基于振幅和相位信息的多目标学习的远场语音识别方法与流程
本发明属于远场语音识别
技术领域:
,具体是涉及一种基于振幅和相位信息的多目标学习的远场语音识别方法。
背景技术:
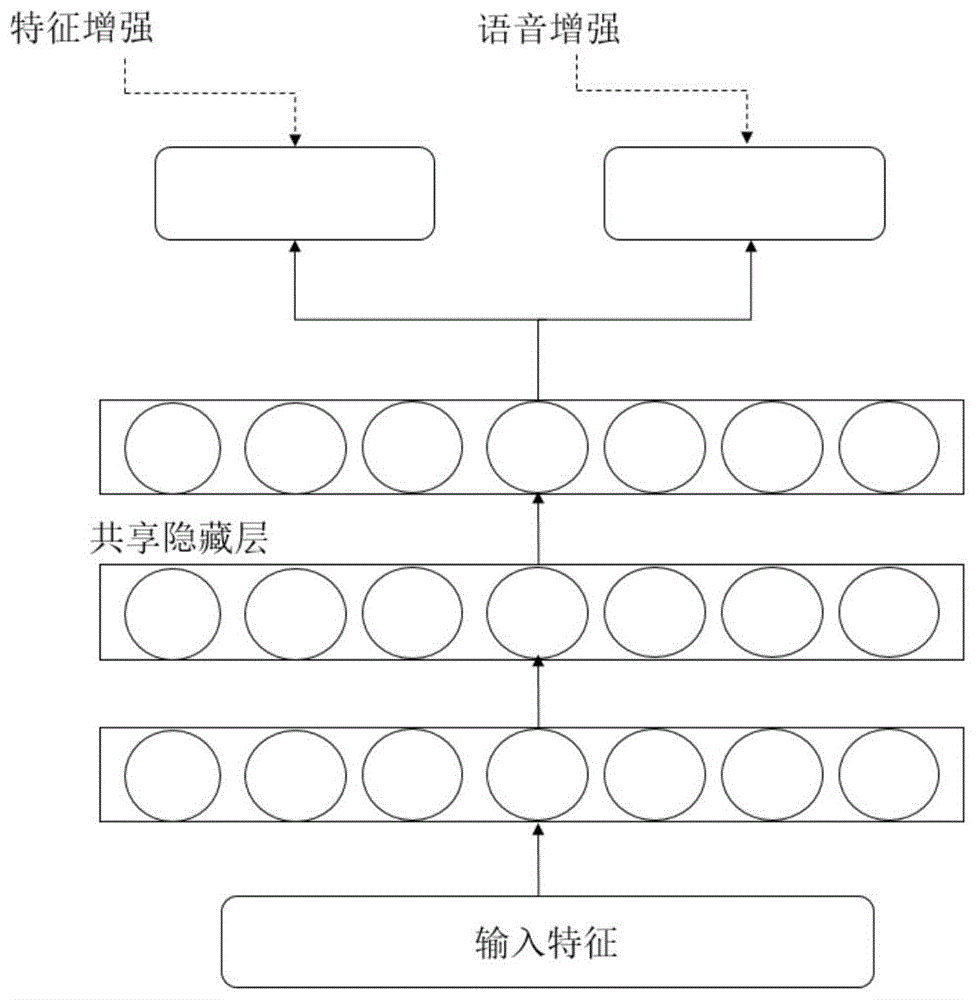
:语音交互是人类社会最直接、最自然的沟通交流方式。语音识别作为关键技术之一,能够通过识别语音信号,将语音信号转化为文本文字。语音识别是一门触及广泛领域的交叉学科,其最终目的是使人类同计算机进行语音交互。经过多年的研究,近场语音识别技术已经取得了重大突破,并大大提高了性能,但是远场语音识别技术还存在着诸多问题,在远场语音识别中,目标语音经常会被背景噪声和混响干扰,从而降低了语音识别的准确率,导致性能的急剧下降。因此需要对麦克风采集到的信号进行语音增强处理,去除噪声和混响等干扰因素。技术实现要素:本发明针对相位信息在混响语音中受到严重干扰,而且相位信息本身存在的相位卷绕问题,使用了群延迟方法避免相位信息的卷绕问题,同时尝试使用不同的相位信息,群延迟系统(mgdcc)以及基于相位域的源分离方法的声道信息(pbsfvt),利用不同相位信息的互补性作为重要的辅助特征来进行语音增强。为了解决以上问题,本发明使用不同的相位信息作为重要的辅助特征来进行语音增强,提出了一种基于振幅和相位信息的多目标学习的远场语音识别方法,采用的技术方案如下:基于振幅和相位信息的多目标学习的远场语音识别方法,包括以下步骤:1)输入数据准备:分别对训练集、开发集和验证集中的数据进行数据准备;2)特征提取:(1)基于振幅信息的特征提取:通过分帧、加窗,并对每一个短时分析窗,通过快速傅里叶变换将信号由时域转换到频域并且得到对应的频谱,然后使用mel滤波器进行频率的过滤并且以此来模拟人类的感知系统;(2)基于相位信息的特征提取:提取每一帧语音的相位信息,包括群延迟系统mgdcc以及基于相位域的源分离方法的声道信息pbsfvt两种相位特征;3)模型训练:将提取到的特征输入到多目标的dnn中,多目标的dnn网络可以同时对两个不同的目标进行学习,从而模拟不同目标之间的共性和差异。所述步骤2)-(2)中基于相位信息的特征提取,包括群延迟系统mgdcc相位特征,具体提取过程如下:在进行语音信号处理的过程中,需要对语音信号的相位部分进行展开求解其负导数,其负导数称为群延迟系数(gdf);群延迟函数其本质上是计算连续语谱图的导数的负数;连续的相位谱特征即非卷绕的相位谱特征可以表示为:群延迟函数也同样可以被计算为下列的表述形式:其中:下角标r和i分别表示的实部和虚部两个部分,和y(ω)分别表示的是x(n)和nx(n)傅里叶转换之后的频域信息;调整之后的群延迟系数可以计算为:其中:s(ω)表示x(ω)的平滑版本;减少频谱的尖峰特性,引入了两个新的变量α和γ来进行消除:其中:α和γ,其取值范围均在0~1之间。所述步骤2)-(2)中基于相位信息的特征提取,包括基于相位域的源分离方法的声道信息pbsfvt两种相位特征,具体提取过程如下:使用短时傅里叶变换x(ω)可以被分解为两种:全通相位以及最小相位两个部分:x(ω)=|x(ω)|ejarg{x(ω)}=xminph(ω)xallp(ω)其中:xminph(ω)和xallp(ω)分别表示傅里叶变换之后的x对应的最小相位部分和全通相位部分,并且最小相位和原始语音信号之间存在着下式的关系:|x(ω)|=|xminph(ω)|另一方面,最小相位和全通相位之间的关系为:arg{x(ω)}=arg{xminph(ω)}+arg{xallp(ω)}通过希尔伯特变换将语音信号从振幅域变换到相位域中,获得最小相位特征:通过傅里叶变换后,卷积关系会变成相乘关系,得到下列等式:将最小相位特征以及声道信息处理方法结合起来,使用源滤波模型在最小相位域的操作进行源滤波操作进行信息分离,将最小相位语音信号分解为声源信息和声道信息,从而得到两者不同的模型。