FDNS应用前实现将MDCT频谱衰落到白噪声的装置及方法与流程
本发明涉及音频信号编码、处理及解码,特别地涉及,针对切换式音频编码系统在错误隐藏过程中的改良信号衰落的装置及方法。
背景技术:
在下文中,描述关于封包丢失隐藏(plc)过程中的语音及音频编码解码器衰落的现有技术的状态。关于现有技术的状态的解释始于g系列(g.718、g.719、g.722、g.722.1、g.729、g.729.1)的itu-t编码解码器,接着为3gpp编码解码器(amr、amr-wb、amr-wb+)及ietf编码解码器(opus),且以两种mpeg编码解码器(e-aac、hiln)结束(itu=国际电信协会;3gpp=第三代合作伙伴计划;amr=适应性多速率;wb=宽带;ietf=因特网工程任务小组)。随后,分析关于追踪背景噪声水平的现有技术的状态,接着为提供概述的总结。
首先,考虑g.718。g.718为支持dtx/cng(dtx=数字影院系统;cng=舒缓噪声产生)的窄频及宽带语音编码解码器。作为尤其涉及低延迟码的实施例,此处,将更详细地描述低延迟版本模式。
考虑acelp(层1)(acelp=代数码激发线性预测),itu-t为g.718[itu08a,章节7.11]推荐了用以控制衰落速度的线性预测域中的适应性衰落。大体而言,隐藏遵循此原理:
根据g.718,在帧擦除的状况下,隐藏策略可总结为将信号能量及频谱包络收敛至背景噪声的所估计参数。将信号的周期性收敛为零。收敛速度取决于最后正确地接收的帧的参数及连续被擦除的帧的数目,并由衰减因子α控制。衰减因子α进一步取决于用于无声帧的lp(lp=线性预测)滤波器的稳定性θ。大体而言,若接收到的最后良好帧处于稳定分段中,则收敛是缓慢的,且若帧处于转变分段中,则收敛是快速的。
衰减因子α取决于[itu08a,章节6.8.1.3.1及7.11.1.1]中所描述的信号分类得到的语音信号类别。基于邻近isf(导抗频谱频率)滤波器之间的距离度量计算稳定性因子θ[itu08a,章节7.1.2.4.2]。
表1展示α的计算方案:
表1:衰减因子α的值,值θ为自邻近lp滤波器之间的距离度量所计算的稳定性因子[itu08a,章节7.1.2.4.2]。
此外,g.718提供衰落方法以便修改的频谱包络。一般想法为使最后的isf参数朝向适应性isf均值向量收敛。首先,从最后3个已知的isf向量计算出平均isf向量。接着,将平均isf向量与脱机训练的长期isf向量(其为常数向量)再次平均[itu08a,章节7.11.1.2]。
此外,g.718提供衰落方法,以控制长期行为且因此控制与背景噪声的相互作用,其中将音高激发能量(且因此激发周期性)收敛为0,而随机激发能量收敛为cng激发能量[itu08a,章节7.11.1.6]。如下计算创新增益衰落:
其中
类似于周期性激发衰落,从
图2概述g.718的解码器结构。特别地,图2说明用于plc的具有高通滤波器的高阶g.718解码器结构。
通过g.718的上文所描述的方法,对于封包丢失的较长突发,创新增益gs收敛为舒缓噪声产生过程中所使用的增益gn。如[itu08a,章节6.12.3]中所描述,舒缓噪声增益gn给定为能量
其中unvoiced_vad包含语音活动检测,其中unv_cnt包含成列的无声帧的数目,其中lp_gainc包含固定码簿的低通增益,且其中lp_ener包含初始化为0的低通cng能量估计
此外,若最后的良好帧的信号分类为不同于无声的信号,则g.718提供引入至无声激发的信号路径中的高通滤波器,参见图2,亦参见[itu08a,章节7.11.1.6]。此滤波器具有低搁板特性,其在dc处的频率响应比奈奎斯频率处的频率响应低大约5db。
此外,g.718提出解耦式ltp反馈回路(ltp=长期预测):虽然在正常操作过程中,基于完全激发逐子帧地更新用于适应性码簿的反馈回路([itu08a,章节7.1.2.1.4])。在隐藏过程中,仅基于有声激发,逐帧地更新此反馈回路(参见[itu08a,章节7.11.1.4、7.11.2.4、7.11.1.6、7.11.2.6;dec_gv_exc@dec_gen_voic.c及syn_bfi_post@syn_bfi_pre_post.c])。借助于此方法,适应性码簿未被噪声「污染」,该噪声的起源在于随机选择的创新激发。
关于g.718的变换编码增强层(3至5),在隐藏过程中,解码器的关于高层解码的行为类似于正常操作,只是mdct(改良型离散余弦转换)频谱被设定为零。在隐藏过程中并未应用特定的衰落行为。
关于cng,在g.718中,按以下次序完成cng合成。首先,对舒缓噪声帧的参数进行解码。接着,合成舒缓噪声帧。然后重置音高缓冲器。接着,储存用于fer(帧错误恢复)分类的合成。然后,进行频谱去加重。接着进行低频后滤波。接着,更新cng变量。
在隐藏的状况下,执行完全一样的步骤,除了从比特串流中解码cng参数。这意味在帧丢失的过程中不更新参数,而是使用来自最后良好sid(静默插入描述符)帧的解码参数。
现在考虑g.719。基于siren22的g.719为基于变换的全频带音频编码解码器。itu-t为g.719推荐了在频谱域中具有帧重复的衰落[itu08b,章节8.6]。根据g.719,将帧擦除隐藏机制并入到解码器中。当正确地接收到帧时,将重建变换系数储存于缓冲器中。若通知解码器帧已丢失或帧被损毁,则在最近接收的帧中重建的变换系数以因子0.5按比例递减,且接着被用作当前帧的重建变换系数。解码器通过将这些系数变换至时域及执行开窗重迭相加操作而继续进行。
在下文中,描述了g.722。g.722为50至7000hz编码系统,其使用在高达64kbit/s(千位/秒)的比特率内的子频带适应性差分脉码调制(sb-adpcm)。使用qmf分析(qmf=正交镜像滤波)将信号拆分成较高及较低子频带。两个所得频带为adpcm编码的(adpcm=适应性差分脉码调制)。
对于g.722,在附录iii[itu06a]中指定用于封包丢失隐藏的高复杂性算法,及在附录iv[itu07]中指定用于封包丢失隐藏的低复杂性算法。g.722-附录iii([itu06a,章节iii.5])提出逐步执行的静音,其在帧丢失20ms之后开始,在帧丢失60ms之后完成。此外,g.722-附录iv提出衰落技术,其「对每一个样本」应用「逐样本地计算及调适的增益因子」[itu07,章节iv.6.1.2.7]。
在g.722中,就在qmf合成之前,静音程序发生于子频带域中,且作为plc模块的最后步骤。使用来自信号分类器的类别信息执行静音因子的计算,该信号分类器亦为plc模块的部分。在类别transient、uv_transition与其他类别之间进行区别。此外,在10ms帧的单次丢失与其他状况(10ms帧的多次丢失及20ms帧的单次/多次丢失)之间进行区别。
由图3说明此情形。特别地,图3描绘g.722的衰落因子取决于类别信息且其中80个样本等效于10ms的情境。
根据g.722,plc模块产生用于遗漏帧的信号及应该与下一良好帧交叉衰落的某一额外信号(10ms)。针对此额外信号的静音遵循相同规则。在g.722的高频带隐藏中,交叉衰落并未发生。
在下文中,考虑g.722.1。基于siren7的g.722.1为具有超宽带带扩展模式的基于变换的宽带带音频编码解码器,其被称作g.722.1c。g.722.1c自身基于siren14。itut为g.722.1推荐具有后续静音的帧重复[itu05,章节4.7]。若借助于此推荐中未定义的外部发信号机制来通知解码器帧已丢失或损毁,则解码器重复先前帧的解码mlt(调制重迭变换)系数。该解码器通过将该系数变换至时域及执行与先前及下一帧的解码信息的重迭及相加操作来继续进行。若先前帧亦丢失或损毁,则解码器将所有当前帧mlt系数设定为零。
现在考虑g.729。g.729为用于语音的音频数据压缩算法,其压缩10毫秒持续时间的封包中的数字语音。其被正式地描述为使用码激发线性预测语音编码码(cs-acelp)的在8kbit/s下的语音编码[itu12]。
如[cpk08]中所概述,g.729推荐lp域中的衰落。g.729标准中所使用的plc算法基于先前接收的语音信息来重建用于当前帧的语音信号。换言之,plc算法用先前接收的帧的等效特性来代替遗漏激发,但激发能量最终逐渐衰减,适应性及固定码簿的增益按常数因子衰减。
通过以下等式来给出衰减的固定码簿增益:
其中m为子帧索引。
适应性码簿增益是基于先前适应性码簿增益的衰减版本:
naminpark等人针对g.729提议使用借助于线性回归的预测的信号振幅控制[cpk08,pkj+11]。其用于突发封包丢失,且使用线性回归作为核心技术。线性回归是基于如下线性模型:
g′i=a+bi(2)
其中,g′i为新预测的当前振幅,a及b为用于一阶线性函数的系数,且i为帧的索引。为了找到优化系数a*及b*,使平方预测误差的总和最小化:
ε为平方误差,gj为原始的过去第j个振幅。为了使此误差最小化,简单地将关于a及b的导数设定为零。通过使用优化参数a*及b*,每一个
图4展示通过使用线性回归的振幅预测,特别地,振幅
为了获得丢失封包i的振幅a′i,将比率σi
与比例因子si相乘:
a′i=si*σi(6)
其中比例因子si取决于连续隐藏帧的数目l(i):
在[pkj+11]中,提出了略有不同的按比例缩放。
根据g.729,然后a′i将被平滑化以防止帧边界处的离散衰减。将最终平滑化振幅ai(n)与自先前plc组件获得的激发相乘。
在下文中,考虑g.729.1。g.729.1为基于g.729的嵌入式可变比特率编码器:可与g.729互操作的8至32kbit/s可调式宽带编码器比特串流[itu06b]。
根据g.729.1,如在g.718(参见上文)中,提出适应性衰落,其取决于信号特性的稳定性([itu06b,章节7.6.1])。在隐藏的过程中,信号通常是基于衰减因子α而衰减的,衰减因子α取决于最后良好接收的帧类别的参数及连续被擦除帧的数目。衰减因子α进一步取决于用于无声帧的lp滤波器的稳定性。大体而言,若最后良好接收帧处于稳定分段中,则衰减是缓慢的,且若帧处于转变分段中,则衰减是快速的。
此外,衰减因子α取决于每一子帧的平均音高增益
其中
表2展示α的计算方案,其中
在隐藏程序的过程中,α被用于以下隐藏工具中:
表2:衰减因子α的值,值θ为自邻近lp滤波器之间的距离度量所计算的稳定性因子。[itu06b,章节7.6.1]。
根据g.729.1,关于喉脉冲再同步,因为先前帧的激发的最后脉冲是用于建构周期性部分,所以其增益在隐藏的帧的开始处大约是正确的,且可被设定为1。增益接着在整个帧中逐样本地线性衰减,从而达成在帧的结束处的α的值。通过使用最后良好帧的每一子帧的音高激发增益值来外插有声片段的能量演进。大体而言,若这些增益大于1,则信号能量正在增加,若这些增益小于1,则能量正在减少。α因此被设定为
关于激发的随机部分的建构,根据g.729.1,在被擦除区块的开始处,通过使用最后良好帧的每一子帧的创新激发增益来初始化创新增益gs:
gs=0.1g(0)+0.2g(1)+0.3g(2)+0.4g(3)
其中g(0)、g(1)、g(2)及g(3)为最后正确地接收的帧的四个子帧的固定码簿增益或创新增益。如下进行创新增益衰减:
其中
根据g.729.1,若最后良好帧为无声,则仅使用创新激发且其进一步按0.8的因子衰减。在此状况下,用创新激发来更新过去激发缓冲器,因为激发的周期性部分是不可用的,参见[itu06b,章节7.6.6]。
在下文中,考虑amr。3gppamr[3gp12b]为利用acelp算法的语音编码解码器。amr能够编码具有8000个样本/s的采样率及4.75与12.2kbit/s之间的比特率的语音,且支持静默描述符帧的发信号(dtx/cng)。
在amr中,在错误隐藏的过程中(参见[3gp12a]),区别了易于出错(位错误)的帧与完全丢失(完全没有资料)的帧。
对于acelp隐藏,amr引入估计频道质量的状态机:状态计数器的值愈大,频道质量愈差。系统在状态0开始。每次检测到不良帧,状态计数器便递增1,且在其达到6时饱和。每次检测到良好语音帧,状态计数器便被重置为零,不过在状态为6时除外,此时状态计数器被设定为5。状态机的控制流程可由以下c程序代码描述(bfi为不良帧指示符,state为状态变量):
除了此状态机之外,在amr中,检查来自当前及先前帧的不良帧旗标(prevbfi)。
三个不同组合为可能的:
三个组合中的第一个为bfi=0,prevbfi=0,state=0:在所接收的语音帧或在先前接收的语音帧中并未检测到错误。所接收的语音参数以正常方式用于语音合成中。储存语音参数的当前帧。
三个组合中的第二者为bfi=0,prevbfi=1,state=0或5:在所接收的语音帧中并未检测到错误,但先前接收的语音帧是不良的。限制ltp增益及固定码簿增益使其低于用于最后接收的良好子帧的值:
其中gp=当前解码ltp增益,gp(-1)=用于最后良好子帧的ltp增益(bfi=0),且
其中gc=当前解码固定码簿增益,且gc(-1)=用于最后良好子帧的固定码簿增益(bfi=0)。
所接收的语音参数的剩余部分被正常地用于语音合成中。储存语音参数的当前帧。
三个组合中的第三者为bfi=1,prevbfi=0或1,state=1……6:在所接收的语音帧中检测到错误,且开始替换及静音程序。ltp增益及固定码簿增益由来自先前子帧的衰减值代替:
其中gp指示当前解码ltp增益,且gp(-1),……,gp(-n)指示用于最后n个子帧的ltp增益,且median5()指示5点中值运算,且
p(state)=衰减因子,
其中(p(1)=0.98,p(2)=0.98,p(3)=0.8,p(4)=0.3,p(5)=0.2,p(6)=0.2)且state=状态号,且
其中gc指示当前解码固定码簿增益,且gc(-1),……,gc(-n)指示用于最后n个子帧的固定码簿增益,且median5()指示5点中值运算,且c(state)=衰减因子,其中(c(1)=0.98,c(2)=0.98,c(3)=0.98,c(4)=0.98,c(5)=0.98,c(6)=0.7)且state=状态号。
在amr中,ltp滞后值(ltp=长期预测)由来自先前帧的第4个子帧的过去值(12.2模式)或基于最后正确接收的值略作修改的值(所有其他模式)代替。
根据amr,在接收到损毁资料时按接收到固定码簿创新脉冲时的状态使用来自错误帧的所接收脉冲。在并未接收到数据的状况下,应使用随机固定码簿索引。
关于amr中的cng,根据[3gp12a,章节6.4],通过使用来自较早接收的有效sid帧的sid信息来替换每一个第一丢失的sid帧,且应用用于有效sid帧的程序。对于后续丢失的sid帧,将衰减技术应用于舒缓噪声,该舒缓噪声将逐渐减少输出水平。因此,检查最后sid更新是否是在超过50个帧(=1s)以前,若是如此,则将使输出静音(每一帧水平衰减-6/8db[3gp12d,dtx_dec{}@sp_dec.c],其每秒产生37.5db)。应注意在lp域中执行应用于cng的衰落。
在下文中,考虑amr-wb。适应性多速率wb[itu03,3gp09c]为基于amr的语音编码解码器,acelp(参见章节1.8)。其使用参数带宽扩展且亦支持dtx/cng。在标准[3gp12g]的描述中,给出了隐藏实例解决方案,其与amr[3gp12a]下的状况相同,具有微小的偏差。因此,此处仅描述与amr的不同之处。针对标准描述,参见上文的描述。
关于acelp,在amr-wb中,基于参考源代码,通过修改音高增益gp(针对上文的amr,被称作ltp增益)及通过修改码增益gc执行acelp衰落[3gp12c]。
在丢失帧的状况下,用于第一子帧的音高增益gp与最后良好帧中的音高增益相同,不过其被限于0.95与0.5之间。对于第二、第三及以后的子帧,音高增益gp以0.95的因子减小,且再次受限制。
amr-wb提出:在隐藏的帧中,gc是基于最后gc:
gc,current=gc,past*(1.4-gp,past)(14)
为了隐藏ltp滞后,在amr-wb中,将五个最后良好ltp滞后及ltp增益的历史用于寻找在帧丢失的状况下进行更新的最佳方法。在接收到具有位错误的帧的情况下,不论所接收的ltp滞后是否可使用,皆执行预测[3gp12g]。
关于cng,在amr-wb中,若最后正确地接收的帧为sid帧,且帧分类为丢失,则其应由最后有效的sid帧信息来替换,且应该应用用于有效sid帧的程序。
