用于对话会话管理的系统和方法与流程
本发明涉及话音用户接口和交谈代理,并且特别涉及对交谈交互会话中的对话的控制的让渡。
背景技术:
在过去的五十年左右,已经发生的信息技术革命意味着许多人类活动现在涉及并且经常围绕对信息技术系统(并且特别是计算机)的操纵。支持这些交互的接口的性质已经与这些系统的处理和电信能力并行地从打孔卡、键盘、鼠标驱动的图形用户接口以及最新的多触点触屏接口持续演进,显示给用户的信息的丰富性和可访问性已经增加,并且交互的精确性和便利性有所改进。然而,基于与所讨论的设备的手动交互,已经系统地保留了这种操作。
近年来,语音处理已经大有进步,其中诸如pepper之类的交互式机器人和诸如amazonalexa、okgoogle、siri和cortana之类的话音接口正在进入市场。然而,机器人仍然需要改进以像人类一样自然地进行交谈。例如,一个问题是用户必须以非常特定的方式讲话来通过语音与机器人进行交互。用户必须在没有犹豫或暂停的情况下,优选地在没有任何“嗯”或“啊”的情况下清晰地讲话。不幸的是,研究指示人类平均每4.4秒就会发出这种类型的不流畅,例如,暂停以容许他们思考的时间。在这些情况下,语音系统可能假设人类已经完成讲话,并突然中断或处理不完整的想法。存在用于尝试解决该中断问题的各种策略。当今的话音服务中的许多都依赖自动语音识别和自然语言理解来检测用户的命令是否完整,因此部分地解决了中断问题。然而,在这种情况下,如果用户的输入由多个句子组成,则将仅处理第一个句子;增量对话策略可以在这里有所帮助。其他系统仅允许使用按钮来结束讲话轮次。在主动对话系统中,避免该问题的另一方式是问特定的、非开放式问题,例如,“您更喜欢哪种颜色,红色还是蓝色?”通常,人类使自己适应了系统,从而一口气讲出“完美”的串在一起的序列,使他们的通信方式符合机器的约束。
自20世纪60年代末以来,一直在研究轮次转换(turn-taking)作为人类交谈分析的一部分。轮次转换包括诸如交谈发言权(conversationalfloor)之类的概念,当讲话者继续讲话或结束其讲话轮次时,可以分别“保持”或“放弃”交谈发言权。另一重要的概念是“重叠(ovelap)”,即一个讲话者的语音与当前正在讲话的人的语音重叠。取决于文化或区域,通常在交谈时可能会或多或少地发生重叠。一些重叠是协作性的,例如作为对话者的语音的延续或诸如“嗯啊”之类的反馈语。在另一方面,一些重叠是竞争性的,在本文中我们称其为中断。抓住讲话轮次并改变主题可以与显示权力、统治和威胁相关联。因此,对于机器人和ai而言,避免这些重叠可能是重要的,以免它们被感知为主导的人类讲话者。诸如“啊”或“嗯”之类的补白暂停(filledpause)或补白(filler)在自然交谈中是经常发生的,并且指示思考和/或期望继续讲话。语言社区中的普遍共识是,这些不是错误,而是语言和交谈的正常部分。相关地,在单词或短语之间也存在无声的暂停,从而将讲话轮次内的语音的部分分开。
在自动化系统中高效地标识对话者放弃交谈发言权的时刻对于改进人类对话者与自动化系统之间的通信的流畅度和效率是重要的,以减少中断、重复等的发生。
技术实现要素:
根据本发明,在第一方面,提供了一种检测在与机器接口的对话中人类对话者对讲话轮次的让渡的方法,该方法包括在来自人类对话者的话语期间捕获基于人类对话者的第一语音特性的第一意图指示符,以及检测来自人类对话者的话语的终止。当来自人类对话者的话语的终止被确定时,捕获基于对话者的身体移动的第二意图指示符。然后确定第一意图指示符和第二意图指示符是否一起被认为与人类对话者放弃对对话的控制一致,并且当确定第一意图指示符和第二意图指示符一起被认为与人类对话者放弃对对话的控制一致时,响应人类对话者。
在第一方面的发展中,方法包括这样的附加步骤:当来自人类对话者的话语的终止被确定时,捕获基于对话者的第二语音特性的第三意图指示符。确定第一意图指示符和第二意图指示符是否一起被认为与人类对话者放弃对对话的控制一致的步骤包括:确定第一意图指示符和第二意图指示符和第三意图指示符是否一起被认为与人类对话者放弃对对话的控制一致。
在第一方面的进一步的发展中,第二意图指示符包括以下各项中的一个或多个:对人类对话者的注视的定向的确定,对人类对话者相对于对话的焦点的物理接近程度的检测,对人类对话者的身体相对于对话的焦点的定向的检测,对人类对话者的指定身体部分相对于对话的焦点的定向的检测。
在第一方面的进一步的发展中,对人类对话者的注视的定向的确定包括:对人类对话者的注视已经返回到对话的焦点的确定。
在第一方面的进一步的发展中,第一意图指示符或第三意图指示符包括以下各项中的一个或多个:对来自人类对话者的补白声音的分析,对来自人类对话者的声音的音调的检测或话语的语义组成部分。
在第一方面的进一步的发展中,第一意图指示符主要基于接近话语的终止的语音特性。
在第一方面的进一步的发展中,仅在话语中的暂停的持续时间被检测到已经超过预定的阈值持续时间的情况下,话语才被确定为终止。
