一种基于自适应语音帧加权的说话人识别方法与流程
本发明属于语音信号处理技术领域,特别是一种基于自适应语音帧加权的说话人识别方法。
背景技术:
说话人识别技术(也称声纹识别技术)属于生物认证技术的一种,是一项根据语音波形中反映说话人生理和行为特征的语音参数,自动识别说话人身份的技术。说话人识别在个性化人机交互、军事斗争、信息安全及多媒体娱乐领域都有着广阔的应用前景。例如,通过说话人声纹自动判别出访客身份,从而提供个性化、贴身化服务。
现有的说话人识别方法主要包括:基于高斯混合模型的方法、基于ubm-map(universalbackgroundmodel,maximumaposteriori)架构的方法、基于i-vector的说话人识别方法、基于dnn(deepneuralnetwork)的说话人识别方法、基于cnn(convolutionalneuralnetwork)的说话人识别方法。
尽管声纹识别的研究已有半个世纪之久,但现有的声纹识别系统仍存在许多困难,还远远达不到社会对其实用化的要求,主要存在的问题有:
1.尚未找到简单、可靠的说话人语音特征参数。语音信号中既包含了说话人的语义信息,也包含了说话人发声特征的个性信息,是语音特征和说话人特征的混合体,到目前为止,还没有很好的方法将说话人的个体特征从语音特征中分离出来,也没有找到简单的声学特征参数用以可靠地识别说话人。
2.语音信号的漂移性。即使对于同一说话人和同一文本,语音信号也有很大的变异性,说话人的语音特征不是固定不变的,它具有时变特征,常常与说话人所处的环境、情绪、健康状况有密切关系,会随着时间的推移和年龄的变化而变化。另外,传输语音的通信信道的时变效应问题也是语音信号产生变异的重要方面。语音信号的变异性本质上说是说话人特征空间发生移动,说话人模式发生变异,从而增加识别过程中的不确定性。说话人识别中存在的噪声、多通道、时飘、情绪等热点都属于这个方面。
3.大规模识别系统。说话人识别系统要将特征空间划分为n个子空间(n=说话人数),当说话人自动识别系统中的n增多时,说话人识别系统的性能将受到极大的挑战。
技术实现要素:
本发明要解决的技术问题是提供基于自适应语音帧加权的说话人识别方法,解决现有技术中i-vector说话人识别框架中,噪声的干扰对识别结果的影响。
为解决上述问题,本发明提供的解决方案是提供一种基于自适应语音帧加权的说话人识别方法,第一步,基于训练数据得到通用背景高斯模型,包括:
a1:通过最大期望算法,利用训练数据训练出256个中心的通用背景高斯模型,返回gmm超参数均值、均方差矩阵和权重;
a2:提取得到的所述通用背景高斯模型的baum-welch零阶统计量ng和一阶统计量fg,其中:
其中,p(g|ot,λubm)表示给定观测ot后,所述通用背景高斯模型的第g个分量的后验概率;
a3:通过最大期望算法从训练集中学习一个全变量子空间t,假设因子分析的模型为:
m=m+t·x
其中,m是从测试集自适应调整ubm后得到的均值超矢量,m是ubm的均值超矢量,x是遵循标准正态分布的随机矢量,称作i-vector;
第二步,通过训练数据对高斯概率线性判别分类器进行训练,包括:b1:提取训练集的i-vector来训练高斯概率线性判别分类器,使用最大期望算法来从训练集的i-vector学习得到高斯概率线性判别分类器;
假设i-vector的因子分析模型为:
b2:高斯概率线性判别分类器的对应参数经训练后返回,对应参数包括:特征音矩阵、残差噪声的协方差矩阵、i-vector的均值、权值转化;
