口语理解装置和使用该装置的口语理解方法与流程
本发明一般地涉及口语理解装置,更具体地,涉及用于同时学习时隙标记(slottagging)和语言生成的口语理解装置以及使用该装置的口语理解方法。
背景技术:
随着最近对话系统服务的出现,例如
slu指的是分析语音识别的话语以根据语义结构提取时隙,在许多自然语言处理或对话系统中起重要作用。然而,一般的口语理解装置具有以下问题。
首先,当仅学习时隙标记时,未登录(oov)处理受到限制。
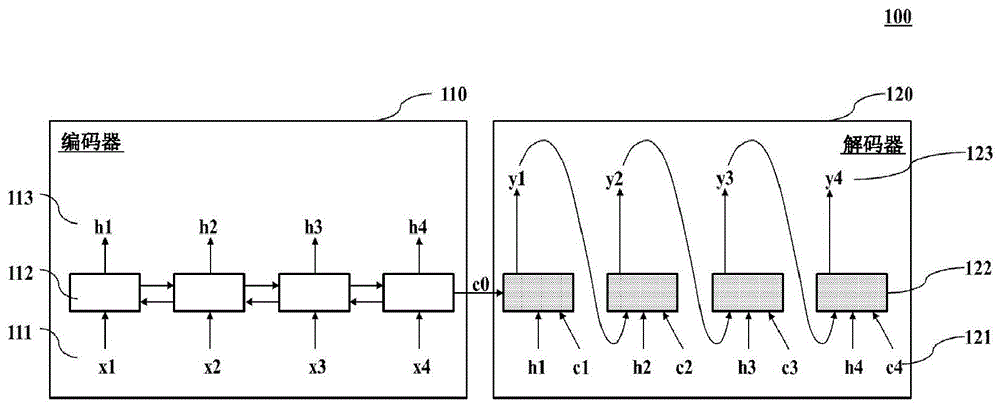
图1是示出仅学习时隙标记的常规模型100的图。
如图1所示,该模型仅使用序列到序列注意模型(attentionmodel)来学习时隙标签。序列到序列注意模型试图通过编码器110和解码器120生成将对应于输入数据的源序列转换成对应于输出数据的目标序列的概率模型。编码器110输入输入令牌111(x1到x4)构成到神经网络112的源序列以输出隐藏状态113(h1到h4),并且解码器120将隐藏状态113和注意121(c1到c4)输入到神经网络122以输出包括输出令牌123的目标序列(y1到y4),从而预测时隙标签。然而,仅学习了时隙标记的上述模型仅学习关于每个词(word)(例如,输入令牌)的时隙标签(例如,输出令牌),因此即使序列的模式相同,当输入oov时也不能执行准确的时隙标记。
第二,当同时学习时隙标记和语言模型时,由于语言模型引起的噪声,时隙标记的性能恶化。
图2是示出同时学习时隙标记和语言模型的常规模型200的图。
如图2所示,当同时学习语言模型210和时隙标记220时,不充分的学习数据可能妨碍学习,因为词汇量的大小wt大于时隙标签的大小st。另外,需要用户意图的操作(例如,时隙标记)通常具有不足以学习语言模型的数据规模,因此语言模型的操作可能恶化。
因此,需要这样一种具有鲁棒性的口语理解模型,其能够提高处理oov词的性能并增强时隙标签提取性能。
技术实现要素:
这里公开的实施例的目的是提供一种口语理解装置和口语理解方法,该方法使用该装置,对于输入语句根据去词汇化的时隙名称和/或语句的输出学习关于相同模式中的语句的语境,并改善oov词的时隙标记性能。
本领域技术人员将理解,可以通过本发明实现的目的不限于上文和上文具体描述的内容,并且本发明可以实现的其他目的将更多从以下详细描述中清楚地理解。
根据本发明实施例,口语理解装置可以包括:时隙标记模块,包括:语素分析单元,配置为分析关于所说语句的语素;时隙标记单元,配置为在根据所分析的语素生成的多个输入令牌中标记对应于语义实体的时隙;以及时隙名称转换单元,配置为基于相邻的语境信息将与所标记的时隙对应的短语转换为去词汇化(delexicalized)的时隙名称;和语言生成模块,配置为通过基于多个输入令牌组合去词汇化的时隙名称来生成组合序列。
另外,根据本发明实施例,口语理解方法可以包括:根据对所说语句的语素分析来对所说语句进行令牌化(tokenize);从根据所分析的语素生成的多个输入令牌中标记对应于语义实体的时隙;基于相邻的语境信息将对应于所标记的时隙的短语转换为去词汇化的时隙名称;并且通过基于所述多个输入令牌组合去词汇化的时隙名称来生成组合序列。
根据本发明实施例,对于输入语句通过同时学习时隙标记和语言生成并输出去词汇化的时隙名称和/或语句,可以学习关于相同模式中的语句的语境。此外,即使当输入包括oov词的令牌时,也可以提取与令牌相对应的时隙,因此可以改善时隙标记性能。
本领域技术人员将理解,可以通过本发明实现的效果不限于上文已经具体描述的效果,并且本发明的其他优点将从以下详细描述中更清楚地理解。