所述步骤3)具体为:构建多任务深度神经网络,将提取的振幅特征和相位特征输入到神经网络中训练,输出增强后语音以及增强后的特征。还包括srmr测评和语音识别,具体是将dnn输出的增强后的特征进行语音识别,从而得到词错误率wer(worderrorrate),把输出的增强后的语音进行srmr评测。有益效果本发明利用了多目标学习的方法,同时增强了语音信号和语音的特征,与现有的方法相比,考虑到了群延迟系统(mgdcc)特征在混响语音下的效果较差,增加了另一种相位特征基于相位域的源分离方法的声道信息(pbsfvt)来弥补mgdcc的不足,进而提高语音识别准确率。附图说明图1是本发明提出的多目标学习框架基本结构图。图2是基于源分离方法的最小相位域声道信息提取过程。图3是本发明方法流程图。具体实施方式下面通过具体实施例和附图对本发明作进一步的说明。本发明的实施例是为了更好地使本领域的技术人员更好地理解本发明,并不对本发明作任何的限制。如图3所示,一种基于振幅和相位信息的多目标学习的远场语音识别方法,包括以下步骤:步骤一,输入数据准备:数据集选取reverb2014挑战赛所提供的数据,分别对训练集、开发集和验证集中的数据进行数据准备;步骤二,特征提取:1)基于振幅信息的特征提取:通过分帧、加窗,并对每一个短时分析窗,通过快速傅里叶变换将信号由时域转换到频域并且得到对应的频谱,然后使用mel滤波器进行频率的过滤并且以此来模拟人类的感知系统。2)基于相位信息的特征提取:提取每一帧语音的相位信息,包括群延迟系统(mgdcc)以及基于相位域的源分离方法的声道信息(pbsfvt)两种相位特征。本发明所述步骤二基于相位信息的特征提取包括群延迟系统(mgdcc)以及基于相位域的源分离方法的声道信息(pbsfvt)两种相位特征,具体提取过程如下:1)mgdcc提取:当我们在进行语音信号处理的过程中,需要对语音信号的相位部分进行展开求解其负导数,其负导数称为群延迟系数(gdf),这样做可以有效地用于提取各种语音信号参数。群延迟函数是目前相位谱的主要表示方法,其本质上是计算连续语谱图的导数的负数。因此连续的相位谱特征即非卷绕的相位谱特征可以表示为:在上式中,是非卷绕的相位信息函数,群延迟函数也同样可以被计算为下列的表述形式,其中,下角标r和i分别表示的实部和虚部两个部分,和y(ω)分别表示的是x(n)和nx(n)傅里叶转换之后的频域信息。另外从上式中可以看出,分母在靠近单位圆的零处消失,因此需要对该函数进行进一步的调整,即针对分母变为零的情况进行调整。通过用其基于平滑的谱来代替分母进行解决分母变为零的问题,可以克服群延迟谱的尖峰的特性。调整之后的群延迟系数可以计算为:其中,s(ω)表示x(ω)的平滑版本,但是原始的群延迟函数仍然存在着共振峰谱的峰值尖锐问题,这样会影响语音识别的性能。为了减少频谱的尖峰特性,引入了两个新的变量α和γ来进行消除,其取值范围在0~1之间。2)pbsfvt提取:语音信号是一种混合相位信息的信号,其中包含最小相位信息以及全通相位信息等等。因此使用短时傅里叶变换x(ω)可以被分解为两种:全通相位以及最小相位两个部分。x(ω)=|x(ω)|ejarg{x(ω)}=xminph(ω)xallp(ω)其中,xminph(ω)和xallp(ω)分别表示傅里叶变换之后的x对应的最小相位部分和全通相位部分,并且最小相位和原始语音信号之间存在着下式的关系:|x(ω)|=|xminph(ω)|另一方面,最小相位和全通相位之间的关系为:arg{x(ω)}=arg{xminph(ω)}+arg{xallp(ω)}对于最小相位部分的信息,希尔伯特变换提供了相位和振幅之间的映射关系,因此我们可以通过希尔伯特变换将语音信号从振幅域变换到相位域中,如下所示,这样我们就可以获得最小相位特征,通过傅里叶变换后,卷积关系会变成相乘关系,因此可以得到下列等式:可以将最小相位特征以及声道信息处理方法结合起来,使用源滤波模型在最小相位域的操作进行源滤波操作进行信息分离,这样就可以将最小相位语音信号分解为声源信息和声道信息,从而得到两者不同的模型。