第三步,根据注册信息对识别结果进行打分,将得分最高者辨识为目标说话人,包括:c1:对待识别说话人进行注册,首先导入待注册说话人的mfcc特征,接下来使用最大后验概率算法将先前训练好的所述通用背景高斯模型自适应调整为表示各个说话人的gmm模型,并根据gmm超参数提取代表各个说话人身份特征的i-vector;
c2:对待识别说话人进行打分,首先导入待识别说话人的mfcc特征,之后提取各个说话人的i-vector,并根据步骤c1中得到的已注册说话人的i-vector进行打分,使用高斯概率线性判别分类器计算i-vector试验的验证分数,计算如下:
注册说话人和目标说话人分别记为x1和x2,x1和x2通过之前训练的高斯概率线性判别分类器进行建模;通过批次间的对数似然比来描述是相同的说话人(h1)或者是不同的说话人(h0);
c3:对得分进行筛选,评分最高的就是待识别说话人所对应的注册说话人的身份。
在本发明基于自适应语音帧加权的说话人识别方法的另一实施例中,对受噪声影响较小的语音帧,选择增大其在识别中的权重,在i-vector提取过程中,计算gmm的baum-welch统计量时,不同帧有不同的权重,对于语音帧{x1,…,xi,…xn}来说,权重分别为{α1,…,αi,…,αn},且{αi≥0,i=1,…,n}:
在说话人识别中,gmm用于建模从说话人的语句中提取出频谱特征的概率密度,对于一个d维的特征矢量xi,概率密度函数如下所示:
式中
给定从语句中提取的n个特征矢量,θ的最大似然估计将会用来最大化下式的似然:
使用对数似然j(θ)作为优化目标,
对于每个特征矢量xi引入权重参数αi,相应的对数似然目标函数为:
引入一个辅助函数
其中引入了一个中间变量:
其中的c是非负常数项:
其中,
于是,mk和σk可以由下式计算得出:
其中的diag是对角化算子,只保留矩阵中的对角线条目,随后利用拉格朗日乘子法来优化关于wk的函数;
通过解
在下一次迭代时,首先用更新后的wk,mk和σk来计算
在本发明基于自适应语音帧加权的说话人识别方法的另一实施例中,对说话人i-vector提取流程包括:
从ubm均值中提取了预先训练好的说话人和信道无关的超矢量μkd×1之后,i-vector可以用下式提取ωr×1:
m=μ+tω,
在这里,mkd×1是经过自适应的gmm的均值超矢量,tkd×r是一个对说话人和信道子空间建模的低秩矩阵,ωr×1是一个服从标准正态分布的随机矢量称为i-vector,矩阵t建模了全变量子空间,并且已经使用em算法经训练数据训练过;
对于测试语音段,通过加权gmm算法,可以得到一个加权的m,归结为下面的零阶和一阶bw统计量:
集中的一阶统计量如下:
这里μk是μ的第k个子向量,
当令
最终,一段语音的i-vector可以由下式得到:
其中,ir×r是身份矩阵,nkd×kd是对角线元素为{nkid×d,k=1,…,k}的对角矩阵;
在本发明基于自适应语音帧加权的说话人识别方法的另一实施例中,对于鲁棒性不同的帧,需要对它们赋予不同的权重,通过将附加噪声添加到测试语音段上,包括:
1)首先,选取white,babble和pink噪声对原始的带噪语音进行二次加噪处理;
2)然后,得到原始语音帧和处理后的语音帧的mfcc特征,并求出二者的欧氏距离;
3)三种距离取平均值后,选取出它们中的最小值并记为dmin,那么语音帧xi被赋予的权重为:
其中,