在第一方面的进一步的发展中,捕获人类对话者的第二意图指示符的步骤在预定的持续时间内被执行。
在第一方面的进一步的发展中,在确定第一意图指示符和第二意图指示符是否与人类对话者放弃对对话的控制一致的步骤时,确定第一意图指示符和第二意图指示符并不一起与人类对话者放弃对对话的控制一致,方法返回到检测来自人类对话者的话语的终止的步骤。
根据本发明,在第二方面,提供了一种用于处理在与人类对话者的对话中用于注入的材料的系统,该系统包括:输入,其接收承载来自人类对话者的话语的通信信道的表示;输出,其用于传达承载材料的通信信道的表示;以及处理器,其适于处理表示以检测话语的终止。该处理器还适于在来自人类对话者的话语的终止被确定的情况下,捕获基于人类对话者的第一语音特性的第一意图指示符以及基于人类对话者的身体移动的第二意图指示符,并且确定一个或多个意图指示符是否与人类对话者放弃对对话的控制一致,并且在确定一个或多个意图指示符与人类对话者放弃对对话的控制一致的情况下,发起对人类对话者的响应。
在第二方面的进一步的发展中,系统包括:由人类对话者可感知的焦点;以及检测器,其能够将人类对话者相对于焦点的身体移动的方面确定为第二意图指示符。
在第二方面的进一步的发展中,第二意图指示符包括以下各项中的一个或多个:对人类对话者的注视的定向的确定,对人类对话者相对于对话的焦点的物理接近程度的检测,对人类对话者的身体相对于对话的焦点的定向的检测,对人类对话者的指定身体部分相对于对话的焦点的定向的检测,并且系统还包括视频输入换能器和适于确定人类对话者的注视的定向的注视跟踪器。
在第二方面的进一步的发展中,第一意图指示符或第三意图指示符包括以下各项中的一个或多个:对来自人类对话者的补白声音的分析,对来自人类对话者的声音的音调的检测或话语的语义组成部分。
根据本发明,在第三方面,提供了一种计算机程序,该计算机程序包括适于实现第一方面的步骤的指令。
附图说明
现在将参考附图描述本发明的上述和其他优点,其中:
图1a呈现了其中处理在与人类对话者的对话中用于注入的材料的场景;
图1b呈现了图1a的场景的第一替代方案;
图1c呈现了图1a的场景的第二替代方案;
图1d呈现了图1a的场景的第三替代方案;
图2示出了可以在对话的不同阶段进行测量的对应的注视方向数据;
图3示出了根据实施例的检测在与机器接口的对话中人类对话者对讲话轮次的让渡的方法;
图4示出了根据图3的实施例的发展的检测在与机器接口的对话中人类对话者对讲话轮次的让渡的方法;
图5呈现了根据实施例的用于检测在与机器的对话中人类对话者对讲话轮次的让渡的系统;
图6示出了适合于本发明的实施例的实现方式的通用计算系统;
图7示出了适于构成实施例的机器人;以及
图8示出了适于构成实施例的智能电话设备。
具体实施方式
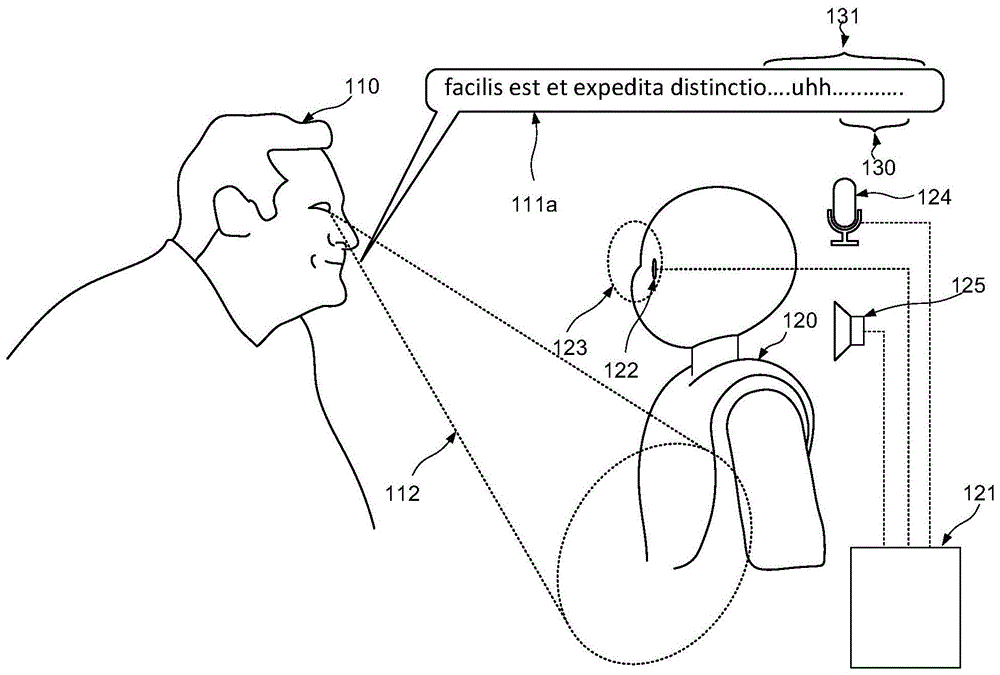
图1a、图1b和图1c呈现了其中处理在与人类对话者的对话中用于注入的材料的场景的多个阶段。特别地,机器人120参与与人类对话者110的对话。机器人的处理器试图标识适当的时刻以准备为对话做出贡献,并将其注入交谈中。
图1a呈现了其中处理在与人类对话者的对话中用于注入的材料的场景。如在文本气泡111a中示出的,人类对话者已经说出话语“facilisestetexpeditadistinctio……uhh”。机器人122设置有麦克风124,借助于该麦克风124可以例如通过模数转换、滤波和可以是适当的其他预处理以可处理的形式捕获并渲染话语。根据本发明的实施例,可以连续地处理该话语以标识每句话语的结束。话语的结束可以被认为与连续语音分段的结束一致。仅在话语中的暂停的持续时间被检测到已经超过预定的阈值持续时间的情况下,话语才被确定为终止。阈值持续时间可以具有任何合适的值。例如,阈值持续时间可以位于50ms至400ms之间。已经发现200ms左右的最小暂停持续时间为讲英语的人提供良好的结果。可以根据对话者的语音特性来动态地确定阈值持续时间。可以参考诸如所使用的语言、由于口音等引起的区域差异、讲话者的成熟度和能力等之类的背景因素来设置阈值持续时间。
也可以定义能量强度阈值,其中低于该阈值的声音输入级别被认为属于暂停时段。可以根据对话者话音级别、对话者与焦点和/或麦克风之间预测或检测到的距离、背景噪声级别和适当的其他因素来动态地定义能量强度级别。
如图1a中示出的,话语以无声时段130作为结束,这使处理器121能够标识话语的终止。