步骤三,模型训练:将提取到的特征输入到多目标的dnn中,多目标的dnn网络可以同时对两个不同的目标进行学习,从而模拟不同目标之间的共性和差异。步骤四,输出结果:将dnn输出的增强后的特征进行语音识别,从而得到wer(worderrorrate),把输出的增强后的语音进行srmr评测。图1是本发明所提出的多目标学习框架基本结构图,将基于mfcc基本特征的语音识别任务作为主任务,基于语谱图特征的语音增强任务作为辅助任务。这种前端特征处理模型将语音识别任务和语音增强任务结合起来,利用神经网络的非线性映射能力进行去混响操作。在前端去混响处理的回归模型中,以最小化均方误差(mse)的损失函数为目标进行优化。多目标神经网络学习同时估计两个不同任务的目标,学习两个任务之间的共性和差异。与单独训练模型相比,该方法可以提高主任务模型的学习效率和预测精度。其中dnn有3层隐藏层,包括3072个节点,损失函数是mse,最优化算法选取的是随机梯度下降。语音识别任务选取23维的mfb特征作为基本特征,辅助的语音增强任务选取256维的语谱图特征,相位特征mgdcc和pbsfvt分别是13维和23维。在本多目标学习框架中,主要任务为特征增强任务,用于后端的语音识别系统,辅助任务为语音增强任务,用来提升主任务的泛化效果。通过共享层的表示方法能够学习两个任务之间的相关性。图2是基于源分离方法的最小相位域声道信息提取过程,由于语音信号中的大部分信息集中在中低频部分,因此使用梅尔滤波器进行过滤,在低频获得更高的分辨率,而高频部分则会被抑制其分辨率。另外最后的一步就是进行去相关操作,主要原因是使得数据更好地匹配在gmm-hmm系统中使用的对角协方差矩阵,获取得到声学模型中更精确的对齐信息。最后,对特征向量进行最终的处理,例如使用倒谱均值归一化(cmn),并计算动态特征。在本任务中,该特征参数的基本设置为帧长度,帧移位和滤波器数量分别为25ms和10ms和23个,之后使用dct去相关并且进行数据降维,获得13维的数据特征。表1是神经网络的结构以及参数设置;参数值共享隐藏层数3隐藏节点每层3072隐藏节点类型sigmoid损失函数mse(均方误差)最优化算法随机梯度下降上下文大小15迭代次数30表2是多任务学习框架中不同输入结果对比(wer%)表1列出了神经网络的结构以及具体的参数设置、表2是在reverb2014挑战赛数据集上进行的实验结果对比,评价指标是wer(worderrorrate),我们可以证明相位信息在多目标学习中的重要性。在本实验中,将相位信息作为幅度信息的重要的辅助信息,作为振幅特征的补充。在本发明中,通过希尔伯特特征空间转换的方法将在频域进行处理的信息转换到最小相位域进行估计相位信息,这样能够得到相对精确的相位估计特征。通过对比mfb+spectrum方法和mfb+spectrum+mgdcc+pbsfvt方法,可以看到自动语音识别的性能得到了提高,并将识别结果wer从26.57%降低到23.68%,相对错误率减少了10.88%。尽管上面结合图对本发明进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨的情况下,还可以做出很多变形,这些均属于本发明的保护之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1