车载语音分析方法、系统、存储介质以及设备与流程
本发明涉及语音控制领域,特别是涉及一种车载语音分析方法、系统、存储介质以及设备。
背景技术:
随着计算机技术的快速发展,利用计算机来实现语音识别已经日渐成熟。近年来,实现人机之间更加智能化的有效交互,构建更加高效流畅的人机交流环境已经成为当前信息技术领域不可或缺的热点话题。语音识别技术是当前实现人机交互最便捷的方式,它使得语音输入、语音搜索、智能家居控制等各种语音识别产品受到广大用户的青睐。
在汽车领域,相比于传统的按键、触屏操作,通过语音识别的方式来完成车辆操作和控制已经成为车载智能的标准配置,通过语音识别方式,可以减少驾驶员视线和双手的转移,有利于驾驶员集中精力驾驶,提高行车安全。
发明人在实现本发明的过程中,发现一般的车载智能语音操作控制,需要遵循车载系统的语音规律,语音识别准确率低,人机交互体验显得呆板,不灵活。
技术实现要素:
基于此,本发明的目的在于,提供一种车载语音分析方法,其具有能更精确地进行语音识别,使人机交互的体验更高效的优点。
一种车载语音分析方法,包括如下步骤:
获取待识别的车载语音信号以及汽车的标识信息;
根据待识别的车载语音信号,调用基于kaldi训练的语音识别模型、基于cmusphinx训练的语音识别模型以及多个语音识别服务商接口,获得多个待融合的语音文本;
通过多源文本融合模型将多个所述待融合的语音文本进行融合,获得融合后的语音文本;
根据所述汽车的标识信息以及所述语音文本,在汽车指令数据库中获得匹配的汽车操作指令。
本发明通过调用多个语音识别服务商接口、基于kaldi训练的语音识别模型、以及基于cmusphinx训练的语音识别模型,获得多个待融合的语音文本,再将获得的多个待融合的语音文本进行融合,以融合后的语音文本来匹配控制汽车的操作指令,提高了语音识别的准确性,提高了人机交互的效率和体验,使机器能更好地理解人类语言。
在一个实施例中,所述根据所述汽车的标识信息以及所述语音文本,在汽车指令数据库中获得匹配的汽车操作指令的步骤,包括:
根据所述汽车的标识信息,从汽车指令数据库中查询获得对应汽车的指令文字集以及操作指令集;
将所述语音文本和所述指令文字集中的各指令文字分别进行语义角色标注;
计算语义角色标注后的语音文本与语义角色标注后的各指令文字的语义相似度、词形相似度和句长相似度;
将所述语义相似度、词形相似度和句长相似度按照预设的权重进行累加,获得最高的累加值对应的指令文字或者按累加值降序排列时在预设范围内的累加值对应的指令文字,并将所述指令文字对应的操作指令作为匹配的汽车操作指令。
通过结合语义相似度、词形相似度和句长相似度进行相似度匹配,提高了操作指令的匹配精确度。
在一个实施例中,所述语义相似度的计算方式为:
上述公式中,t1和t2分别表示语义角色标注后的语音文本与语义角色标注后的指令文字;similarity(t1,t2)表示t1和t2之间的语义相似度;m,n分别表示t1中标注的语义角色的数量和t2中标注的语义角色的数量;(i,j)∈{(p,q)|rq,rq∈r(f1)∩r(f2),1≤p≤m,1≤q≤n};v1,v2分别表示t1中的动词和t2中的动词,similarity(v1,v1)为动词v1和动词v2的词语相似度;ei和ej分别表示t1中的动词和t2中的论元,similarity(ei,ej)为论元ei和论元ej间的相似度;α为谓词相似度在全句中所占的权重;
所述词形相似度的计算方式为:
上述公式中,wordsimilarity(t1,t2)表示t1和t2之间的词形相似度;len(t1)和len(t2)分别为t1和t2中词的数量,sameword为t1和t2中相同词的个数;
所述句长相似度的计算方式为:
上述公式中,lensimilarity(t1,t2)表示t1和t2之间的句长相似度;len(t1)和len(t2)分别为t1和t2两个句子中词的数量。
在一个实施例中,所述语义相似度、词形相似度和句长相似度按照预设的权重进行累加的计算方式为:
multisimilarity(t1,t2)=γ1similarity(t1,t2)+γ2wordsimilarity(t1,t2)+γ3lensimilarity(t1,t2)
上述公式中,γi权重,i∈[1,2,3]且
在一个实施例中,所述汽车的标识信息包括车辆品牌型号和车辆编号;所述汽车指令数据库包括各汽车的品牌型号、各汽车的车辆编号、各汽车对应的指令文字集以及操作指令集。
在一个实施例中,所述调用基于kaldi训练的语音识别模型、基于cmusphinx训练的语音识别模型以及多个语音识别服务商接口,获得多个待融合的语音文本的步骤,还包括:
将在预设时间内返回的文本作为待融合的语音文本;或
将预设数量内的文本作为待融合的语音文本。
在一个实施例中,所述多源文本融合模型包括两个循环神经网络,其中一个循环神经网络将多个待融合的语音文本作为输入,并输出一词向量;另一个循环神经网络将所述词向量解码为融合后的语音文本。
本发明还提供一种车载语音分析系统,包括:
语音获取模块,用于获取待识别的车载语音信号以及汽车的标识信息;
语音识别模块,用于根据待识别的车载语音信号,调用基于kaldi训练的语音识别模型、基于cmusphinx训练的语音识别模型以及多个语音识别服务商接口,获得多个待融合的语音文本;
文本融合模块,用于通过多源文本融合模型将多个所述待融合的语音文本进行融合,获得融合后的语音文本;
匹配模块,用于根据所述汽车的标识信息以及所述语音文本,在汽车指令数据库中获得匹配的汽车操作指令。
本发明通过调用多个语音识别服务商接口、基于kaldi训练的语音识别模型、以及基于cmusphinx训练的语音识别模型,获得多个待融合的语音文本,再将获得的多个待融合的语音文本进行融合,以融合后的语音文本来匹配控制汽车的操作指令,提高了语音识别的准确性,提高了人机交互的效率和体验,使机器能更好地理解人类语言。
本发明还提供一种计算机可读存储介质,其上储存有计算机程序,其特征在于,该计算机程序被处理器执行时实现如上述任意一项所述的车载语音分析方法的步骤。
本发明还提供一种计算机设备,其特征在于,包括储存器、处理器以及储存在所述储存器中并可被所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如上述任意一项所述的车载语音分析方法的步骤。
为了更好地理解和实施,下面结合附图详细说明本发明。
附图说明
图1为本发明车载语音分析方法的流程图;
图2为本发明车载语音分析方法的原理图;
图3为本发明匹配获得控制汽车的操作指令的流程图;
图4为本发明车载语音分析系统的结构框图;
图5本发明匹配模块的结构框图。
具体实施方式
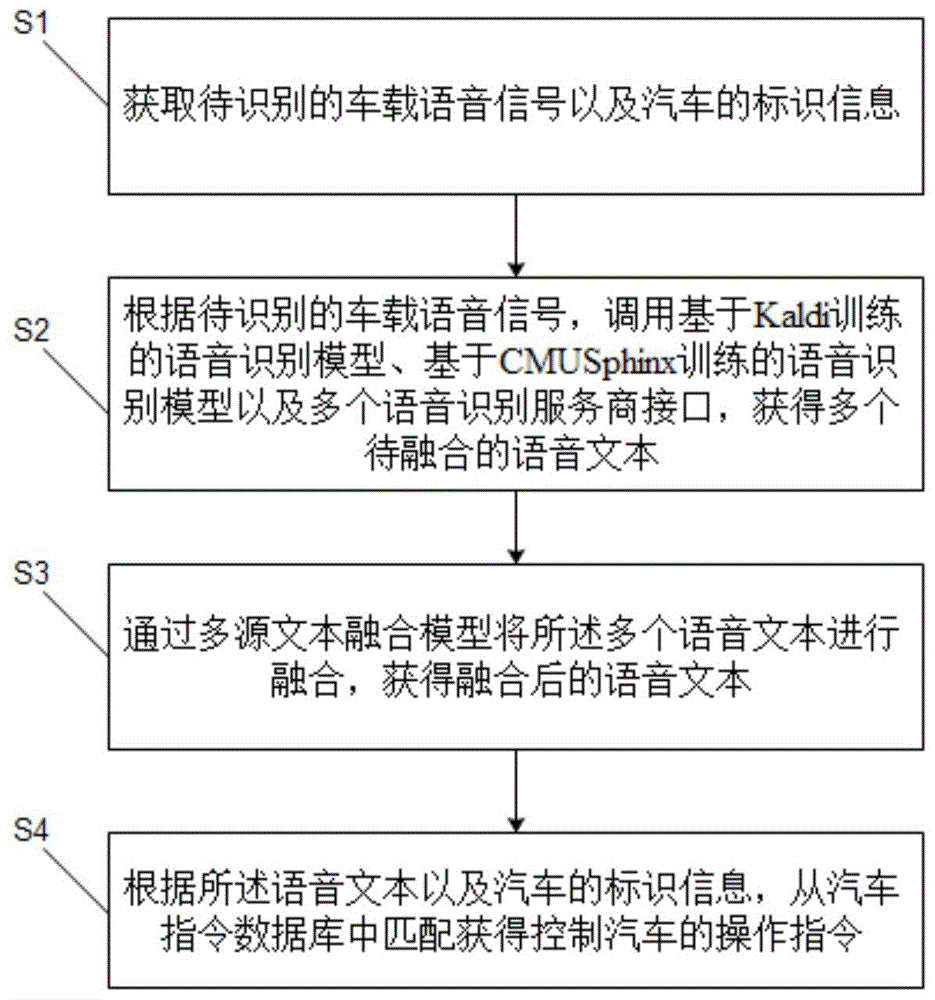
请同时参阅图1和图2,本发明的车载语音分析方法,包括如下步骤:
步骤s1:获取待识别的车载语音信号以及汽车的标识信息。