在音频处理领域,已经对检测补白暂停进行了许多研究。如masatakagoto、katunobuitou和satoruhayamizu于1999年的文章“areal-timefilledpausedetectionsystemforspontaneousspeechrecognition”(proceedingsofeurospeech,1999年,第227-230页)中所解释的,可以通过跟踪日语中的语音的基本频率和频谱包络来实时检测补白暂停。最近,interspeech2013svc数据集可以用于检测语音信号,例如,teunfkrikke和khietptruong于2013年在题为“detectionofnonverbalvocalizationsusinggaussianmixturemodels:lookingforfillersandlaughterinconversationalspeech(2013)”的文章中呈现的笑声和补白暂停。
因此,在可以确定话语111a已经终止时,还可以确定以补白语音的形式的第一意图指示符在接近话语的结束时出现。
因此,第一意图指示符可以包括以下各项中的一个或多个:对来自人类对话者的补白声音的分析,对来自人类对话者的声音的音调的检测或话语的语义组成部分。特别地,在话语的结束处的下降音调可以被认为是用户放弃交谈发言权的意图的指示符,而平坦的音调则是讲话者希望保持发言权的信号。呈现句法或概念上完整的话语被认为是用户放弃交谈发言权的意图的指示符。在讲话轮次的结束时可能更慢地说出给定的单词或音节。可以并行使用许多这样的意图指示符。第一意图指示符可以包括这些因素中的一些或全部的任何组合。
可以采用补白的存在来构成第一意图指示符,该第一意图指示符基于对话者的第一语音特性。特别地,补白在话语的结束处的存在可以被认为是人类对话者不旨在放弃交谈发言权的指示符。将认识到的是,可以考虑基于对话者的语音特性的许多其他这种第一意图指示符。例如,对来自人类对话者的补白声音的分析,对来自人类对话者的声音的音调的检测或话语的语义组成部分。
在某些实施例中,可以评估在话语的结束处(但在话语期间)的预定的持续时间的时间窗口131以用于对这种第一意图指示符的检测。
可以注意到,如图1a中示出的,对话者110的注视112指向下方并朝向右方,远离对应于机器人的面部的焦点区域123。这个事实可以由注视跟踪系统检测到,该注视跟踪系统如所示地与机器人的视频系统集成,其基于机器人的“眼睛”的位置上的摄像机。
在人类之间的交谈中,注视已经被标识为指示讲话轮次的结束的一种方式。如seanandrist、xiangzhitan、michaelgleicher和bilgemutlu于2014年在题为“conversationalgazeaversionforhumanlikerobots”(proceedingsofthe2014acm/ieeeinternationalconferenceonhuman-robotinteraction,acm,第25-32页)的文章中,以及simonho、tomfoulsham和alankingstone于2015年在题为“speakingandlisteningwiththeeyes:gazesignalingduringdyadicinteractions”(plosone10,8(2015),
e0136905)的文章中所讨论的,人类在思考时将典型地向上看、向侧边看或向下看,并且然后在他们结束讲话时将其注视返回到他们的对话者。可以在federicorossano于2012年的“gazeinconversation”(handbookofconversationanalysis,jacksidnell和tanyastivers(eds.),johnwileyandsons,ltd,chichester,uk,第15章,第308-329页)中发现对交谈中的注视的透彻研究。
人们倾向于在话语的开始处中断眼神交流以获得他们的轮次,并且在与其他人类谈话时集中于制定回答。在他们的响应的结束处,讲话者通常看向听众以发信号表示他们已经结束了他们的回答,并且邀请听众接过交谈发言权。
图2示出了可以在对话的不同阶段进行测量的对应的注视方向数据。
响应开始于思考阶段201,其伴随着注视方向偏离角和音调值的增加。中间阶段202是人类的口头答复,其具有偶尔的音调值改变。最后,参与者看回203机器人,因此放弃交谈发言权而有利于机器人。这可以用作轮次转换策略的基础——注视检测器可以仅在最相关的时间期间(例如,在话语的结束之后)跟踪注视信息。已经发现在话语的结束之后的1.5秒的时段通常构成用于针对话音用户接口或交谈代理的这种确定的高效窗口。如根据图2将认识到的,在该时段期间,对话者的注视方向可以显著变化。因此,第二意图指示符可以基于测量时段内的平均值或平滑值。在语音话语的结束后的注视方向可以因此被认为用于区分对话者是试图保持还是放弃交谈发言权。简而言之,该系统可以计算人类是否正在看向机器人。参考估计出的注视方向,可以将正负0.15弧度的角度用作阈值,在该阈值之内对话者可以被认为正在看向机器人,并且在该阈值之外对话者可以被称为正在转移其注视。可以基于特定对话者的行为来动态地确定注视方向阈值。还可以考虑在对话者与焦点之间的检测到或测量到的距离和/或焦点的大小。
