一种声纹鉴权训练方法及系统与流程
本发明涉及生物识别技术,尤其涉及声纹识别,具体来说,尤其与一种利用深度学习方法的声纹鉴权训练方法及系统。
背景技术:
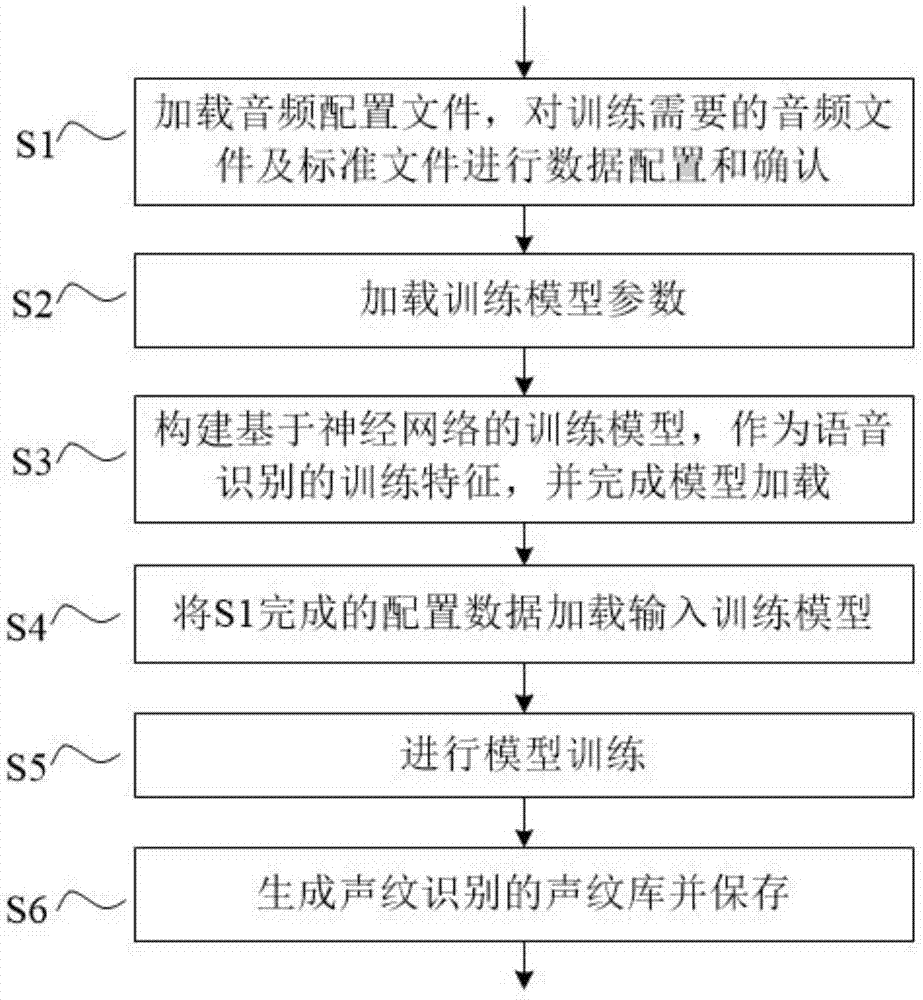
:传统的方法i-vector方法认为说话内容可以被分为两个部分,一个部分依赖于说话者和信道可变性,另一个部分依赖于其它的相关因素。i-vector声纹识别是一个多步过程,其涉及到使用不同说话者的数据来估计一个通用的背景模型,通常是高斯混合模型,收集充分的统计数据,提取i-vector,最后使用一个分类器来进行识别任务。传统的方法i-vector方法,业界的声纹识别率处于70%左右,且与文本相关。技术实现要素:本发明提供一种与文本无关的声纹识别手段,具体是一种利用深度学习方法的声纹鉴权训练方法及系统,通过构建神经网络,使用softmax分类和基于余弦相似性的三元组损失进行训练评估,识别精度高达到94.45%,相比于传统的i-vector方法,准确率提高了近30%。本发明采用以下技术:一种声纹鉴权训练方法,其特征在于,包括以下步骤:加载音频配置文件,对训练需要的音频文件及标准文件进行数据配置和确认;加载训练模型参数,参数包括训练集大小、训练的帧数和音频语谱图;构建基于神经网络的训练模型,作为语音识别的训练特征,并完成模型加载;将完成的配置数据加载输入训练模型;进行模型训练:通过预训练来初始化神经网络的权重,初始化采用he初始化;通过分类器进行处理,分类器采用sofmax多类分类器;通过余弦相似性的三元组损失函数进行评估;通过归一化处理使评估数据标准化,归一化采用l2-nomarl;生成声纹识别的声纹库并保存。进一步,所述训练模型参数,包括训练集大小、训练的帧数和音频语谱图。进一步,所述训练集大小,是每个训练样本对应一段语音的连续语谱图的时长。进一步,所述音频语谱图,使用的是维度为(32,32,3)的伪图相。进一步,所述神经网络为rescnn神经网络的参数为:卷积块conv3×3、滤波器的尺寸3×3、两个方向上的零填充1、连续跨步1×1参数化。一种声纹鉴权训练系统,其特征在于,包括:音频配置模块,用于加载音频配置文件,对训练需要的音频文件及标准文件进行数据配置和确认;参数加载模块,用于加载训练模型参数;模型构建模块,用于构建基于神经网络的训练模型,作为语音识别的训练特征,并完成模型加载;数据输入模块,用于将音频配置模块完成的配置数据加载输入训练模型;模型训练模块,用于进行模型训练;存储模块,用于将生成的声纹识别声纹库进行保存。其中,所述模型训练模块包括:预训单元,用于通过预训练来初始化神经网络的权重;分类单元,用于通过分类器进行处理;评估单元,用于通过余弦相似性的三元组损失函数进行评估;归一化单元,用于通过归一化处理使评估数据标准化。本发明有益效果:1、利用所设计的核心参数,构造rescnn神经网络,用于构建训练模型,并采用he初始化来初始化神经网络的权重,使用softmax分类和基于余弦相似性的三元组损失进行训练评估,识别精度高达到94.45%,相比于传统的i-vector方法,准确率提高了近30%;2、通过rescnn神经网络的构造参数设计,使rescnn由许多堆叠的残余块resblock组成,每个resblock包含较低层输出和较高的之间的直接链接,有效缓解非常深度的cnn的训练;3、he初始化不受三重损失中的可变难度的影响,交叉熵损失比三重态损失产生更稳定的收敛;当三元组选择随小批量增加而加快时,小批量随机梯度下降sgd具有更好的泛化能力;4、使用softmax分类训练10个周期,然后进行15个周期的三重损失评估训练;在整个25个周期的训练中,分类训练的神经网络可以达到比没有分类训练的神经网络更低的eer和更高的acc;5、在三重损失训评估过程中,进行了有效的转化:选择了一个说话者的话语,然后计算一个嵌入,标记为“anchor”。