其中,所述待识别的车载语音信号可为各种终端语音采集设备,包括但不限于平板电脑,手机,笔记本电脑、mp4等设备采集到的语音数据。所述汽车的标识信息可包括车辆品牌型号和车辆编号等信息。
步骤s2:根据待识别的车载语音信号,调用基于kaldi训练的语音识别模型、基于cmusphinx训练的语音识别模型以及多个语音识别服务商接口,获得多个待融合的语音文本。
在一个实施例中,对于待识别的车载语音信号,还可通过场景融合的噪声消除算法进行去噪处理,以便于语音信号的识别和分析。
其中,所述语音识别服务商接口包括但不限于科大讯飞语音听写api(applicationprogramminginterface,简称应用程序编程接口)、阿里云语音识别api或者是sdk(softwaredevelopmentkit,简称软件开发工具包)的形式,通过所述语音识别服务商接口,可将待识别的车载语音信号直接返回到待融合的语音文本。
由于语音识别服务商接口的语音识别框架通常是基于gmm-hmm的,而浅层的模型结构的建模能力有限,不能捕获到数据特征之间的高阶相关性,因此,本申请在本地服务器增加了基于kaldi训练的语音识别模型、以及基于cmusphinx训练的语音识别模型同时进行文本识别,其中,基于kaldi训练的语音识别模型以及基于cmusphinx训练的语音识别模型是采用车载领域的语音数据集训练出来的模型,其对于车载语音信号的识别具有更准确的识别能力,而且通过将基于kaldi训练的语音识别模型、以及基于cmusphinx训练的语音识别模型和多个语音识别服务商接口反馈的待融合的语音文本进行融合来获得语音文本,提高了车载语音识别的准确性。
步骤s3:通过多源文本融合模型将所述多个语音文本进行融合,获得融合后的语音文本。
步骤s4:根据所述语音文本以及汽车的标识信息,从汽车指令数据库中匹配获得控制汽车的操作指令。
本发明通过调用多个语音识别服务商接口、基于kaldi训练的语音识别模型、以及基于cmusphinx训练的语音识别模型,获得多个待融合的语音文本,再将获得的多个待融合的语音文本进行融合,以融合后的语音文本来匹配控制汽车的操作指令,提高了语音识别的准确性,提高了人机交互的效率和体验,使机器能更好地理解人类语言。
在一个实施例中,基于kaldi训练的语音识别模型可为自定义配置cd-dnn-hmm神经网络结构训练的识别模型。实质上,语音识别的问题可以看成是使得概率p(w|o)最大的语句:
上式公式中,p(w)为语言模型(languagemodel,lm)的概率,即词序列w在自然语言中发生的概率;p(o|w)是声学模型(acousticmode,am)的概率;o是语言信号提取出的声学特征向量序列,对于任一词序列而言,p(o)为一个定值;p(w|o)为对应词序列的概率。用维特比算法(viterbi)解码的方式对其进行展开:
上式公式中,p(ot|qt)为似然概率,t为状态的时序标签;p(ot|qt)可通过贝叶斯定理计算如下:
上式公式中,p(qt|ot)是从dnn中估计的状态后验概率;p(ot)是独立于词序列的固定不变值;p(qt)是训练集中估计的各状态的先验概率,是训练过程中训练出来的,即把观测值(特征向量)状态上对齐,跟某个状态对齐的观测值的个数占比即为该状态的先验概率,因此,通过上述公式即可实现对cd-dnn-hmm中的神经网络结构的解码和训练,从而获得基于kaldi训练的语音识别模型。