因此,注视方向可以被认为构成第二意图指示符,该第二意图指示符基于对话者的身体移动。特别地,可以将对人类对话者的注视尚未返回到与机器人的注视“相遇”的确定认为是人类对话者不旨在放弃交谈发言权的指示符。将认识到的是,与机器人的注视“相遇”可以对应于将人类对话者的注视引导到任何任意定义的区域。该区域可以对应于机器人的面部或眼睛的表示,或者可以对应于显示器或其他焦点。虽然如图1中所呈现的,向机器人提供视频输入并支持其注视跟踪功能的摄像机以类似于人类的面部上的眼睛的方式被放置,但并不是在所有实施例中都需要是这样的情况。
因此,对人类对话者的注视的定向的确定可以包括对人类对话者的注视已经返回到对话的焦点的确定。
使用各种系统来跟踪眼睛移动,这些系统可以适于实现该功能。可以使用任何这种系统,包括头戴式系统、基于台式的系统或远程系统。这些设备通常使用摄像机和处理软件,以根据红外发射源的瞳孔/角膜反射来计算注视位置。为了增加台式设备的数据准确度,可以通过在台上固定下巴来限制头部移动。校准过程也是常见的,以确保系统准确度。校准过程通常包括在观看场景的不同位置显示若干点;眼睛跟踪软件将计算处理瞳孔位置和头部位置的转换。基于台式的眼睛跟踪器通常是双目的,并且因此可以计算眼睛发散度,并且以x-y像素输出注视交叉点(gip)的原始坐标,该原始坐标实时应用于屏幕。该特征允许将注视位置集成作为针对hmi的输入。然后,定义感兴趣区域(aoi)以与用户进行交互。当注视与aoi相遇时,生成事件,并且将发送一条特定的信息。当aoi是具有一定自由度的接口元素(例如,滚动条)时,人们正在讨论的是动态aoi(daoi)。与静态aoi相比,跟踪daoi是更具挑战性的。
在一些实施例中,注视方向可以仅仅被认为是瞬时关注点,即,眼睛跟踪系统认为用户在接收到输入的瞬间正在注视的任何点。在某些实施例中,对用户的关心点的确定可以涉及在预定的持续时间内对用户的关注点的加权平均值的确定——下文描述了进一步的实施例。
将认识到的是,可以考虑基于对话者的身体移动的许多其他这种意图指示符。例如,对人类对话者相对于对话的焦点的物理接近程度的检测,对人类对话者的身体相对于对话的焦点的定向的检测,对人类对话者的指定身体部分相对于对话的焦点的定向(例如,头部角度)的检测,或人类对话者的眼睛睁开程度。
特别地,讲话者倾向于转移他们的注视或倾斜他们的头部以获得其轮次并且集中于制定回答,而在他们的响应结束处,他们通常看向听众以发信号表示他们已经结束了他们的回答,并且他们邀请听众接过交谈发言权。在开始响应时,人们倾向于用他们的上半身接近机器人,并且在讲话轮次的结束时移动到他们的初始位置。因此,头部角度可以包括第二意图指示符的组成部分。
在人们的讲话轮次的结束处,人们将其耳朵转向机器人,以专注于机器人的回答。因此,头部定向可以包括第二意图指示符的组成部分。
讲话轮次的结束常常伴随着手势的结束。因此,特性手部移动可以包括第二意图指示符的组成部分。
人们倾向于在倾听时比讲话时更加静止。因此,一般对话者的移动级别可以包括第二意图指示符的组成部分。
面部动作单元可以包括第二意图指示符的组成部分。例如,眯着眼睛可以被认为是用户的思考行为,这指示他想保持发言权。
在图1a的场景中,人类对话者在他们的话语的结束处包括补白的事实以及他们的注视仍然从与机器人的面部相对应的焦点区域转移开的事实可以被认为与对话者不旨在放弃发言权一致,并且可以得出这样的结论:对话者不旨在放弃发言权。
图1b呈现了图1a的场景的第一替代方案。
图1b与图1a相同,除了如在文本气泡111b中示出的人类对话者已经说出了话语“facilisestetexpeditadistinctio……”之外。即,在时间窗口131期间没有明显的补白。基于此,尽管人类对话者在他们的话语的结束处不包括补白的事实可能已经被认为指示对话者不旨在保留发言权,但是他们的注视仍然从与机器人的面部相对应的焦点区域转移开的事实可以被认为是他们实际上不旨在放弃发言权的指示符,并且可以得出这样的结论:对话者不旨在放弃发言权。
图1c呈现了图1a的场景的第二替代方案。
图1c与图1a相同,除了人类对话者110的注视112c与焦点区域123一致之外,该焦点区域123如所示地与机器人120的面部相关联。
基于此,尽管人类对话者在他们的话语的结束处包括补白的事实可能已经被认为指示对话者确实旨在保留发言权,但是他们的注视返回到与机器人的面部相对应的焦点区域的事实可以被认为是他们确实旨在放弃发言权的指示符,并且可以得出这样的结论:对话者不旨在放弃发言权。
图1d呈现了图1a的场景的第三替代方案。
图1d与图1a相同,除了如在文本气泡111b中示出的人类对话者已经说出了话语“facilisestetexpeditadistinctio……”之外。即,在时间窗口131期间没有明显的补白。此外,人类对话者110的注视112c与焦点区域123一致,该焦点区域123如所示地与机器人120的面部相关联。
基于此,人类对话者在他们的话语的结束处不包括补白的事实已经被认为指示对话者确实旨在放弃发言权,并且他们的注视返回到与机器人的面部相对应的焦点区域的事实可以一起被认为与人类对话者放弃对对话的控制一致,并且可以得出这样的结论:对话者确实旨在放弃发言权。