对于后续丢失sid帧,amr-wb提出将衰减技术应用于舒缓噪声,该舒缓噪声将逐渐减少输出水平。因此,检查最后sid更新是否是在超过50个帧(=1s)以前,若是如此,则将输出静音(每一帧水平衰减-3/8db[3gp12f,dtx_dec{}@dtx.c],其每秒产生18.75db)。应注意在lp域中执行应用于cng的衰落。
现在考虑amr-wb+。适应性多速率wb+[3gp09a]为使用acelp及tcx(tcx=9变换编码激发)作为核心编码解码器的切换式编码解码器。其使用参数带宽扩展且亦支持dtx/cng。
在amr-wb+中,应用模式外插逻辑以在失真超帧内外插丢失帧的模式。此模式外插是基于在模式指示符的定义中存在冗余的事实。由amr-wb+提出的决策逻辑(在[3gp09a,图18]中给出)如下:
-定义向量模式(m-1,m0,m1,m2,m3),其中m-1指示先前超帧的最后帧的模式,且m0、m1、m2、m3指示当前超帧(自比特串流解码)中的帧的模式,其中mk=-1、0、1、2或3(-1:丢失,0:acelp,1:tcx20,2:tcx40,3:tcxs0),且其中丢失帧的数目nloss可在0与4之间。
-若m-1=3,且帧0至3的模式指示符中的两者等于三,则所有指示符将被设定为三,因为接着可肯定在超帧内指示了一个tcx80帧。
-若帧0至3中的仅一个指示符为三(且丢失帧的数目nloss为三),则模式将被设定为(1,1,1,1),因为接着tcx80目标频谱的3/4丢失且极有可能全局tcx增益丢失。
-若模式指示(x,2,-1,x,x)或(x,-1,2,x,x),则其将被外插为(x,2,2,x,x),从而指示tcx40帧。若模式指示(x,x,x,2,-1)或(x,x,-1,2),则其将被外插为(x,x,x,2,2),亦指示tcx40帧。应注意(x,[0,1],2,2,[0,1])为无效配置。
-之后,对于丢失的每一帧(模式=-1),若前一帧为acelp,将模式设定为acelp(模式=0),且针对所有其他状况,将模式设定为tcx20(模式=1)。
关于acelp,根据amr-wb+,若丢失帧模式导致在模式外插之后mk=0,则针对此帧应用与[3gp12g]中相同的方法(参见上文)。
在amr-wb+中,取决于丢失帧的数目及外插之模式,区别进行以下tcx相关隐藏方法(tcx=经变换编码激发):
-若整个帧丢失,则应用类似acelp的隐藏:重复最后激发,且使用隐藏的isf系数(朝向其适应性均值稍微移位)以合成时域信号。另外,就在lpc(线性预测编码)合成之前,在线性预测域中乘以每一帧(20ms)0.7的衰落因子[3gp09b,dec_tcx.c]。
-若最后模式为tcx80,以及(部分丢失)超帧的外插模式为tcx80(nloss=[1,2],模式=(3,3,3,3,3)),则考虑到最后正确地接收的帧,利用相位及振幅外插在fft域中执行隐藏。此处,相位信息的外插方法并不被关注(与衰落策略无关),且因此未进行描述。对于进一步细节,参见[3gp09a,章节6.5.1.2.4]。关于amr-wb+的振幅修改,针对tcx隐藏所执行的方法由以下步骤构成[3gp09a,章节6.5.1.2.3]:
-计算先前帧量级频谱:
-计算当前帧量级频谱:
-计算先前与当前帧之间的非丢失频谱系数的能量的增益差:
-使用如下等式来外插遗漏频谱系数的振幅:
若(lost[k])a[k]=gain·olda[k]
-在mk=[2,3]的丢失帧的每一其他状况中,使用所有可用的信息(包括全局tcx增益)来合成tcx目标(解码频谱加噪声填充(使用自比特串流解码的噪声水平)的反fft)。在此状况下并不应用衰落。
关于amr-wb+中的cng,使用与amr-wb中相同的方法(参见上文)。
在下文中,考虑opus。opus[iet12]并有来自两种编码解码器的技术:语音导向式silk(其被称为skype编码解码器)及低潜时celt(celt=受约束的能量重迭变换)。可在高及低比特率之间顺畅地调整opus,且在内部,opus在处于较低比特率下的线性预测编码解码器(silk)与处于较高比特率下的变换编码解码器(celt)以及用于短重迭的混合体之间切换。
关于silk音讯数据压缩及解压缩,在opus中,若干参数在silk解码器例程中的隐藏的过程中受到衰减。在使用来自先前帧的激发的最后音高循环积累起激发的情况下,取决于连续丢失帧的数目,通过对于每一帧将所有lpc系数与0.99、0.95抑或0.90相乘使ltp增益参数衰减。音高滞后参数在连续丢失的过程中极缓慢地增大。对于单次丢失,与最后帧相比较,音高滞后参数保持恒定。此外,激发增益参数按每一帧
现在,在opus的上下文中,考虑celt。celt为基于变换的编码解码器。celt的隐藏以基于音高的plc方法为特征,该方法应用于多达五个连续丢失帧。从帧6开始,应用类似噪声的隐藏方法,该方法产生背景噪声,该背景噪声的特性应该听起来好像先前背景噪声。
图5说明celt的突发丢失行为。特别地,图5描绘celt隐藏语音分段的频谱图(x轴:时间;y轴:频率)。浅灰色方框指示前5个连续丢失帧,其中应用基于音高的plc方法。除此之外,展示了类似噪声的隐藏。应注意的是即刻执行切换,该切换并非平滑地转变。
关于基于音高的隐藏,在opus中,基于音高的隐藏由通过自相关发现解码信号中的周期性及使用音高偏移(音高滞后)重复窗化波形(在使用lpc分析及合成的激发域中)构成。窗化波形以保留时域混迭消除的方式与先前帧及下一帧重迭[iet12]。另外,通过以下程序代码得到及应用衰落因子:
在此程序代码中,exc含有激发信号,该激发信号多达在丢失之前的max_period个样本。
激发信号稍后与衰减相乘,接着经由lpc合成而被合成及输出。
用于时域方法的衰落算法可概述如下:
-找到在丢失之前的最后音高循环的音高同步能量。
-找到在丢失之前的倒数第二音高循环的音高同步能量。
-若能量增大,则对其进行限制以保持恒定:衰减=1
-若能量减少,则在隐藏的过程中继续相同的衰减。
关于类似噪声的隐藏,根据opus,对于第六个及以后的连续丢失帧,执行mdct域中的噪声替换方法,以便对舒缓背景噪声进行仿真。
关于背景噪声水平及形状的追踪,在opus中,背景噪声估计执行如下:在mdct分析之后,计算每一频带的mdct频带能量的平方根,其中根据[iet12,表55],mdct频率仓(bin)的分组遵循巴克尺度(barkscale)。接着通过以下等式将能量的平方根变换至log2域:
bandloge[i]=log2(e)·loge(bande[i]-emeans[i])其中i=0...21(18)
其中e为欧拉数,bande为mdct频带的平方根,且emeans为常数向量(其为得到导致增强的编码增益的结果零均值所必要的)。
在opus中,如下在解码器侧上对背景噪声求对数[iet12,amp2log2及log2amp@quant_bands.c]:
backgroundloge[i]=min(backgroundloge[i]+8·0.001,bandloge[i])
其中i=0…21(19)
所追踪的最小能量基本上是由当前帧的频带的能量的平方根来判定的,但自一个帧至下一帧的增加限于0.05db。
关于背景噪声水平及形状的应用,根据opus,若应用类似plc的噪声,则使用如在最后良好帧中得到的backgroundloge,且将其反向转换至线性域:
其中e为欧拉数,且emeans为与用于“线性至对数”变换的常数向量相同的常数向量。
当前隐藏程序将用由随机数产生器产生的白噪声填充mdct帧,且以该白噪声逐频带地匹配bande的能量的方式按比例调整此白噪声。随后,应用产生时域信号的反mdct。在重迭相加及去加重(如在常规解码中)之后,放出时域信号。
在下文中,考虑mpeg-4he-aac(mpeg=动画专业团体;he-aac=高效率进阶音讯编码)。高效率进阶音讯编码由补充了参数带宽扩展(sbr)的基于变换的音频编码解码器(aac)构成。
关于aac(aac=进阶音讯编码),dab联盟针对dab+中的aac指定了在频域中至零的衰落[ebu10,章节a1.2](dab=数位音频传输)。例如衰减斜坡的衰落行为可能为固定的或可由使用者调整。来自最后au(au=存取单元)的频谱系数按对应于衰落特性的因子衰减,且接着被传递至频率至时间映像。取决于衰减斜坡,隐藏在数个连续无效au之后切换至静音,其意味完整频谱将被设定为0。
drm(drm=数字版权管理)联盟针对drm中的aac指定了在频域中的衰落[ebu12,章节5.3.3]。隐藏刚好在最终的频率至时间转换之前对频谱数据起作用。若多个帧被损毁,隐藏首先基于来自最后有效帧的略作修改的频谱值实施衰落。此外,类似于dab+,例如衰减斜坡的衰落行为可能为固定的或可由使用者调整。来自最后帧的频谱系数按对应于衰落特性的因子衰减,且接着被传递至频率至时间映像。取决于衰减斜坡,隐藏在数个连续无效帧之后切换至静音,其意味完整频谱将被设定为0。
3gpp为增强型aacplus中的aac引入了类似于drm的在频域中的衰落[3gp12e,章节5.1]。隐藏刚好在最终的频率至时间转换之前对频谱数据起作用。若多个帧被损毁,隐藏首先基于来自最后良好帧的略作修改的频谱值实施衰落。完整衰落历时5个帧。复制来自最后良好帧的频谱系数,且其按如下因子衰减:
衰落因子=2-(nfadeoutframe/2)
其中nfadeoutframe作为自最后良好帧以来的帧计数器。在历时五个帧的衰落之后,隐藏切换至静音,此意味完整频谱将被设定为0。
lauber及sperschneider为aac引入了基于能量外插的mdct频谱的逐帧衰落[ls01,章节4.4]。前一频谱的能量形状可能被用以外插所估计频谱的形状。可独立于隐藏技术,作为一种后隐藏来执行能量外插。
关于aac,在比例因子频带的基础上执行能量计算以便接近人类听觉系统的关键频带。个别能量值被逐帧地减小以便平滑地降低音量,例如使信号衰落。由于所估计值表示当前信号随时间流逝而快速降低,所以此情形变得有必要。
为了产生待馈出的频谱,lauber及sperschneider提议帧重复或噪声替换[ls01,章节3.2及3.3]。
quackenbusch及driesen针对aac提议至零的指数逐帧衰落[qd03]。提出了时间/频率系数的邻近集合的重复,其中每一重复具有指数地增加的衰减,因此在延长的中断的状况下逐渐衰落至静音。
关于mpeg-4he-aac中的sbr(sbr=频谱带复制),3gpp针对增强型aacplus中的sbr提议了对解码包络数据进行缓冲,且在帧丢失的状况下,再次使用所传输的包络数据的缓冲能量,且针对每一隐藏的帧使能量按3db的恒定比率减少。将结果反馈至正常解码程序中,其中包络调整器用其计算增益,这些增益用于调整由hf产生器产生的修补高频带。sbr解码接着照常发生。此外,增量(δ)编码的噪声底限及正弦水平值被删除。因为与先前信息的差别不再可用,所以解码噪声底限及正弦水平保持与hf产生的信号的能量成正比[3gp12e,章节5.2]。
drm联盟针对结合aac的sbr指定与3gpp相同的技术[ebu12,章节5.6.3.1]。此外,dab联盟针对dab+中的sbr指定与3gpp相同的技术[ebu10,章节a2]。
在下文中,考虑mpeg-4celp及mpeg-4hvxc(hvxc=谐波向量激发编码)。drm联盟针对结合celp及hvxc的sbr[ebu12,章节5.6.3.2]指定不管何时检测到损毁的sbr帧,用于语音编码解码器的sbr的最低要求隐藏应用于数据值的预定集合。那些值产生在低相对播放水平处的静态高频带频谱包络,从而展现出朝向较高频率的滚降。目标仅为借助于插入“舒缓噪声”(与严格的静音相对照)而确保没有不良的、潜在大声的音讯突发到达听者的耳朵。此实际上并非真正的衰落,而是跳转至某一能量水平以便插入某一种类的舒缓噪声。
随后,提到替代例[ebu12,章节5.6.3.2],其再次使用最后正确地解码数据且使水平(l)朝向0缓慢地衰落,这类似于aac+sbr状况。
现在,考虑mpeg-4hiln(hiln=谐波及个别线加噪声)。meine等人引入了在参数域中用于参数mpeg-4hiln编码解码器[iso09]的衰落[mep01]。对于持续谐波分量,用于代替损毁的差分编码参数的良好默认行为是保持频率恒定,使振幅按衰减因子(例如,-6db)减少,及令频谱包络朝向具有平均化的低通特性的频谱包络收敛。用于频谱包络的替代例将为使其保持不变。关于振幅及频谱包络,可以与对待谐波分量相同的方式来对待噪声分量。
在下文中,考虑现有技术中的背景噪声水平的追踪。rangachari及loizou[rl06]提供对若干方法的良好概述且论述其中一些的限制。用于追踪背景噪声水平的方法为(例如)最小值跟踪程序[rl06][coh03][sfb00][dob95],基于vad(vad=语音活动检测);卡尔曼滤波[gan05][bjh06],子空间分解[bp06][hjh08];软决策[ss98][mpc89][he95]及最小值统计。
最小值统计方法被选择用于usac-2(usac=统一语音及音讯编码)的范畴内,且随后更详细概述。
基于最佳平滑及最小值统计的噪声功率谱密度估计[mar01]引入噪声估计式,该噪声估计式能够独立于信号为作用中语音或背景噪声的情况而工作。与其他方法相对比,最小值统计算法并不使用任何显式临限值在语音活动与语音暂停之间进行区分,且因此相较于与传统的语音活动检测方法相关的程度,与软决策方法相关的程度更高。类似于软决策方法,其亦可在语音活动的过程中更新所估计噪声psd(功率谱密度)。
最小值统计方法根据两个观测,亦即语音及噪声通常在统计上独立且有噪声语音信号的功率频繁衰减至噪声的功率水平。因此有可能通过跟踪有噪声信号psd的最小值而得到准确的噪声psd(psd=功率谱密度)估计。因为最小值小于(或在其他状况下等于)平均值,所以最小值跟踪方法需要偏差补偿。
偏差为平滑化信号psd的方差的函数,且因而取决于psd估计式的平滑参数。与对最小值跟踪的较早期研究(其利用恒定平滑参数及恒定最小偏差校正)相对比,使用基于时间及频率的psd平滑,其亦需要基于时间及频率的偏差补偿。
使用最小值跟踪提供对噪声功率的粗略估计。然而,存在一些缺点。具有固定平滑参数的平滑化加宽了平滑化psd估计的语音活动的峰值。此将产生不准确的噪声估计,因为用于最小值搜寻的滑动窗可能滑到宽峰值中。因此,无法使用接近于一的平滑参数,且因此,噪声估计将具有相对较大的方差。此外,使噪声估计偏向较低值。此外,在增加噪声功率的状况下,最小值跟踪落在后面。
具有低复杂性的基于mmse的噪声psd跟踪[hhj10]引入了背景噪声psd方法,该方法利用了用于dft(离散傅立叶变换)频谱上的mmse搜寻。该算法由这些处理步骤构成:
-基于先前帧的噪声psd计算最大可能性估计式。
-计算最小均方估计式。
-使用决策导向方法[em84]来估计最大可能性估计式。
-在假定语音及噪声dft系数为高斯分布的情况下计算反偏差因子。
-所估计噪声功率谱密度为平滑的。
亦应用安全网方法以便避免算法的完全死锁。
基于数据驱动的递归噪声功率估计来跟踪非稳定噪声[eh08]引入了用于根据由极不稳定噪声源污染的语音信号估计噪声频谱方差的方法。此方法亦使用在时间/频率方向上的平滑。
基于噪声功率估计的平滑及估计偏差校正的低复杂性噪声估计算法[yu09]增强了[eh08]中所引入的方法。主要的差别在于,用于噪声功率估计的频谱增益函数是由迭代数据驱动方法发现的。
用于噪声语音增强的统计方法[mar03]组合[mar01]中给出的最小值统计方法、软决策增益修改[mca99]、先验snr的估计[mca99]、适应性增益限制[mc99]以及mmse对数频谱振幅估计式[em85]。
对于多个语音及音频编码解码器而言,衰落是备受关注的,这些编码解码器特别地为amr(参见[3gp12b])(包括acelp及cng)、amr-wb(参见[3gp09c])(包括acelp及cng)、amr-wb+(参见[3gp09a])(包括acelp、tcx及cng)、g.718(参见[itu08a])、g.719(参见[itu08b])、g.722(参见[itu07])、g.722.1(参见[itu05])、g.729(参见[itu12、cpk08、pkj+11])、mpeg-4he-aac/增强型aacplus(参见[ebu10、ebu12、3gp12e、ls01、qd03])(包括aac及sbr)、mpeg-4hiln(参见[iso09、mep01])及opus(参见[iet12])(包括silk及celt)。
