一种改进的多个病理单元音识别方法与流程
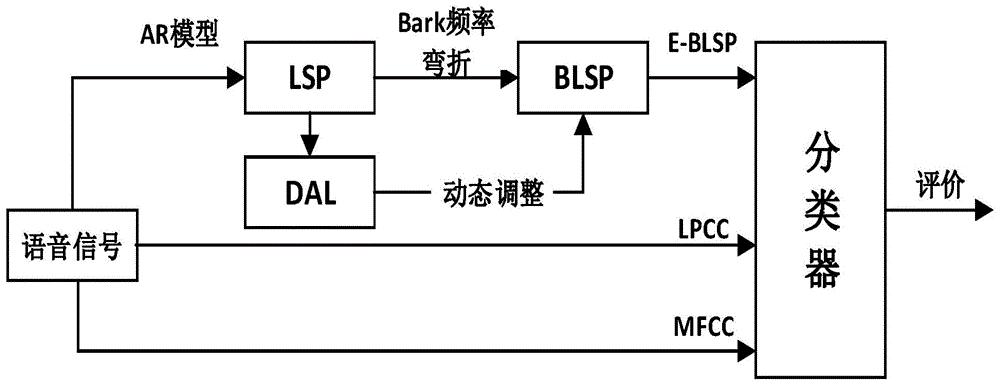
本发明涉及一种病理单元音识别方法。特别是涉及一种改进的多个病理单元音识别方法.
背景技术:
语音是语言传递最直接的方式,因此嗓音音质好坏直接影响着人们日常的沟通效率。据统计在美国大约有750万人患有嗓音疾病,其中教学专业人士的嗓音患病率为57.7%,非教学专业为28.8%。此外,在英国,每年大约有2200人被诊断出患有喉癌。嗓音的含混不清会极大地降低人们的生活质量,因此对病理嗓音进行识别继而修复显得尤为重要。
嗓音疾病可以通过药物和物理方式治疗,但治疗的不彻底性会对患病语者的表达产生影响,因此采用非侵入性修复方式对病理嗓音进行识别修复成为学者们研究的关键。单元音嗓音的识别修复是复杂字词句的基础。对于多个单元音嗓音识别研究,目前研究对象都是基于正常嗓音,常用到的特征参数有线性预测倒谱参数(linearpredictioncepstrumcoefficient,lpcc)、mel频率倒谱参数(mel-frequencycepstralcoefficients,mfcc)和共振峰等。然而针对病理嗓音的识别工作大都着眼于病理嗓音和正常嗓音的二分类,由于大部分声学特征参数对/a/音的识别率几乎都高于其他元音,因此国内外一般选择病理单元音/a/作为实验样本,通过提取嗓音样本的特征参数并将其输入到不同分类网络进行病理嗓音的识别。常用的识别特征有基频扰动、振幅扰动等长时特征、mpeg-7和多向回归mdr(multidirectionalregression,mdr)等回归特征等。但是应用于多个正常单元音识别的特征(lpcc、mfcc)对多个病理单元音的识别效果较差。
技术实现要素:
本发明所要解决的技术问题是,提供一种能够进一步提高病理嗓音识别率的改进的多个病理单元音识别方法。
本发明所采用的技术方案是:一种改进的多个病理单元音识别方法,包括如下步骤:
1)计算输入语音信号的线谱对参数;
2)计算输入语音信号的相邻差分线谱对参数;
3)对输入语音信号的线谱对参数进行频率弯折,得到输入语音信号的巴克线谱对参数;
4)对输入语音信号的巴克线谱对参数进行特征增强得到增强型巴克线谱对参数;
5)将输入语音信号的增强型巴克线谱对参数输入到深度神经网络分类器中进行多个病理单元音的识别。
步骤1)包括:
(1.1)进行信号预处理,包括去直流处理和分帧处理;
(1.2)对于每帧语音信号,根据设置的模型阶数p=12采用莱文逊-杜宾自相关算法计算12阶线性预测系数ai;
(1.3)由(1.2)计算得到的线性预测系数ai计算得到线性预测逆滤波器系统函数,如下:
式中,a(z)表示线性预测逆滤波器系统函数;p表示模型阶数;ai表示线性预测系数;
(1.4)计算线性预测逆滤波器系统函数a(z)的p+1阶对称和反对称多项式:
p(z)=a(z)+z-(p+1)a(z-1)(2)
式中,p(z)表示a(z)的p+1阶对称多项式,a(z)表示线性预测逆滤波器系统函数;p表示模型阶数;
q(z)=a(z)-z-(p+1)a(z-1)(3)
式中,q(z)表示a(z)的p+1阶反对称多项式,a(z)表示线性预测逆滤波器系统函数;p表示模型阶数;
(1.5)由p(z)和q(z)计算12阶输入语音信号的线谱对参数:
式中,h(ejω)是线性预测频谱幅值,ejω是z的频率表示形式,p(ejω)是a(ejω)的p+1阶对称多项式,q(ejω)是a(ejω)的p+1阶反对称多项式,cosθi和cosωi是lsp系数在余弦域的表示,θi和ωi是输入语音信号的线谱对系数对应的线谱频率,π是累乘符号。
步骤2)是根据如下公式计算:
dali=li+1-lii=1,2,...m(m<n)(5)