基于图1a、图1b、图1c和图1d中探索的不同场景,可以提供一种用于对在与人类对话者的对话中用于注入的材料进行机器处理的方法。
图3示出了根据实施例的检测在与机器接口的对话中人类对话者对讲话轮次的让渡的方法。
如所示的,该方法在步骤300处开始,然后进行到步骤305,在步骤305处,在来自人类对话者的话语期间捕获基于对话者的第一语音特性的第一意图指示符,例如,如上面参考图1a、图1b、图1c和图1d所讨论的。在步骤310处,确定话语是否已经终止,并且在话语尚未终止的情况下,方法返回到步骤305。在步骤310处确定话语已经终止的情况下,方法进行到步骤315,在步骤315处,捕获基于对话者的身体移动的第二意图指示符。
对人类对话者的第二意图指示符的捕获可以在预定的持续时间内被执行,或者直到获得完整的测量为止,或者直到达到要求的收敛度或置信度为止,或者以其他方式。
方法接下来进行到步骤320,在步骤320处,确定第一意图指示符和第二意图指示符是否一起被认为与人类对话者放弃对对话的控制一致。如果在步骤320处确定第一意图指示符和第二意图指示符一起被认为与人类对话者放弃对所述对话的控制一致,则方法进行到步骤325,在步骤325处,可以将材料注入对话中。如果确定第一意图指示符和第二意图指示符并不一起与人类对话者放弃对对话的控制一致,则方法返回到检测来自人类对话者的话语的终止的步骤305,这在本实施例中是经由步骤305实现的。
如关于图1a、图1b、图1c和图1d讨论的那样,已经表明了一种二元方法,其中第一意图指示符和第二意图两者都必须对应于人类对话者希望放弃对交谈发言权的控制,以使机器人占有交谈发言权。将认识到的是,在一些实施例中,第一意图指示符或第二意图指示符中的任一个或两者可以是非二元的。
在确定第一意图指示符和第二意图指示符一起被认为与人类对话者放弃对对话的控制一致的情况下,方法进行到步骤325,在步骤325处,系统响应人类对话者。可以基于当前迭代中对话者的话语和/或任何先前的话语以及任何外部刺激来编译该响应,或者该响应可以完全独立于对话者的话语。该响应可以采取语音和/或系统能够执行的任何其他动作的形式。当确定对话者已经放弃交谈发言权时不一定立即注入材料,并且实际上在那时材料可能尚未被定义。在某些实施例中,在执行响应之前,可能有处理对话者的评论并作为其结果生成材料的附加步骤。
将认识到的是,可以在不改变上面描述的步骤的逻辑重要性的情况下修改这些步骤。例如,在一些实施例中,一旦在步骤310处检测到话语的结束,就可以对传入音频进行缓冲,并且可以在经缓冲的数据上追溯执行对音频的评估以确定存在第一意图指示符。这不一定表明重构图3的流程图,因为即使稍后执行对音频的评估,但是在一些情况下,第一意图指示符可能仍然被认为在音频被缓冲时被捕获。在一些实施例中,捕获第一意图指示符的步骤可以包括评估音频数据以提取第一意图指示符的子步骤,该子步骤可以在步骤310处检测到话语的结束之前或之后发生。
已经发现,一方面基于对话者的第一语音特性的第一意图指示符和另一方面基于对话者的身体移动的第二意图指示符的组合考虑在测定人类对话者相对于放弃交谈发言权的真实意图时特别高效。在面对不存在来自机器人的响应的情况下,这倾向于导致人类对话者的重复较少发生,机器人对人类对话者的不适当中断较少发生,以及来自人类对话者的话语相应地更长。结构化的方法在话语的结束处检测基于第一语音特性的第一意图指示符并且在话语被认为终止之后考虑基于身体移动的第二意图指示符产生了这些好处,同时限制了对处理器、存储器、能量和其他系统资源的需求。
图4示出了根据图3的实施例的发展的检测在与机器接口的对话中人类对话者对讲话轮次的让渡的方法。
如图3中示出的,一旦在步骤310处检测到话语的终止,方法就如上面所描述地进行到步骤315,并且并行地进行到附加步骤417。在步骤417处,捕获基于对话者的第二语音特性的第三意图指示符。方法从步骤417进行到步骤418,在步骤418处确定第三意图指示符是否与人类对话者放弃对对话的控制一致。
第三意图指示符可以包括在话语的结束之后检测来自人类对话者的任何语音。因此,检测第二意图指示符的步骤可以包括:另外地检测来自人类对话者的其他话语,并且在检测到任何这种其他话语的情况下,返回到检测来自人类对话者的话语的终止的步骤,这在本实施例中是经由步骤305实现的。
这种新的语音可以被认为指示人类对话者恢复该阶段,而无论如第一意图指示符和第二意图指示符所表明的他们的明显意图是什么。
因此,如果在步骤418处确定第三意图指示符并不与人类对话者放弃对对话的控制一致,则方法返回到步骤305。否则,该方法进行到步骤320,如关于图3所讨论的。
将认识到的是,步骤320和步骤418可以在单个步骤中组合,其中确定第一意图指示符和第二意图指示符是否一起被认为与人类对话者放弃对对话的控制一致的步骤还包括确定第一意图指示符和第二意图指示符和第三意图指示符是否一起被认为与人类对话者放弃对对话的控制一致。