取决于编码解码器,在不同域中执行衰落:
对于利用lpc的编码解码器,在线性预测域(亦称为激发域)中执行衰落。对于基于acelp的编码解码器(例如,amr、amr-wb、amr-wb+的acelp核心、g.718、g.729、g.729.1、opus中的silk核心);使用时间-频率变换进一步处理激发信号的编码解码器(例如amr-wb+的tcx核心、opus中的celt核心)及在线性预测域中操作的舒缓噪声产生(cng)方案(例如,amr中的cng、amr-wb中的cng、amr-wb+中的cng)而言,此情形同样适用。
对于将时间信号直接变换至频域的编码解码器,在频谱/子频带域中执行衰落。对于基于mdct或类似变换的编码解码器(诸如,mpeg-4he-aac中的aac、g.719、g.722(子频带域)及g.722.1)而言,此情形同样适用。
对于参数编码解码器,在参数域中应用衰落。对于mpeg-4hiln而言,此情形同样适用。
关于衰落速度及衰落曲线,衰落通常是通过应用衰减因子而实现,该衰减因子被应用于适当域中的信号表示。衰减因子的大小控制着衰落速度及衰落曲线。在大多数状况下,逐帧地应用衰减因子,但亦利用逐样本应用,参见例如g.718及g.722。
可能以两个方式(绝对及相对)提供用于某一信号分段的衰减因子。
在绝对地提供衰减因子的状况下,参考水平总是为最后接收的帧的水平。绝对衰减因子通常以用于紧接在最后良好帧之后的信号分段的接近1的值开始,且接着朝向0较快地或较慢地降级。衰落曲线直接取决于这些因子。此为例如g.722的附录iv中所描述的隐藏的状况(特别地参见[itu07,图iv.7]),其中可能的衰落曲线为线性或逐渐线性的。考虑增益因子g(n)(而g(0)表示最后良好帧的增益因子)、绝对衰减因子αabs(n),任何后续丢失帧的增益因子可得到为:
g(n)=αabs(n)·g(0)(21)
在相对地提供衰减因子的状况下,参考水平为来自先前帧的水平。此情形在递归隐藏程序的状况下(例如,在已经衰减的信号被进一步处理及再次衰减的情况下)具有优点。
若递归地应用衰减因子,则此因子可能为独立于连续丢失帧的数目的固定值,例如针对g.719的0.5(参见上文);与连续丢失帧的数目有关的固定值,例如,如在[cpk08]中针对g.729所提出的:针对前两个帧的1.0、针对接下来两个帧的0.9、针对帧5及6的0.8及针对所有后续帧的0(参见上文);或与连续丢失帧的数目有关且取决于信号特性的值,例如用于不稳定的信号的较快衰落及用于稳定信号的较慢衰落,例如g.718(参见上文的章节及[itu08a,表44]);
假设相对衰落因子0≤αrel(n)≤1,而n为丢失帧的数目(n≥1);任何后续帧的增益因子可被得到为:
g(n)=αrel(n)·g(n-1)(22)
从而导致指数衰落。
关于衰落程序,通常指定衰减因子,但在一些应用标准(drm、dab+)中,衰减因子的指定被留给制造者完成。
若不同信号部分被单独地衰落,则可能应用不同衰减因子例如以用某一速度衰减音调分量及用另一速度衰减类似噪声的分量(例如,amr、silk)。
通常,将某一增益应用于整个帧。当在频谱域中执行衰落时,此情形是仅有的可能方式。然而,若在时域或线性预测域中进行衰落,则可能进行更细致化的衰落。此更细致化的衰落应用于g.718中,其中通过最后帧的增益因子与当前帧的增益因子之间的线性内插针对每一样本得到个体增益因子。
对于具有可变帧持续时间的编码解码器,恒定的相对衰减因子导致取决于帧持续时间的不同衰落速度。例如对于aac就是此状况,其中帧持续时间取决于采样率。
为了对最后接收的信号的时间形状采用所应用的衰落曲线,可能进一步调整(静态)衰落因子。例如针对amr应用此进一步动态调整,其中考虑先前五个增益因子的中值(参见[3gp12b]及章节1.8.1)。在执行任何衰减之前,若中值小于最后增益,则将当前增益设定为中值,否则使用最后增益。此外,例如针对g729应用此进一步动态调整,其中使用先前增益因子的线性回归来预测振幅(参见[cpk08、pkj+11]及章节1.6)。在此状况下,用于第一隐藏帧的所得增益因子可能超出最后接收的帧的增益因子。
关于衰落的目标水平,对于所有所分析的编码解码器(包括那些编码解码器的舒缓噪声产生(cng)),目标水平为0(g.718及celt例外)。
在g.718中,单独地执行音高激发(表示音调分量)的衰落及随机激发(表示类似噪声的分量)的衰落。在音高增益因子衰落至零的同时,创新增益因子衰落至cng激发能量。
假设给出相对衰减因子,此基于公式(23)而导致以下绝对衰减因子:
g(n)=αrel(n)·g(n-1)+(1-αrel(n))·gn(25)
其中gn为在舒缓噪声产生的过程中使用的激发的增益。当gn=0时,此公式对应于公式(23)。
g.718在dtx/cng的状况下不执行衰落。
在celt中,不存在朝向目标水平的衰落,但在历时5个帧的音调隐藏(包括衰落)之后,水平在第6个连续丢失帧处即刻切换至目标水平。使用公式(19)逐频带地得到水平。
关于衰落的目标频谱形状,所有所分析的纯粹基于变换的编码解码器(aac、g.719、g.722、g.722.1)以及sbr仅仅在衰落的过程中延长最后良好帧的频谱形状。
各种语音编码解码器使用lpc合成将频谱形状衰落至均值。均值可能为静态(amr)或适应性的(amr-wb、amr-wb+、g.718),而适应性均值系自静态均值及短期均值得到(通过求最后n个lp系数集合的平均值来得到)(lp=线性预测)。
所论述的编码解码器amr、amr-wb、amr-wb+、g.718中的所有cng模块皆在衰落的过程中延长最后良好帧的频谱形状。
关于背景噪声水平追踪,自文献中已知五个不同方法:
-基于语音活动检测器:基于snr/vad,但极难以调谐,且难以用于低snr语音。
-软决策方案:软决策方法考虑到语音存在的机率[ss98][mpc89][he95]。
-最小值统计:跟踪psd的最小值,在缓冲器中随时间的流逝保持一定量的值,因此使得能够从过去样本中找到最小噪声[mar01][hhj10][eh08][yu09]。
-卡尔曼滤波:算法使用随时间的流逝观测到的含有噪声(随机变化)的一系列量测,且产生倾向于比单独基于单一量测的估计更精确的噪声psd的估计。卡尔曼滤波器对有噪声输入数据的串流进行递归操作,以产生系统状态的统计学上的最佳估计[gan05][bjh06]。
-子空间分解:此方法试图利用例如klt(卡忽南-拉维(karhunen-loève)变换,其亦称为主分量分析)及/或dft(离散时间傅立叶变换)将类似噪声的信号分解成干净的语音信号及噪声部分。接着可使用任意平滑算法追踪本征向量/本征值[bp06][hjh08]。
技术实现要素:
本发明的目的在于提供用于音频编码系统的改良概念。本发明的目的是由用于对编码音频信号进行解码以获得重建音频信号的装置、由用于对编码音频信号进行解码以获得重建音频信号的方法及由计算机可读存储介质实现。
提供用于对编码音频信号进行解码以获得重建音频信号的装置。装置包含用于接收包括关于编码音频信号的音频信号频谱的多个音频信号样本的信息的一个或多个帧的接收接口,及用于产生重建音频信号的处理器。处理器用于,在当前帧不由接收接口接收的情况下或在当前帧由接收接口接收但被损毁的情况下,通过将修改的频谱衰落至目标频谱来产生重建音频信号,其中修改的频谱包含多个修改的信号样本,其中对于修改的频谱的每个修改的信号样本,该修改的信号样本的绝对值等于音频信号频谱的音频信号样本中一个的绝对值。此外,处理器用于,在一个或多个帧中的当前帧由接收接口接收的情况下以及由接收接口接收的当前帧未被损毁的情况下,不将修改的频谱衰减至目标频谱。
根据实施例,目标频谱可例如为类似噪声的频谱。
在实施例中,类似噪声的频谱可例如表示白噪声。
根据实施例,类似噪声的频谱可例如被成形。
在实施例中,类似噪声的频谱的形状可例如取决于先前接收的信号的音频信号频谱。
根据实施例,类似噪声的频谱可例如取决于音频信号频谱的形状而成形。
在实施例中,处理器可例如使用倾斜因子来使类似噪声的频谱成形。
根据实施例,处理器可例如使用如下公式:
shaped_noise[i]=noise*power(tilt_factor,i/n)
其中n指示样本的数目,其中i为索引,其中0<=i<n,其中tilt_factor>0,且其中power为功率函数。
power(x,y)指示xy
power(tilt_factor,i/n)指示
若tilt_factor小于1,则此情形意味在i增加的情况下的衰减。若tilt_factor大于1,则意味在i增加的情况下的放大。
根据另一实施例,处理器可例如使用如下公式:
shaped_noise[i]=noise*(1+i/(n-1)*(tilt_factor-1))
其中n指示样本的数目,其中i为索引,其中0<=i<n,其中tilt_factor>0。
若tilt_factor小于1,则此情形意味在i增加的情况下的衰减。若tilt_factor大于1,则意味在i增加的情况下的放大。
根据实施例,处理器可例如用于,在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,通过改变音频信号频谱的音频信号样本中的一个或多个的符号来产生修改的频谱。
在实施例中,音频信号频谱的音频信号样本中的每一个可例如由实数表示,但不由虚数表示。
根据实施例,音频信号频谱的音频信号样本可例如被表示在修改离散余弦变换域中。
在另一实施例中,音频信号频谱的音频信号样本可例如被表示在修改离散正弦变换域中。
根据实施例,处理器可例如用于通过使用随机或伪随机输出第一值抑或第二值的随机符号函数产生修改的频谱。
在实施例中,处理器可例如用于通过随后减小衰减因子而将修改的频谱衰落至目标频谱。
根据实施例,处理器可例如用于通过随后增加衰减因子而将修改的频谱衰落至目标频谱。
在实施例中,在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,处理器可例如用于通过使用如下公式产生重建音频信号:
x[i]=(1-cum_damping)*noise[i]+cum_damping*random_sign()*x_old[i]其中i为索引,其中x[i]指示重建音频信号的样本,其中cum_damping为衰减因子,其中x_old[i]指示编码音频信号的音频信号频谱的音频信号样本中的一个,其中random_sign()返回1或-1,且其中noise为指示目标频谱的随机向量。
在实施例中,该随机向量noise可例如被按比例调整以使得其二次均值类似于由接收接口最后所接收的帧中的一个帧所包含的编码音频信号的频谱的二次均值。
根据一般实施例,处理器可例如用于通过使用随机向量产生重建音频信号,按比例调整该随机向量以使得其二次均值类似于由接收接口最后所接收的帧中的一个帧所包含的编码音频信号的频谱的二次均值。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的方法。该方法包括:
-接收包括关于编码音频信号的音频信号频谱的多个音频信号样本的信息的一个或多个帧。及:
-产生重建音频信号。
在当前帧未被接收的情况下或在当前帧被接收但被损毁的情况下,通过将修改的频谱衰落至目标频谱进行产生重建音频信号,其中修改的频谱包含多个修改的信号样本,其中对于修改的频谱的每个修改的信号样本,该修改的信号样本的绝对值等于音频信号频谱的音频信号样本中的一个的绝对值。在一个或多个帧中的当前帧被接收的情况下及在所接收的当前帧未被损毁的情况下,不将修改的频谱衰落至白噪声频谱。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程序。
实施例实现在fdns应用(fdns=频域噪声替换)之前使mdct频谱衰落至白噪声。
根据现有技术,在基于acelp的编码解码器中,用随机向量(例如,用噪声)来代替创新码簿。在实施例中,对tcx解码器结构采用由用随机向量(例如,用噪声)代替创新码簿构成的acelp方法。此处,创新码簿的等效物为通常在比特串流内被接收且被反馈至fdns中的mdct频谱。
经典mdct隐藏方法将为简单地照原样重复此频谱或应用某一随机化程序,该随机化程序基本上延长最后接收的帧的频谱形状[ls01]。此情形的缺点是延长了短期的频谱形状,从而频繁地导致反复的金属声音,该声音并不类似背景噪声,且因此无法被用作舒缓噪声。
使用所提出的方法,通过fdns及tcxltp执行短期频谱成形,仅通过fdns执行长期频谱成形。由fdns进行的成形自短期频谱形状衰落至背景噪声的追踪的长期频谱形状,且将tcxltp衰落至零。
将fdns系数衰落至追踪的背景噪声系数,导致在最后良好频谱包络与长远来看应被设定为目标的频谱背景包络之间具有平滑转变,以便在长突发帧丢失的状况下达成合意的背景噪声。
相比之下,根据现有技术的状态,对于基于变换的编码解码器,通过频域中的帧重复或噪声替换来进行类似噪声的隐藏[ls01]。在现有技术中,噪声替换通常由频谱仓的符号加扰来执行。若在隐藏的过程中使用现有技术tcx(频域)符号加扰,则再次使用最后接收的mdct系数,且在频谱被反向变换至时域之前使每一符号随机化。现有技术的此程序的缺点为对于连续丢失的帧,一次又一次地使用相同频谱,其仅仅是具有不同的符号随机化及全局衰减。当在粗时间网格上查看随时间的流逝的频谱包络时,可以看见包络在连续帧丢失的过程中大约为恒定的,因为频带能量在帧内相对于彼此保持恒定,且仅全局地衰减。在所使用的编码系统中,根据现有技术,使用fdns来处理频谱值,以便恢复原始频谱。此意味在想要将mdct频谱衰落至某一频谱包络(使用例如描述当前背景噪声的fdns系数)的情况下,结果不仅取决于fdns系数,而且取决于被符号加扰的先前解码的频谱。上文所提及的实施例克服现有技术的这些缺点。
实施例是基于有必要在将频谱反馈至fdns处理之前将用于符号加扰的频谱衰落至白噪声的发现。否则,输出的频谱将决不匹配用于fdns处理的目标包络。
在实施例中,对于ltp增益衰落使用与白噪声衰落相同的衰落速度。
此外,提供用于解码音频信号的装置。
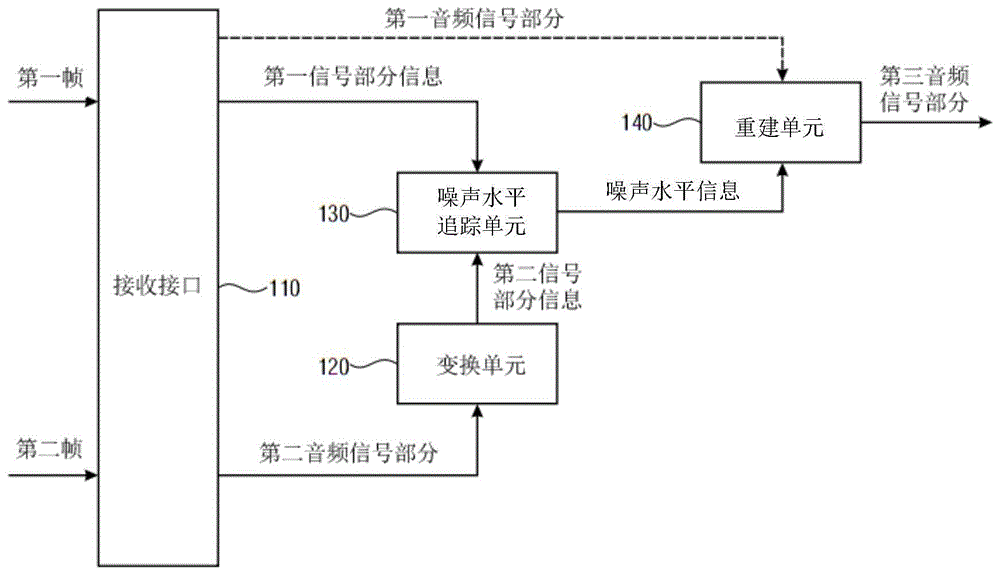
装置包含接收接口。接收接口用于接收多个帧,其中该接收接口用于接收多个帧中的第一帧,该第一帧包含音频信号的第一音频信号部分,该第一音频信号部分被表示于第一域中,且其中接收接口用于接收多个帧中的第二帧,该第二帧包含音频信号的第二音频信号部分。
此外,装置包含变换单元,该变换单元用于将第二音频信号部分或自第二音频信号部分得到的值或信号自第二域变换至追踪域,以获得第二信号部分信息,其中第二域不同于第一域,其中追踪域不同于第二域,且其中追踪域等于或不同于第一域。
此外,装置包含噪声水平追踪单元,其中噪声水平追踪单元用于接收在追踪域中表示的第一信号部分信息,其中第一信号部分信息取决于第一音频信号部分。噪声水平追踪单元用于接收在追踪域中表示的第二信号部分,且其中噪声水平追踪单元用于取决于在追踪域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号部分信息而判定噪声水平信息。
此外,装置包含重建单元,该重建单元用于在多个帧中的第三帧不由接收接口接收而是被损毁的情况下,取决于噪声水平信息而重建音频信号的第三音频信号部分。
音频信号可例如为语音信号或音乐信号,或包含语音及音乐的信号等。
第一信号部分信息取决于第一音频信号部分的陈述意味:第一信号部分信息为第一音频信号部分或已取决于第一音频信号部分而获得/产生第一信号部分信息抑或第一信号部分信息以某一其他方式取决于第一音频信号部分。举例而言,第一音频信号部分可能已自一个域变换至另一域以获得第一信号部分信息。
同样,第二信号部分信息取决于第二音频信号部分的陈述意味:第二信号部分信息为第二音频信号部分抑或已取决于第二音频信号部分而获得/产生第二信号部分信息抑或第二信号部分信息以某一其他方式取决于第二音频信号部分。举例而言,第二音频信号部分可能已自一个域变换至另一域以获得第二信号部分信息。
在实施例中,第一音频信号部分可例如表示于作为第一域的时域中。此外,变换单元可例如用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的激发域变换至为追踪域的时域。此外,噪声水平追踪单元可例如用于接收在作为追踪域的时域中表示的第一信号部分信息。此外,噪声水平追踪单元可例如用于接收在作为追踪域的时域中表示的第二信号部分。
