声纹模型构建方法、声纹识别方法及系统与流程
本发明涉及声纹识别技术领域,特别是一种声纹模型构建方法、声纹识别方法及系统。
背景技术:
声纹类似于指纹,是一个人特有的信息,一个人说的不同的话,其声纹应该是一致的,因此,通过声纹识别可以对说话人进行识别,在目前的语音处理中,“声纹识别”是一项重要的研究内容,如何提高声纹识别的准确率是目前亟待解决的问题。
技术实现要素:
有鉴于此,本发明的目的在于提供一种声纹模型构建方法、声纹识别方法及系统,有利于提高声纹识别的准确率。
为达到上述目的,本发明的技术方案提供了一种声纹模型构建方法,包括:
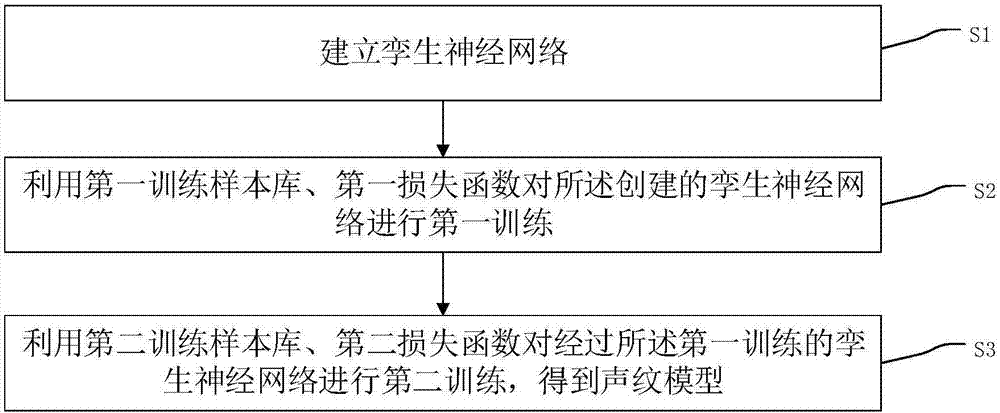
步骤s1:建立孪生神经网络,所述孪生神经网络包括两个相同的子网,每一个所述子网包括特征提取模块以及特征表达模块,所述特征提取模块包括多个带通滤波器,所述特征表达模块包括若干个卷积层和若干个全连接层;
步骤s2:利用第一训练样本库、第一损失函数对所述创建的孪生神经网络进行第一训练,其中,所述第一训练样本库由同一人的多个音频文件构成,在所述第一训练的过程中,通过所述创建的孪生神经网络对所述第一训练样本库中的音频文件进行声纹矢量化,以从其中每一个音频文件中抽取声纹向量,通过所述第一损失函数,使得从同一人的不同音频文件中抽取的声纹向量之间的相似度最大化;
步骤s3:利用第二训练样本库、第二损失函数对经过所述第一训练的孪生神经网络进行第二训练,得到声纹模型,其中,所述第二训练样本库包括正样本集和负样本集,所述正样本集由同一目标人的多个音频文件构成,所述负样本集由非目标人的多个音频文件构成,在所述第二训练的过程中,通过经过所述第一训练的孪生神经网络对所述第二训练样本库中的音频文件进行声纹矢量化,以从其中每一个音频文件中抽取声纹向量,通过所述第二损失函数,使得从不同人的不同音频文件中抽取的声纹向量之间的相似度最小化。
进一步地,所述步骤s2包括:
从第一训练样本库抽取l组音频文件,每一组音频文件包括两个音频文件;
对于所述l组音频文件中的每一组音频文件,在利用所述创建的孪生神经网络对其中的音频文件进行声纹矢量化后,采用cosine相似度计算方式得到其中两个音频文件的声纹向量之间的相似度;
利用所述第一损失函数计算损失值loss_1;
其中,ni为所述l组音频文件中第i组音频文件中两个音频文件的声纹向量之间的相似度;
利用损失值loss_1调整所述创建的孪生神经网络。
进一步地,所述步骤s3包括:
从第二训练样本库抽取m组音频文件,每一组音频文件包括正样本集中的一个音频文件和负样本集中的一个音频文件;
对于所述m组音频文件中的每一组音频文件,在利用经过所述第一训练的孪生神经网络对其中的音频文件进行声纹矢量化后,采用cosine相似度计算方式得到其中两个音频文件的声纹向量之间的相似度;
利用所述第二损失函数计算损失值loss_2;
其中,ki为所述m组音频文件中第i组音频文件中两个音频文件的声纹向量之间的相似度;
利用损失值loss_2调整经过所述第一训练的孪生神经网络。
进一步地,每一个所述子网中的特征提取模块包括n个带通滤波器,其中第i个带通滤波器的公式为:
g[i,f1,f2]=2f2sinc(2πf2i)-2f1sinc(2πf1i);
其中,i=1,2,...,n,
为实现上述目的,本发明的技术方案还提供了一种声纹识别方法,包括:
将待识别的两个音频文件输入利用上述声纹模型构建方法构建的声纹模型中,得到所述待识别的两个音频文件的声纹向量;
