一种语音情感识别方法及系统与流程
本发明涉及语音识别领域,特别是涉及一种语音情感识别方法及系统。
背景技术:
语音情感识别作为人工智能、心理学、计算科学等多学科交叉的新兴领域,进入21世纪后,随着人工智能领域的快速发展,语音情感识别的需求越来越大,所以分析、研究语音中包含的情感特征,判断说话人喜怒哀乐的情绪有非常重要的影响。
传统的语音情感识别领域的研究偏向于分析语音的声学统计特征,其中,情感语音数据库中的语音条目较少,语义也较简单情感语音数据库。现有技术中,用于情感识别的声学特征可分为韵律学特征、基于谱的特征,音质特征。进入21世纪,随着人工智能领域的快速发展,语音情感识别的需求变大,在情感特征的提取方面,最早有启发式算法,包括顺序向后选择、顺序向前选择、优先选择,线性特征参数的提取的算法也被应用,包括主成分分析法、线性判别分析法线性判别分析法,由于现有技术中的分析方法的分析结果的准确率低,提出了一种利用深度信念网络来自动提取特征的方法,并且现有技术中采用过线性判别分类的方法,以及k最近邻法和支持向量机的方法,采用最大似然贝叶斯分类法、核回归和k最近邻法三种分类器,取得了60%-65%的识别率。
现有技术中采用的分类方法以及分析方法的进行语音情感的识别率较低。
技术实现要素:
本发明的目的是提供一种能够提高语音情感识别的识别率的语音情感识别方法及系统。
为实现上述目的,本发明提供了如下方案:
一种语音情感识别方法,所述识别方法包括:
获取语音信号;
预处理所述语音信号,获得预处理语音信号;
计算所述预处理语音信号对应的语谱图;
计算多个不同语段长度的所述预处理语音信号的情感识别率,将所述情感识别率最高对应的语段长度确定为最佳语段长度;
根据所述最佳语段长度对应的语谱图提取所述语音信号的声学特征;
将所述声学特征采用卷积神经网络分类识别所述语音信号的情感。
可选的,所述预处理所述语音信号,获得预处理语音信号具体包括:
将所述语音信号经过数字化处理,获得脉冲语音信号;
将所述脉冲语音信号采样处理,获得离散时间和连续幅值的脉冲语音信号;
将所述离散时间和连续幅值的脉冲语音信号量化处理,获得离散时间和离散幅值的脉冲语音信号;
将所述离散时间和离散幅值的脉冲语音信号进行预加重处理,获得预加重语音信号;
将所述预加重语音信号进行分帧加窗处理,获得预处理语音信号。
可选的,所述计算所述预处理语音信号对应的语谱图具体包括:
获取所述预处理语音信号的采样频率fs、采样数据序列sg和语段长度;
根据所述语段长度和窗函数的窗长nnew将所述预处理语音信号分为n段,获得n段语音信号;
根据所述语段长度和所述n段语音信号计算帧移nsfgtft;
对第i帧语音信号si加窗处理,获得加窗语音信号s′i,
s′i=si×hanning(nnew),其中i的取值为1,2,......,n;
将所述加窗语音信号s′i进行傅里叶变换,获得傅里叶变换语音信号zi;
根据所述傅里叶变换语音信号zi的相位θi计算所述第i帧语音信号si的能量密度函数|zi|2;将所述窗函数进行nsfgtft个帧移,获得第i+1帧语音信号si+1的能量密度函数|zi+1|2;
获得一个[nnew/2]+1行、n列的矩阵r;
将所述矩阵r映射为灰度图,获得所述计算所述预处理语音信号对应的语谱图。