在一个实施例中,所述基于cmusphinx训练的语音识别模型的获取步骤,包括:在服务器配置cmusphinx工具包,包括语言模型训练工具和声学模型训练工具;结合语音语料库训练声学模型;在原有语音模型基础上结合车载领域文本,训练语言模型;指定训练好的声学模型、语言模型和字典文件,传入待识别语音信号,即可获得输出的待融合的语音文本。其中,所述字典文件时指包含要训练的全部词语以及与该词语相应的音素集,即字到语音单元的映射结合,例如:天窗tianchuang。
在一个实施例中,由于在调用多个语音识别服务商接口时,有些语音识别服务商在某些时间段会因网络阻塞,服务不能访问等因素导致返回文本信息失败,因此,为了提高识别的效率,设置获取待融合的语音文本的预设时间,将在预设时间内返回的文本作为待融合的语音文本,在预设时间之后返回的文本则放弃不使用。或者,设置获取待融合的语音文本的预设数量,根据文本的获得时间顺序,在预设数量内的文本作为待融合的语音文本,超出预设数量范围内的文本则放弃不使用。
在一个实施例中,所述多源文本融合模型包括两个循环神经网络(recurrentneuralnetwork,rnn),其中一个循环神经网络用于将多个待融合的语音文本作为输入,并输出一词向量,此过程为编码过程,另一个循环神经网络用于将词向量解码为句子即为融合后的语音文本,此过程为解码过程。在编码过程中rnn的最终隐藏状态包含了所有输入序列的信息并输出一个词向量;在解码过程中的rnn会获取这个词向量,将其作为起始状态并输出一个融合后的句子。训练该神经网络模型使用包含源句子的文件和包含目标句子的文件,通过组合,将包含源句子的文件与目标句子的文件组成源句子-目标句子对。特别地,为提高训练模型训练的效果,可以增加全部训练数据的训练次数,且当模型在基于nist评分值在达到理想阈值时,表明模型训练完成。通过调用多源文本融合模型将多个所述待融合的语音文本进行融合,获得融合后的语音文本。
请参阅图3,在一个实施例中,为提高操作指令的匹配精度,所述根据所述汽车的标识信息以及所述语音文本,在汽车指令数据库中获得匹配的汽车操作指令的步骤,包括:
步骤s41:根据所述汽车的标识信息,从汽车指令数据库中查询获得对应汽车的指令文字集以及操作指令集。
其中,所述汽车指令数据库可包括各汽车的品牌型号、各汽车的车辆编号、各汽车对应的指令文字集以及操作指令集。所述汽车指令数据库可为mysql、mongo或redis数据库。根据所述汽车的标识信息如车辆品牌型号和车辆编号,可以获得该车辆的指令文字集以及对应的操作指令集。
步骤s42:将所述语音文本和所述指令文字集中的各指令文字分别进行语义角色标注。
其中,将所述语音文本和所述指令文字集中的各指令文字分别进行语义角色标注,进而可将标注句型之间的相似度转化为动词和角色标签相同的语义搭配之间的相似度。例如:语音文本内容为“帮我[施事者]打开[动词]天窗[受事者]”,而指令数据库的指令文字中的“打开[动词]音乐[受事者]”。前者(打开,天窗)与后者(打开,音乐)可以组成一个语义配对计算相似度。
步骤s43:计算语义角色标注后的语音文本与语义角色标注后的各指令文字的语义相似度、词形相似度和句长相似度。
在一个实施例中,所述语义相似度的计算方式为:
其中,t1和t2分别表示语义角色标注后的语音文本与语义角色标注后的指令文字;m,n分别表示t1中标注的语义角色的数量和t2中标注的语义角色的数量;(i,j)∈{(p,q)|rq,rq∈r(f1)∩r(f2),1≤p≤m,1≤q≤n};v1,v2分别表示t1中的动词和t2中的动词;similarity(v1,v1)为动词v1和动词v2的词语相似度,其中词语相似度similarity(v1,v1)的计算方法包括但不限于基于词向量方法或者hownet的方法;具体的,基于词向量方法是借助word2vec在给定语料训练出模型的基础上,将词语表示成向量的形式,并计算词语之间的余弦相似度,即对于任意两个词语,用词向量表示v1=(x1,x2,…xn)和v2=(y1,y2,…yn),其中,n表示向量维度;则这两个词语之间的余弦相似度的计算方式为:
similarity(ei,ej)为t1中的论元ei和t2中的论元ej之间的相似度,其中论元是指带有论旨角色的名词短语,例如“打电话给张三”,则“张三”就是论元;“今天我去外婆家”,则“我”和“外婆家”就是论元;α为谓词相似度在全句中所占的权重。α可根据实际情况调节其权重;在本实施例中,α可以取值为0.5。
当t1和t2中的论元数量均小于2个,即论元ei和论元ej中的词语数量均小于2个时,similarity(ei,ej)的计算方法与similarity(v1,v1)相同;而t1和t2中有一个论元数量等于或大于2个,即论元ei和论元ej中有一个的词语数量等于或大于2个时,则将论元ei和论元ej看作两个词集合,分别包含m和n个元素。设论元ei中第m个词和论元ej中第n个词之间的相似度为smn,可以得到相似度矩阵:
则论元ei和论元ej的相似度的计算方式为:
上述公式中,
在一个实施例中,语音文本中的动词v也可能是单个,也可能是多个。当动词v是单个词时,即语音文本中指令只包含一个操作信息,按原式计算;当动词v是一个1*k维有序数组时,遍历数组动词v中每个元素,依次计算其与各指令文字的相似度。
在一个实施例中,所述词形相似度的计算方式为:
上述公式中,len(t1)和len(t2)分别为t1和t2中词的数量,sameword为t1和t2中相同词的个数。
在一个实施例中,所述句长相似度的计算方式为:
上述公式中,len(t1)和len(t2)分别为t1和t2中词的数量。
步骤s44:将所述语义相似度、词形相似度和句长相似度按照预设的权重进行累加,获得最高的累加值对应的指令文字或者按累加值降序排列时在预设范围内的多个累加值对应的指令文字,并将所述指令文字对应的操作指令作为匹配的汽车操作指令。
在一个实施例中,所述语义相似度、词形相似度和句长相似度按照预设的权重进行累加的计算方式为:
multisimilarity(t1,t2)=γ1similarity(t1,t2)+γ2wordsimilarity(t1,t2)+γ3lensimilarity(t1,t2)
上述公式中,γi权重,i∈[1,2,3]且
在一个实施例中,语音文本中的动词v为一个时,则获得最高的累加值对应的指令文字,并将所述指令文字对应的操作指令作为匹配的汽车操作指令。当语音文本中的动词v为多个时,则根据动词个数设置预设范围,获取按累加值降序排列时在预设范围内的多个累加值对应的指令文字,并将所述指令文字对应的操作指令作为匹配的汽车操作指令。例如设置与动词v个数一样的数量范围,如动词v个数为3,则预设范围也为3,再获取按累加值降序排列时在排名预设范围内即排列前3位的3个累加值对应的指令文字,并将这些指令文字对应的操作指令作为匹配的汽车操作指令。当最高累加值低于指定的阈值时,则返回语音指令不正确的信息。
请参阅图4,本发明还提供一种车载语音分析系统1,包括:
语音获取模块11,用于获取待识别的车载语音信号以及汽车的标识信息。