根据实施例,第一音频信号部分可例如表示于作为第一域的激发域中。此外,变换单元可例如用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的时域变换至为追踪域的激发域。此外,噪声水平追踪单元可例如用于接收在作为追踪域的激发域中表示的第一信号部分信息。此外,噪声水平追踪单元可例如用于接收在作为追踪域的激发域中表示的第二信号部分。
在实施例中,第一音频信号部分可例如表示于作为第一域的激发域中,其中噪声水平追踪单元可例如用于接收第一信号部分信息,其中该第一信号部分信息被表示于为追踪域的fft域中,且其中该第一信号部分信息取决于在激发域中表示的该第一音频信号部分,其中变换单元可例如用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的时域变换至为追踪域的fft域,且其中噪声水平追踪单元可例如用于接收在fft域中表示的第二音频信号部分。
在实施例中,装置可例如进一步包含用于取决于第一音频信号部分而判定第一聚合值的第一聚合单元。此外,装置可例如进一步包含用于取决于第二音频信号部分而将第二聚合值判定为自第二音频信号部分得到的值的第二聚合单元。此外,噪声水平追踪单元可例如用于接收第一聚合值作为在追踪域中表示的第一信号部分信息,其中噪声水平追踪单元可例如用于接收第二聚合值作为在追踪域中表示的第二信号部分信息,且其中噪声水平追踪单元可例如用于取决于在追踪域中表示的第一聚合值及取决于在追踪域中表示的第二聚合值而判定噪声水平信息。
根据实施例,第一聚合单元可例如用于判定第一聚合值以使得第一聚合值指示第一音频信号部分或自第一音频信号部分得到的信号的均方根。此外,第二聚合单元可例如用于判定第二聚合值以使得第二聚合值指示第二音频信号部分或自第二音频信号部分得到的信号的均方根。
在实施例中,变换单元可例如用于通过对自第二音频信号部分得到的值应用增益值而将自第二音频信号部分得到的值自第二域变换至追踪域。
根据实施例,增益值可例如指示由线性预测编码合成引入的增益,或增益值可例如指示由线性预测编码合成及去加重引入的增益。
在实施例中,噪声水平追踪单元可例如用于通过应用最小值统计方法判定噪声水平信息。
根据实施例,噪声水平追踪单元可例如用于将舒缓噪声水平判定为噪声水平信息。重建单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收接口接收但被损毁的情况下,取决于噪声水平信息而重建第三音频信号部分。
在实施例中,噪声水平追踪单元可例如用于将舒缓噪声水平判定为自噪声水平频谱得到的噪声水平信息,其中该噪声水平频谱是通过应用最小值统计方法而获得。重建单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收接口接收但被损毁的情况下,取决于多个线性预测系数而重建第三音频信号部分。
根据另一实施例,噪声水平追踪单元可例如用于将指示舒缓噪声水平的多个线性预测系数判定作为噪声水平信息,且重建单元可例如用于取决于多个线性预测系数而重建第三音频信号部分。
在实施例中,噪声水平追踪单元用于将指示舒缓噪声水平的多个fft系数判定作为噪声水平信息,且第一重建单元用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收接口接收但被损毁的情况下,取决于自这些fft系数得到的舒缓噪声水平而重建第三音频信号部分。
在实施例中,重建单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收接口接收但被损毁的情况下,取决于噪声水平信息及取决于第一音频信号部分而重建第三音频信号部分。
根据实施例,重建单元可例如用于通过减小或放大自第一或第二音频信号部分得到的信号来重建第三音频信号部分。
在实施例中,装置可例如进一步包含长期预测单元,该长期预测单元包含延迟缓冲器。此外,长期预测单元可例如用于取决于第一或第二音频信号部分、取决于储存于延迟缓冲器中的延迟缓冲器输入及取决于长期预测增益而产生被处理信号。此外,长期预测单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收接口接收但被损毁的情况下,使长期预测增益朝向零衰落。
根据实施例,长期预测单元可例如用于使长期预测增益朝向零衰落,其中长期预测增益衰落至零的速度取决于衰落因子。
在实施例中,长期预测单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收接口接收但被损毁的情况下,通过将产生的被处理信号储存于延迟缓冲器中来更新延迟缓冲器输入。
根据实施例,变换单元可例如为第一变换单元,及重建单元为第一重建单元。装置进一步包含第二变换单元及第二重建单元。第二变换单元可例如用于在多个帧中的第四帧不由接收接口接收的情况下或在该第四帧由接收接口接收但被损毁的情况下,将噪声水平信息自追踪域变换至第二域。此外,第二重建单元可例如用于在多个帧中的该第四帧不由接收接口接收的情况下或在该第四帧由接收接口接收但被损毁的情况下,取决于在第二域中表示的噪声水平信息而重建音频信号的第四音频信号部分。
在实施例中,第二重建单元可例如用于取决于噪声水平信息及取决于第二音频信号部分重建第四音频信号部分。
根据实施例,第二重建单元可例如用于通过减小或放大自第一或第二音频信号部分得到的信号来重建第四音频信号部分。
此外,提供用于解码音频信号的方法。
该方法包括:
-接收多个帧中的第一帧,该第一帧包含音频信号的第一音频信号部分,该第一音频信号部分被表示于第一域中。
-接收多个帧中的第二帧,该第二帧包含音频信号的第二音频信号部分。
-将第二音频信号部分或自第二音频信号部分得到的值或信号自第二域变换至追踪域以获得第二信号部分信息,其中第二域不同于第一域,其中追踪域不同于第二域,且其中追踪域等于或不同于第一域。
-取决于在追踪域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号部分信息而判定噪声水平信息,其中第一信号部分信息取决于第一音频信号部分。及:
-在多个帧中的第三帧不被接收的情况下或在该第三帧被接收但被损毁的情况下,取决于在追踪域中表示的噪声水平信息而重建音频信号的第三音频信号部分。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程序。
本发明的实施例中的一些提供时间变化平滑参数,以使得经平滑化周期图的跟踪能力及其方差受到较好地平衡,以开发用于偏差补偿的算法及大体上加速噪声跟踪。
本发明的实施例是基于如下发现,关于衰落,关注以下参数:衰落域;衰落速度,或更一般地,衰落曲线;衰落的目标水平;衰落的目标频谱形状;及/或背景噪声水平追踪。在此上下文中,实施例是基于现有技术具有显著缺点的发现。
提供针对切换式音频编码系统的在错误隐藏过程中的改良信号衰落的装置及方法。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程序。
实施例实现衰落至舒缓噪声水平。根据实施例,实现在激发域中的共同舒缓噪声水平追踪。不管所使用的核心编码器(acelp/tcx)如何,在突发封包丢失的过程中被设定为目标的舒缓噪声水平将是相同的,且该舒缓噪声水平将总是最新的。共同噪声水平追踪是必要的,还不存在该现有技术。实施例提供切换式编码解码器在突发封包丢失的过程中至类似舒缓噪声的信号的衰落。
此外,实施例实现了总复杂性与具有两个独立噪声水平追踪模块的情况相比将较低,因为可共享功能(prom)及内存。
在实施例中,在语音起作用的过程中,激发域中的水平得到(与时域中的水平得到相比较)提供更多的最小值,因为语音信息的部分由lp系数涵盖。
在acelp的状况下,根据实施例,水平得到发生于激发域中。在tcx的状况下,在实施例中,在时域中得到水平,且作为校正因子应用lpc合成及去加重的增益,以便模型化激发域中的能量水平。追踪激发域中的水平(例如在fdns之前)理论上亦将为可能的,但tcx激发域与acelp激发域之间的水平补偿被认为是相当复杂的。
现有技术并未并有在不同域中的这种共同背景水平追踪。现有技术并不具有在切换式编码解码器系统中的例如在激发域中的这种共同舒缓噪声水平追踪。因此,实施例相比于现有技术是有利的,因为对于现有技术,在突发封包丢失的过程中被设定为目标的舒缓噪声水平可取决于水平受到追踪的先前编码模式(acelp/tcx)而不同;因为在现有技术中,针对每一编码模式为单独的追踪将导致不必要的附加项及额外计算复杂性;及因为在现有技术中,最新舒缓噪声水平在任一核心中归因于最近切换至此核心可能并不可用。
根据一些实施例,在激发域中进行水平追踪,但在时域中进行tcx衰落。通过时域中的衰落,避免tdac的失效,这些失效将导致频迭。当隐藏音调信号分量时,此情形变得备受关注。此外,避免acelp激发域与mdct频谱域之间的水平转换,且因此例如节省了计算资源。由于激发域与时域之间的切换,在激发域与时域之间需要水平调整。通过得到将由lpc合成及预强调引入的增益及使用此增益作为校正因子来使水平在两个域之间转换来解决此情形。
相比之下,现有技术并不进行在激发域中的水平追踪及在时域中的tcx衰落。关于目前先进技术的基于变换的编码解码器,在激发域(针对时域/类似acelp隐藏方法,参见[3gp09a])中抑或在频域(针对如帧重复或噪声替换的频域方法,参见[ls01])中应用衰减因子。在频域中应用衰减因子的现有技术的方法的缺点为在时域中的重迭相加区中将导致频迭。对于被应用不同衰减因子的邻近帧将出现此状况,因为衰落程序使tdac(时域频迭消除)失效。此在隐藏音调信号分量时尤其相关。上文所提及的实施例因此相比于现有技术是有利的。
实施例补偿高通滤波器对lpc合成增益的影响。根据实施例,为了补偿由经高通滤波无声激发引起的lpc分析及强调的非吾人所乐见的增益改变,得到校正因子。此校正因子考虑此非吾人所乐见的增益改变,且修改激发域中的目标舒缓噪声水平以使得在时域中达到正确目标水平。
相比之下,若未将最后良好帧的信号分类为无声,则例如g.718[itu08a]的现有技术将高通滤波器引入至无声激发的信号路径中,如图2中所描绘。由此,现有技术导致非吾人所乐见的副效应,因为后续lpc合成的增益取决于由该高通滤波器更改的信号特性。因为在激发域中追踪及应用背景水平,所以算法依赖于lpc合成增益,lpc合成增益又再次取决于激发信号的特性。换言之,如由现有技术所进行的,归因于高通滤波的激发的信号特性的修改可产生lpc合成的修改(通常减少的)增益。此情形导致错误的输出水平,即使激发水平是正确的。
实施例克服现有技术的这些缺点。
特别地,实施例实现舒缓噪声的适应性频谱形状。与g.718相对比,通过追踪背景噪声的频谱形状及通过在突发封包丢失的过程中应用(衰落至)此形状,先前背景噪声的噪声特性将为匹配的,导致舒缓噪声的合意的噪声特性。此情形避免可通过使用频谱包络引入的频谱形状的突兀的错配,该频谱包络是由脱机训练及/或最后接收的帧的频谱形状得到。
此外,提供用于解码音频信号的装置。装置包含接收接口,其中接收接口用于接收包含音频信号的第一音频信号部分的第一帧,且其中接收接口用于接收包含音频信号的第二音频信号部分的第二帧。
此外,装置包含噪声水平追踪单元,其中噪声水平追踪单元用于取决于第一音频信号部分及第二音频信号部分中的至少一个(此意味:取决于第一音频信号部分及/或第二音频信号部分)判定噪声水平信息,其中噪声水平信息被表示于追踪域中。
此外,装置包含第一重建单元,该第一重建单元用于在多个帧中的第三帧不由接收接口接收的情况下,或在该第三帧由接收接口接收但被损毁的情况下,取决于噪声水平信息而在第一重建域中重建音频信号的第三音频信号部分,其中第一重建域不同于或等于追踪域。
此外,装置包含变换单元,该变换单元用于在多个帧中的第四帧不由接收接口接收的情况下,或在该第四帧由接收接口接收但被损毁的情况下,将噪声水平信息自追踪域变换至第二重建域,其中第二重建域不同于追踪域,且其中第二重建域不同于第一重建域,及
此外,装置包含第二重建单元,该第二重建单元用于在多个帧中的该第四帧不由接收接口接收的情况下,或在该第四帧由接收接口接收但被损毁的情况下,取决于在第二重建域中表示的噪声水平信息而在第二重建域中重建音频信号的第四音频信号部分。
根据一些实施例,追踪域可例如其中追踪域为时域、频谱域、fft域、mdct域或激发域。第一重建域可例如为时域、频谱域、fft域、mdct域或激发域。第二重建域可例如为时域、频谱域、fft域、mdct域或激发域。
在实施例中,追踪域可例如为fft域,第一重建域可例如为时域,及第二重建域可例如为激发域。
在另一实施例中,追踪域可例如为时域,第一重建域可例如为时域,及第二重建域可例如为激发域。
根据实施例,该第一音频信号部分可例如被表示于第一输入域中,及该第二音频信号部分可例如被表示于第二输入域中。变换单元可例如为第二变换单元。装置可例如进一步包含用于将第二音频信号部分或自第二音频信号部分得到的值或信号自第二输入域变换至追踪域以获得第二信号部分信息的第一变换单元。噪声水平追踪单元可例如用于接收在追踪域中表示的第一信号部分信息,其中第一信号部分信息取决于第一音频信号部分,其中噪声水平追踪单元用于接收在追踪域中表示的第二信号部分,且其中噪声水平追踪单元用于取决于在追踪域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号部分信息判定噪声水平信息。
根据实施例,第一输入域可例如为激发域,及第二输入域可例如为mdct域。
在另一实施例中,第一输入域可例如为mdct域,且其中第二输入域可例如为mdct域。
根据实施例,第一重建单元可例如用于通过进行至类似噪声的频谱的第一衰落而重建第三音频信号部分。第二重建单元可例如用于通过进行至类似噪声的频谱的第二衰落及/或ltp增益的第二衰落来重建第四音频信号部分。此外,第一重建单元及第二重建单元可例如用于在相同衰落速度的情况下进行至类似噪声的频谱的第一衰落及第二衰落及/或ltp增益的第二衰落。
在实施例中,装置可例如进一步包含用于取决于第一音频信号部分而判定第一聚合值的第一聚合单元。此外,装置可例如进一步包含用于取决于第二音频信号部分而将第二聚合值判定为自第二音频信号部分得到的值的第二聚合单元。噪声水平追踪单元可例如用于接收第一聚合值作为在追踪域中表示的第一信号部分信息,其中噪声水平追踪单元可例如用于接收第二聚合值作为在追踪域中表示的第二信号部分信息,且其中噪声水平追踪单元用于取决于在追踪域中表示的第一聚合值及取决于在追踪域中表示的第二聚合值而判定噪声水平信息。
根据实施例,第一聚合单元可例如用于判定第一聚合值以使得第一聚合值指示第一音频信号部分或自第一音频信号部分得到的信号的均方根。第二聚合单元用于判定第二聚合值以使得第二聚合值指示第二音频信号部分或自第二音频信号部分得到的信号的均方根。
在实施例中,第一变换单元可例如用于通过对自第二音频信号部分得到的值应用增益值,而将自第二音频信号部分得到的值自第二输入域变换至追踪域。
根据实施例,增益值可例如指示由线性预测编码合成引入的增益,或其中增益值指示由线性预测编码合成及去加重引入的增益。
在实施例中,噪声水平追踪单元可例如用于通过应用最小值统计方法判定噪声水平信息。
根据实施例,噪声水平追踪单元可例如用于将舒缓噪声水平判定为噪声水平信息。重建单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下,或在该第三帧由接收接口接收但被损毁的情况下,取决于噪声水平信息而重建第三音频信号部分。
在实施例中,噪声水平追踪单元可例如用于将舒缓噪声水平判定为自噪声水平频谱得到的噪声水平信息,其中该噪声水平频谱系通过应用最小值统计方法而获得。重建单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下,或在该第三帧由接收接口接收但被损毁的情况下,取决于多个线性预测系数而重建第三音频信号部分。
根据实施例,第一重建单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下,或在该第三帧由接收接口接收但被损毁的情况下,取决于噪声水平信息及取决于第一音频信号部分而重建第三音频信号部分。
在实施例中,第一重建单元可例如用于通过减小或放大第一音频信号部分来重建第三音频信号部分。
根据实施例,第二重建单元可例如用于取决于噪声水平信息及取决于第二音频信号部分重建第四音频信号部分。