式中,dali是第i阶相邻差分线谱对参数,li+1第i+1阶线谱对参数,li第i阶线谱对参数,m是相邻差分线谱对参数最大阶数,n是线谱对参数最大阶数。
步骤3)所述的频率弯折是采用如下公式:
bark=26.81/(1+(1960/f))-0.53(6)
式中,bark表示bark频率;f表示线性频率。
步骤4)是采取双向迭代的方式对第j阶巴克线谱对参数进行调整,j=2,...,n-1,调整后直接更新原来的巴克线谱对参数,并将调整后的第j阶巴克线谱对参数用到调整下一阶的巴克线谱对参数中,设定当前帧的巴克线谱对参数为{b1,b2,...bn}n,n是巴克线谱对的阶数,当前帧的相邻差分线谱对参数的系数为bi+1-bi,i=1,2,...,n-1;具体迭代公式如下:
ci=η(bi+1-bi),η<1,i=2,3,...,n-1(8)
(1)前向迭代:从j=2到j=n-1,前向调整第j阶巴克线谱对参数;
(2)后向迭代:从j=n-1到j=2,后向调整第j阶巴克线谱对参数;
(3)取平均:对前向迭代和后向迭代得到的巴克线谱对参数取平均得到增强型巴克线谱对参数;
式中,η控制共振峰增强的程度,η越小,增强效果越明显。
步骤5)是首先从svd病理嗓音数据库中的每种单元音数据集中随机选取75%作训练集,25%作测试集,保证在分类网络训练和测试阶段每类嗓音数据满足平均分布,然后将蠕动息肉病理嗓音/a/、/i/、/u/和正常嗓音/a/、/i/、/u/这6种单元音嗓音的12阶增强型巴克线谱对参数输入到深度神经网络中进行识别,网络参数设置为:2层隐含层,每层100个神经元,选择relu函数作为激活函数,在识别模型最后一层选用softmax函数将神经网络的输出变成一个概率分布,进而优化分类结果。
本发明的一种改进的多个病理单元音识别方法,具有如下有益效果:
1)本发明保证改进的多个病理单元音识别方法较传统的mfcc、lpcc特征有更好的识别率,提出了一种适用于多个病理单元音识别的广泛性特征e-blsp。新提出的e-blsp特征实现了对正常/a/、/i/、/u/和病理/a/、/i/、/u/6种单元音的高识别率;
2)本发明提出的e-blsp特征对病理/i/音的识别率高于病理/a/音,而传统的病理嗓音识别大都基于单元音/a/,这为病理嗓音的识别诊断提高了新的思路,也为后续对单元音及更复杂的字词句的嗓音修复提供了研究基础。
附图说明
图1是本发明一种改进的多个病理单元音识别方法的结构示意;
图2a是正常单元音/a/的11阶dal参数盒图;
图2b是病理单元音/a/的11阶dal参数盒图;
图2c是正常单元音/i/的11阶dal参数盒图;
图2d是病理单元音/i/的11阶dal参数盒图;
图2e是正常单元音/u/的11阶dal参数盒图;
图2f是病理单元音/u/的11阶dal参数盒图;
图3a是本发明实施例12阶lsp参数的示意图;
图3b是本发明实施例12阶blsp参数的示意图;
图4a是本发明实施例12阶blsp参数的三维频谱示意图;
图4b是本发明实施例12阶e-blsp参数的三维频谱示意图。
具体实施方式
下面结合实施例和附图对本发明的一种改进的多个病理单元音识别方法做出详细说明。
如图1所示,本发明的一种改进的多个病理单元音识别方法,包括如下步骤:
1)计算输入语音信号的线谱对(linespectrumpair,lsp)参数;包括:
(1.1)进行信号预处理,包括去直流处理和分帧处理;
(1.2)对于每帧语音信号,根据设置的模型阶数p=12采用莱文逊-杜宾自相关算法计算12阶线性预测系数ai;
(1.3)由(1.2)计算得到的线性预测系数ai计算得到线性预测逆滤波器系统函数,如下:
式中,a(z)表示线性预测逆滤波器系统函数;p表示模型阶数;ai表示线性预测系数;
(1.4)计算线性预测逆滤波器系统函数a(z)的p+1阶对称和反对称多项式:
p(z)=a(z)+z-(p+1)a(z-1)(2)
式中,p(z)表示a(z)的p+1阶对称多项式,a(z)表示线性预测逆滤波器系统函数;p表示模型阶数;
q(z)=a(z)-z-(p+1)a(z-1)(3)
式中,q(z)表示a(z)的p+1阶反对称多项式,a(z)表示线性预测逆滤波器系统函数;p表示模型阶数;
(1.5)由p(z)和q(z)计算12阶输入语音信号的线谱对参数:
式中,h(ejω)是线性预测频谱幅值,ejω是z的频率表示形式,p(ejω)是a(ejω)的p+1阶对称多项式,q(ejω)是a(ejω)的p+1阶反对称多项式,cosθi和cosωi是lsp系数在余弦域的表示,θi和ωi是输入语音信号的线谱对系数对应的线谱频率(linearspectrumfrequency,lsf),π是累乘符号。
2)计算输入语音信号的相邻差分线谱对(differenceofadjacentlsp,dal)参数;
是根据如下公式计算:
dali=li+1-lii=1,2,...m(m<n)(5)
式中,dali是第i阶相邻差分线谱对参数,li+1第i+1阶线谱对参数,li第i阶线谱对参数,m是相邻差分线谱对参数最大阶数,n是线谱对参数最大阶数。
3)对输入语音信号的线谱对参数进行频率弯折,得到输入语音信号的巴克线谱对(barklinespectrumpair,blsp)参数;
所述的频率弯折是采用如下公式:
bark=26.81/(1+(1960/f))-0.53(6)
式中,bark表示bark频率;f表示线性频率。
4)对输入语音信号的巴克线谱对参数进行特征增强得到增强型巴克线谱对(enhanced-barklinespectrumpair,e-blsp)参数;是采取双向迭代的方式对第j阶巴克线谱对参数进行调整,j=2,...,n-1,调整后直接更新原来的巴克线谱对参数,并将调整后的第j阶巴克线谱对参数用到调整下一阶的巴克线谱对参数中,设定当前帧的巴克线谱对参数为{b1,b2,...bn}n,n是巴克线谱对的阶数,当前帧的相邻差分线谱对参数的系数为bi+1-bi,i=1,2,...,n-1;具体迭代公式如下:
ci=η(bi+1-bi),η<1,i=2,3,...,n-1(8)
(1)前向迭代:从j=2到j=n-1,前向调整第j阶巴克线谱对参数;
(2)后向迭代:从j=n-1到j=2,后向调整第j阶巴克线谱对参数;
(3)取平均:对前向迭代和后向迭代得到的巴克线谱对参数取平均得到增强型巴克线谱对参数;
式中,η控制共振峰增强的程度,η越小,增强效果越明显。
5)将输入语音信号的增强型巴克线谱对参数输入到深度神经网络分类器中进行多个病理单元音的识别。是首先从svd病理嗓音数据库中的每种单元音数据集中随机选取75%作训练集,25%作测试集,保证在分类网络训练和测试阶段每类嗓音数据满足平均分布,然后将蠕动息肉病理嗓音/a/、/i/、/u/和正常嗓音/a/、/i/、/u/这6种单元音嗓音的12阶增强型巴克线谱对参数输入到深度神经网络中进行识别,网络参数设置为:2层隐含层,每层100个神经元,选择relu函数作为激活函数,在识别模型最后一层选用softmax函数将神经网络的输出变成一个概率分布,进而优化分类结果。
下面给出具体实例:
1、预处理:分帧处理中每帧信号的时间长度为30ms,采样频率为8khz,对应帧长为240,帧移取80
2、计算线性预测系数时,p=12
3、由线性预测系数可以计算得到线性预测逆滤波器系统函数a(z)
4、计算a(z)的p+1阶对称和反对称多项式p(z)和q(z)
5、由p(z)和q(z)计算12阶lsp参数
6、由12阶lsp参数计算输入语音信号的11阶dal(differenceofadjacentlsp,dal)参数