附图说明
通过结合下面简要描述的附图参考以下描述,可以更好地理解本文的实施例,其中相同的附图标记表示相同或功能相似的元件。
图1是示出仅学习时隙标记的模型的图。
图2是示出同时学习时隙标记和语言模型的模型的图。
图3是示意性地示出根据本发明实施例的口语理解装置的配置的图。
图4是示出借助于根据本发明实施例的口语理解装置的数据学习的图。
图5是示出根据本发明实施例的生成组合时隙标签的方法的示意性流程图。
图6和7是用于在输入未登录(oov)词时比较根据本发明实施例的口语理解装置与一般语言理解装置之间的时隙标记的表。
图8和9是根据根据本发明实施例的口语理解装置与一般语言理解装置之间的语言生成模型学习来比较时隙标记的表。
应当理解,上述附图不一定按比例绘制,而且呈现了说明本发明的基本原理的各种优选特征的略微简化的表示。本发明的具体设计特征,包括例如特定尺寸、方向、位置和形状,将部分地由特定的预期应用和使用环境确定。
具体实施方式
现在将详细参考实施例,其示例在附图中示出。虽然本发明可以进行各种修改和替换,但是其具体实施例在附图中以示例的方式示出。然而,本发明不应被解释为限于这里描述的实施例,而是相反,本发明将覆盖落入实施例的精神和范围内的所有修改形式、等同形式和替代形式。
虽然诸如“第一”、“第二”等术语可用于描述各种组件,但是这些组件不应受上述术语的限制。上述术语仅用于区分一个组件与另一个组件。另外,考虑到实施例的构造和操作而特别定义的术语仅用于描述实施例,而不是限定实施例的范围。
在对实施例的描述中,应当理解,当一个元件被称为在另一个元件“上”或“下”形成时,它可以直接在另一个元件“上”或“下”或者间接地在其间形成有介入元件。还应该理解,当元件被称为“在……上”或“在……下”时,“在元件下”以及“在元件上”可以包括基于该元件。
如本文所使用的,诸如“上”/“上部”/“上方”,“下”/“下部”/“下方”等的关系术语仅用于区分一个实体或元素与另一实体或元素,不一定要求或暗示这些实体或元素之间的任何物理或逻辑关系或顺序。
使用说明书中使用的术语描述了特定实施例,并且不旨在限制本发明。除非上下文另有明确说明,否则单数形式也旨在包括复数形式。应当理解,本文描述的术语“包括”或“具有”用于指定在说明书中公开的特征、数字、步骤、操作、组件、部件或其组合的存在,并且不排除添加一个或多个其他特征、数字、步骤、操作、组件、部件或其组合的存在或可能性。
除非另有说明,否则包括技术和科学术语的所有术语具有与本发明所属领域的普通技术人员通常理解的含义相同的含义。通常使用的术语,例如在词典中定义的术语,应该被解释为与来自语境的相关技术的含义一致。除非在本发明中不同地定义,否则这些术语不应以理想或过度正式的方式解释。
另外,应理解,以下方法或其方面中的一个或多个可由至少一个控制单元执行。术语“控制单元”可以指代包括存储器和处理器的硬件装置。存储器配置为存储程序指令,并且处理器被专门编程为执行程序指令以执行下面进一步描述的一个或多个过程。如本文所述,控制单元可以控制单元、模块、部件、装置等的操作。此外,应当理解,如本领域普通技术人员将理解的,以下方法可以由包括控制单元的装置结合一个或多个其他组件来执行。
此外,本发明的控制单元可以体现为包含由处理器执行的可执行程序指令的非暂时性计算机可读介质。计算机可读介质的示例包括但不限于rom、ram、光盘(cd)-rom、磁带、软盘、闪存驱动器、智能卡和光学数据存储装置。计算机可读记录介质还可以分布在整个计算机网络中,使得程序指令以分布式方式存储和执行,例如通过远程信息处理服务器或控制器区域网络(can)。