在实施例中,第二重建单元可例如用于通过减小或放大第二音频信号部分来重建第四音频信号部分。
根据实施例,装置可例如进一步包含长期预测单元,该长期预测单元包含延迟缓冲器,其中长期预测单元可例如用于取决于第一音频信号部分或第二音频信号部分、取决于储存于延迟缓冲器中的延迟缓冲器输入及取决于长期预测增益而产生处理信号,且其中长期预测单元用于在多个帧中的该第三帧不由接收接口接收的情况下,或在该第三帧由接收接口接收但被损毁的情况下,使长期预测增益朝向零衰落。
在实施例中,长期预测单元可例如用于使长期预测增益朝向零衰落,其中长期预测增益衰落至零的速度取决于衰落因子。
在实施例中,长期预测单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下,或在该第三帧由接收接口接收但被损毁的情况下,通过将产生的处理信号储存于延迟缓冲器中来更新延迟缓冲器输入。
此外,提供用于解码音频信号的方法。该方法包括:
-接收包含音频信号的第一音频信号部分的第一帧,及接收包含音频信号的第二音频信号部分的第二帧。
-取决于第一音频信号部分及第二音频信号部分中的至少一个判定噪声水平信息,其中噪声水平信息被表示于追踪域中。
-在多个帧中的第三帧未被接收的情况下,或在该第三帧被接收但被损毁的情况下,取决于噪声水平信息而在第一重建域中重建音频信号的第三音频信号部分,其中第一重建域不同于或等于追踪域。
-在多个帧中的第四帧未被接收的情况下,或在该第四帧被接收但被损毁的情况下,将噪声水平信息自追踪域变换至第二重建域,其中第二重建域不同于追踪域,且其中第二重建域不同于第一重建域。及:
-在多个帧中的该第四帧未被接收的情况下,或在该第四帧被接收但被损毁的情况下,取决于在第二重建域中表示的噪声水平信息而在第二重建域中重建音频信号的第四音频信号部分。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程序。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的装置。装置包括用于接收一个或多个帧的接收接口、系数产生器及信号重建器。系数产生器用于在一个或多个帧中的当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下,判定由当前帧包含的一个或多个第一音频信号系数,其中该一个或多个第一音频信号系数指示编码音频信号的特性,及判定指示编码音频信号的背景噪声的一个或多个噪声系数。此外,系数产生器用于在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,取决于一个或多个第一音频信号系数及取决于一个或多个噪声系数而产生一个或多个第二音频信号系数。音频信号重建器用于在当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下取决于一个或多个第一音频信号系数而重建重建音频信号的第一部分。此外,音频信号重建器用于在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,取决于一个或多个第二音频信号系数而重建重建音频信号的第二部分。
在一些实施例中,一个或多个第一音频信号系数可例如为编码音频信号的一个或多个线性预测滤波器系数。在一些实施例中,一个或多个第一音频信号系数可例如为编码音频信号的一个或多个线性预测滤波器系数。
根据实施例,一个或多个噪声系数可例如为指示编码音频信号的背景噪声的一个或多个线性预测滤波器系数。在实施例中,一个或多个线性预测滤波器系数可例如表示背景噪声的频谱形状。
在实施例中,系数产生器可例如用于判定一个或多个第二音频信号部分以使得一个或多个第二音频信号部分为重建音频信号的一个或多个线性预测滤波器系数,或使得一个或多个第一音频信号系数为重建音频信号的一个或多个导抗频谱对。
根据实施例,系数产生器可例如用于通过应用如下公式而产生一个或多个第二音频信号系数:
fcurrent[i]=α·flast[i]+(1-α)·ptmean[i]
其中fcurrent[i]指示一个或多个第二音频信号系数中的一个,其中flast[i]指示一个或多个第一音频信号系数中的一个,其中ptmean[i]为一个或多个噪声系数中的一个,其中α为实数,其中0≤α≤1,且其中i为索引。在实施例中,0<a<1。
根据实施例,flast[i]指示编码音频信号的线性预测滤波器系数,且其中fcurrent[i]指示重建音频信号的线性预测滤波器系数。
在实施例中,ptmean[i]可例如指示编码音频信号的背景噪声。
在实施例中,系数产生器可例如用于在一个或多个帧中的当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下,通过判定编码音频信号的噪声频谱来判定一个或多个噪声系数。
根据实施例,系数产生器可例如用于通过对信号频谱使用最小值统计方法来判定背景噪声频谱及通过自背景噪声频谱计算表示背景噪声形状的lpc系数来判定表示背景噪声的lpc系数。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的方法。该方法包括:
-接收一个或多个帧。
-在一个或多个帧中的当前帧被接收的情况下及在所接收的当前帧未被损毁的情况下,判定由当前帧所包含一个或多个第一音频信号系数,其中该一个或多个第一音频信号系数指示编码音频信号的特性,及判定指示编码音频信号的背景噪声的一个或多个噪声系数。
-在当前帧未被接收的情况下或在所接收的当前帧被损毁的情况下,取决于一个或多个第一音频信号系数及取决于一个或多个噪声系数而产生一个或多个第二音频信号系数。
-在当前帧被接收的情况下及在所接收的当前帧未被损毁的情况下,取决于一个或多个第一音频信号系数而重建重建音频信号的第一部分。及:
-在当前帧未被接收的情况下或在所接收的当前帧被损毁的情况,取决于一个或多个第二音频信号系数重建重建音频信号的第二部分。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程序。
具有在衰落的过程中追踪及应用舒缓噪声的频谱形状的共同手段具有若干优点。通过追踪及应用频谱形状以使得频谱形状对于两个核心编码解码器而言可类似地实现,允许了简单的共同方法。celt仅教示频谱域中的能量的逐频带追踪及频谱域中的频谱形状的逐频带形成,此对于celp核心而言是不可能的。
相比之下,在现有技术中,在突发丢失的过程中引入的舒缓噪声的频谱形状是完全静态的抑或部分静态的且部分适应于频谱形状的短期均值(如g.718中所实现[itu08a]),且通常将与在封包丢失之前在信号中的背景噪声不匹配。舒缓噪声特性的此错配可能造成麻烦。根据现有技术,可使用经脱机训练的(静态)背景噪声形状,其针对特定信号而言可听起来是合意的,但针对其他信号而言不太合意,例如,汽车噪声听起来与办公室噪声完全不同。
此外,在现有技术中,可使用对先前接收的帧的频谱形状的短期均值的调适,其可能使信号特性更接近于之前接收的信号,但不一定更接近于背景噪声特性。在现有技术中,在频谱域中逐频带地追踪频谱形状(如celt[iet12]中所实现)并不适用于不仅使用基于mdct域的核心(tcx)而且使用基于acelp的核心的切换式编码解码器。上文所提及的实施例因此相比于现有技术是有利的。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的装置。装置包括用于接收多个帧的接收接口、用于储存解码音频信号的音频信号样本的延迟缓冲器、用于自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本的样本选择器,及用于处理选定音频信号样本以获得重建音频信号的重建音频信号样本的样本处理器。样本选择器用于在当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下,取决于由当前帧所包含的音高滞后信息自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本。此外,样本选择器用于在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,取决于由先前由接收接口所接收的另一帧所包含的音高滞后信息自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本。
根据实施例,样本处理器可例如用于在当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下,通过取决于由当前帧所包含的增益信息重新按比例调整选定音频信号样本而获得重建音频信号样本。此外,样本选择器可例如用于在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,通过取决于由先前由接收接口所接收的该另一帧所包含的增益信息重新按比例调整选定音频信号样本而获得重建音频信号样本。
在实施例中,样本处理器可例如用于在当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下,通过将选定音频信号样本与取决于由当前帧所包含的增益信息的值相乘而获得重建音频信号样本。此外,样本选择器用于在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,通过将选定音频信号样本与取决于由先前由接收接口所接收的该另一帧所包含的增益信息的值相乘而获得重建音频信号样本。
根据实施例,样本处理器可例如用于将重建音频信号样本储存于延迟缓冲器中。
在实施例中,样本处理器可例如用于在由接收接口接收另一帧之前将重建音频信号样本储存于延迟缓冲器中。
根据实施例,样本处理器可例如用于在由接收接口接收另一帧之后将重建音频信号样本储存于延迟缓冲器中。
在实施例中,样本处理器可例如用于取决于增益信息重新按比例调整选定音频信号样本以获得重新按比例调整的音频信号样本及通过组合重新按比例调整的音频信号样本与输入音频信号样本以获得处理音频信号样本。
根据实施例,样本处理器可例如用于在当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下,将指示重新按比例调整的音频信号样本与输入音频信号样本的组合的处理音频信号样本储存于延迟缓冲器中,且不将重新按比例调整的音频信号样本储存于延迟缓冲器中。此外,样本处理器用于在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,将重新按比例调整的音频信号样本储存于延迟缓冲器中且不将处理音频信号样本储存于延迟缓冲器中。
根据另一实施例,样本处理器可例如用于在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,将处理音频信号样本储存于延迟缓冲器中。
在实施例中,样本选择器可例如用于通过取决于修改的增益重新按比例调整选定音频信号样本而获得重建音频信号样本,其中修改的增益系根据如下公式来定义的:
gain=gain_past*damping;
其中gain为修改的增益,其中样本选择器可例如用于在gain已被计算之后将gain_past设定为gain,且其中damping为实值。
根据实施例,样本选择器可例如用于计算修改的增益。
在实施例中,damping可例如根据下式来定义:0≤damping≤1。
根据实施例,在自上一次帧由接收接口接收以来至少预定义数目的帧尚未由接收接口接收的情况下,修改的增益gain可例如被设定为零。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的方法。该方法包括:
-接收多个帧。
-储存解码音频信号的音频信号样本。
-自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本。及:
-处理选定音频信号样本以获得重建音频信号的重建音频信号样本。
在当前帧被接收的情况下及在所接收的当前帧未被损毁的情况下,取决于由当前帧所包含的音高滞后信息而进行自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本的步骤。此外,在当前帧未被接收的情况下或在所接收的当前帧被损毁的情况下,取决于由先前由接收接口所接收的另一帧所包含的音高滞后信息而进行自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本的步骤。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程序。
实施例使用tcxltp(txcltp=经变换编码激发长期预测)。在正常操作的过程中,用合成的信号更新tcxltp内存,该合成的信号含有噪声及重建音调分量。
代替在隐藏的过程中停用tcxltp,可在隐藏的过程中以在最后良好帧中接收的参数继续其正常操作。此保留信号的频谱形状,特别地,由ltp滤波器模型化的那些音调分量。
此外,实施例解耦tcxltp反馈回路。正常tcxltp操作的简单继续会引入额外噪声,因为随着每一更新步骤都会引入来自ltp激发的其他随机产生的噪声。音调分量因此随时间的流逝因添加的噪声而愈来愈失真。
为了克服此情形,可仅反馈更新的tcxltp缓冲器(在不添加噪声的情况下),以便不会以不合需要的随机噪声污染音调信息。
此外,根据实施例,将tcxltp增益衰落至零。
这些实施例是基于如下发现:继续tcxltp有助于短期地保留信号特性,但就长期而言具有以下缺点:在隐藏的过程中播出的信号将包括在丢失之前存在的发声/音调信息。尤其对于干净的语音或有背景噪声的语音,音调或谐波极不可能在极长的时间内极慢地衰减。通过在隐藏的过程中继续tcxltp操作,特别地在解耦ltp内存更新(仅反馈音调分量而不反馈符号加扰部分)的情况下,发声/音调信息将在整个丢失之内保持存在于隐藏的信号中,仅通过整体衰落至舒缓噪声水平而衰减。此外,在突发丢失的过程中应用tcxltp而不随时间的流逝衰减的情况下,不可能在突发封包丢失的过程中达到舒缓噪声包络,因为信号将接着总是并有ltp的发声信息。
因此,使tcxltp增益朝向零衰落,以使得由ltp表示的音调分量将衰落至零,同时信号衰落至背景信号水平及形状,且使得衰落达到所要的频谱背景包络(舒缓噪声)而不并有不合需要的音调分量。
在实施例中,对于ltp增益衰落使用与白噪声衰落相同的衰落速度。
相比之下,在现有技术中,不存在在隐藏的过程中使用ltp的已知的变换编码解码器。对于mpeg-4ltp[iso09],现有技术中并不存在隐藏方法。利用ltp的现有技术的另一基于mdct的编码解码器为celt,但此编码解码器针对前五个帧使用类似acelp的隐藏,且针对所有后续帧产生背景噪声,此举并不利用ltp。不使用tcxltp的现有技术的缺点为用ltp模型化的所有音调分量会突然消失。此外,在现有技术的基于acelp的编码解码器中,在隐藏的过程中延长ltp操作,且使适应性码簿的增益朝向零衰落。关于反馈回路操作,现有技术使用两个方法:反馈整个激发,例如创新及适应性激发的总和(amr-wb);抑或仅反馈经更新的适应性激发,例如音调信号部分(g.718)。上文所提及的实施例克服现有技术的缺点。
附图说明
在下文中,参考附图更详细地描述本发明的实施例,其中:
图1a说明根据实施例的用于对音频信号进行解码的装置;
图1b说明根据另一实施例的用于对音频信号进行解码的装置;
图1c说明根据另一实施例的用于对音频信号进行解码的装置,其中装置进一步包含第一聚合单元及第二聚合单元;
图1d说明根据另一实施例的用于对音频信号进行解码的装置,其中装置更包含长期预测单元,该长期预测单元包含延迟缓冲器;
图2说明g.718的解码器结构;
图3描绘g.722的衰落因子取决于类别信息的情境;
图4展示用于使用线性回归进行振幅预测的方法;
图5说明受约束的能量重迭变换(celt)的突发丢失行为;
图6展示在无错误操作模式的过程中在解码器中的根据实施例的背景噪声水平追踪;
图7说明根据实施例的lpc合成及去加重的增益推导;
图8描绘根据实施例的在封包丢失的过程中的舒缓噪声水平应用;
图9说明根据实施例的在acelp隐藏的过程中的进阶高通增益补偿;
图10描绘根据实施例的在隐藏的过程中的ltp反馈回路的解耦;