7、对输入语音信号的lsp参数进行频率弯折得到输入语音信号的blsp(barklinespectrumpair,blsp)参数
图2a~图2f所示是本发明实施例6种单元音信号dal参数的盒图。其中,图2a所示是正常单元音/a/的11阶dal参数盒图;图2b所示是病理单元音/a/的11阶dal参数盒图;图2c所示是正常单元音/i/的11阶dal参数盒图;图2d所示是病理单元音/i/的11阶dal参数盒图;图2e所示是正常单元音/u/的11阶dal参数盒图;图2f所示是病理单元音/u/的11阶dal参数盒图。
由图2a~图2f可知,对于正常/a/、/i/、/u/三种单元音信号,前7阶dal数据分布的矩形框差别较大,对三种单元音有较好的区分度;对于病理/a/、/i/、/u/三种单元音信号,前7阶dal数据比正常嗓音分布较为均匀。对于病理/a/音,后4阶dal参数与正常/a/音分布完全不一样,而病理/i/音和/u/音的后4阶dal数据分布有较多重合部分,区分效果差。由于dal低阶参数对应信号低频部分,本发明实施例考虑到dal参数低频段区分度高于高频段的特性和bark域更能真实反应人耳对信号产生的感觉,采用bark域变换尺度对提取的lsp进行非线性频率弯折得到blsp参数,弯折函数是:
bark=26.81/(1+(1960/f))-0.53(6)
式中,bark表示bark频率;f表示线性频率。
图3a~图3b所示是本发明实施例12阶lsp参数和12阶blsp参数的示意图。与图3a相比,图3b放大了信号低频部分,压缩了高频部分,提高了正常和病理多元音的区分度。
8、对输入语音信号的blsp参数进行特征增强得到e-blsp(enhanced-barklinespectrumpair,e-blsp)参数:η控制共振峰增强的程度,η越小,增强效果越明显。本发明实施例η取0.4。
图4a~图4b所示是本发明实施例12阶blsp参数和12阶e-blsp参数的三维频谱示意图。图4b与图4a相比,共振峰频率处幅值大大提高,展宽效应得以抑制,大大增强了正常和病理多元音的区分度。
9、将输入语音信号的e-blsp参数输入到dnn分类器中进行多个病理单元音的识别
本发明实施例首先从每种单元音数据集中随机选取75%作训练集,25%作测试集,保证在分类网络训练和测试阶段每类嗓音数据满足平均分布,然后将6种单元音嗓音的12阶e-blsp参数输入到dnn(deepneuralnetwork,dnn)网络中进行识别。网络参数设置如下:2层隐含层,每层100个神经元。
本发明实施例在选取单元音嗓音源信号方面,采用萨兰大学语音研究所负责录制的svd(saarbruckenvoicedatabase,svd)病理嗓音数据库,包含持续元音/a/、/i/和/u/的正常和各种病理嗓音信号,采样率统一为50khz,分辨率为16位。从中选取蠕动息肉病理嗓音和正常嗓音的各三种持续元音/a/、/i/、/u/进行实验,采样率统一降为8khz。每类语音样本总数为180,包含4种不同音调(正常、低、高、低-高-低)。
本发明实施例的评价主要有准确率和auc两个指标。准确率定义为被正确分类案例的百分比,roc(receiveroperatingcharacteristic,roc)曲线是反映敏感性和特异性连续变量的综合指标,可以用构图法揭示敏感性和特异性的相互关系,auc(areaundercurve,auc)被定义为roc曲线下与坐标轴围成的面积,取值范围在0.5和1之间,auc的值越大,分类效果越好。为了保证实验的准确性和广泛性,每种特征组合实验做10次,将其取平均作为最后的分类结果。
从表1可以看出:本发明的特征对多个病理单元音的识别率比采用传统的mfcc和lpcc高。最高准确率可达97.3600%,auc可达0.9894。
表1
- 还没有人留言评论。精彩留言会获得点赞!