再产生两个嵌入,一个来自相同的演讲者,标记为“positive”,一个来自于不同的演讲者,标记为“negative”;在训练过程中,训练目标转换为让anchor与positive嵌入之间的余弦相似度高于anchor与negative嵌入之间的余弦相似度,提高了识别效率和精度。附图说明图1为本发明方法流程图。图2为本发明进行模型训练的方法流程图。图3为本发明系统结构图。图4为本发明模型训练模块的结构图。图5为本发明rescnn神经网络构造说明示意图。图6为本发明采用triplet-loss损失函数引入嵌入式向量的示意图。图7为本发明实施例训练结果图。具体实施方式为了使本申请的目的、技术方案和具体实施方法更为清楚,结合附图实例对本申请进行进一步详细说明。本训练方法实现了一个文本无关的声纹识别,主要涉及深度rescnn神经网络模型构建,从音频中提取特征,使用he初始化、使用softmax分类训练、使用基于余弦相似性的实现三元组损失tripletloss评估。在训练过程中,选择了一个说话者的话语,然后计算一个嵌入,标记为“anchor”。再产生两个嵌入,一个来自相同的演讲者,标记为“positive”,一个来自于不同的演讲者,标记为“negative”。在训练过程中,其目标是让anchor与positive嵌入之间的余弦相似度高于anchor与negative嵌入之间的余弦相似度。本发明训练方法具体实施步骤如图1~2所示:s1、加载音频配置文件:主要配置训练需要的音频文件及标准文件配置数据;并且确认配置数据;如完成数据加载步骤s2。s2、加载训练模型参数:加载训练模型的batch_size,frames,batch_shape,其中:batch_size是训练集大小,每个训练样本对应一段语音的连续语谱图,默认使用1s钟时间。frames是训练的帧数,batch_size为音频语谱图的,这里使用的维度是(32,32,3)的伪图相;如果加载完成执行s3。s3、构建基于神经网络的训练模型,作为语音识别的训练特征,并完成模型加载;完成模型加载执行s4。具体的:构造rescnn神经网络,采用的核心参数如下:卷积块conv3×3;滤波器的尺寸3×3;两个方向上的零填充1;以及连续跨步1×1参数化;构造rescnn神经网络的主要流程,如图5所示。s4、加载训练数据:将s1完成的配置数据加载输入训练模型,为rescnn神经网络提供输入数据,完成作为完成后执行s5。s5、进行模型训练:s51、使用he来初始化神经网络的权重。s52、通过sofmax分类器进行处理。s53、完成sofmax分类器处理后,通过余弦相似性的三元组损失函数进行评估处理。引入triplet-loss损失函数,用于指导神经网络训练网络的权重,且嵌入式向量是经过归一化的。如图6所示,从样本中随机取出三个样本,分别是positive、anchor、negative三个样本,其中positive和anchor是同类样本,anchor与negative是异类样本,训练神经网络的目的就是使得positive与anchor的距离更小,anchor和negative的距离更大。