在下文中,将参考附图描述根据本发明实施例的口语理解装置。
图3是示意性地示出根据本发明实施例的口语理解装置的配置的图。
如图3所示,根据实施例的口语理解装置300可以包括所说语句输入单元310、时隙标记模块320和语言生成模块330。
所说语句输入单元310可以接收用户发出的语音的识别结果。这里,语音识别结果可以是通过将用户发出的语音转换为文本形式而获得的输入语句。
时隙标记模块320可以标记与通过分析关于从所说语句输入单元301输入的语句的语素提取的语义实体相对应的时隙,并基于相邻的语境信息将对应于所标记的时隙的短语转换为去词汇化的时隙名称。这里,时隙标记指的是提取与输入语句中的用户意图相关的概念对应的词的技术。
在下文中,将根据输入到根据本发明实施例的时隙标记模块320的语音识别结果的示例来详细描述时隙标记模块320和语言生成模块330的子组件。
时隙标记模块320可以包括语素分析单元321、时隙标记单元322、时隙标签分配单元323、时隙名称转换单元324和时隙标签组合输出单元325。
输入语句1:callhonggil-dong,please(请给honggil-dong打电话)
当根据语音识别结果的文本形式的语句从所说语句输入单元310输入到时隙标记模块320时,语素分析单元321可以对输入语句进行令牌化。例如,当语音识别结果是“callhonggil-dong,please”时,语素分析单元321可以将输入的语句令牌化为“call”,“honggil-dong”和“please”。
时隙标记单元322可以从构成输入语句的令牌中提取与用户意图相关的概念(即,语义实体)对应的词(或短语)。换句话说,时隙标记单元322可以标记对应于语义实体的时隙,以便识别关于语义实体的功能角色。可以标记一个或多个时隙。例如,由于在输入语句1中用户具有“打电话(makingacall)”的意图,因此可以提取作为与“被叫方(calledparty)”的意图相关的概念的“honggil-dong”作为语义实体。
此外,时隙标记单元322还可以包括语义实体识别单元(未示出),其确定构成输入语句的每个令牌是否是语义实体,以便确定将在后面描述的标记时隙的去词汇化。
语义实体识别单元(未示出)可以根据二进制实体分类来确定令牌是否是语义实体,并且将确定结果提供给后面将描述的时隙标记单元322和时隙名称转换单元324。这里,可以在时隙提取之前执行令牌是否是语义实体的确定。
当令牌是语义实体时,二进制实体分类可以将构成输入语句的每个令牌分类为第一值,并且当令牌不是语义实体时,二进制实体分类可以将其分类为第二值,关于语义实体的确定结果可以由包括第一值和/或第二值的二进制数表示。这里,第一值可以是1(或0),第二值可以是0(或1)。同时,描述为确定令牌是否是语义实体的方法的二进制实体分类是示例性的,并且对于本领域技术人员显而易见的是,本发明不限于此。
时隙标记单元322可以将与由语义实体识别单元(未示出)提供的第一值相对应的令牌标记为时隙。例如,语义实体识别单元(未示出)可以根据上述输入语句1生成“1,0,0,0,0”的二进制序列,并将该二进制序列提供给时隙标记单元322,时隙标记单元322可以将作为对应于“1”的令牌的“honggil-dong”标记为时隙。
时隙标签分配单元323可以通过顺序标记方法将时隙标签分配给构成输入语句的每个令牌。具体地,当时隙是令牌时,相应的时隙名称被分配为时隙标签。当时隙不是令牌时,向其分配标签0(外侧)。可以按输入令牌的次序顺序地分配时隙标签。例如,可以通过时隙标签分配单元323为构成上述输入语句1的每个令牌分配时隙标签“honggil-dong,0,0,0,0”。