可选的,所述将所述声学特征采用卷积神经网络分类识别所述语音信号的情感具体包括:
所述语谱图采用卷积神经网络的卷积层处理,三维的所述语谱图转换为n个二维特征;
其中,bj为能够训练的偏差函数,kij为卷积核,xi表示输入的第i段语谱图;yi表示输出的第i段语谱图对应的二维特征;
将所述输出的第i段语谱图对应的二维特征yi通过池化层处理,获得低分辨率声学特征y′i;
所述卷积层与所述池化层之间设置有全连接层,所述全连接层中有激活函数,所述全连接层用于所述卷积层与所述池化层之间的数据传输。
一种语音情感识别系统,所述识别系统包括:
语音信号获取模块,用于获取语音信号;
预处理模块,用于预处理所述语音信号,获得预处理语音信号;
语谱图计算模块,用于计算所述预处理语音信号对应的语谱图;
最佳语段长度确定模块,用于计算多个不同语段长度的所述预处理语音信号的情感识别率,将所述情感识别率最高对应的语段长度确定为最佳语段长度;
声学特征提取模块,用于根据所述最佳语段长度对应的语谱图提取所述语音信号的声学特征;
卷积神经网络模块,用于将所述声学特征采用卷积神经网络分类识别所述语音信号的情感。
可选的,所述预处理模块具体包括:
数字化处理单元,用于将所述语音信号经过数字化处理,获得脉冲语音信号;
采样处理单元,用于将所述脉冲语音信号采样处理,获得离散时间和连续幅值的脉冲语音信号;
量化处理单元,用于将所述离散时间和连续幅值的脉冲语音信号量化处理,获得离散时间和离散幅值的脉冲语音信号;
预加重处理单元,用于将所述离散时间和离散幅值的脉冲语音信号进行预加重处理,获得预加重语音信号;
分帧加窗单元,用于将所述预加重语音信号进行分帧加窗处理,获得预处理语音信号。
可选的,所述语谱图计算模块具体包括:
预处理语音信号信息获取单元,用于获取所述预处理语音信号的采样频率fs、采样数据序列sg和语段长度;
预处理语音信号分段单元,用于根据所述语段长度和窗函数的窗长nnew将所述预处理语音信号分为n段,获得n段语音信号;
帧移计算单元,用于根据所述语段长度和所述n段语音信号计算帧移nsfgtft;
加窗处理单元,用于对第i帧语音信号si加窗处理,获得加窗语音信号s′i,
s′i=si×hanning(nnew),其中i的取值为1,2,......,n;
傅里叶变换单元,用于将所述加窗语音信号s′i进行傅里叶变换,获得傅里叶变换语音信号zi;
语谱图获取单元,用于根据所述傅里叶变换语音信号zi的相位θi计算所述第i帧语音信号si的能量密度函数|zi|2;将所述窗函数进行nsfgtft个帧移,获得第i+1帧语音信号si+1的能量密度函数|zi+1|2;
获得一个[nnew/2]+1行、n列的矩阵r;
将所述矩阵r映射为灰度图,获得所述计算所述预处理语音信号对应的语谱图。
可选的,所述卷积神经网络模块具体包括:
卷积层单元,用于所述语谱图采用卷积神经网络的卷积层处理,三维的所述语谱图转换为n个二维特征;
池化层单元,用于将所述输出的第i段语谱图对应的二维特征yi通过池化层处理,获得低分辨率声学特征y′i;
全连接层单元,用于所述卷积层与所述池化层之间设置有全连接层,所述全连接层中有激活函数,所述全连接层用于所述卷积层与所述池化层之间的数据传输。