采用的三元组损失函数为:其中,a为可调范围在0~2的参数,表示同类样本positive和anchor嵌入式向量之间的余弦,表示异类样本negative和anchor嵌入式向量之间的余弦。s54、通过归一化处理使评估数据标准化。归一算法采用l2-nomarl,实现评估模型数据标准。s6、保存模型:生成声纹识别的声纹库并保存。本发明训练系统结构如图3~4所示,用于实现本发明的训练方法。一种声纹鉴权训练系统,包括:音频配置模块,用于加载音频配置文件,对训练需要的音频文件及标准文件进行数据配置和确认;参数加载模块,用于加载训练模型参数;模型构建模块,用于构建基于神经网络的训练模型,作为语音识别的训练特征,并完成模型加载;数据输入模块,用于将音频配置模块完成的配置数据加载输入训练模型;模型训练模块,用于进行模型训练;存储模块,用于将生成的声纹识别声纹库进行保存。具体的,所述模型训练模块包括:预训单元,用于通过预训练来初始化神经网络的权重;分类单元,用于通过分类器进行处理;评估单元,用于通过余弦相似性的三元组损失函数进行评估;归一化单元,用于通过归一化处理使评估数据标准化。具体的,所述模型构建模块,用于构建基于rescnn神经网络的训练模型,其中,rescnn神经网络的参数为:卷积块conv3×3、滤波器的尺寸3×3、两个方向上的零填充1、连续跨步1×1参数化,如图5所示。训练结果说明:实验测试条件使用了一块nvidia-gtx1080ti的gpu进行模型训练。采用音频数据源:清华的thchs30,2017年论文库st-cmds-20170001_1-os以及aishell库;共计词条15w左右的80g,45小时的数据。从下载的音频数据源生成配置文件,并放置到代码的数据目录,完成训练需要的音频文件及标准文件数据配置。将配置的数据加载输入所构建的训练模型进行训练:使用he初始化预训练来初始化神经网络的权重。输入sofmax分类器进行处理。完成sofmax分类器处理后,通过余弦相似性实现的三元组损失函数进行训练评估。根据损失函数,训练网络的过程中,同类样本的嵌入式向量之间的余玄距离越来越小,即同类嵌入式向量具有内聚性。异类样本的嵌入式向量之间的余玄距离越来越大,即异类嵌入式向量具有扩张性。根据内聚性和扩张性,输出样本会出现遍布与空间的聚落,同一聚落是同类样本的概率较大,不同聚落是不同样本之间的概率也较大,容易把异类样本区分开来。完成评估后,通过归一化处理使评估数据标准化。he初始化网络权重不受三重损失中的可变难度的影响,交叉熵损失比三重态损失产生更稳定的收敛。当三元组选择随小批量增加而加快时,小批量随机梯度下降sgd具有更好的泛化能力。使用softmax分类训练10个周期,然后进行15个周期的三重损失训练评估。在整个25个周期的训练中,分类训练的神经网络可以达到比没有分类训练的神经网络更低的eer和更高的acc。保存模型:生成声纹识别的声纹库并保存。实验结果:如图7可知,在10个echo训练时,测试机趋于稳定时,稳定精确度在94.45%范围上摆动;样本特征提取所需要时间为:训练次数时间测试精确度120万68小时21分钟94.45实验结果表明:本方法要明显优于传统的i-vector方法。若在一个文本独立的数据集中随机挑选出50个演讲者,本方法在说话者身份确认任务上的正确率是94.5%。相比于传统的i-vector方法,提高了30%的正确率。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1