时隙名称转换单元324可以基于相邻的语境信息将对应于标记时隙的短语转换为去词汇化的时隙名称。位于时隙之前和之后的至少一个令牌可以用作相邻的语境信息。例如,可以基于相邻的语境信息将上述输入语句1中的“honggil-dong”转换为“被叫方”的去词汇化的时隙名称。
此外,可以从语义实体识别单元(未示出)向时隙名称转换单元324提供关于语义实体的确定结果(其表示为包括第一值和/或第二值的二进制数),以确定时隙是否是去词汇化的。例如,当在语义实体单元(未示出)中生成的二进制序列“1,0,0,0,0”被提供给时隙名称转换器324时,时隙名称转换器324可以确定“honggil-dong”(其是对应于“1”的令牌)转换为去词汇化的时隙名称。
时隙标签组合输出单元325可以组合由时隙标签分配单元323分配的时隙标签和通过时隙名称转换器324去词汇化的时隙名称标签,并将该组合提供给时隙标记模型学习单元340。例如,可以针对上述输入语句1最终输出“被叫方,0,0,0,0”的时隙标签。
语言生成模块330可以将输入语句与转换的时隙名称组合以生成组合序列。语言生成需要为输入语句生成预定的输出语句,并且可以主要用于自动编码或相邻语句生成。这里,自动编码是指生成与输入语句相同的语句,并且相邻语句生成是指在对话系统中生成先前话语的后续话语。
语言生成模块330可以包括语句组合单元341和序列组合输出单元342。
语句组合单元341可以基于由语素分析单元321令牌化的输入语句的令牌来组合由时隙标记单元322标记的时隙的去词汇化时隙名称,以生成语言。例如,语句组合单元341可以针对“call”,“honggil-dong”和“please”的输入语句生成“call”,“被叫方”和“please”的组合序列。
序列组合输出单元342可以输出从语句组合单元341生成的组合序列,并将生成的组合序列提供给语言生成模型学习单元350。
此外,根据本发明实施例的口语理解装置300还可以包括时隙标记模型学习单元340(其学习由时隙标记模块320提供的组合时隙标签)、语言生成模型学习单元350(其学习由语言生成模块330提供的组合序列)以及存储组合时隙标签和组合序列的数据库360。
这里,时隙标记模型学习单元340可以从语义实体识别单元(未示出)学习关于由包括第一值和/或第二值的二进制数表示的语义实体的确定结果。
此外,数据库360可以存储来自时隙标记模型学习单元340和语言生成模型学习单元350的学习数据,例如组合时隙标签、关于语义实体的确定结果和组合序列,可以提供学习数据至时隙标记模块320使得对相同模式的输入语句执行重复学习,并且可以存储(或累积)作为重复学习的结果而获得的数据。
根据本发明实施例的口语理解装置300可以同时学习时隙标记和语言生成。特别地,口语理解装置300可以通过对于输入语句输出去词汇化的时隙名称和/或语句学习关于相同模式中的语句的语境,并且即使输入包括未登录(oov)词的令牌也可以提取与令牌相对应的时隙,从而改善时隙标记性能。
在下文中,将参照图3和图4描述根据本发明实施例的口语理解装置的数据学习方法。
图4是示出根据本发明实施例的口语理解装置的数据学习的图。
如图4所示,模型使用序列到序列注意模型来学习数据,例如组合时隙标签、关于语义实体的确定结果以及组合序列。
编码器410可以对输入语句进行编码,并且解码器420可以执行时隙标记、组合序列生成和语义实体确定。编码器410和解码器420可以根据操作在功能上分类。