因此,第三意图指示符可以包括以下各项中的一个或多个:对来自人类对话者的补白声音的分析,对来自人类对话者的声音的音调的检测或话语的语义组成部分。
图5呈现了根据实施例的用于检测在与机器的对话中人类对话者对讲话轮次的让渡的系统。
如所示的,系统520包括:输入526,其接收承载来自人类对话者110的话语的通信信道524的表示;输出525,其用于传达承载材料的通信信道的表示;处理器521,其适于处理表示以检测话语的终止。
处理器521还适于在来自人类对话者110的话语的终止被确定的情况下,捕获基于对话者的第一语音特性的第一意图指示符以及基于对话者的身体移动的第二意图指示符,并且确定一个或多个意图指示符是否与人类对话者放弃对对话的控制一致,并且在确定一个或多个意图指示符与人类对话者放弃对对话的控制一致的情况下,响应对话者,例如,如上面关于图3或图4所讨论的。
根据某些可选的变型,图5的系统可以包括:由对话者110可感知的焦点529;以及检测器522,其能够将对话者相对于焦点的身体移动的方面确定为第二意图指示符。通过示例的方式,检测器522可以包括如上面所讨论的摄像机122。
根据图5的系统的某些可选的变型,第二意图指示符可以包括以下各项中的一个或多个:对人类对话者的注视的定向的确定,对人类对话者相对于对话的焦点的物理接近程度的检测,对人类对话者的身体相对于对话的焦点的定向的检测,对人类对话者的指定身体部分相对于对话的焦点的定向的检测。该系统还可以包括视频输入换能器522和适于确定人类对话者的注视的定向的注视跟踪器。如上面所讨论的,这样的注视跟踪器可以被实现为独立系统,或者使用来自诸如摄像机之类的现有系统的数据来实现。可以通过硬件或软件或两者的组合来执行对该数据的注视跟踪处理。
根据图5的系统的某些可选的变型,第一意图指示符或第三意图指示符可以包括以下各项中的一个或多个:对来自人类对话者的补白声音的分析,对来自人类对话者的声音的音调的检测或话语的语义组成部分。
虽然已经关于并入了所提到的各种操作系统(例如,摄像机122、麦克风124、扬声器125、处理器121和焦点区域123)的机器人120描述了图1a、图1b、图1c和图1d,但是将认识到的是,本发明的实施例可以采取操作元件的任何适当分布的形式。在一些实施例中,焦点在某种程度上可以类似于仿生面部。例如,焦点可以包括表示眼睛的两个点。焦点可以另外地包括嘴或鼻子的表示。在一些情况下,这些特征可以与功能组件一致,这些功能组件可以对应于相应的面部特征的功能(眼睛对应于视频输入,嘴巴对应于音频换能器等)或不对应于这些面部特征的功能,或者可替代地可以仅是针对一些或所有元件的图形表示。该表示可以或多或少地类似于人类的面部,并且在一些情况下可以另外地表示诸如肤色、纹理等之类的特征。该表示可以表示动物、奇幻生物或机械实体。该表示可以以整体或部分地呈现在图形显示器上。在另一方面,焦点区域可以包括任何任意的可见特征。例如,焦点区域可以仅包括在墙壁、格栅、窗户或可能由数字单元例如经由虚拟或增强现实可标识的区域上的斑点。同样地,焦点区域不一定被定义在物理空间中,而可以仅存在于三维的计算机生成的空间中。
诸如摄像机122、麦克风124、扬声器125之类的其他元件可以位于相对于该焦点区域的任何位置。可以提供多个摄像机、麦克风或扬声器,并且这些元件可以根据相对于对话者最佳的位置独立地操作,或者来自或去往特定类型的设备的每个示例中的一些或全部示例的信号可以被一起处理以便获得最优结果。例如,来自可以分布在空间中的多个麦克风的信号可以被一起处理以便排除背景噪声等。
上面已经将基于对话者的身体移动的第二意图指示符呈现为经由视频输入122捕获的,然而,取决于所讨论的身体移动的性质,可以提供其他传感器。例如,取决于要检测的身体移动,可以提供lidar传感器、声波传感器、红外传感器或任何其他合适的传感器。
将认识到的是,可以基于多个相应的输入来编译第一意图指示符和/或第二意图指示符和/或第三指示符。第一意图指示符和/或第三意图指示符可以在包括上面所呈现的那些语音特性中的任一种特性的合适的语音特性的任何组合上编译,并且第二意图指示符可以在包括上面所呈现的那些身体移动特性中的任一种特性的合适的身体移动特性的任何组合上编译。
根据某些实施例,机器人或其他交谈代理通过检测不存在特定的语音特性(例如,在话语的结束处的补白语音的引入)和存在特性物理行为(例如,在话语的结束之后的指定时间窗口期间,对话者将他们的注视返回到交谈的焦点,例如,机器人的面部)来确定人类对话者是否已经放弃交谈发言权。在检测到特性的这种组合的情况下,机器人可以确定交谈发言权是开放的,并且响应可能是适当的。这可能例如经由话音或文本来触发交谈响应。