计算所述待识别的两个音频文件的声纹向量之间的相似度;
根据所述待识别的两个音频文件的声纹向量之间的相似度判断所述待识别的两个音频文件是否来自同一个人。
为实现上述目的,本发明的技术方案还提供了一种声纹模型构建系统,包括:
建立模块,用于建立孪生神经网络,所述孪生神经网络包括两个相同的子网,每一个所述子网包括特征提取模块以及特征表达模块,所述特征提取模块包括多个带通滤波器,所述特征表达模块包括若干个卷积层和若干个全连接层;
第一训练模块,用于利用第一训练样本库、第一损失函数对所述创建的孪生神经网络进行第一训练,其中,所述第一训练样本库由同一人的多个音频文件构成,在所述第一训练的过程中,通过所述创建的孪生神经网络对所述第一训练样本库中的音频文件进行声纹矢量化,以从其中每一个音频文件中抽取声纹向量,通过所述第一损失函数,使得从同一人的不同音频文件中抽取的声纹向量之间的相似度最大化;
第二训练模块,用于利用第二训练样本库、第二损失函数对经过所述第一训练的孪生神经网络进行第二训练,得到声纹模型,其中,所述第二训练样本库包括正样本集和负样本集,所述正样本集由同一目标人的多个音频文件构成,所述负样本集由非目标人的多个音频文件构成,在所述第二训练的过程中,通过经过所述第一训练的孪生神经网络对所述第二训练样本库中的音频文件进行声纹矢量化,以从其中每一个音频文件中抽取声纹向量,通过所述第二损失函数,使得从不同人的不同音频文件中抽取的声纹向量之间的相似度最小化。
进一步地,所述第一训练模块包括:
第一抽取单元,用于从第一训练样本库抽取l组音频文件,每一组音频文件包括两个音频文件;
第一处理单元,用于对于所述l组音频文件中的每一组音频文件,在利用所述创建的孪生神经网络对其中的音频文件进行声纹矢量化后,采用cosine相似度计算方式得到其中两个音频文件的声纹向量之间的相似度;
第一计算单元,用于利用所述第一损失函数计算损失值loss_1;
其中,ni为所述l组音频文件中第i组音频文件中两个音频文件的声纹向量之间的相似度;
第一调整单元,用于利用损失值loss_1调整所述创建的孪生神经网络。
进一步地,所述第二训练模块包括:
第二抽取单元,用于从第二训练样本库抽取m组音频文件,每一组音频文件包括正样本集中的一个音频文件和负样本集中的一个音频文件;
第二处理单元,用于对于所述m组音频文件中的每一组音频文件,在利用经过所述第一训练的孪生神经网络对其中的音频文件进行声纹矢量化后,采用cosine相似度计算方式得到其中两个音频文件的声纹向量之间的相似度;
第二计算单元,用于利用所述第二损失函数计算损失值loss_2;
其中,ki为所述m组音频文件中第i组音频文件中两个音频文件的声纹向量之间的相似度;
第二调整单元,用于利用损失值loss_2调整经过所述第一训练的孪生神经网络。
进一步地,每一个所述子网中的特征提取模块包括n个带通滤波器,其中第i个带通滤波器的公式为:
g[i,f1,f2]=2f2sinc(2πf2i)-2f1sinc(2πf1i);
其中,i=1,2,...,n,
为实现上述目的,本发明的技术方案还提供了一种声纹识别系统,包括:
输入模块,用于将待识别的两个音频文件输入利用上述声纹模型构建系统构建的声纹模型中,得到所述待识别的两个音频文件的声纹向量;
计算模块,用于计算所述待识别的两个音频文件的声纹向量之间的相似度;
判断模块,用于根据所述待识别的两个音频文件的声纹向量之间的相似度判断所述待识别的两个音频文件是否来自同一个人。