根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明公开了一种语音情感识别方法及系统。所述识别方法为获取语音信号;预处理所述语音信号,获得预处理语音信号;计算所述预处理语音信号对应的语谱图;计算多个不同语段长度的所述预处理语音信号的情感识别率,将所述情感识别率最高对应的语段长度确定为最佳语段长度;根据所述最佳语段长度对应的语谱图提取所述语音信号的声学特征;将所述声学特征采用卷积神经网络分类识别所述语音信号的情感。采用基于语谱图和卷积神经网络的语音情感识别方法提升了语音情感识别率,基于最佳语段长度的语谱图的特征和卷积神经网络的识别方法也进一步提高了语音情感的识别率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
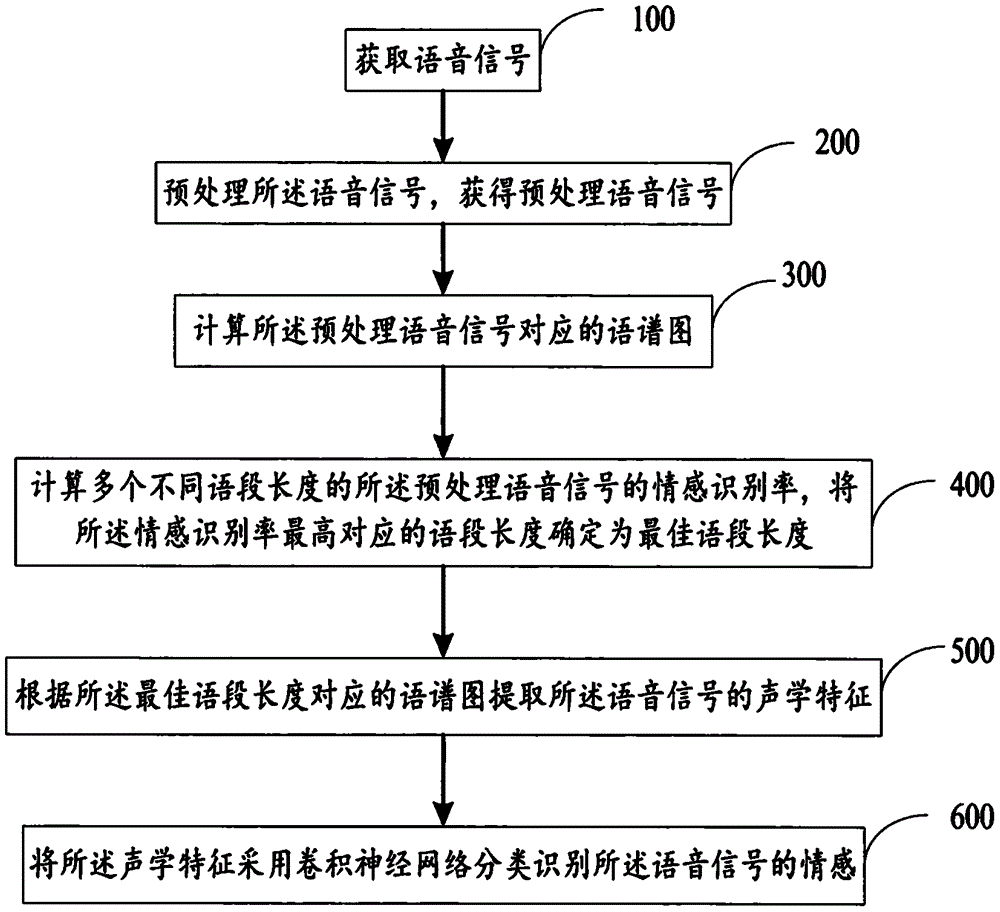
图1为本发明提供的语音情感识别方法的流程图;
图2为本发明提供的语音情感识别系统的组成框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种能够提高语音情感识别的识别率的语音情感识别方法及系统。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,一种语音情感识别方法,所述识别方法包括:
步骤100:获取语音信号;
步骤200:预处理所述语音信号,获得预处理语音信号;
步骤300:计算所述预处理语音信号对应的语谱图;
步骤400:计算多个不同语段长度的所述预处理语音信号的情感识别率,将所述情感识别率最高对应的语段长度确定为最佳语段长度;
步骤500:根据所述最佳语段长度对应的语谱图提取所述语音信号的声学特征;
步骤600:将所述声学特征采用卷积神经网络分类识别所述语音信号的情感。
所述步骤200:预处理所述语音信号,获得预处理语音信号具体包括:
将所述语音信号经过数字化处理,获得脉冲语音信号;
将所述脉冲语音信号采样处理,获得离散时间和连续幅值的脉冲语音信号;
将所述离散时间和连续幅值的脉冲语音信号量化处理,获得离散时间和离散幅值的脉冲语音信号;
将所述离散时间和离散幅值的脉冲语音信号进行预加重处理,获得预加重语音信号;
将所述预加重语音信号进行分帧加窗处理,获得预处理语音信号。
所述步骤300:计算所述预处理语音信号对应的语谱图具体包括:
获取所述预处理语音信号的采样频率fs、采样数据序列sg和语段长度;
根据所述语段长度和窗函数的窗长nnew将所述预处理语音信号分为n段,获得n段语音信号;
根据所述语段长度和所述n段语音信号计算帧移nsfgtft;
对第i帧语音信号si加窗处理,获得加窗语音信号s′i,
s′i=si×hanning(nnew),其中i的取值为1,2,......,n;
将所述加窗语音信号s′i进行傅里叶变换,获得傅里叶变换语音信号zi;
根据所述傅里叶变换语音信号zi的相位θi计算所述第i帧语音信号si的能量密度函数|zi|2;将所述窗函数进行nsfgtft个帧移,获得第i+1帧语音信号si+1的能量密度函数|zi+1|2;
获得一个[nnew/2]+1行、n列的矩阵r;
将所述矩阵r映射为灰度图,获得所述计算所述预处理语音信号对应的语谱图,通过权值共享的滤波器能够减少需要训练的系数的数量。
所述步骤600:将所述声学特征采用卷积神经网络分类识别所述语音信号的情感具体包括:
所述语谱图采用卷积神经网络的卷积层处理,三维的所述语谱图转换为n个二维特征;
其中,bj为能够训练的偏差函数,kij为卷积核,xi表示输入的第i段语谱图;yi表示输出的第i段语谱图对应的二维特征;
将所述输出的第i段语谱图对应的二维特征yi通过池化层处理,获得低分辨率声学特征y′i;
所述卷积层与所述池化层之间设置有全连接层,所述全连接层中有激活函数,所述全连接层用于所述卷积层与所述池化层之间的数据传输。
如图2所示,一种语音情感识别系统,所述识别系统包括:
语音信号获取模块1,用于获取语音信号;
预处理模块2,用于预处理所述语音信号,获得预处理语音信号;
语谱图计算模块3,用于计算所述预处理语音信号对应的语谱图;
最佳语段长度确定模块4,用于计算多个不同语段长度的所述预处理语音信号的情感识别率,将所述情感识别率最高对应的语段长度确定为最佳语段长度;
声学特征提取模块5,用于根据所述最佳语段长度对应的语谱图提取所述语音信号的声学特征;
卷积神经网络模块6,用于将所述声学特征采用卷积神经网络分类识别所述语音信号的情感。
所述预处理模块2具体包括:
数字化处理单元,用于将所述语音信号经过数字化处理,获得脉冲语音信号;
采样处理单元,用于将所述脉冲语音信号采样处理,获得离散时间和连续幅值的脉冲语音信号;
量化处理单元,用于将所述离散时间和连续幅值的脉冲语音信号量化处理,获得离散时间和离散幅值的脉冲语音信号;
预加重处理单元,用于将所述离散时间和离散幅值的脉冲语音信号进行预加重处理,获得预加重语音信号;
分帧加窗单元,用于将所述预加重语音信号进行分帧加窗处理,获得预处理语音信号。
所述语谱图计算模块3具体包括:
预处理语音信号信息获取单元,用于获取所述预处理语音信号的采样频率fs、采样数据序列sg和语段长度;
预处理语音信号分段单元,用于根据所述语段长度和窗函数的窗长nnew将所述预处理语音信号分为n段,获得n段语音信号;
帧移计算单元,用于根据所述语段长度和所述n段语音信号计算帧移nsfgtft;
加窗处理单元,用于对第i帧语音信号si加窗处理,获得加窗语音信号s′i,
s′i=si×hanning(nnew),其中i的取值为1,2,......,n;
傅里叶变换单元,用于将所述加窗语音信号s′i进行傅里叶变换,获得傅里叶变换语音信号zi;
语谱图获取单元,用于根据所述傅里叶变换语音信号zi的相位θi计算所述第i帧语音信号si的能量密度函数|zi|2;将所述窗函数进行nsfgtft个帧移,获得第i+1帧语音信号si+1的能量密度函数|zi+1|2;
获得一个[nnew/2]+1行、n列的矩阵r;
将所述矩阵r映射为灰度图,获得所述计算所述预处理语音信号对应的语谱图。
所述卷积神经网络模块6具体包括:
卷积层单元,用于所述语谱图采用卷积神经网络的卷积层处理,三维的所述语谱图转换为n个二维特征;
池化层单元,用于将所述输出的第i段语谱图对应的二维特征yi通过池化层处理,获得低分辨率声学特征y′i;
全连接层单元,用于所述卷积层与所述池化层之间设置有全连接层,所述全连接层中有激活函数,所述全连接层用于所述卷积层与所述池化层之间的数据传输。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!