图11说明根据实施例的于对编码音频信号进行解码以获得重建音频信号的装置;
图12展示根据另一实施例的用于对编码音频信号进行解码以获得重建音频信号的装置;
图13说明另一实施例的用于对编码音频信号进行解码以获得重建音频信号的装置;及
图14说明另一实施例的用于对编码音频信号进行解码以获得重建音频信号的装置。
具体实施方式
图1a说明根据实施例的用于对音频信号进行解码的装置。
装置包含接收接口110。接收接口用于接收多个帧,其中接收接口110用于接收多个帧中的第一帧,该第一帧包含音频信号的第一音频信号部分,该第一音频信号部分被表示于第一域中。此外,接收接口110用于接收多个帧中的第二帧,该第二帧包含音频信号的第二音频信号部分。
此外,装置包含变换单元120,该变换单元用于将第二音频信号部分或自第二音频信号部分得到的值或信号自第二域变换至追踪域,以获得第二信号部分信息,其中第二域不同于第一域,其中追踪域不同于第二域,且其中追踪域等于或不同于第一域。
此外,装置包含噪声水平追踪单元130,其中噪声水平追踪单元用于接收在追踪域中表示的第一信号部分信息,其中第一信号部分信息取决于第一音频信号部分,其中噪声水平追踪单元用于接收在追踪域中表示的第二信号部分,且其中噪声水平追踪单元用于取决于在追踪域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号部分信息而判定噪声水平信息。
此外,装置包含重建单元,该重建单元用于在多个帧中的第三帧不由接收接口接收而是被损毁的情况下,取决于噪声水平信息而重建音频信号的第三音频信号部分。
关于第一及/或第二音频信号部分,例如第一及/或第二音频信号部分可例如被反馈至一个或多个处理单元(未示出)中以用于产生用于一个或多个扬声器的一个或多个扬声器信号,使得可重新播放由第一及/或第二音频信号部分包含的所接收的声音信息。
然而,此外,第一及第二音频信号部分亦用于隐藏,例如在后续帧并未到达接收器的状况下或在彼后续帧不正确的状况下。
尤其,本发明是基于噪声水平追踪应在共同域(本文中被称作“追踪域”)中进行的发现。追踪域可例如为激发域,例如由lpc(lpc=线性预测系数)或由isp(isp=导抗频谱对)表示信号的域,如amr-wb及amr-wb+中所描述(参见[3gp12a]、[3gp12b]、[3gp09a]、[3gp09b]、[3gp09c])。在单一域中追踪噪声水平尤其具有如下优点:当信号在第一域中的第一表示与第二域中的第二表示之间切换时(例如,当信号表示自acelp切换至tcx或自tcx切换至acelp时),避免了频迭效应。
关于变换单元120,所变换的是第二音频信号部分自身,或自第二音频信号部分得到的信号(例如,已被处理第二音频信号部分以获得得到的信号),或自第二音频信号部分得到的值(例如,已处理第二音频信号部分以获得得到的值)。
关于第一音频信号部分,在一些实施例中,第一音频信号部分可经处理及/或变换至追踪域。
然而,在其他实施例中,第一音频信号部分可已经被表示于追踪域中。
在一些实施例中,第一信号部分信息等同于第一音频信号部分。在其他实施例中,第一信号部分信息为例如取决于第一音频信号部分的聚合值。
现在,首先更详细地考虑至舒缓噪声水平的衰落。
所描述的衰落方法可例如实施于xhe-aac[nmr+12]的低延迟版本(xhe-aac=扩展高效率aac)中,该版本能够在逐帧的基础上在acelp(语音)与mdct(音乐/噪声)编码之间顺畅地切换。
关于在追踪域(例如激发域)中的共同水平追踪,为了在封包丢失的过程中应用至适当舒缓噪声水平的平滑衰落,需要在正常解码程序的过程中识别此舒缓噪声水平。可例如假设类似于背景噪声的噪声水平大部分为舒缓的。因此,可在正常解码的过程中得到及连续更新背景噪声水平。
本发明是基于以下发现:当具有切换式核心编码解码器(例如,acelp及tcx)时,考虑独立于所选择核心编码器的共同背景噪声水平为特别合适的。
图6描绘在无错误操作模式的过程中(例如在正常解码的过程中)在解码器中的根据较佳实施例的背景噪声水平追踪。
追踪自身可例如使用最小值统计方法来执行(参见[mar01])。
此被追踪的背景噪声水平可例如被认为是上文所提及的噪声水平信息。
举例而言,文献“rainermartin的noisepowerspectraldensityestimationbasedonoptimalsmoothingandminimumstatistics(基于优化光滑和最小值统计的噪声功率谱密度估计)(ieeetransactionsonspeechandaudioprocessing(语音处理及音频处理)9(2001),第5期,第504至512页)”中呈现的最小值统计噪声估计[mar01]可用于背景噪声水平追踪。
相应地,在一些实施例中,噪声水平追踪单元130用于通过应用最小值统计方法(例如通过使用[mar01]的最小值统计噪声估计)来判定噪声水平信息。
随后,描述此追踪方法的一些考虑因素及细节。
关于水平追踪,背景应该为类似噪声的。因此较佳地执行在激发域中的水平追踪以避免追踪由lpc取出的前景音调分量。举例而言,acelp噪声填充亦可使用激发域中的背景噪声水平。在激发域中进行追踪的情况下,对背景噪声水平的仅一个单次追踪可起到两个用途,从而减小计算复杂性。在较佳实施例中,在acelp激发域中执行追踪。
图7说明根据实施例的lpc合成及去加重的增益推导。
关于水平得到,水平得到可例如在时域中抑或在激发域中抑或在任何其他合适的域中进行。在用于水平得到及水平追踪的域不同的情况下,可例如需要增益补偿。
在较佳实施例中,在激发域中执行用于acelp的水平得到。因此,并不需要增益补偿。
对于tcx,可例如需要增益补偿以将得到的水平调整至acelp激发域。
在较佳实施例中,用于tcx的水平得到在时域中发生。发现了用于此方法的易管理的增益补偿:如图7中所示得到由lpc合成及去加重引入的增益,且将得到的水平除以此增益。
或者,可在tcx激发域中执行用于tcx的水平得到。然而,tcx激发域与acelp激发域之间的增益补偿被认为太复杂。
因此返回到图1a,在一些实施例中,第一音频信号部分被表示于作为第一域的时域中。变换单元120用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的激发域变换至为追踪域的时域。在这些实施例中,噪声水平追踪单元130用于接收在作为追踪域的时域中表示的第一信号部分信息。此外,噪声水平追踪单元130用于接收在作为追踪域的时域中表示的第二信号部分。
在其他实施例中,第一音频信号部分被表示于作为第一域的激发域中。变换单元120用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的时域变换至为追踪域的激发域。在这些实施例中,噪声水平追踪单元130用于接收在作为追踪域的激发域中表示的第一信号部分信息。此外,噪声水平追踪单元130用于接收在作为追踪域的激发域中表示的第二信号部分。
在实施例中,第一音频信号部分可例如被表示于作为第一域的激发域中,其中噪声水平追踪单元130可例如用于接收第一信号部分信息,其中该第一信号部分信息被表示于为追踪域的fft域中,且其中该第一信号部分信息取决于在激发域中表示的该第一音频信号部分,其中变换单元120可例如用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的时域变换至为追踪域的fft域,且其中噪声水平追踪单元130可例如用于接收在fft域中表示的第二音频信号部分。
图1b说明根据另一实施例的装置。在图1b中,图1a的变换单元120为第一变换单元120,及图1a的重建单元140为第一重建单元140。装置进一步包含第二变换单元121及第二重建单元141。
第二变换单元121用于在多个帧中的第四帧不由接收接口接收的情况下或在该第四帧由接收接口接收但被损毁的情况下,将噪声水平信息自追踪域变换至第二域。
此外,第二重建单元141用于在多个帧中的该第四帧不由接收接口接收的情况下或在该第四帧由接收接口接收但被损毁的情况下,取决于在第二域中表示的噪声水平信息而重建音频信号的第四音频信号部分。
图1c说明根据另一实施例的用于对音频信号进行解码的装置。装置进一步包含用于取决于第一音频信号部分而判定第一聚合值的第一聚合单元150。此外,图1c的装置进一步包含用于取决于第二音频信号部分而将第二聚合值判定为自第二音频信号部分得到的值的第二聚合单元160。在图1c的实施例中,噪声水平追踪单元130用于接收第一聚合值作为在追踪域中表示的第一信号部分信息,其中噪声水平追踪单元130用于接收第二聚合值作为在追踪域中表示的第二信号部分信息。噪声水平追踪单元130用于取决于在追踪域中表示的第一聚合值及取决于在追踪域中表示的第二聚合值而判定噪声水平信息。
在实施例中,第一聚合单元150用于判定第一聚合值以使得第一聚合值指示第一音频信号部分或自第一音频信号部分得到的信号的均方根。此外,第二聚合单元160用于判定第二聚合值以使得第二聚合值指示第二音频信号部分或自第二音频信号部分得到的信号的均方根。
图6说明根据另一实施例的用于对音频信号进行解码的装置。
在图6中,背景水平追踪单元630实施根据图1a的噪声水平追踪单元130。
此外,在图6中,rms单元650(rms=均方根)为第一聚合单元,且rms单元660为第二聚合单元。
根据一些实施例,图1a、图1b及图1c的(第一)变换单元120用于通过对自第二音频信号部分得到的值应用增益值(x)(例如,通过将自第二音频信号部分得到的值除以增益值(x))将自第二音频信号部分得到的值自第二域变换至追踪域。在其他实施例中,可例如乘以增益值。
在一些实施例中,增益值(x)可例如指示由线性预测编码合成引入的增益,或增益值(x)可例如指示由线性预测编码合成及去加重引入的增益。
在图6中,单元622提供指示由线性预测编码合成及去加重引入的增益的值(x)。单元622接着将由第二聚合单元660提供的值(其为自第二音频信号部分得到的值)除以所提供的增益值(x)(例如,通过除以x,抑或通过乘以值1/x)。因此,图6的包含单元621及622的单元620实施图1a、图1b或图1c的第一变换单元。
图6的装置接收具有第一音频信号部分的第一帧,该第一音频信号部分为有声激发及/或无声激发且被表示于追踪域中(在图6中,(acelp)lpc域)。将第一音频信号部分反馈至lpc合成及去加重单元671中以进行处理,从而获得时域第一音频信号部分输出。此外,将第一音频信号部分反馈至rms模块650中以获得指示第一音频信号部分的均方根的第一值。此第一值(第一rms值)被表示于追踪域中。接着将在追踪域中表示的第一rms值反馈至噪声水平追踪单元630中。
此外,图6的装置接收具有第二音频信号部分的第二帧,该第二音频信号部分包含mdct频谱且被表示于mdct域中。噪声填充由噪声填充模块681进行,频域噪声成形由频域噪声成形模块682进行,至时域的变换由imdct/ola模块683(ola=重迭相加)进行,且长期预测由长期预测单元684进行。长期预测单元可例如包含延迟缓冲器(图6中未图示)。
接着将自第二音频信号部分得到的信号反馈至rms模块660中以获得第二值,该第二值指示获得自第二音频信号部分得到的那个信号的均方根。此第二值(第二rms值)仍被表示于时域中。单元620接着将第二rms值自时域变换至追踪域,此处追踪域为(acelp)lpc域。接着将在追踪域中表示的第二rms值反馈至噪声水平追踪单元630中。
在实施例中,在激发域中进行水平追踪,但在时域中进行tcx衰落。
尽管在正常解码的过程中追踪背景噪声水平,但背景噪声水平可例如在封包丢失的过程中用作最后接收的信号平滑地逐水平衰落至的适当舒缓噪声水平的指示符。
得到用于追踪的水平及应用水平衰落大体而言为彼此独立的,且可在不同域中执行。在较佳实施例中,在与水平得到相同的域中执行水平应用,从而导致相同的益处:对于acelp而言,不需要增益补偿,且对于tcx而言,需要关于水平得到的反增益补偿(参见图6)且因此可使用相同增益得到,如由图7所说明。
在下文中,描述根据实施例的高通滤波器对lpc合成增益的影响的补偿。
图8概述此方法。特别地,图8说明在封包丢失的过程中的舒缓噪声水平应用。
在图8中,高通增益滤波器单元643、乘法单元644、衰落单元645、高通滤波器单元646、衰落单元647及组合单元648一起形成第一重建单元。
此外,在图8中,背景水平供应单元631提供噪声水平信息。举例而言,背景水平供应单元631可同样实施为图6的背景水平追踪单元630。
此外,在图8中,lpc合成及去加重增益单元649及乘法单元641一起用于第二变换单元640。
此外,在图8中,衰落单元642表示第二重建单元。
在图8的实施例中,有声及无声激发被单独地衰落:有声激发衰落至零,但无声激发朝向舒缓噪声水平衰落。图8此外描绘高通滤波器,其在除了当信号被分类为无声时之外的所有状况下被引入至无声激发的信号链中以抑制低频分量。
为了将高通滤波器的影响模型化,将在lpc合成及去加重之后的水平在有高通滤波器的情况下计算一次,且在无高通滤波器的情况下计算一次。随后,得到那些两个水平之比且将其用以更改所应用的背景水平。
此情形由图9说明。特别地,图9描绘根据实施例的在acelp隐藏的过程中的进阶高通增益补偿。
代替当前激发信号,仅将简单脉冲用作此计算的输入。这允许复杂性减少,因为脉冲响应快速衰减,且因此可在较短时间范围内执行rms得到。实际上,使用仅一个子帧而非整个帧。
根据实施例,噪声水平追踪单元130用于将舒缓噪声水平判定为噪声水平信息。重建单元140用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三帧由接收接口110接收但被损毁的情况下,取决于噪声水平信息而重建第三音频信号部分。
根据实施例,噪声水平追踪单元130用于将舒缓噪声水平判定为噪声水平信息。重建单元140用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三帧由接收接口110接收但被损毁的情况下,取决于噪声水平信息而重建第三音频信号部分。
在实施例中,噪声水平追踪单元130用于将舒缓噪声水平判定为自噪声水平频谱得到的噪声水平信息,其中该噪声水平频谱系通过应用最小值统计方法而获得的。重建单元140用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三帧由接收接口110接收但被损毁的情况下,取决于多个线性预测系数而重建第三音频信号部分。
在实施例中,(第一及/或第二)重建单元140、141可例如用于在多个帧中的该第三(第四)帧不由接收接口110接收的情况下或在该第三(第四)帧由接收接口110接收但被损毁的情况下,取决于噪声水平信息及取决于第一音频信号部分而重建第三音频信号部分。
根据实施例,(第一及/或第二)重建单元140、141可例如用于通过减小或放大第一音频信号部分来重建第三(或第四)音频信号部分。
图14说明用于对音频信号进行解码的装置。装置包含接收接口110,其中接收接口110用于接收包含音频信号的第一音频信号部分的第一帧,且其中接收接口110用于接收包含音频信号的第二音频信号部分的第二帧。
此外,装置包含噪声水平追踪单元130,其中噪声水平追踪单元130用于取决于第一音频信号部分及第二音频信号部分中的至少一个(此意味:取决于第一音频信号部分及/或第二音频信号部分)判定噪声水平信息,其中噪声水平信息被表示于追踪域中。
此外,装置包含第一重建单元140,该第一重建单元用于在多个帧中的第三帧不由接收接口110接收的情况下或在该第三帧由接收接口110接收但被损毁的情况下,取决于噪声水平信息而在第一重建域中重建音频信号的第三音频信号部分,其中第一重建域不同于或等于追踪域。
此外,装置包含变换单元121,该变换单元用于在多个帧中的第四帧不由接收接口110接收的情况下或在该第四帧由接收接口110接收但被损毁的情况下,将噪声水平信息自追踪域变换至第二重建域,其中第二重建域不同于追踪域,且其中第二重建域不同于第一重建域,及
此外,装置包含第二重建单元141,该第二重建单元用于在多个帧中的该第四帧不由接收接口110接收的情况下或在该第四帧由接收接口110接收但被损毁的情况下,取决于在第二重建域中表示的噪声水平信息而在第二重建域中重建音频信号的第四音频信号部分。
根据一些实施例,追踪域可例如其中追踪域为时域、频谱域、fft域、mdct域或激发域。第一重建域可例如为时域、频谱域、fft域、mdct域或激发域。第二重建域可例如为时域、频谱域、fft域、mdct域或激发域。