在下文中,将基于输入语句2详细描述根据本发明实施例的在编码器410和解码器420中学习上述数据的方法。
输入语句2:fromlatoseattle(从洛杉矶到西雅图)
编码器410可以将通过语素分析单元321令牌化输入语句而获得的多个输入令牌411(x1至x4)输入至神经网络412,从而输出多个隐藏状态413(h1至h4)。
解码器420可以将隐藏状态413和注意421(c1至c4)输入到神经网络422以输出多个输出令牌y1至y4,从而预测时隙标签。这里,关于当前输出令牌yi,可以考虑先前输出令牌yi-1、当前隐藏状态hi和当前注意ci,并且i表示时间步长。
如上所述,解码器420可以执行语义实体确定423、时隙标记424和组合序列生成425,并且学习相应的操作。
一起参考图3和图4,语义实体识别单元(未示出)可以根据二进制实体分类执行(或输出)语义实体的确定并且学习确定结果。例如,由于用户意图在上述输入语句2中提取关于“出发地”和“目的地”的信息,语义实体识别单元(未示出)可以将“la”和“seattle”的输入令牌确定为语义实体,将“1”分配给“la”和“seattle”,并将“0”分配给“from”和“to”,以根据输入令牌的次序输出“0,1,0,1”的确定结果。
此外,语义实体识别单元(未示出)可以将语义实体确定结果423提供给时隙标记单元322和时隙名称转换单元324,时隙标记模块320可以输出组合时隙标签424以执行时隙标记操作,并且语言生成模块330可以输出组合序列425以执行语言生成操作。
虽然已经描述了生成组合时隙标签424和组合序列425的方法,但是为了便于描述,下面将基于输入语句2简要地描述该方法。
例如,“la”和“seattle”可以基于输入语句2的相邻语境信息分别被转换为“from_loc(位置)”和“to_loc(位置)”的去词汇化时隙名称,标签“0(外侧)”可以被分配给“from”和“to”,并且时隙标签组合输出单元325可以生成“0,from_loc,0,to-loc”的组合时隙标签425。
另外,语言生成模块可以基于令牌化输入语句的令牌来组合标记时隙的去词汇化时隙名称,以生成“from,from_loc,to,to_loc”的组合序列424。
如上所述,根据本发明实施例的口语理解装置可以生成包括组合时隙标签、关于语义实体的确定结果和组合序列的数据,并且学习数据的分布。
组合时隙标签分布可以定义为由下面的等式1表示。
[等式1]
p(yi|y<i;x)=slotlabeldist(si)
这里,i表示时间步长,yi表示第i个输出令牌,x表示输入令牌,并且该等式表示先前所有输出令牌和输入令牌被转换为当前输出令牌的概率分布。
组合序列分布可以定义为由下面的等式2表示。
[等式2]
这里,i表示时间步长,yiword表示第i个输出词,x表示输入词。
语义实体分布可以被定义为由下面的等式3表示。
[等式3]
p(zi|y<i;x)=slotlabeldist(si)
这里,z表示第一值或第二值,i表示时间步长,zi表示第i个z值,x表示输入令牌。第一值可以是1(或0),第二值可以是0(或1)。
此外,可以通过考虑以下来确定包括组合时隙标签、关于语义实体的确定结果和组合序列的数据的分布概率:通过将时隙标记权重应用于输出令牌是第一值还是第二值的概率而获得的值以及通过将语言生成学习权重应用于输出词是第一值还是第二值的概率而获得的值,并且上述数据的分布概率可以定义为由下面的等式4表示。
[等式4]
这里,αs和αw分别表示根据zi的时隙标记和语言生成的学习权重。