所公开的方法可以采取完全硬件实施例(例如,fpga)、完全软件实施例(例如,以根据本发明控制系统)或包含硬件元件和软件元件两者的实施例的形式。软件实施例包括但不限于固件、常驻软件、微码等。本发明可以采取可从计算机可用或计算机可读介质访问的计算机程序产品的形式,从而提供程序代码以供计算机或指令执行系统使用或与其结合使用。
计算机可用或计算机可读可以是可以包含、存储、传送、传播或传输供指令执行系统、装置或设备使用或与其结合使用的程序的任何装置。介质可以是电子、磁性、光学、电磁、红外或半导体系统(或装置或设备)或传播介质。
在一些实施例中,本文描述的方法和过程可以由用户设备以整体或部分地实现。这些方法和过程可以通过计算机应用程序或服务、应用编程接口(api)、库和/或其他计算机程序产品或此类实体的任何组合来实现。
用户设备可以是移动设备(例如,智能电话或平板计算机)、计算机或具有处理能力的任何其他设备(例如,机器人或其他连接的设备)。
图6示出了适合于本发明的实施例的实现方式的通用计算系统。
如图6中示出的,系统包括逻辑器件601和存储设备602。该系统可以可选地包括显示子系统611,输入子系统612、613、614,通信子系统620和/或未示出的其他组件。
逻辑器件901包括被配置为执行指令的一个或多个物理设备。例如,逻辑器件601可以被配置为执行作为一个或多个应用、服务、程序、例程、库、对象、组件、数据结构或其他逻辑构造的一部分的指令。可以实现这样的指令以执行任务、实现数据类型、转换一个或多个组件的状态、实现技术效果或以其他方式达到期望的结果。
逻辑器件601可以包括被配置为执行软件指令的一个或多个处理器。另外地或可替代地,逻辑器件可以包括被配置为执行硬件或固件指令的一个或多个硬件或固件逻辑器件。逻辑器件的处理器可以是单核心的或多核心的,并且在其上执行的指令可以被配置用于顺序、并行和/或分布式处理。逻辑器件601的单个组件可选地可以分布在两个或更多个分离的设备之间,这些设备可以位于远程处和/或被配置用于协调处理。逻辑器件601的方面可以由以云计算配置配置的可远程访问的联网的计算设备虚拟化并执行。
存储设备602包括一个或多个物理设备,这些物理设备被配置为保存可由逻辑器件执行以实现本文描述的方法和过程的指令。当实现这样的方法和过程时,可以转换存储设备902的状态——例如以保存不同的数据。
存储设备602可以包括可移除和/或内置的设备。存储设备602可以包括一种或多种类型的存储设备,包括光学存储器(例如,cd、dvd、hd-dvd、蓝光光盘等)、半导体存储器(例如,ram、eprom、eeprom等)和/或磁性存储器(例如,硬盘驱动器、软盘驱动器、磁带驱动器、mram等)以及其他。存储设备可以包括易失性、非易失性、动态、静态、读取/写入、只读、随机存取、顺序存取、位置可寻址、文件可寻址和/或内容可寻址的设备。
在某些布置中,系统可以包括适于支持在逻辑器件601与其他系统组件之间的通信的接口603。例如,附加系统组件可以包括可移除和/或内置的扩展存储设备。扩展存储设备可以包括一种或多种类型的存储设备,包括光学存储器632(例如,cd、dvd、hd-dvd、蓝光光盘等)、半导体存储器633(例如,ram、eprom、eeprom、flash等)和/或磁性存储器631(例如,硬盘驱动器、软盘驱动器、磁带驱动器、mram等)以及其他。这样的扩展存储设备可以包括易失性、非易失性、动态、静态、读取/写入、只读、随机存取、顺序存取、位置可寻址、文件可寻址和/或内容可寻址的设备。
将认识到的是,存储设备包括一个或多个物理设备,并且不包括传播信号本身。然而,与存储在存储设备上相反,本文描述的指令的方面可替代地可以通过通信介质(例如,电磁信号、光信号等)传播。
逻辑器件601和存储设备602的方面可以被一起集成为一个或多个硬件逻辑组件。这样的硬件逻辑组件可以包括例如现场可编程门阵列(fpga)、程序和应用专用集成电路(pasic/asic)、程序和应用专用标准产品(pssp/assp)、片上系统(soc)以及复杂可编程逻辑器件(cpld)。
术语“程序”可以用于描述被实现以执行特定功能的计算系统的方面。在一些情况下,可以经由逻辑器件执行由存储设备保存的机器可读指令来实例化程序。将理解的是,可以根据相同的应用、服务、代码块、对象、库、例程、api、功能等实例化不同的模块。同样地,可以由不同的应用、服务、代码块、对象、例程、api、功能等实例化相同的程序。术语“程序”可以包含单个或成组的可执行文件、数据文件、库、驱动程序、脚本、数据库记录等。
系统包括眼睛跟踪硬件,该眼睛跟踪硬件可以对应于如上面所描述的元件122、522。该硬件可以是系统或外围设备的组成组件。该硬件的功能可以由运行在逻辑器件601上的软件或以其他方式支持或增强。
特别地,图6的系统可以用于实现本发明的实施例。
例如,实现关于图3或图4描述的步骤的程序可以存储在存储设备602中并且由逻辑器件601执行。从人类对话者接收到的数据、要被注入对话中的数据、移动数据和/或者用户注视方向可以存储在存储设备602或扩展存储设备632、633或631中。逻辑器件601可以使用从相机616或眼睛跟踪系统660接收到的数据来确定用户注视方向,并且显示器611可以提供针对对话的输出和/或作为焦点的功能。
