一种非平行语料语音个性化转换方法与流程
本发明涉及语音个性化技术领域,特别是一种非平行语料语音个性化转换方法。
背景技术:
随着智能化家居的发展,语音个性化技术在越来越多的领域得到了应用。语音播报技术的发展大大方便了人们的生活,提高了生活的品质。现在的语音个性化技术大多通过个性化目标与本人的平行语料,提取声纹特征后进行矩阵变化,例如dtw,对语音语料的要求比较高,耗时也比较多。
技术实现要素:
为解决现有技术中存在的问题,本发明的目的是提供一种非平行语料语音个性化转换方法,本发明解决了目前的声音个性化算法需要先找到平行语音数据,训练时间较长的问题。
为实现上述目的,本发明采用的技术方案是:一种非平行语料语音个性化转换方法,包括以下步骤:
s1、根据文本采集目标语音,并对目标语音的文本和语音进行修正;
s2、将目标语音的中文音素对齐,得到目标语音中每个中文音素对应的音频;
s3、提取中文音素对应的音频特征和音素信息;
s4、训练hmm-gmm语音识别模型,并将提取的音频特征和音素信息输入到hmm-gmm语音识别模型中,得到目标语音音频特征与对应的中文音素之间的印射模型,印射模型用于对中文音素进行预测,通过预测的中文音素训练第一chbg网络;
s5、目标语音的中文音素通过第一chbg网络训练后,再通过对其训练dnn语言模型得到目标语音的音频特征对应的中文音素,并根据中文音素得到目标语音的pulse;
s6、通过训练第二chbg网络得到原语音的中文音素对应的pulse与目标语音的中文音素对应的pulse的对应模型;
s7、将dnn语言模型和chbg网络串联即可将原语音转换为目标语音。
作为一种优选的实施方式,所述步骤s1中在录音棚中采集至少1000句同一人物的语音作为目标语音,语音的采样频率为48000hz,所采集的目标语音中包含22个声母,39个韵母以及声调组合成的217个中文音素。
作为另一种优选的实施方式,所述步骤s2中,将目标语音的中文音素对齐的具体步骤为通过人工分割得到目标语音的音频分割后的label文件,通过hmm-gmm语音识别模型对其进行训练,得到目标语音中每个中文音素对应的音频。
作为另一种优选的实施方式,所述步骤s3中,提取的音频特征包括lsf特征、hnr特征和gain特征,采用加窗分帧的傅里叶变化进行提取,其中窗长为0.025s,采样频率为16000hz,对音频特征进行提取时,f0特征1维,gain特征1维,hnr特征5维,lsfsource特征10维,lsf特征30维。
作为另一种优选的实施方式,所述chbg网络包括:
卷积神经网络(converlution),用于对原语音的音频进行特征训练,且卷积神经网络包括256个卷积核,采用depthwiseconvolution提高了卷积运算的速度;
高速神经网络(highwaynet),用于处理卷积信息,并对卷积结果进行归一化;
双向神经网络(bi-directional),用于对不同时刻的高速神经网络的参数进行更新;
gru神经网络,gru神经网络作为lstm的一种变体,用于将忘记门和输入门合成一个单一的更新门。
作为另一种优选的实施方式,所述步骤s7具体如下:
将dnn语言模型和chbg网络串联,以原语音的中文音素对应的pulse与目标语音的中文音素对应的pulse作为中间媒介将原语音转换为目标语音,并通过pulsemodel后端处理工具将pulse进行合成。
本发明通过对目标语音的音频训练hmm-gmm语音识别模型,利用lsf(linespectralfrequencies),gain,hnr(harmonic-to-noiseratio)音频特征进行音频的对应中文音素前端对齐和分割,并将对应中文音素通过深度学习的第一chbg网络和dnn语言模型得到目标语音的pulse,再通过训练第二chbg网络得到原语音的中文音素对应的pulse与目标语音的中文音素对应的pulse的对应模型,转换时将和第二chbg网络混合在一起,通过dnn语言模型找到对应中文音素在目标语音中的pulse,再通过第二chbg网络得到原语音对应的中文音素的在目标语音中的pulse,将中文音素作为训练的桥梁,将不同声音特征的目标语音和原语音的pulse关联起来,即可完成原语音到目标语音的转换。