等式4表示包括组合时隙标签、关于语义实体的确定结果和组合序列的数据的学习分布概率。由于学习数据可以包括去词汇化的时隙名称,因此根据本发明实施例的口语理解装置可以改善时隙标签提取性能和oov处理性能。
在下文中,将参考图5描述生成重组时隙标签的方法。
图5是示出根据本发明实施例的生成组合时隙标签的方法的示意性流程图。
生成组合时隙标签的方法可以包括所说语句令牌化步骤s510、语义实体确定步骤s520、时隙标签标记步骤s530、时隙名称转换步骤s550和组合时隙标签生成步骤s560。
在所说语句令牌化步骤s510中,可以分析并令牌化通过将用户发出的语音转换成文本而获得的输入语句的语素以生成多个令牌。
在语义实体确定步骤s520中,确定多个令牌是否是与用户意图相关的概念(即,语义实体)对应的词(或短语)。这里,可以根据二进制实体分类来执行语义实体确定。当令牌是语义实体时,二进制实体分类可以将构成输入语句的每个令牌分类为第一值,并且当令牌不是语义实体时,将令牌分类为第二值。语义实体确定结果可以表示为包括第一值和/或第二值的二进制。这里,第一值可以是1(或0),第二值可以是0(或1)。被描述为语义实体确定方法的二进制实体分类是示例性的,并且对于本领域技术人员来说显而易见的是,本发明不限于此。
如果特定令牌是作为语义实体确定结果的语义实体,则可以执行时隙标签标记步骤s530,并且如果特定令牌不是语义实体,则可以执行0(外侧)标签分配步骤s540。
在时隙标签标记步骤s530中,可以将与根据二进制实体分类输出的第一值相对应的令牌标记为时隙。换句话说,可以标记对应于语义实体的时隙以便识别语义实体的功能角色,并且可以标记至少一个时隙。
在时隙名称转换步骤s550中,可以基于相邻语境信息将与在时隙标签标记步骤s530中标记的时隙相对应的短语转换为去词汇化时隙名称。这里,位于时隙之前和之后的至少一个令牌可以用作相邻语境信息。
在0(外侧)标签分配步骤s540中,可以根据二进制实体分类将标签0(外侧)分配给与第二值输出对应的令牌。
在组合时隙标签生成步骤s560中,可以组合在时隙名称转换步骤s550中生成的去词汇化时隙名称标签和在0(外侧)标签分配步骤s540中分配的时隙标签,以生成组合时隙标签。
如上所述,通过对于输入语句生成去词汇化的时隙名称,可以学习关于相同模式中的语句的语境。此外,即使当输入包括oov的令牌时,也可以提取与令牌对应的时隙,因此可以提高时隙标记性能。
在下文中,将通过参考图6和7的比较来描述当输入oov词时根据本发明实施例的口语理解装置和一般语言理解装置中的时隙标记。
图6和7是用于在输入oov词时比较根据本发明实施例的口语理解装置与一般语言理解装置之间的时隙标记的表。
在图6和7中,“黄金(gold)”指的是正确的答案,“我们(ours)”指的是根据本发明实施例的口语理解装置,“基线(baseline)”指的是图1所示的仅学习时隙标记的模型。将基于以下输入语句3给出描述。
输入语句3:whatistheseatingcapacityoftheaircraft(飞机的载客人数是多少)。
在输入语句3中,由于用户意图提取关于“特定飞机(specificaircraft)”的载客人数的信息,因此可以提取与意图“特定飞机”相关的概念作为语义实体。
参考图6和7,当在输入语句3的末尾给出诸如“oos”和/或“moo”的oov词作为输入令牌时,仅学习一般时隙标记的模型(基线)可能将oov词标记为“往返(roundtrip)”(参见图6)或将oov词标记为“0(外侧)”标签(参见图7)。如上所述,如果输入语句中加入拼写错误或oov词,即使输入相同模式的语句,仅学习时隙标记的模型可能不理解用户的意图(参考图6),或者可能不执行时隙标记(参见图7)。