本发明的有益效果是:本发明提供一种基于自适应语音帧加权的说话人识别方法,利用带噪语音段中存在的各语音帧信噪比不一致的问题,将信噪比高的语音帧加重权,信噪比低的帧加弱权,并将其提取为对应的mfcc特征,从而构建出含有帧加权信息的gmm并提取i-vector。在此基础上实现了说话人识别任务,使得原有的说话人识别框架在噪声环境下依然有较好的性能。
附图说明
图1是本发明一种基于自适应语音帧加权的说话人识别方法中应用于说话人识别系统示意图;
图2是本发明一种基于自适应语音帧加权的说话人识别方法中帧加权方法步骤示意图;
图3是本发明一种基于自适应语音帧加权的说话人识别方法中本发明和原i-vector说话人识别系统在white噪声环境下完成确认任务的效果对比图。
具体实施方式
为了便于理解本发明,下面结合附图和具体实施例,对本发明进行更详细的说明。附图中给出了本发明的较佳的实施例。但是,本发明可以以许多不同的形式来实现,并不限于本说明书所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
需要说明的是,除非另有定义,本说明书所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是用于限制本发明。本说明书所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
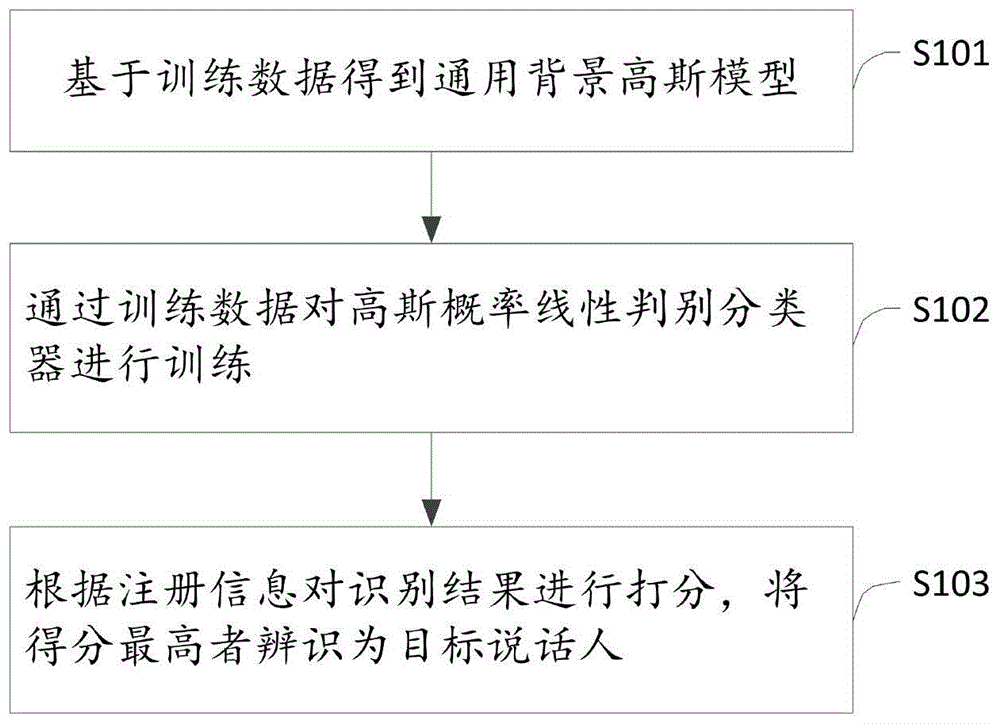
结合图1,本发明公开了一种基于自适应语音帧加权的说话人识别方法实施例,包括步骤有:
第一步s101,基于训练数据得到通用背景高斯模型,包括:
a1:通过最大期望算法(expectationmaximizationalgorithm),利用训练数据训练出256个中心的通用背景高斯模型(universalbackgroundmodel,ubm),返回gmm超参数均值、均方差矩阵和权重;
a2:提取得到的所述通用背景高斯模型的baum-welch零阶统计量ng和一阶统计量fg,其中:
其中,p(g|ot,λubm)表示给定观测ot后,所述通用背景高斯模型的第g个分量的后验概率;
a3:通过最大期望算法从训练集中学习一个全变量子空间t,假设因子分析的模型为:
m=m+t·x
其中,m是从测试集自适应调整ubm后得到的均值超矢量,m是ubm的均值超矢量,x是遵循标准正态分布的随机矢量,称作i-vector;
第二步s102,通过训练数据对高斯概率线性判别分类器进行训练,具体包括:
b1:提取训练集的i-vector来训练高斯概率线性判别分类器(gaussianprobabilisticlda,gplda),使用最大期望算法来从训练集的i-vector学习得到高斯概率线性判别分类器;
假设i-vector的因子分析模型为:
b2:高斯概率线性判别分类器的对应参数经训练后返回,对应参数包括:特征音矩阵、残差噪声的协方差矩阵、i-vector的均值、权值转化;
第三步s103,根据注册信息对识别结果进行打分,将得分最高者辨识为目标说话人,具体包括:
c1:对待识别说话人进行注册,首先导入待注册说话人的mfcc特征,接下来使用最大后验概率算法(maximumaposterioriestimation,map)将先前训练好的所述通用背景高斯模型自适应调整为表示各个说话人的gmm模型,并根据gmm超参数提取代表各个说话人身份特征的i-vector;
c2:对待识别说话人进行打分,首先导入待识别说话人的mfcc特征,之后提取各个说话人的i-vector,并根据步骤c1中得到的已注册说话人的i-vector进行打分,使用高斯概率线性判别分类器计算i-vector试验的验证分数,计算如下:
注册说话人和目标说话人分别记为x1和x2,x1和x2通过之前训练的高斯概率线性判别分类器进行建模;通过批次间的对数似然比来描述是相同的说话人(h1)或者是不同的说话人(h0);
c3:对得分进行筛选,评分最高的就是待识别说话人所对应的注册说话人的身份。
进一步的,因为不同的语音帧对于噪声的鲁棒性是不同的,所以对那些受噪声影响较小的语音帧,我们选择增大其在识别中的权重,从而提升这些噪声鲁棒帧对最后识别效果的影响。为此,在i-vector提取过程中,计算gmm的baum-welch统计量时,不同帧有不同的权重,对于语音帧{x1,…,xi,…xn}来说,权重分别为{α1,…,αi,…,αn},且{αi≥0,i=1,…,n}:
在说话人识别中,gmm用于建模从说话人的语句中提取出频谱特征的概率密度,对于一个d维的特征矢量xi,概率密度函数如下所示:
式中
给定从语句中提取的n个特征矢量,θ的最大似然估计将会用来最大化下式的似然:
使用对数似然j(θ)作为优化目标,
对于每个特征矢量xi引入权重参数αi,相应的对数似然目标函数为:
引入一个辅助函数
其中引入了一个中间变量:
其中的c是非负常数项:
其中,
于是,mk和σk可以由下式计算得出:
其中的diag是对角化算子,只保留矩阵中的对角线条目,随后利用拉格朗日乘子法来优化关于wk的函数;
通过解
在下一次迭代时,首先用更新后的wk,mk和σk来计算
进一步的,对说话人i-vector提取流程包括:
从ubm均值中提取了预先训练好的说话人和信道无关的超矢量μkd×1之后,i-vector可以用下式提取ωr×1:
m=μ+tω,
在这里,mkd×1是经过自适应的gmm的均值超矢量,tkd×r是一个对说话人和信道子空间建模的低秩矩阵,ωr×1是一个服从标准正态分布的随机矢量称为i-vector,矩阵t建模了全变量子空间,并且已经使用em算法经训练数据训练过;
对于测试语音段,通过加权gmm算法,可以得到一个加权的m,归结为下面的零阶和一阶bw统计量:
集中的一阶统计量如下:
这里μk是μ的第k个子向量,
当令
最终,一段语音的i-vector可以由下式得到:
其中,ir×r是身份矩阵,nkd×kd是对角线元素为{nkid×d,k=1,…,k}的对角矩阵;
进一步的,对于鲁棒性不同的帧,需要对它们赋予不同的权重,通过将附加噪声添加到测试语音段上,结合图2所示步骤,包括:
1)首先,选取white,babble和pink三种噪声对原始的带噪语音进行二次加噪处理;
2)然后,得到原始语音帧和处理后的语音帧的mfcc特征,并求出二者的欧氏距离;
3)每个语音帧对三种欧氏距离取平均值后,选取出它们中的最小值并记为dmin,那么语音帧xi被赋予的权重为:
其中,
图3是本发明和原i-vector说话人识别系统在white噪声环境下完成确认任务的效果对比图。
本发明的有益效果是:本发明提供一种基于自适应语音帧加权的说话人识别方法,利用带噪语音段中存在的各语音帧信噪比不一致的问题,将信噪比高的语音帧加重权,信噪比低的帧加弱权,并将其提取为对应的mfcc特征,从而构建出含有帧加权信息的gmm并提取i-vector。在此基础上实现了说话人识别任务,使得原有的说话人识别框架在噪声环境下依然有较好的性能。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!