基于卷积神经网络的语音人格预测方法与流程
本发明涉及计算机应用技术领域,尤其涉及一种基于卷积神经网络的语音人格预测方法。
背景技术:
人格是个体在行为上的内部倾向性,代表了人与人之间稳定的行为差别。对人格的准确测评可以在消费、招聘等领域为用户提供精确的个性化服务。语音是人的“听觉面孔”与人格之间存在紧密联系,通过一个人的说话方式和发音特点可以推断他的人格特质。传统的人格测评使用问答方式的人格问卷,步骤不仅较为复杂而且必须依赖用户的配合。
传统方法需要通过提取语音的一些特征,包括声学特征和韵律特征。这些人工特征不能完整反映语音的信息,同时人工特征的设计需要很强的先验知识。这些缺点决定了现有技术在实际系统开发中很难设计出最优的具有区分度的特征,影响了语音预测人格模型性能的进一步提高。
技术实现要素:
针对上述问题中的至少之一,本发明提供了一种基于卷积神经网络的语音人格预测方法,通过对语音进行频谱分析,使用卷积神经网络对语音与大五人格的关系进行建模,实现基于语音的人格特质预测,给出关于开放性、尽责性、外向性、宜人性与神经质五个人格维度强弱的评估,克服了传统方法需要很强的先验知识来辅助提取有区分度特征的缺点,实现了语音特征的自动化提取,具有泛化性强,准确率高的优点。
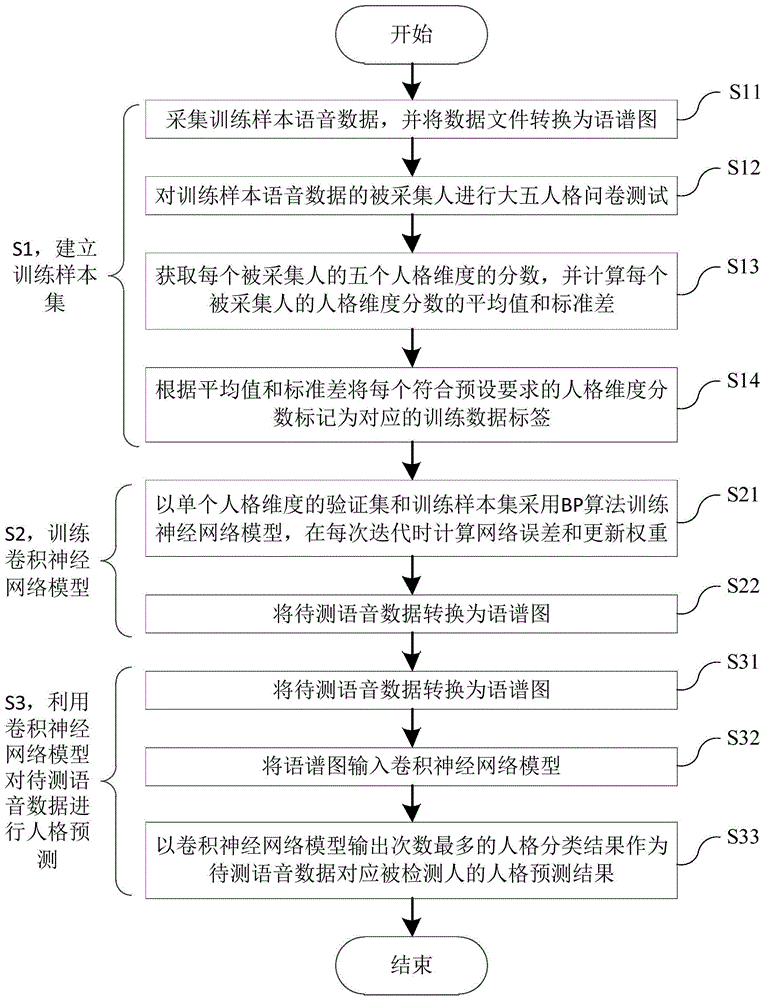
为实现上述目的,本发明提供了一种基于卷积神经网络的语音人格预测方法,包括:步骤s1,建立训练样本集,所述步骤s1具体包括:步骤s11:采集训练样本语音数据,并将数据文件转换为语谱图;步骤s12:对所述训练样本语音数据的被采集人进行大五人格问卷测试;步骤s13:获取每个被采集人的五个人格维度的分数,并计算每个被采集人的人格维度分数的平均值和标准差;步骤s14:根据所述平均值和标准差将每个符合预设要求的人格维度分数标记为对应的训练数据标签;步骤s2,训练卷积神经网络模型,所述步骤s2具体包括:步骤s21:以单个人格维度的验证集和所述训练样本集采用bp算法训练神经网络模型,并在每次迭代时计算网络误差和更新权重;步骤s22:训练至所述验证集正确率不再提高时终止,并保存神经网络参数作为该人格维度的神经网络模型;步骤s3,利用所述卷积神经网络模型对待测语音数据进行人格预测,所述步骤s3具体包括:步骤s31:将所述待测语音数据转换为语谱图;步骤s32:将所述语谱图输入所述卷积神经网络模型;步骤s33:以所述卷积神经网络模型输出次数最多的人格分类结果作为所述待测语音数据对应被检测人的人格预测结果。
在上述技术方案中,优选地,所述步骤s14中根据所述平均值和标准差将每个符合预设要求的人格维度分数标记为对应的训练数据标签具体包括:将低于对应平均值0.5个标准差的人格维度分数标记为0,将高于对应平均值0.5个标准差的人格维度分数标记为1,将标记后的人格维度分数作为训练数据标签。
在上述技术方案中,优选地,所述卷积神经网络模型类型为resnet,其迭代过程中采用最小批的方式计算网络误差和更新权重。
在上述技术方案中,优选地,所述步骤s31中将所述待测语音数据转换为语谱图具体包括:将所述待测语音数据按照步移1秒窗长3秒的时间窗进行分割;将分割后的所有待测语音数据片段转换为语谱图。
在上述技术方案中,优选地,所述步骤s21中以单个人格维度的验证集和所述训练样本集采用bp算法训练神经网络模型具体包括:搭建预设层数的神经网络,并将所述神经网络的输入层大小设置为所述语谱图大小;以80%训练样本集对应20%验证集的比例划分所述训练样本语音数据;以所述训练样本集和所述验证集采用bp算法训练神经网络模型。
在上述技术方案中,优选地,采用短时傅里叶变换将数据文件转换为语谱图。
与现有技术相比,本发明的有益效果为:通过对语音进行频谱分析,使用卷积神经网络对语音与大五人格的关系进行建模,实现基于语音的人格特质预测,给出关于开放性、尽责性、外向性、宜人性与神经质五个人格维度强弱的评估,克服了传统方法需要很强的先验知识来辅助提取有区分度特征的缺点,实现了语音特征的自动化提取,具有泛化性强,准确率高的优点。
