一种语音数据处理方法及装置与流程
本发明涉及数据通信技术领域,具体而言,涉及一种语音数据处理方法及装置。
背景技术:
目前,智能手机、平板电脑、计算机等电子设备均具有录音功能,能够接收并记录周围场景的声音信息,进而可以通过其安装的应用程序对记录的声音信息进行进一步处理。在实践中发现,当电子设备上安装有多个需要对周围场景的声音信息进行处理的软件(如录音应用程序、语音识别应用程序等)时,当同时开启语音识别应用程序和录音应用程序进行音频处理时,两个应用程序无法同时获取到麦克风输入的音频数据,进而导致两个应用程序无法同时对输入的音频数据进行处理。
技术实现要素:
鉴于上述问题,本发明提供了一种语音数据处理方法及装置,能够实现多个应用程序获取到麦克风输入的音频数据,进而使得多个应用程序能够同时对输入的音频数据进行处理。
为了实现上述目的,本发明采用如下的技术方案:
本发明第一方面公开了一种语音数据处理方法,包括:
接收输入的原始语音数据;
确定需要获取所述原始语音数据的多个应用程序;
对所述原始语音数据进行分流处理,得到多个分流语音数据包,其中,所述多个分流语音数据包的数量与所述多个应用程序的数量相同,每个所述分流语音数据包的语音内容都与所述原始语音数据的语音内容相同;
向每个所述应用程序发送一个所述分流语音数据包。
作为一种可选的实施方式,在本发明第一方面中,对所述原始语音数据进行分流处理,得到多个分流语音数据包包括:
对所述原始语音数据进行预处理,得到预处理语音数据;
根据所述预处理语音数据,生成多个镜像语音数据包,其中,所述多个镜像语音数据包与所述多个应用程序一一对应;
根据预存的文件格式对照表,确定每个应用程序所支持的语音数据的文件格式;
将每个所述镜像语音数据包的文件格式转换为与该镜像语音数据包对应的应用程序所支持的文件格式,从而得到与每个应用程序对应的分流语音数据包。
作为一种可选的实施方式,在本发明第一方面中,对所述原始语音数据进行预处理,得到预处理语音数据,包括:
对所述原始语音数据进行语音增强处理,以去除所述原始语音数据中的干扰数据,得到去噪语音数据;
对所述处理语音数据进行端点检测处理,以去除所述处理语音数据中的静音数据段,得到预处理语音数据。
作为一种可选的实施方式,在本发明第一方面中,向每个所述应用程序发送一个所述分流语音数据包,包括:
根据预存的文件传输方式表,通过与每个所述应用程序对应的传输方式,将每个所述分流语音数据包发送至与该分流语音数据包对应的应用程序。
作为一种可选的实施方式,在本发明第一方面中,所述文件格式对照表包括多个应用程序标识以及与每个应用程序标识对应的语音数据的文件格式。
本发明第二方面公开一种语音数据处理装置,包括:
接收模块,用于接收输入的原始语音数据;
确定模块,用于确定需要获取所述原始语音数据的多个应用程序;
分流模块,用于对所述原始语音数据进行分流处理,得到多个分流语音数据包,其中,所述多个分流语音数据包的数量与所述多个应用程序的数量相同,每个所述分流语音数据包的语音内容都与所述原始语音数据的语音内容相同;
发送模块,用于向每个所述应用程序发送一个所述分流语音数据包。
作为一种可选的实施方式,在本发明第二方面中,所述分流模块,包括:
预处理子模块,用于对所述原始语音数据进行预处理,得到预处理语音数据;
生成子模块,用于根据所述预处理语音数据,生成多个镜像语音数据包,其中,所述多个镜像语音数据包与所述多个应用程序一一对应;
确定子模块,用于根据预存的文件格式对照表,确定每个应用程序所支持的语音数据的文件格式;
转换子模块,用于将每个所述镜像语音数据包的文件格式转换为与该镜像语音数据包对应的应用程序所支持的文件格式,从而得到与每个应用程序对应的分流语音数据包。
作为一种可选的实施方式,在本发明第二方面中,所述预处理子模块,包括:
语音增强单元,用于在所述接收输入的原始语音数据之后,对所述原始语音数据进行语音增强处理,以去除所述原始语音数据中的干扰数据,得到处理语音数据;
端点检测单元,用于对所述处理语音数据进行端点检测处理,以去除所述处理语音数据中的静音数据段,得到纯语音数据。
本发明第三方面公开一种计算机设备,包括存储器以及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述计算机设备执行第一方面公开的部分或者全部所述的语音数据处理方法。
本发明第四方面公开一种计算机可读存储介质,其存储有第三方面所述的计算机设备中所使用的所述计算机程序。
根据本发明提供的语音数据处理方法及装置,先通过拾音装置接收输入的原始语音数据;确定需要获取原始语音数据的多个应用程序;对原始语音数据进行分流处理,得到多个分流语音数据包,其中,多个分流语音数据包的数量与多个应用程序的数量相同,每个分流语音数据包的语音内容都与原始语音数据的语音内容相同;向每个应用程序发送一个分流语音数据包,实现多个应用程序获取到麦克风输入的音频数据,进而使得多个应用程序能够同时对输入的音频数据进行处理。
为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对本发明范围的限定。
图1是本发明实施例一提供的一种语音数据处理方法的流程示意图;
图2是本发明实施例二提供的一种语音数据处理方法的流程示意图;
图3是本发明实施例三提供的一种语音数据处理装置的结构示意图。
具体实施方式
下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
针对现有技术中的问题,本发明提供了一种语音数据处理方法及装置;该技术可以先通过拾音装置接收输入的原始语音数据;确定需要获取原始语音数据的多个应用程序;对原始语音数据进行分流处理,得到多个分流语音数据包,其中,多个分流语音数据包的数量与多个应用程序的数量相同,每个分流语音数据包的语音内容都与原始语音数据的语音内容相同;向每个应用程序发送一个分流语音数据包,实现多个应用程序获取到麦克风输入的音频数据,进而使得多个应用程序能够同时对输入的音频数据进行处理。并且,该技术可以采用相关的软件或硬件实现,下面通过实施例进行描述。
实施例1
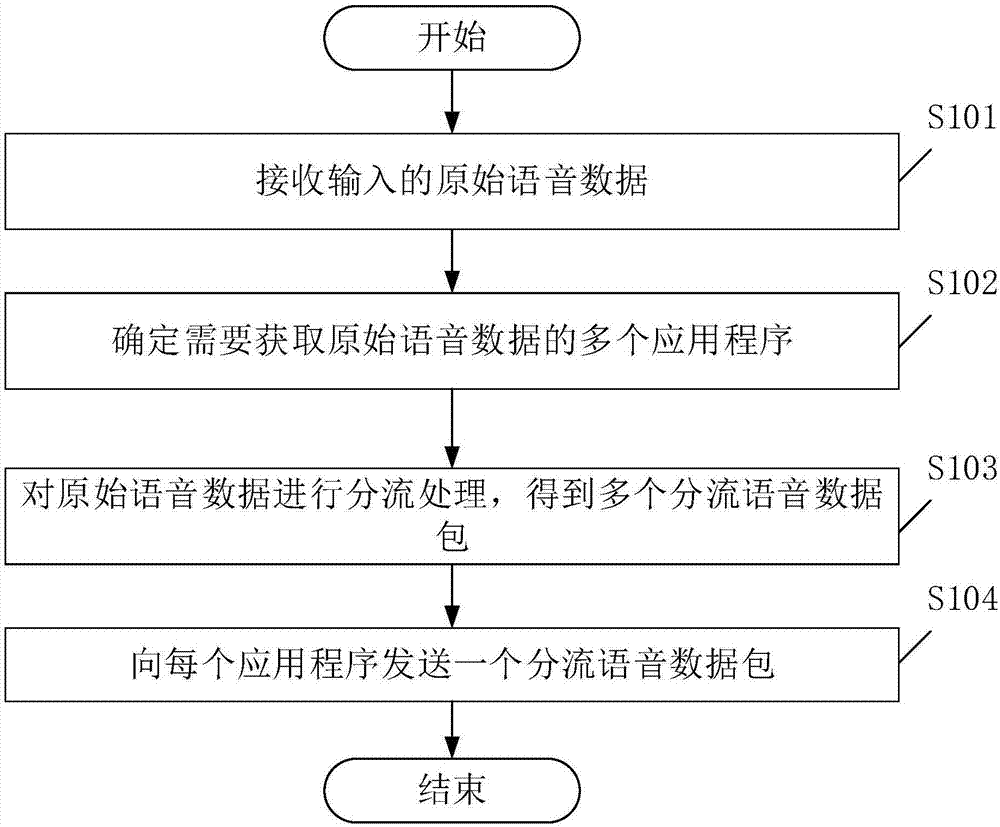
请参阅图1,图1是本发明实施例提供的一种语音数据处理方法的流程示意图。其中,如图1所示,该语音数据处理方法可以包括以下步骤:
s101、接收输入的原始语音数据。
本实施例中,可以通过拾音装置获取原始语音数据。其中拾音装置可以为单个麦克风、麦克风阵列等,对此本实施例不作限定。
作为一种可选的实施方式,当通过麦克风阵列获取原始语音数据时,可以包括以下步骤:
获取多个麦克风输入的语音数据;
将所有的麦克风输入的语音数据进行合并处理,得到一个原始语音数据。
本实施例中,在安卓系统中,所有麦克风输入的语音数据将先发送至fpga处理器,由fpga处理器对所有的麦克风输入的语音数据进行合并处理,最终得到一个原始语音数据。
在上述实施方式中,通过麦克风阵列获取原始语音数据,能够增强所录取的声音的立体感,提升语音数据的质量。
s102、确定需要获取原始语音数据的多个应用程序。
本实施例中,该应用程序可以为录音应用程序、语音识别应用程序、语音聊天程序等,对此本实施例不作限定。
在实际使用中,当开启录音应用程序进行录音的同时,开启语音识别应用程序进行同步语音识别时,则此时可以确定出需要获取原始语音数据的应用程序为录音应用程序和语音识别应用程序。
s103、对原始语音数据进行分流处理,得到多个分流语音数据包。
本实施例中,多个分流语音数据包的数量与多个应用程序的数量相同,每个分流语音数据包的语音内容都与原始语音数据的语音内容相同。