因此,本发明可以以计算机程序的形式体现。
将认识到的是,如本文所使用的“服务”是跨多个用户会话可执行的应用程序。服务可以对一个或多个系统组件、程序和/或其他服务而言是可用的。在一些实现方式中,服务可以在一个或多个服务器计算设备上运行。
当包括显示子系统611时,该显示子系统611可以用于呈现由存储设备保存的数据的视觉表示。该视觉表示可以采取图形用户接口(gui)的形式。当本文描述的方法和过程改变了由存储设备602保存的数据,并因此转换了存储设备602的状态时,显示子系统611的状态可以同样地被转换以视觉地呈现基础数据的变化。显示子系统611可以包括实际上利用任何类型的技术的一个或多个显示设备。这种显示设备可以在共享的外壳中与逻辑器件和/或存储设备组合,或者这种显示设备可以是外围显示设备。
当包括输入子系统时,该输入子系统可以包括一个或多个用户输入设备(例如,键盘612、鼠标611、触摸屏611或游戏控制器、按钮、脚踏开关等(未示出))或与其接合。在一些实施例中,输入子系统可以包括所选定的自然用户输入(nui)元件部分或与其接合。这种元件部分可以是集成的或外围的,并且输入动作的转导和/或处理可以在板上或板外进行处理。示例nui元件部分可以包括用于语音和/或话音识别的麦克风;用于机器视觉和/或手势识别的红外、彩色、立体和/或深度相机;用于运动检测和/或意图识别的头部跟踪器、眼睛跟踪器660、加速度计和/或陀螺仪;以及用于评估大脑活动的电场感应元件部分。
当包括通信子系统620时,该通信子系统620可以被配置为将计算系统与一个或多个其他计算设备通信地耦合。例如,通信模块可以经由任何尺寸的网络(包括例如个域网、局域网、广域网或互联网)将计算设备通信地耦合到例如托管在远程服务器676上的远程服务。通信子系统可以包括与一种或多种不同的通信协议兼容的有线和/或无线通信设备。作为非限制性示例,通信子系统可以被配置用于经由无线电话网络674或者有线或无线局域网或广域网进行通信。在一些实施例中,通信子系统可以允许计算系统经由诸如互联网675之类的网络向其他设备发送消息和/或从其他设备接收消息。通信子系统可以另外地支持与无源设备(nfc、rfid等)的短距离感应通信621。
图6的系统旨在反映各种不同类型的信息处理系统。将认识到的是,关于图6描述的子系统和特征中的许多对于本发明的实现方式不是要求的,而是被包括以反映根据本发明的可能的系统。将认识到的是,系统架构变化很大,并且图6的不同子系统之间的关系仅是示意性的,并且可能关于系统中的角色的布局和分布而变化。将认识到的是,在实践中,系统可能并入关于图6描述的各种特征和子系统的不同子集。
图7和图8公开了根据本发明的其他示例设备。本领域普通技术人员将认识到,将来可以采用也根据本发明操作的系统。
图7示出了适于构成实施例的机器人。如图7中示出的,机器人包括如上面所描述的元件601、602、603、611、620、631、633、614、615、616、660和621。该机器人可以经由移动电话网络674或互联网675与服务器676进行通信。也可以使用诸如专用网络或wi-fi之类的替代通信机制。在另一方面,可以省略元件612、613、632、621、617、6。虽然被示出为仿生机器人,但是该机器人可以类似地是机器人割草机、吸尘器或任何类型的家用、社交或工业机器人。
图8示出了适于构成实施例的智能电话设备。如图8中示出的,智能电话设备并入如上面所描述的元件601、602、603、620,可选的近场通信接口621,闪速存储器633以及元件614、615、616、640和611。该智能电话设备经由网络675与电话网络674和服务器676进行通信。也可以使用诸如专用网络或wi-fi之类的替代通信机制。该图中公开的特征也可以包括在平板计算机设备内。
将认识到的是,本发明的实施例适于要求解析自由人类语音的无数其他上下文。例如,智能个人助理在网络扬声器设备、车辆等上进行接合。
将认识到的是,并非所有元件都需要在相同的位置提供——例如,虽然音频输入和输出元件、能够检测人类对话者的移动的元件以及可选地焦点可以被本地地提供给人类对话者,但其他功能中的任一项都可以远程实现。
将理解的是,本文描述的配置和/或方法本质上是示例性的,并且这些特定的实施例或示例不应被认为具有限制意义,因为许多变型是可能的。本文描述的特定例程或方法可以表示任何数量的处理策略中的一个或多个。因此,可以以示出和/或描述的序列、以其他序列、并行地执行示出和/或描述的各种动作或者省略这些动作。同样地,可以改变上面描述的过程的次序。
本公开的主题包括本文公开的各种过程、系统和配置以及其他特征、功能、动作和/或属性的所有新颖和非显而易见的组合和子组合,以及其任何和所有等效物。
- 还没有人留言评论。精彩留言会获得点赞!