本发明提供的声纹模型构建方法,采用孪生网络的思想对声纹模型的网络结构进行设计,并通过第一训练和第二训练实现声纹模型对不同人的音频声纹进行聚类,使训练后得到的声纹模型能够有效对音频文件进行声纹矢量化,从而有利于提高声纹识别的准确率。
附图说明
通过以下参照附图对本发明实施例的描述,本发明的上述以及其它目的、特征和优点将更为清楚,在附图中:
图1是本发明实施例提供的一种声纹模型构建方法的流程图;
图2是本发明实施例提供的一种孪生神经网络中子网的示意图;
图3是本发明实施例提供的对孪生神经网络进行第一训练的示意图;
图4是本发明实施例提供的对孪生神经网络进行第二训练的示意图;
图5是本发明实施例提供的一种声纹模型构建系统的示意图。
具体实施方式
以下基于实施例对本发明进行描述,但是本发明并不仅仅限于这些实施例。在下文对本发明的细节描述中,详尽描述了一些特定的细节部分,为了避免混淆本发明的实质,公知的方法、过程、流程、元件并没有详细叙述。
此外,本领域普通技术人员应当理解,在此提供的附图都是为了说明的目的,并且附图不一定是按比例绘制的。
除非上下文明确要求,否则整个说明书和权利要求书中的“包括”、“包含”等类似词语应当解释为包含的含义而不是排他或穷举的含义;也就是说,是“包括但不限于”的含义。
在本发明的描述中,需要理解的是,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
参见图1,图1是本发明实施例提供的一种声纹模型构建方法的流程图,该方法包括:
步骤s1:建立孪生神经网络,所述孪生神经网络包括两个相同的子网,每一个所述子网包括用于特征提取的特征提取模块以及用于特征表达的特征表达模块,其中,所述特征提取模块包括多个带通滤波器,所述特征表达模块包括若干个卷积层和若干个全连接层;
例如,特征表达模块包括1、2或3个卷积层以及1、2或3个全连接层;
步骤s2:利用第一训练样本库、第一损失函数对所述创建的孪生神经网络进行第一训练,其中,所述第一训练样本库由同一人的多个音频文件构成,在所述第一训练的过程中,通过所述创建的孪生神经网络对所述第一训练样本库中的音频文件进行声纹矢量化,以从其中每一个音频文件中抽取声纹向量,通过所述第一损失函数,使得从同一人的不同音频文件中抽取的声纹向量之间的相似度最大化;
步骤s3:利用第二训练样本库、第二损失函数对经过所述第一训练的孪生神经网络进行第二训练,得到声纹模型,其中,所述第二训练样本库包括正样本集和负样本集,所述正样本集由同一目标人的多个音频文件构成,所述负样本集由非目标人的多个音频文件构成,在所述第二训练的过程中,通过经过所述第一训练的孪生神经网络对所述第二训练样本库中的音频文件进行声纹矢量化,以从其中每一个音频文件中抽取声纹向量,通过所述第二损失函数,使得从不同人的不同音频文件中抽取的声纹向量之间的相似度最小化。
本发明实施例提供的声纹模型构建方法,采用孪生网络的思想对声纹模型的网络结构进行设计,并通过第一训练和第二训练实现声纹模型对不同人的音频声纹进行聚类,使训练后得到的声纹模型能够有效对音频文件进行声纹矢量化,从而有利于提高声纹识别的准确率。
例如,本发明实施例提供的声纹模型构建方法可以具体包括:
步骤a:建立孪生神经网络,其中,该孪生神经网络包括两个相同的子网,子网采用sincnet结构,如图2所示,每一个子网包括特征提取模块以及特征表达模块,每一个子网中的特征表达模块包括3个卷积层(conv)和2个全连接层(fc)(包含一般的池化层、激活层、drop-out层等),每一个子网中的特征提取模块包括n个带通滤波器(g1,g2,…,gn),其中第i个带通滤波器的公式为:
g[i,f1,f2]=2f2sinc(2πf2i)-2f1sinc(2πf1i);
其中,i=1,2,...,n,
sincnet的核心思想是使用多个带通滤波器过滤出有用的信息(即特征信息),带通滤波器作为网络的一部分与特征表达过程一起参与训练,其参数由训练得到,在本实施例中,通过sincnet结构的子网从音频文件(wav文件)中提取特征信息,并进行特征表达,从而将wav数据转化成向量形式,即实现声纹矢量化;
其中,在本实施例中,带通滤波器的数量n为预设值,可根据实际情况进行调整,带通滤波器过滤后得到的数据(即特征信息)输入至特征表达模块,在特征表达模块中利用3个卷积层进行三次卷积运算后,再通过两层全连接层(包含一般的池化层、激活层、drop-out层等)最后输出向量v(即为声纹向量);
步骤b:利用第一训练样本库、第一损失函数对步骤a创建的孪生神经网络进行第一训练(即预训练),其中,该第一训练样本库由同一人的多个音频文件构成;
即在该步骤中,使用每个说话人的多个音频对孪生神经网络进行单人预训练,将同一个人的两段不同语音输入创建的孪生神经网络,loss函数(即损失函数)采用loss_1,即最大化从同一个人的不同音频文件中抽取的声纹向量之间的相似度,具体地,参见图3,该步骤包括:
步骤b1:从第一训练样本库抽取l组音频文件,每一组音频文件包括两个音频文件,l为不小于2的正整数;
步骤b2:对于所述l组音频文件中的每一组音频文件,在利用所述创建的孪生神经网络对其中的音频文件进行声纹矢量化后(即通过孪生神经网络中的一个子网对每一组音频文件中的一个音频文件wav1进行声纹矢量化,通过另一个子网对每一组音频文件中的另一个音频文件wav2进行声纹矢量化),采用cosine相似度计算方式得到其中两个音频文件的声纹向量之间的相似度(即从两个音频文件中抽取的声纹向量之间的相似度);
cosine相似度是计算向量空间中两个向量方向差异大小的方法,在本发明中,假设一个人的声纹特征随着声音的大小、环境、身体健康状况、年龄、心情等情况会有一定的变化,进而反应到向量空间上即是向量长度和相位角度的变化,但是不管情况如何变化,属于同一个人的一些固有的声纹特征是不会变的,因此,声纹向量的这种变化幅度应该是非常小的,则可以认为两个相近的声纹向量即为同一个说话人,其中,cosine相似度的计算公式如下:
其中,v1为两个音频文件中一个音频文件的声纹向量,v2为另一个音频文件的声纹向量;
步骤b3:利用所述第一损失函数计算损失值loss_1,其中,该第一损失函数的公式如下:
其中,ni为所述l组音频文件中第i组音频文件中两个音频文件的声纹向量之间的相似度;
步骤b4:利用损失值loss_1调整所述创建的孪生神经网络。
步骤c:利用第二训练样本库、第二损失函数对经过所述第一训练的孪生神经网络进行第二训练(即再训练),得到声纹模型,其中,所述第二训练样本库包括正样本集和负样本集,所述正样本集由同一目标人的多个音频文件构成,所述负样本集由非目标人的多个音频文件构成;