本实施例中,在安卓系统中,在系统底层的hal层可以实现对原始语音数据进行分流处理。
在实际使用中,当开启录音应用程序进行录音的同时,开启语音识别应用程序进行同步语音识别时,则对原始语音数据进行分流处理,可以得到两个语音内容与原始语音数据的语音内容相同的分流语音数据包。具体地,可以先在hal层创建一个缓冲器(buffer),然后将原始语音数据拷贝一份存储到缓冲器(buffer)中,进而可以得到两个语音内容与原始语音数据的语音内容相同的分流语音数据包。
s104、向每个应用程序发送一个分流语音数据包。
在图1所描述的语音数据处理方法中,先通过拾音装置接收输入的原始语音数据;确定需要获取原始语音数据的多个应用程序;对原始语音数据进行分流处理,得到多个分流语音数据包,其中,多个分流语音数据包的数量与多个应用程序的数量相同,每个分流语音数据包的语音内容都与原始语音数据的语音内容相同;向每个应用程序发送一个分流语音数据包。可见,实施图1所描述的语音数据处理方法,能够实现多个应用程序获取到麦克风输入的音频数据,进而使得多个应用程序能够同时对输入的音频数据进行处理。
实施例2
请参阅图2,图2是本发明实施例提供的一种语音数据处理方法的流程示意图。其中,如图2所示,该语音数据处理方法可以包括以下步骤:
s201、接收输入的原始语音数据。
s202、确定需要获取原始语音数据的多个应用程序。
s203、对原始语音数据进行语音增强处理,以去除原始语音数据中的干扰数据,得到去噪语音数据。
本实施例中,可以通过语音增强的方法对原始语音信号进行去噪处理,有利于消除环境噪声的干扰,进一步提升录音质量。
作为一种可选的实施方式,可以采用维纳滤波法对原始语音信号进行滤波处理,得到去噪语音信号。
s204、对处理语音数据进行端点检测处理,以去除处理语音数据中的静音数据段,得到预处理语音数据。
本实施例中,可以通过端点检测技术,检测出去噪语音信号中的静音信号段和非静音信号段,并去除去噪语音信号中的静音信号段,得到非静音信号段,即为纯语音信号。
本实施例中,端点检测是指在语音信号中将语音和非语音信号时段区分开来,准确地确定出语音信号的起始点。经过端点检测后,后续处理就可以只对语音信号进行,能够避免每个应用程序都对得到的语音数据进行预处理,减少应用程序对语音数据处理的处理量,进而有利于提升系统运算速度。
本实施例中,实施上述步骤s203~步骤s204,能够对原始语音数据进行预处理,得到预处理语音数据。
s205、根据预处理语音数据,生成多个镜像语音数据包,其中,多个镜像语音数据包与多个应用程序一一对应。
本实施例中,每个镜像语音数据包的语音内容与预处理语音数据的语音内容相同。
s206、根据预存的文件格式对照表,确定每个应用程序所支持的语音数据的文件格式。
本实施例中,文件格式对照表包括多个应用程序标识以及与每个应用程序标识对应的语音数据的文件格式,对此本实施例不作限定。
s207、将每个镜像语音数据包的文件格式转换为与该镜像语音数据包对应的应用程序所支持的文件格式,从而得到与每个应用程序对应的分流语音数据包。
本实施例中,实施上述步骤s203~步骤s204,能够对原始语音数据进行分流处理,得到与多个应用程序数量相同的分流语音数据包。
s208、根据预存的文件传输方式表,通过与每个应用程序对应的传输方式,将每个分流语音数据包发送至与该分流语音数据包对应的应用程序。
本实施例中,文件传输方式表包括多个应用程序标识以及与每个应用程序标识对应的文件传输方式。具体的,文件传输方式表可以包括录音应用程序的标识、语音识别应用程序的标识、录音应用程序的标识对应的传输方式(如通过framework进行传输)以及语音识别应用程序的标识对应的传输方式(如通过jni接口直接进行传输)等,对此本实施例不作限定。
可见,实施图2所描述的语音数据处理方法,能够实现多个应用程序获取到麦克风输入的音频数据,进而使得多个应用程序能够同时对输入的音频数据进行处理。