另一方面,根据本发明实施例的口语理解装置(“我们”)基于相邻语境信息(例如,飞机(aircraft))将oov词转换为去词汇化的时隙名称“aircraft_code”,并且生成组合时隙标签和组合序列以学习语句模式,因此即使在输入语句3的末尾给出诸如“oos”和/或“moo”的oov词作为输入令牌,也可以执行时隙标记。换句话说,根据本发明实施例的口语理解装置可以通过组合时隙标签和组合序列来学习相同模式的语句,该组合时隙标签是通过基于相邻语境信息将对应于时隙的词(或短语)转换为去词汇化的时隙名称而获得的,因此可以正确地理解用户的意图。
在下文中,将通过参考图8和9的比较来描述当在根据本发明实施例的口语理解装置和一般语言理解装置中学习语言生成模型时的效果。
图8和9是用于根据根据本发明实施例的口语理解装置与一般语言理解装置之间的语言生成模型学习来比较时隙标记的表。
在图8和9中,“黄金”指的是正确的(即,对的)答案,“我们”指的是根据本发明实施例的口语理解装置,并且“基线”指的是图1所示的仅学习时隙标记的模型。图8基于下面的输入语句4,而图9基于下面的输入语句5。
输入语句4:ineedflightsdepartingfromoaklandandarrivinginsaltlakecity(我需要从奥克兰出发并到达盐湖城的航班)。
输入语句5:findmeaflightfromcincinnatitoanyairportinthenewyorkcityarea(请帮我查找从辛辛那提到纽约市区域内任何机场的航班)。
在输入语句4和5中,用户具有提取关于“目的地(destination)”的飞机信息的意图,因此可以提取与意图“目的地”相关的概念作为语义实体。
参考图8和9,根据本发明实施例的口语理解装置(我们)可以对于在“fromoakland(从奥克兰)”和/或“fromcincinnati(从辛辛那提)”之后输入的令牌学习去词汇化时隙名称“to_loc.city”。因此,可以执行符合语境的时隙标记。换句话说,根据本发明实施例的口语理解装置(我们)可以通过基于令牌化输入语句的令牌组合去词汇化的时隙名称来生成组合序列,因此可以学习语句模式以执行适应语境的时隙标记。
另一方面,仅学习时隙标记的一般模型(基线)不学习语言生成模型,因此对于在“fromoakland”和/或“fromcincinnati”之后输入的令牌可能进行时隙标记“stop_loc.city”和/或“city”而不是“to_loc.city”。这种时隙标记可能导致不适当的后续话语,因为用户的意图没有反映在其中或没有被其理解。
如上所述,根据本发明的实施例,可以执行适合于语境的时隙标记,因为学习了语言生成模型,因此可以防止引起不适当的后续话语。
尽管上面已经描述了一些实施例,但是各种其他实施例也是可能的。如果不是不兼容技术,则上述实施例可以以各种方式组合以实现新的实施例。
根据上述实施例的口语理解装置和使用该装置的口语理解方法可以用在诸如智能秘书和对话导航系统的对话系统服务中。
本领域技术人员将理解,在不脱离本发明的精神和基本特征的情况下,本发明可以以除了本文所述之外的其他具体方式来实施。因此,上述实施例在所有方面都应被解释为说明性的而非限制性的。本发明的范围应由所附权利要求及其合法等同形式确定,而不是由以上描述确定,并且落入所附权利要求的含义和等同范围内的所有改变都旨在包含在其中。
- 还没有人留言评论。精彩留言会获得点赞!