比snrprio;转至步骤s209;
s209、计算出增益g(w),然后乘上判为语音帧的带噪语音信号,得出语音估计;转至步骤s210;
s210、对fft变换的语音帧voice_frame恢复相位,并做ifft变换(傅里叶逆变换);转至步骤s211;
s211、对ifft变换的语音帧进行去重叠处理,然后从增强后的重叠信号中抽取出最终的纯净语音信号估计,输出纯净语音。
步骤s204中,加窗处理后对每一帧加过窗函数的信号进行有声/无声判决,具体方法如下:
判断每帧信号是否为有声信号,若是有声信号,则将该帧信号转至步骤s205进行处理,若是无声信号,则更新噪声谱,然后将该帧信号转至步骤s208进行处理。
步骤s205中,步骤s205中,根据下式计算带噪语音的短时能量qn,
其中,x(m)为带噪语音信号序列,并且当t[x(m)]=x2(m)时,通过上式计算带噪语音的短时能量,当t[x(m)]=|sgn[x(m)]-sgn[x(m-1)]|,且
设s(i)为带噪语音的某一帧信号,则其短时能量为
根据下式计算门限初值h1,
h1=a1×max(ff)+a2×min(ff)
ff=ln(amp/zcr)
其中,a1+a2=1,且a1>0,a2>0,通过调节a1和a2,以使得h1达到最佳门限以判定该帧是语音信号还是噪声。
步骤s206中,对语音和噪声做出首次判断的方法如下:
根据前面设定的门限值,对语音和噪声进行比较,然后对连续6帧低于门限的帧判为噪声帧,并赋0。
步骤s208中,根据下式求出先验信噪比snrprio,
其中,s(ω)表示语音信号的短时谱,
步骤s209中,采用直接判断法对snrprio进行估计:
其中,
然后重新列出增益型谱减法的公式如下:
现在要把增益g(ω,i)用先验信噪比snrprio来表示,因为
snrpost(ω,i)=1+snrprio(ω,i)
因此,根据下式计算增益g(w,i),
其中,snrprio(w,i)为先验信噪比,i为帧数。
步骤s209中,根据下式计算语音估计值
其中,g(ω)为增益,|y(ω)|为语音帧的带噪语音信号。
步骤s211中,在步骤s203分帧时信号要重叠,一般取帧长的一半,在步骤s211的ifft中需要去重叠。
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!