附图说明
图1为本发明一种实施例公开的基于卷积神经网络的语音人格预测方法的流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合附图对本发明做进一步的详细描述:
如图1所示,根据本发明提供的一种基于卷积神经网络的语音人格预测方法,包括:步骤s1,建立训练样本集,步骤s1具体包括:步骤s11:采集训练样本语音数据,并将.wav格式的语音数据文件经过短时傅里叶变换转换为语谱图;步骤s12:对训练样本语音数据的被采集人进行大五人格问卷测试;步骤s13:获取每个被采集人的五个人格维度的分数,并计算每个被采集人的人格维度分数的平均值和标准差;步骤s14:根据平均值和标准差将每个符合预设要求的人格维度分数标记为对应的训练数据标签;步骤s2,训练卷积神经网络模型,步骤s2具体包括:步骤s21:以单个人格维度的验证集和训练样本集采用bp算法训练神经网络模型,并在每次迭代时计算网络误差和更新权重;步骤s22:训练至验证集的正确率不再提高时终止,并保存神经网络参数作为该人格维度的神经网络模型,对五个人格维度分别训练5个神经网络模型;步骤s3,利用卷积神经网络模型对待测语音数据进行人格预测,步骤s3具体包括:步骤s31:将待测语音数据按照步移1秒窗长3秒的时间窗进行分割并转换为语谱图;步骤s32:将所有语谱图依次输入卷积神经网络模型;步骤s33:获得神经网络模型输出的分类结果,统计每个分类的次数,最终以卷积神经网络模型输出次数最多的人格分类结果作为待测语音数据对应被检测人的人格预测结果。
在上述实施例中,优选地,步骤s14中根据平均值和标准差将每个符合预设要求的人格维度分数标记为对应的训练数据标签具体包括:将低于对应平均值0.5个标准差的人格维度分数标记为0,将高于对应平均值0.5个标准差的人格维度分数标记为1,将标记后的人格维度分数作为训练数据标签。
在上述实施例中,优选地,卷积神经网络模型类型为resnet,其迭代过程中采用最小批的方式计算网络误差和更新权重。
具体的,通过线下采集的大学生的语音数据对语音与人格的关系进行建模,对上述实施例进行说明,具体实施步骤如下:
(1)通过线下采集的方式收集到198人的说话录音,录音内容包括3段固定文本、10串随机数字、2段开放式问题回答。每人平均录音时长450秒,录音格式pcm.wav,采样率16000hz,单通道。
(2)对每个说话人进行了大五人格量表测试,获得说话人大五人格各个维度得分。求得每个人格维度得分的平均值及标准差,将得分低于平均值0.5个标准差的数据记为0,高于平均值0.5个标准差的记为1,作为录音数据标签。
(3)对语音文件进行预处理:按照步移1秒窗长3秒的时间窗对每个说话人的语音文件进行分割,形成多个语音段。
(4)对语音进行频谱分析:通过短时傅里叶变换将语音段转换为语谱图。
(5)搭建50层的resnet网络,神经网络输入层大小为语谱图大小,即(512,300,1),输出层是2个神经元的softmax层。
(6)对每一个人格维度进行神经网络的训练,以下以一个人格维度为例进行说明。
(7)按照80%训练集20%验证集的比例对数据进行划分;
(8)采用bp算法训练神经网络,每次迭代采用最小批的方式计算网络误差和更新权重,当在验证集上正确率不再提高时终止网络训练,保存神经网络参数。
(9)使用保存的模型对测试语音进行人格预测:
1)将待预测语音文件按照步移1秒窗长3秒的时间窗进行分割并转换为语谱图。
2)将所全部语谱图依次输入神经网络模型,获得神经网络输出的分类结果。
3)统计每个分类的次数,最终以次数最多的分类作为此个语音文件的最终预测结果。
通过上述步骤建立的卷积神经网络模型,对测试语音的人格5个维度的平均预测准确率达到68.9%。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!