在实施例中,追踪域可例如为fft域,第一重建域可例如为时域,及第二重建域可例如为激发域。
在另一实施例中,追踪域可例如为时域,第一重建域可例如为时域,及第二重建域可例如为激发域。
根据实施例,该第一音频信号部分可例如被表示于第一输入域中,及该第二音频信号部分可例如被表示于第二输入域中。变换单元可例如为第二变换单元。装置可例如进一步包含用于将第二音频信号部分或自第二音频信号部分得到的值或信号自第二输入域变换至追踪域以获得第二信号部分信息的第一变换单元。噪声水平追踪单元可例如用于接收在追踪域中表示的第一信号部分信息,其中第一信号部分信息取决于第一音频信号部分,其中噪声水平追踪单元用于接收在追踪域中表示的第二信号部分,且其中噪声水平追踪单元用于取决于在追踪域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号部分信息判定噪声水平信息。
根据实施例,第一输入域可例如为激发域,及第二输入域可例如为mdct域。
在另一实施例中,第一输入域可例如为mdct域,且其中第二输入域可例如为mdct域。
在例如在时域中表示信号的情况下,信号可例如由信号的时域样本表示。或例如,在频谱域中表示信号的情况下,信号可例如由信号的频谱的频谱样本表示。
在实施例中,追踪域可例如为fft域,第一重建域可例如为时域,及第二重建域可例如为激发域。
在另一实施例中,追踪域可例如为时域,第一重建域可例如为时域,及第二重建域可例如为激发域。
在一些实施例中,图14中所说明的单元可例如按针对图1a、图1b、图1c及图1d所描述的配置。
关于特别的实施例,在例如低速率模式中,根据实施例的装置可例如接收acelp帧作为输入,这些acelp帧被表示于激发域中且接着经由lpc合成变换至时域。此外,在低速率模式中,根据实施例的装置可例如接收tcx帧作为输入,这些tcx帧被表示于mdct域中,且接着经由反mdct而变换至时域。
接着在fft域中进行追踪,其中通过进行fft(快速傅立叶变换)自时域信号得到fft信号。可例如通过对于所有频谱线分开进行最小值统计方法来进行追踪以获得舒缓噪声频谱。
接着通过基于舒缓噪声频谱进行水平得到来进行隐藏。基于舒缓噪声频谱进行水平得到。对于fdtcxplc进行至时域中的水平转换。进行在时域中的衰落。针对acelpplc及针对tdtcxplc(类似acelp)进行至激发域中的水平得到。接着进行在激发域中的衰落。
以下清单概述此情形:
低速率:
●输入:
○acelp(激发域->时域,经由lpc合成)
○tcx(mdct域->时域,经由反mdct)
●追踪:
○fft域,经由fft自时域得到
○最小值统计,对于所有频谱线分开进行->舒缓噪声频谱
●隐藏:
○基于舒缓噪声频谱的水平得到
○对于以下plc水平转换至时域中
■fdtcxplc->在时域中衰落
○对于以下plc水平转换至激发域中
■acelpplc
■tdtcxplc(类似acelp)->在激发域中衰落
在例如高速率模式中,其可例如接收tcx帧作为输入,这些tcx帧被表示于mdct域中,且接着经由反mdct而变换至时域。
接着可在时域中进行追踪。可例如通过基于能量水平进行最小值统计方法来进行追踪以获得舒缓噪声水平。
对于隐藏,对于fdtcxplc而言,水平可被照原样使用,且可仅进行时域中的衰落。对于tdtcxplc(类似acelp),进行至激发域的水平转换及在激发域中的衰落。
以下清单概述此情形:
高速率:
●输入:
○tcx(mdct域->时域,经由反mdct)
●追踪:
○时域
○基于能量水平的最小值统计->舒缓噪声水平
●隐藏:
○「照原样」使用水平
■fdtcxplc->在时域中衰落
○对于以下plc水平转换至激发域中
■tdtcxplc(类似acelp)->在激发域中衰落
fft域及mdct域皆为频谱域,而激发域为某种时域。
根据实施例,第一重建单元140可例如用于通过进行至类似噪声的频谱的第一衰落而重建第三音频信号部分。第二重建单元141可例如用于通过进行至类似噪声的频谱的第二衰落及/或ltp增益的第二衰落来重建第四音频信号部分。此外,第一重建单元140及第二重建单元141可例如用于按相同衰落速度进行至类似噪声的频谱的第一衰落及至类似噪声的频谱的第二衰落及/或ltp增益的第二衰落。
现在考虑舒缓噪声的适应性频谱成形。
为了达成在突发封包丢失的过程中至舒缓噪声的适应性成形,作为第一步骤,可进行对表示背景噪声的适当lpc系数的发现。可在起作用语音的过程中使用用于发现背景噪声频谱的最小值统计方法及接着通过使用文献中已知的用于lpc得到的任意算法而自背景噪声频谱计算lpc系数来得到这些lpc系数。例如,一些实施例可直接将背景噪声频谱转换成可直接用于mdct域中的fdns的表示。
至舒缓噪声的衰落可在isf域中进行(在lsf域中亦可适用;lsf线谱频率):
fcurrent[i]=α·flast[i]+(1-α)·ptmean[i]i=0...16(26)
通过将ptmean设定为描述舒缓噪声的适当lp系数。
关于舒缓噪声的上文所描述的适应性频谱成形,由图11说明更一般实施例。
图11说明根据实施例的用于对编码音频信号进行解码以获得重建音频信号的装置。
装置包含用于接收一个或多个帧的接收接口1110、系数产生器1120及信号重建器1130。
系数产生器1120用于在一个或多个帧中的当前帧由接收接口1110接收的情况下及在由接收接口1110接收的当前帧并非被损毁/不正确的情况下,判定由当前帧包含一个或多个第一音频信号系数,其中该一个或多个第一音频信号系数指示编码音频信号的特性,且判定指示编码音频信号的背景噪声的一个或多个噪声系数。此外,系数产生器1120用于在当前帧不由接收接口1110接收的情况下或在由接收接口1110接收的当前帧被损毁/不正确的情况下,取决于一个或多个第一音频信号系数及取决于一个或多个噪声系数而产生一个或多个第二音频信号系数。
音频信号重建器1130用于在当前帧由接收接口1110接收的情况下及在由接收接口1110接收的当前帧未被损毁的情况下,取决于一个或多个第一音频信号系数而重建重建音频信号的第一部分。此外,音频信号重建器1130用于在当前帧不由接收接口1110接收的情况下或在由接收接口1110接收的当前帧被损毁的情况下,取决于一个或多个第二音频信号系数而重建重建音频信号的第二部分。
判定背景噪声在现有技术中是熟知的(参见例如[mar01]:rainermartin的“noisepowerspectraldensityestimationbasedonoptimalsmoothingandminimumstatistics(基于优化光滑和最小值统计的噪声功率谱密度估计)”,ieeetransactionsonspeechandaudioprocessing(语音处理及音频处理)9(2001)第5期,第504至512页),且在实施例中,装置相应地继续进行。
在一些实施例中,一个或多个第一音频信号系数可例如为编码音频信号的一个或多个线性预测滤波器系数。在一些实施例中,一个或多个第一音频信号系数可例如为编码音频信号的一个或多个线性预测滤波器系数。
现有技术中已知如何自线性预测滤波器系数或自导抗频谱对重建音频信号(例如,语音信号)(参见例如,[3gp09c]:speechcodecspeechprocessingfunctions(语音编码解码器的语音处理功能);adaptivemulti-rate-wideband(amrwb)speechcodec(自适应多速率宽带语音编码解码器);transcodingfunctions(编码变换功能),3gppts26.190,第三代合作伙伴计划,2009),且在实施例中,信号重建器相应地继续进行。
根据实施例,一个或多个噪声系数可例如为指示编码音频信号的背景噪声的一个或多个线性预测滤波器系数。在实施例中,一个或多个线性预测滤波器系数可例如表示背景噪声的频谱形状。
在实施例中,系数产生器1120可例如用于判定一个或多个第二音频信号部分以使得一个或多个第二音频信号部分为重建音频信号的一个或多个线性预测滤波器系数,或使得一个或多个第一音频信号系数为重建音频信号的一个或多个导抗频谱对。
根据实施例,系数产生器1120可例如用于通过应用如下公式而产生一个或多个第二音频信号系数:
fcurrent[i]=α·flast[i]+(1-α)·ptmean[i]
其中fcurrent[i]指示一个或多个第二音频信号系数中的一个,其中flast[i]指示一个或多个第一音频信号系数中的一个,其中ptmean[i]为一个或多个噪声系数中的一个,其中α为实数,其中0≤α≤1,且其中i为索引。
根据实施例,flast[i]指示编码音频信号的线性预测滤波器系数,且其中fcurrent[i]指示重建音频信号的线性预测滤波器系数。
在实施例中,ptmean[i]可例如为线性预测滤波器系数,其指示编码音频信号的背景噪声。
根据实施例,系数产生器1120可例如用于产生至少10个第二音频信号系数作为一个或多个第二音频信号系数。
在实施例中,系数产生器1120可例如用于在一个或多个帧中的当前帧由接收接口1110接收的情况下及在由接收接口1110接收的当前帧未被损毁的情况下,通过判定编码音频信号的噪声频谱来判定一个或多个噪声系数。
在下文中,考虑在fdns应用之前将mdct频谱衰落至白噪声。
代替随机修改mdct频率仓的符号(符号加扰),用使用fdns成形的白噪声来填充完整频谱。为了避免频谱特性中的实时改变,应用符号加扰与噪声填充之间的交叉衰落。可如下实现交叉衰落:
其中:
cum_damping为(绝对)衰减因子,其在帧之间减少,自1开始且朝向0减少
x_old为最后接收的帧的频谱
random_sign返回1或-1
noise含有随机向量(白噪声),其被按比例调整以使得其二次均值(rms)类似于最后良好频谱。
术语random_sign()*old_x[i]表征用以使相位随机化且如此避免谐波重复的符号加扰程序。
随后,可在交叉衰落之后执行能量水平的另一归一化以确保总能量不会归因于两个向量的相关而发生偏离。
根据实施例,第一重建单元140可例如用于取决于噪声水平信息及取决于第一音频信号部分重建第三音频信号部分。在特定实施例中,第一重建单元140可例如用于通过减小或放大第一音频信号部分来重建第三音频信号部分。
在一些实施例中,第二重建单元141可例如用于取决于噪声水平信息及取决于第二音频信号部分重建第四音频信号部分。在特别的实施例中,第二重建单元141可例如用于通过减小或放大第二音频信号部分来重建第四音频信号部分。
关于上文所描述的在fdns应用之前mdct频谱至白噪声的衰落,由图12说明更一般的实施例。
图12说明根据实施例的用于对编码音频信号进行解码以获得重建音频信号的装置。
装置包含用于接收包含关于编码音频信号的音频信号频谱的多个音频信号样本的信息的一个或多个帧的接收接口1210,及用于产生重建音频信号的处理器1220。
处理器1220用于在当前帧不由接收接口1210接收的情况下或在当前帧由接收接口1210接收但被损毁的情况下,通过将修改的频谱衰落至目标频谱来产生重建音频信号,其中修改的频谱包含多个修改的信号样本,其中针对修改的频谱的每个修改的信号样本,该修改的信号样本的绝对值等于音频信号频谱的音频信号样本中的一个的绝对值。
此外,处理器1220用于在一个或多个帧中的当前帧由接收接口1210接收的情况下及在由接收接口1210接收的当前帧未被损毁的情况下,不将修改的频谱衰落至目标频谱。
根据实施例,目标频谱为类似噪声的频谱。
在实施例中,类似噪声的频谱表示白噪声。
根据实施例,类似噪声的频谱被成形。
在实施例中,类似噪声的频谱的形状取决于先前接收的信号的音频信号频谱。
根据实施例,取决于音频信号频谱的形状而成形类似噪声的频谱。
在实施例中,处理器1220使用倾斜因子来使类似噪声的频谱成形。
根据实施例,处理器1220使用如下公式:
shaped_noise[i]=noise*power(tilt_factor,i/n)
其中n指示样本的数目,
其中i为索引,
其中0<=i<n,其中tilt_factor>0,
其中power为功率函数。
若tilt_factor小于1,则此情形意味在i增加的情况下的衰减。若tilt_factor大于1,则意味在i增加的情况下的放大。
根据另一实施例,处理器1220可使用如下公式:
shaped_noise[i]=noise*(1+i/(n-1)*(tilt_factor-1))
其中n指示样本的数目,
其中i为索引,其中0<=i<n,
其中tilt_factor>0。
根据实施例,处理器1220用于在当前帧不由接收接口1210接收的情况下或在由接收接口1210接收的当前帧被损毁的情况下,通过改变音频信号频谱的音频信号样本中的一个或多个的符号来产生修改的频谱。
在实施例中,音频信号频谱的音频信号样本中的每一个由实数表示,但不由虚数表示。
根据实施例,音频信号频谱的音频信号样本被表示在修改离散余弦变换域中。
在另一实施例中,音频信号频谱的音频信号样本被表示在经修改离散正弦变换域中。
根据实施例,处理器1220用于通过使用随机或伪随机输出第一值抑或第二值的随机符号函数产生修改的频谱。
在实施例中,处理器1220用于通过随后减小衰减因子而将修改的频谱衰落至目标频谱。
根据实施例,处理器1220用于通过随后增加衰减因子而将修改的频谱衰落至目标频谱。
在实施例中,在当前帧不由接收接口1210接收的情况下或在由接收接口1210接收的当前帧被损毁的情况下,处理器1220用于通过使用如下公式产生重建音频信号:
x[i]=(1-cum_damping)*noise[i]+cum_damping*random_sign()*x_old[i]
其中i为索引,其中x[i]指示重建音频信号的样本,其中cum_damping为衰减因子,其中x_old[i]指示编码音频信号的音频信号频谱的音频信号样本中的一个,其中random_sign()返回1或-1,且其中noise为指示目标频谱的随机向量。
一些实施例继续tcxltp操作。在那些实施例中,在隐藏的过程中用自最后良好帧得到的ltp参数(ltp滞后及ltp增益)继续tcxltp操作。
ltp操作可概述如下:
-基于先前得到的输出对ltp延迟缓冲器进行反馈。
-基于ltp滞后:从ltp延迟缓冲器当中选择被用作ltp贡献以使当前信号成形的适当信号部分。
-使用ltp增益重新按比例调整此ltp贡献。
-将此重新按比例调整的ltp贡献与ltp输入信号相加以产生ltp输出信号。
关于执行ltp延迟缓冲器更新的时间,可考虑不同方法:
作为使用来自最后帧n-1的输出的在帧n中的第一ltp操作。这对在帧n中的ltp处理的过程中待使用的在帧n中的ltp延迟缓冲器进行更新。
作为使用来自当前帧n的输出的在帧n中的最后ltp操作。这对在帧n+1中的ltp处理的过程中待使用的在帧n中的ltp延迟缓冲器进行更新。
在下文中,考虑tcxltp反馈回路的解耦。
解耦tcxltp反馈回路避免了在处于隐藏模式中时在ltp解码器的每一反馈回路的过程中额外噪声的引入(由应用于lpt输入信号的噪声替换产生)。
图10说明此解耦。特别地,图10描绘在隐藏的过程中的ltp反馈回路的解耦(bfi=1)。
图10说明延迟缓冲器1020、样本选择器1030及样本处理器1040(样本处理器1040由虚线指示)。
到执行ltp延迟缓冲器1020更新的时间,一些实施例如下继续进行:
-对于正常操作:按第一ltp操作更新ltp延迟缓冲器1020可能为较佳的,因为通常持续地储存经求和的输出信号。通过此方法,可省略专用缓冲器。
-对于解耦操作:按最后ltp操作更新ltp延迟缓冲器1020可能为较佳的,因为通常仅暂时地储存对信号的ltp贡献。通过此方法,保留了暂时性ltp贡献信号。就实施而言,完全可使此ltp贡献缓冲器为持续性的。
假设在任何状况下使用后一方法(正常操作及隐藏),实施例可例如实施以下情形:
-在正常操作的过程中:在添加至ltp输入信号之后的ltp解码器的时域信号输出被用以对ltp延迟缓冲器进行反馈。
-在隐藏的过程中:在添加至ltp输入信号之前的ltp解码器的时域信号输出被用以对ltp延迟缓冲器进行反馈。
一些实施例使tcxltp增益朝向零衰落。在此实施例中,tcxltp增益可例如按某一信号适应性衰落因子朝向零衰落。例如,此情形可例如根据以下伪码迭代地进行:
gain=gain_past*damping;
[...]