即在该步骤中,在对孪生神经网络预训练完成后采用不同人的不同音频文件继续对孪生神经网络进行训练,在该步骤中,可从所有的说话人中随机抽取一个人作为目标人,将目标人的所有音频视为正样本,得到正样本集,非目标人的所有音频视为负样本,得到负样本集,每次训练时从正样本集中抽取p_n个正样本,从负样本集中随机抽取n_n个负样本,p_n与n_n可以不相等但是差距不应该过大,正负样本的比例不要超过1∶5,以保证训练结果不受样本不均衡影响,loss函数(即损失函数)采用loss_2,即最小化从不同人的不同音频中抽取的声纹向量之间的相似度,具体地,参见图4,该步骤具体包括:
步骤c1:从第二训练样本库抽取m组音频文件,每一组音频文件包括正样本集中的一个音频文件和负样本集中的一个音频文件,m为不小于2的正整数;
步骤c2:对于所述m组音频文件中的每一组音频文件,在利用经过所述第一训练的孪生神经网络对其中的音频文件进行声纹矢量化后(即通过孪生神经网络中的一个子网对每一组音频文件中的一个音频文件wav1′进行声纹矢量化,通过另一个子网对每一组音频文件中的另一个音频文件wav2′进行声纹矢量化),采用cosine相似度计算方式得到其中两个音频文件的声纹向量之间的相似度;
步骤c3:利用所述第二损失函数计算损失值loss_2,其中,该第二损失函数如下:
其中,ki为所述m组音频文件中第i组音频文件中两个音频文件的声纹向量之间的相似度;
步骤c4:利用损失值loss_2调整经过所述第一训练的孪生神经网络,得到声纹模型。
本发明实施例提供的声纹模型构建方法在端对端的网络结构基础上结合孪生网络的思想,对声纹模型的网络结构进行了设计,并采取预训练和再训练两个步骤实现对不同人的音频声纹进行聚类,使训练后得到的声纹模型能够有效对音频文件进行声纹矢量化,能够判断不同音频是否来自同一个说话人,有利于提高声纹识别的准确率;且在本发明实施例中,通过两步训练和聚类,训练的过程清楚,结果可控性高,并且在使用sinect结构模型的基础上进行设计,相对cnn等模型能够大大减少参数数量,训练速度更快。
通过上述声纹模型构建方法构建的声纹模型,其中每一个子网的特征提取模块可作为一个声纹特征提取器,再利用特征表达模块对提取的特征进行特征表达,从而实现对声纹的矢量化,得到声纹向量,可应用到声纹识别等场景任务中去。
本发明实施例还提供了一种音频文件矢量化方法,包括:利用上述声纹模型构建方法构建的声纹模型中的子网对待处理的音频文件进行声纹矢量化,得到所述待处理的音频文件的声纹向量。
通过上述声纹模型构建方法构建的声纹模型可对待识别的两个音频文件进行声纹矢量化,再通过待识别的两个音频文件的声纹向量之间的相似度可以判断两个音频文件是否来自同一个人;
本发明实施例还提供了一种声纹识别方法,包括:
步骤s101:将待识别的两个音频文件输入利用上述声纹模型构建方法构建的声纹模型中,得到所述待识别的两个音频文件的声纹向量;
步骤s102:计算所述待识别的两个音频文件的声纹向量之间的相似度;
例如,可以采用cosine相似度计算方式得到待识别的两个音频文件的声纹向量之间的相似度;
步骤s103:根据所述待识别的两个音频文件的声纹向量之间的相似度判断所述待识别的两个音频文件是否来自同一个人;
例如,若待识别的两个音频文件的声纹向量之间的相似度大于预设值,则判断为同一个人,否则判断为不同的人。
参见图5,图5是本发明实施例提供的一种声纹模型构建系统的示意图,该系统包括:
建立模块1,用于建立孪生神经网络,所述孪生神经网络包括两个相同的子网,每一个所述子网包括特征提取模块以及特征表达模块,所述特征提取模块包括多个带通滤波器,所述特征表达模块包括若干个卷积层和若干个全连接层;