语音识别模块12,用于根据待识别的车载语音信号,调用基于kaldi训练的语音识别模型、基于cmusphinx训练的语音识别模型以及多个语音识别服务商接口,获得多个待融合的语音文本。
文本融合模块13,用于通过多源文本融合模型将多个所述待融合的语音文本进行融合,获得融合后的语音文本。
匹配模块14,用于根据所述汽车的标识信息以及所述语音文本,在汽车指令数据库中获得匹配的汽车操作指令。
本发明通过调用多个语音识别服务商接口、基于kaldi训练的语音识别模型、以及基于cmusphinx训练的语音识别模型,获得多个待融合的语音文本,再将获得的多个待融合的语音文本进行融合,以融合后的语音文本来匹配控制汽车的操作指令,提高了语音识别的准确性,提高了人机交互的效率和体验,使机器能更好地理解人类语言。
在一个实施例中,所述多源文本融合模型包括两个循环神经网络(recurrentneuralnetwork,rnn),其中一个循环神经网络用于将多个待融合的语音文本作为输入,并输出一词向量,此过程为编码过程,另一个循环神经网络用于将词向量解码为句子即为融合后的语音文本,此过程为解码过程。在编码过程中rnn的最终隐藏状态包含了所有输入序列的信息并输出一个词向量;在解码过程中的rnn会获取这个词向量,将其作为起始状态并输出一个融合后的句子。训练该神经网络模型使用包含源句子的文件和包含目标句子的文件,通过组合,将包含源句子的文件与目标句子的文件组成源句子-目标句子对。特别地,为提高训练模型训练的效果,可以增加全部训练数据的训练次数,且当模型在基于nist评分值在达到理想阈值时,表明模型训练完成。通过调用多源文本融合模型将多个所述待融合的语音文本进行融合,获得融合后的语音文本。
请参阅图5,在一个实施例中,所述匹配模块14,具体包括:
查询模块141,用于根据所述汽车的标识信息,从汽车指令数据库中查询获得对应汽车的指令文字集以及操作指令集。
语义角色标注模块142,用于将所述语音文本和所述指令文字集中的各指令文字分别进行语义角色标注。
计算模块143,用于计算语义角色标注后的语音文本与语义角色标注后的各指令文字的语义相似度、词形相似度和句长相似度。
指令获取模块144,用于将所述语义相似度、词形相似度和句长相似度按照预设的权重进行累加,获得最高的累加值对应的指令文字或者按累加值降序排列时在预设范围内的多个累加值对应的指令文字,并将所述指令文字对应的操作指令作为匹配的汽车操作指令。
在一个实施例中,所述语义相似度的计算方式为:
其中,t1和t2分别表示语义角色标注后的语音文本与语义角色标注后的指令文字;m,n分别表示t1中标注的语义角色的数量和t2中标注的语义角色的数量;(i,j)∈{(p,q)|rq,rq∈r(f1)∩r(f2),1≤p≤m,1≤q≤n};v1,v2分别表示t1中的动词和t2中的动词;similarity(v1,v1)为动词v1和动词v2的词语相似度,其中词语相似度similarity(v1,v1)的计算方法包括但不限于基于词向量方法或者hownet的方法;具体的,基于词向量方法是借助word2vec在给定语料训练出模型的基础上,将词语表示成向量的形式,并计算词语之间的余弦相似度,即对于任意两个词语,用词向量表示v1=(x1,x2,…xn)和v2=(y1,y2,…yn),其中,n表示向量维度;则这两个词语之间的余弦相似度的计算方式为:
similarity(ei,ej)为t1中的论元ei和t2中的论元ej之间的相似度,其中论元是指带有论旨角色的名词短语,例如“打电话给张三”,则“张三”就是论元;“今天我去外婆家”,则“我”和“外婆家”就是论元;α为谓词相似度在全句中所占的权重。α可根据实际情况调节其权重;在本实施例中,α可以取值为0.5。
当t1和t2中的论元数量均小于2个,即论元ei和论元ej中的词语数量均小于2个时,similarity(ei,ej)的计算方法与similarity(v1,v1)相同;而t1和t2中有一个论元数量等于或大于2个,即论元ei和论元ej中有一个的词语数量等于或大于2个时,则将论元ei和论元ej看作两个词集合,分别包含m和n个元素。设论元ei中第m个词和论元ej中第n个词之间的相似度为smn,可以得到相似度矩阵:
则论元ei和论元ej的相似度的计算方式为:
上述公式中,
在一个实施例中,语音文本中的动词v也可能是单个,也可能是多个。当动词v是单个词时,即语音文本中指令只包含一个操作信息,按原式计算;当动词v是一个1*k维有序数组时,遍历数组动词v中每个元素,依次计算其与各指令文字的相似度。
在一个实施例中,所述词形相似度的计算方式为:
上述公式中,len(t1)和len(t2)分别为t1和t2中词的数量,sameword为t1和t2中相同词的个数。
在一个实施例中,所述句长相似度的计算方式为:
上述公式中,len(t1)和len(t2)分别为t1和t2中词的数量。
在一个实施例中,所述语义相似度、词形相似度和句长相似度按照预设的权重进行累加的计算方式为:
multisimilarity(t1,t2)=γ1similarity(t1,t2)+γ2wordsimilarity(t1,t2)+γ3lensimilarity(t1,t2)
上述公式中,γi权重,i∈[1,2,3]且
在一个实施例中,语音文本中的动词v为一个时,则获得最高的累加值对应的指令文字,并将所述指令文字对应的操作指令作为匹配的汽车操作指令。当语音文本中的动词v为多个时,则根据动词个数设置预设范围,获取按累加值降序排列时在预设范围内的多个累加值对应的指令文字,并将所述指令文字对应的操作指令作为匹配的汽车操作指令。例如设置与动词v个数一样的数量范围,如动词v个数为3,则预设范围也为3,再获取按累加值降序排列时在排名预设范围内即排列前3位的3个累加值对应的指令文字,并将这些指令文字对应的操作指令作为匹配的汽车操作指令。当最高累加值低于指定的阈值时,则返回语音指令不正确的信息。
本发明还提供一种计算机可读存储介质,其上储存有计算机程序,该计算机程序被处理器执行时实现如上述任意一项所述的车载语音分析方法的步骤。
本发明可采用在一个或多个其中包含有程序代码的存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。计算机可读储存介质包括永久性和非永久性、可移动和非可移动媒体,可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括但不限于:相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。
本发明还提供一种计算机设备,包括储存器、处理器以及储存在所述储存器中并可被所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如上述任意一项所述的车载语音分析方法的步骤。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!