本发明的有益效果是:
本发明提供的非平行语料语音个性化转换方法,利用深度学习网络,不需要原声音和目标声音采用相同的文本,即可根据对应的中文音素作为中间媒介实现音素的转化,本发明可应用于语音个性化领域,但不仅限于该领域。
附图说明
图1为本发明实施例非平行语料语音个性化转换方法的示意图。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
实施例
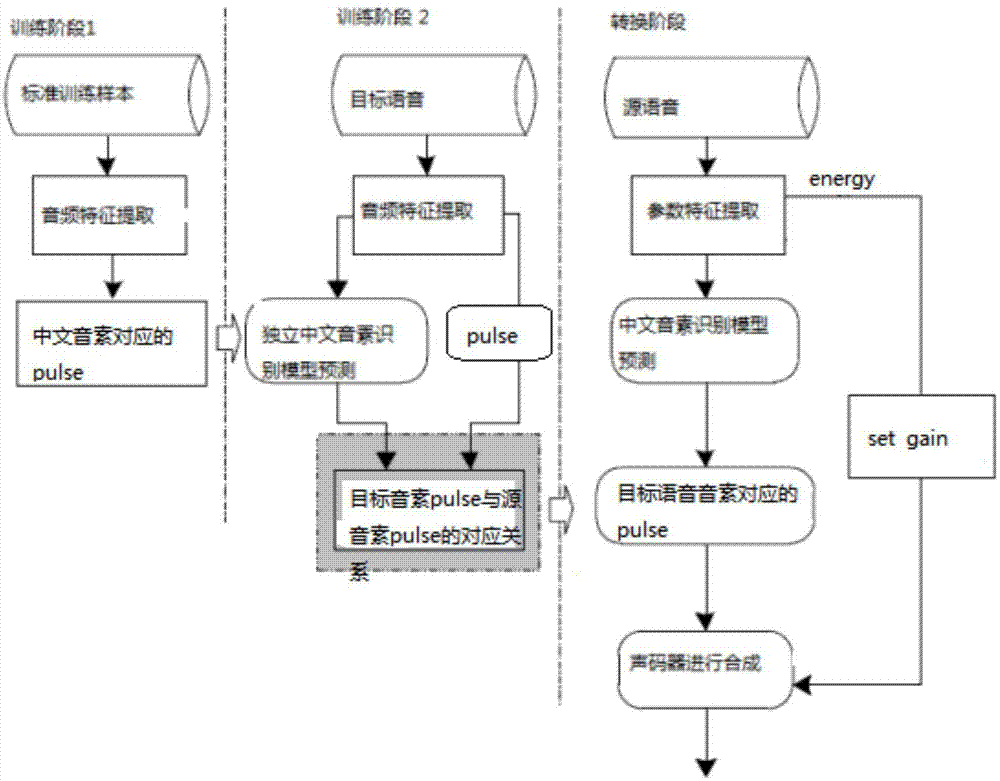
如图1所示,一种非平行语料语音个性化转换方法,包括以下步骤:
s1、根据文本采集目标语音,并对目标语音的文本和语音进行修正;
s2、将目标语音的中文音素对齐,得到目标语音中每个中文音素对应的音频;
s3、提取中文音素对应的音频特征和音素信息;
s4、训练hmm-gmm语音识别模型,并将提取的音频特征和音素信息输入到hmm-gmm语音识别模型中,得到目标语音音频特征与对应的中文音素之间的印射模型,印射模型用于对中文音素进行预测,通过预测的中文音素训练第一chbg网络;
s5、目标语音的中文音素通过第一chbg网络训练后,再通过对其训练dnn语言模型得到目标语音的音频特征对应的中文音素,并根据中文音素得到目标语音的pulse;
s6、通过训练第二chbg网络得到原语音的中文音素对应的pulse与目标语音的中文音素对应的pulse的对应模型;
s7、将dnn语言模型和chbg网络串联即可将原语音转换为目标语音。
本实施例中,所述步骤s1中在录音棚中采集至少1000句同一人物的语音作为目标语音,语音的采样频率为48000hz,所采集的目标语音中包含22个声母,39个韵母以及声调组合成的217个中文音素。
本实施例中,所述步骤s2中,将目标语音的中文音素对齐的具体步骤为通过人工分割得到目标语音的音频分割后的label文件,通过hmm-gmm语音识别模型对其进行训练,得到目标语音中每个中文音素对应的音频。
本实施例中,所述步骤s3中,提取的音频特征包括lsf特征、hnr特征和gain特征,采用加窗分帧的傅里叶变化进行提取,其中窗长为0.025s,采样频率为16000hz,对音频特征进行提取时,f0特征1维,gain特征1维,hnr特征5维,lsfsource特征10维,lsf特征30维。
本实施例中,所述chbg网络包括:
卷积神经网络(converlution),用于对原语音的音频进行特征训练,且卷积神经网络包括256个卷积核,采用depthwiseconvolution提高了卷积运算的速度;
高速神经网络(highwaynet),用于处理卷积信息,并对卷积结果进行归一化;
双向神经网络(bi-directional),用于对不同时刻的高速神经网络的参数进行更新;
gru神经网络,gru神经网络作为lstm的一种变体,用于将忘记门和输入门合成一个单一的更新门。
本实施例中,所述步骤s7具体如下:
将dnn语言模型和chbg网络串联,以原语音的中文音素对应的pulse与目标语音的中文音素对应的pulse作为中间媒介将原语音转换为目标语音,并通过pulsemodel后端处理工具将pulse进行合成。
本实施例通过对目标语音的音频训练hmm-gmm语音识别模型,利用lsf(linespectralfrequencies),gain,hnr(harmonic-to-noiseratio)音频特征进行音频的对应中文音素前端对齐和分割,并将对应中文音素通过深度学习的第一chbg网络和dnn语言模型得到目标语音的pulse,再通过训练第二chbg网络得到原语音的中文音素对应的pulse与目标语音的中文音素对应的pulse的对应模型,转换时将和第二chbg网络混合在一起,通过dnn语言模型找到对应中文音素在目标语音中的pulse,再通过第二chbg网络得到原语音对应的中文音素的在目标语音中的pulse,将中文音素作为训练的桥梁,将不同声音特征的目标语音和原语音的pulse关联起来,即可完成原语音到目标语音的转换。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!