第一训练模块2,用于利用第一训练样本库、第一损失函数对所述创建的孪生神经网络进行第一训练,其中,所述第一训练样本库由同一人的多个音频文件构成,在所述第一训练的过程中,通过所述创建的孪生神经网络对所述第一训练样本库中的音频文件进行声纹矢量化,以从其中每一个音频文件中抽取声纹向量,通过所述第一损失函数,使得从同一人的不同音频文件中抽取的声纹向量之间的相似度最大化;
第二训练模块3,用于利用第二训练样本库、第二损失函数对经过所述第一训练的孪生神经网络进行第二训练,得到声纹模型,其中,所述第二训练样本库包括正样本集和负样本集,所述正样本集由同一目标人的多个音频文件构成,所述负样本集由非目标人的多个音频文件构成,在所述第二训练的过程中,通过经过所述第一训练的孪生神经网络对所述第二训练样本库中的音频文件进行声纹矢量化,以从其中每一个音频文件中抽取声纹向量,通过所述第二损失函数,使得从不同人的不同音频文件中抽取的声纹向量之间的相似度最小化。
在一实施例中,所述第一训练模块包括:
第一抽取单元,用于从第一训练样本库抽取l组音频文件,每一组音频文件包括两个音频文件;
第一处理单元,用于对于所述l组音频文件中的每一组音频文件,在利用所述创建的孪生神经网络对其中的音频文件进行声纹矢量化后,采用cosine相似度计算方式得到其中两个音频文件的声纹向量之间的相似度;
第一计算单元,用于利用所述第一损失函数计算损失值loss_1;
其中,ni为所述l组音频文件中第i组音频文件中两个音频文件的声纹向量之间的相似度;
第一调整单元,用于利用损失值loss_1调整所述创建的孪生神经网络。
在一实施例中,所述第二训练模块包括:
第二抽取单元,用于从第二训练样本库抽取m组音频文件,每一组音频文件包括正样本集中的一个音频文件和负样本集中的一个音频文件;
第二处理单元,用于对于所述m组音频文件中的每一组音频文件,在利用经过所述第一训练的孪生神经网络对其中的音频文件进行声纹矢量化后,采用cosine相似度计算方式得到其中两个音频文件的声纹向量之间的相似度;
第二计算单元,用于利用所述第二损失函数计算损失值loss_2;
其中,ki为所述m组音频文件中第i组音频文件中两个音频文件的声纹向量之间的相似度;
第二调整单元,用于利用损失值loss_2调整经过所述第一训练的孪生神经网络。
在一实施例中,每一个所述子网中的特征提取模块包括n个带通滤波器,其中第i个带通滤波器的公式为:
g[i,f1,f2]=2f2sinc(2πf2i)-2f1sinc(2πf1i);
其中,i=1,2,...,n,
本发明实施例还提供了一种音频文件矢量化系统,所述音频文件矢量化系统利用上述声纹模型构建系统构建的声纹模型中的子网对待处理的音频文件进行声纹矢量化,得到所述待处理的音频文件的声纹向量。
本发明实施例还提供了一种声纹识别系统,包括:
输入模块,用于将待识别的两个音频文件输入上述声纹模型构建系统构建的声纹模型中,得到所述待识别的两个音频文件的声纹向量;
计算模块,用于计算所述待识别的两个音频文件的声纹向量之间的相似度;
判断模块,用于根据所述待识别的两个音频文件的声纹向量之间的相似度判断所述待识别的两个音频文件是否来自同一个人。
本领域的技术人员容易理解的是,在不冲突的前提下,上述各优选方案可以自由地组合、叠加。
应当理解,上述的实施方式仅是示例性的,而非限制性的,在不偏离本发明的基本原理的情况下,本领域的技术人员可以针对上述细节做出的各种明显的或等同的修改或替换,都将包含于本发明的权利要求范围内。
- 还没有人留言评论。精彩留言会获得点赞!