实施例3
请参阅图3,图3是本发明实施例提供的一种语音数据处理装置的结构示意图。其中,如图3所示,该语音数据处理装置包括:
接收模块310,用于接收输入的原始语音数据。
确定模块320,用于确定需要获取原始语音数据的多个应用程序。
本实施例中,接收模块310在接收输入的原始语音数据之后,还可以触发确定模块320确定需要获取原始语音数据的多个应用程序。
分流模块330,用于对原始语音数据进行分流处理,得到多个分流语音数据包,其中,多个分流语音数据包的数量与多个应用程序的数量相同,每个分流语音数据包的语音内容都与原始语音数据的语音内容相同。
发送模块340,用于向每个应用程序发送一个分流语音数据包。
作为一种可选的实施方式,分流模块330,包括:
预处理子模块331,用于对原始语音数据进行预处理,得到预处理语音数据。
生成子模块332,用于根据预处理语音数据,生成多个镜像语音数据包,其中,多个镜像语音数据包与多个应用程序一一对应。
确定子模块333,用于根据预存的文件格式对照表,确定每个应用程序所支持的语音数据的文件格式。
转换子模块334,用于将每个镜像语音数据包的文件格式转换为与该镜像语音数据包对应的应用程序所支持的文件格式,从而得到与每个应用程序对应的分流语音数据包。
作为进一步可选的实施方式,预处理子模块331,包括:
语音增强单元,用于在接收输入的原始语音数据之后,对原始语音数据进行语音增强处理,以去除原始语音数据中的干扰数据,得到处理语音数据。
端点检测单元,用于对处理语音数据进行端点检测处理,以去除处理语音数据中的静音数据段,得到纯语音数据。
可见,实施图3所描述的语音数据处理装置,能够实现多个应用程序获取到麦克风输入的音频数据,进而使得多个应用程序能够同时对输入的音频数据进行处理。
此外,本发明还提供了一种计算机设备。该计算机设备包括存储器和处理器,存储器可用于存储计算机程序,处理器通过运行计算机程序,从而使该计算机设备执行上述方法或者上述语音数据处理装置中的各个模块的功能。
存储器可包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据移动终端的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
本实施例还提供了一种计算机存储介质,用于储存上述计算机设备中使用的计算机程序。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置和方法,也可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,附图中的流程图和结构图显示了根据本发明的多个实施例的装置、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分,所述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在作为替换的实现方式中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,结构图和/或流程图中的每个方框、以及结构图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
另外,在本发明各个实施例中的各功能模块或单元可以集成在一起形成一个独立的部分,也可以是各个模块单独存在,也可以两个或更多个模块集成形成一个独立的部分。
所述功能如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是智能手机、个人计算机、服务器、或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!