gain_past=gain;
其中:
gain为在当前帧中应用的tcxltp解码器增益;
gain_past为在先前帧中应用的tcxltp解码器增益;
damping为(相对)衰落因子。
图1d说明根据另一实施例的装置,其中装置进一步包含长期预测单元170,该长期预测单元170包含延迟缓冲器180。长期预测单元170用于取决于第二音频信号部分、取决于储存于延迟缓冲器180中的延迟缓冲器输入及取决于长期预测增益而产生处理信号。此外,长期预测单元用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三帧由接收接口110接收但被损毁的情况下,使长期预测增益朝向零衰落。
在其他实施例中(未示出),长期预测单元可例如用于取决于第一音频信号部分、取决于储存于延迟缓冲器中的延迟缓冲器输入及取决于长期预测增益而产生处理信号。
在图1d中,此外,第一重建单元140可例如取决于处理信号产生第三音频信号部分。
在实施例中,长期预测单元170可例如用于使长期预测增益朝向零衰落,其中长期预测增益衰落至零的速度取决于衰落因子。
可选地或另外,长期预测单元170可例如用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三帧由接收接口110接收但被损毁的情况下,通过将所产生的处理信号储存于延迟缓冲器180中来更新延迟缓冲器180输入。
关于tcxltp的上文所描述的使用,由图13说明更一般的实施例。
图13说明用于对编码音频信号进行解码以获得重建音频信号的装置。
装置包含用于接收多个帧的接收接口1310、用于储存解码音频信号的音频信号样本的延迟缓冲器1320、用于自储存于延迟缓冲器1320中的音频信号样本选择多个选定音频信号样本的样本选择器1330及用于处理选定音频信号样本以获得重建音频信号的重建音频信号样本的样本处理器1340。
样本选择器1330用于在当前帧由接收接口1310接收的情况下及在由接收接口1310接收的当前帧未被损毁的情况下,取决于由当前帧包含的音高滞后信息自储存于延迟缓冲器1320中的音频信号样本选择多个选定音频信号样本。此外,样本选择器1330用于在当前帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被损毁的情况下,取决于由先前由接收接口1310所接收的另一帧所包含的音高滞后信息自储存于延迟缓冲器1320中的音频信号样本选择多个选定音频信号样本。
根据实施例,样本处理器1340可例如用于在当前帧由接收接口1310接收的情况下及在由接收接口1310接收的当前帧未被损毁的情况下,通过取决于由当前帧所包含的增益信息重新按比例调整选定音频信号样本而获得重建音频信号样本。此外,样本选择器1330可例如用于在当前帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被损毁的情况下,通过取决于由先前由接收接口1310所接收的该另一帧所包含的增益信息重新按比例调整选定音频信号样本而获得重建音频信号样本。
在实施例中,样本处理器1340可例如用于在当前帧由接收接口1310接收的情况下及在由接收接口1310接收的当前帧未被损毁的情况下,通过将选定音频信号样本与取决于由当前帧所包含的增益信息的值相乘而获得重建音频信号样本。此外,样本选择器1330用于在当前帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被损毁的情况下,通过将选定音频信号样本与取决于由先前由接收接口1310所接收的该另一帧所包含的增益信息的值相乘而获得重建音频信号样本。
根据实施例,样本处理器1340可例如用于将重建音频信号样本储存于延迟缓冲器1320中。
在实施例中,样本处理器1340可例如用于在由接收接口1310接收另一帧之前将重建音频信号样本储存于延迟缓冲器1320中。
根据实施例,样本处理器1340可例如用于在由接收接口1310接收另一帧之后将重建音频信号样本储存于延迟缓冲器1320中。
在实施例中,样本处理器1340可例如用于取决于增益信息来重新按比例调整选定音频信号样本以获得重新按比例调整的音频信号样本,及通过组合重新按比例调整的音频信号样本与输入音频信号样本以获得处理音频信号样本。
根据实施例,样本处理器1340可例如用于在当前帧由接收接口1310接收的情况下及在由接收接口1310接收的当前帧未被损毁的情况下,将指示重新按比例调整的音频信号样本与输入音频信号样本的组合的处理音频信号样本储存于延迟缓冲器1320中,且不将重新按比例调整的音频信号样本储存于延迟缓冲器1320中。此外,样本处理器1340用于在当前帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被损毁的情况下,将重新按比例调整的音频信号样本储存于延迟缓冲器1320中,且不将处理音频信号样本储存于延迟缓冲器1320中。
根据另一实施例,样本处理器1340可例如用于在当前帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被损毁的情况下,将处理音频信号样本储存于延迟缓冲器1320中。
在实施例中,样本选择器1330可例如用于通过取决于修改的增益重新按比例调整选定音频信号样本而获得重建音频信号样本,其中修改的增益是根据如下公式来定义的:
gain=gain_past*damping;
其中gain为修改的增益,其中样本选择器1330可例如用于在gain已被计算之后将gain_past设定为gain,且其中damping为实数。
根据实施例,样本选择器1330可例如用于计算修改的增益。
在实施例中,damping可例如根据下式来定义:0<damping<1。
根据实施例,在自上一帧由接收接口1310接收以来至少预定义数目的帧尚未由接收接口1310接收的情况下,修改的增益gain可例如被设定为零。
在下文中,考虑衰落速度。存在应用某种衰落的若干隐藏模块。虽然此衰落的速度可能在那些模块中被不同地进行选择,但对于一个核心(acelp或tcx)的所有隐藏模块使用相同衰落速度系有益的。举例而言:
对于acelp,特别地,针对适应性码簿(通过更改增益)及/或针对创新码簿信号(通过更改增益),应使用相同衰落速度。
又,对于tcx,特别地,针对时域信号及/或针对ltp增益(衰落至零)及/或针对lpc加权(衰落至一)及/或针对lp系数(衰落至背景频谱形状)及/或针对至白噪声的交叉衰落,应使用相同衰落速度。
针对acelp及tcx亦使用相同衰落速度可能进一步为较佳的,但归因于核心的不同性质,亦可能选择使用不同衰落速度。
此衰落速度可能为静态的,但较佳地适应于信号特性。举例而言,衰落速度可例如取决于lpc稳定性因子(tcx)及/或分类及/或连续丢失帧的数目。
衰落速度可例如取决于衰减因子来判定,该衰减因子可能被绝对地或相对地给出,且亦可能在某一衰落的过程中随时间的流逝而改变。
在实施例中,对于ltp增益衰落使用与白噪声衰落相同的衰落速度。
已提供用于产生如上文所描述的舒缓噪声信号的装置、方法及计算机程序。
根据本发明的实施例,提供一种用于对编码音频信号进行解码以获得重建音频信号的装置,其中装置包括:接收接口1210,用于接收包括关于编码音频信号的音频信号频谱的多个音频信号样本的信息的一个或多个帧,以及处理器1220,用于产生重建音频信号,其中处理器1220用于,在当前帧不由接收接口1210接收的情况下或者在当前帧由接收接口1210接收但被损毁的情况下,通过将修改的频谱衰落至目标频谱来产生重建音频信号,其中修改的频谱包括多个修改的信号样本,其中对于修改的频谱的每个修改的信号样本,修改的信号样本的绝对值等于音频信号频谱的音频信号样本中的一个的绝对值,且其中处理器1220用于,在一个或多个帧中的当前帧由接收接口1210接收的情况下以及由接收接口1210接收的当前帧未被损毁的情况下,不将修改的频谱衰落至目标频谱。
根据本发明的实施例,其中目标频谱为类似噪声的频谱。
根据本发明的实施例,其中类似噪声的频谱表示白噪声。
根据本发明的实施例,其中类似噪声的频谱被成形。
根据本发明的实施例,其中类似噪声的频谱的形状取决于先前接收的信号的音频信号频谱。
根据本发明的实施例,其中类似噪声的频谱取决于音频信号频谱的形状而成形。
根据本发明的实施例,其中处理器1220使用倾斜因子使类似噪声的频谱成形。
根据本发明的实施例,其中处理器1220使用以下公式:
shaped_noise[i]=noise*power(tilt_factor,i/n)
其中n指示样本的数目,
其中i为索引,
其中0<=i<n,其中tilt_factor>0,且
其中power为功率函数。
根据本发明的实施例,其中处理器1220用于在当前帧不由接收接口1210接收的情况下或由接收接口1210接收的当前帧被损毁的情况下,通过改变音频信号频谱的音频信号样本中的一个或多个的符号来产生修改的频谱。
根据本发明的实施例,其中音频信号频谱的音频信号样本中的每个由实数但不由虚数表示。
根据本发明的实施例,其中音频信号频谱的音频信号样本被表示在修改离散余弦变换域中。
根据本发明的实施例,其中音频信号频谱的音频信号样本被表示在修改离散正弦变换域中。
根据本发明的实施例,其中处理器1220用于使用随机或伪随机输出第一值或第二值的随机符号函数产生修改的频谱。
根据本发明的实施例,其中处理器1220用于通过随后减小衰减因子而将修改的频谱衰落至目标频谱。
根据本发明的实施例,其中处理器1220用于随后增加衰减因子而将修改的频谱衰落至目标频谱。
根据本发明的实施例,其中在当前帧不由接收接口1210接收的情况下或在当前帧由接收接口1210接收但被损毁的情况下,处理器1220用于通过使用以下公式产生重建音频信号:
x[i]=(1-cum_damping)*noise[i]+cum_damping*random_sign()*x_old[i]
其中i为索引,
其中x[i]指示重建音频信号的样本,
其中cum_damping为衰减因子,
其中x_old[i]指示编码音频信号的音频信号频谱的音频信号样本中的一个,
其中random_sign()返回1或-1,且
其中noise为指示目标频谱的随机向量。
根据本发明的实施例,其中按比例调整随机向量noise,以使得其二次均值类似于已经由接收接口1210接收的帧中的一个所包括的编码音频信号的频谱的二次均值。
根据本发明的实施例,其中处理器1220用于通过使用随机向量产生重建音频信号,其中随机向量被按比例调整以使得其二次均值类似于已经由接收接口1210接收的帧中的一个所包括的编码音频信号的频谱的二次均值。
根据本发明的实施例,提供一种用于对编码音频信号进行解码以获得重建音频信号的方法,其中方法包括:接收包括关于编码音频信号的音频信号频谱的多个音频信号样本的信息的一个或多个帧,以及产生重建音频信号,其中在当前帧未被接收的情况下或在当前帧被接收但被损毁的情况下,通过将修改的频谱衰落至目标频谱来产生重建音频信号,其中修改的频谱包括多个修改的信号样本,其中对于修改的频谱的每个修改的信号样本,修改的信号样本的绝对值等于音频信号频谱的音频信号样本中的一个的绝对值,且其中在一个或多个帧中的当前帧被接收的情况下及在所接收的当前帧未被损毁的情况下,通过不将修改的频谱衰落至目标频谱来产生重建音频信号。
根据本发明的实施例,提供一种计算机程序,用于在执行于计算机或信号处理器上时实施本发明实施例提供的用于对编码音频信号进行解码以获得重建音频信号的方法。
尽管已在装置的上下文中描述一些方面,但显然,这些方面亦表示对应方法的描述,其中区块或器件对应于方法步骤或方法步骤的特征。类似地,在方法步骤的上下文中所描述的方面亦表示对应装置的对应区块或项目或特征的描述。
本发明的分解的信号可储存于数字储存媒体上或可在诸如无线传输媒体的传输媒体或诸如因特网的有线传输媒体上传输。
取决于某些实施要求,本发明的实施例可以硬件或软件实施。实施可使用数字储存媒体来执行,该媒体例如软性磁盘、dvd、cd、rom、prom、eprom、eeprom或闪存,该媒体上储存有电子可读控制信号,这些电子可读控制信号与可编程计算机系统协作(或能够协作)以使得执行各个方法。
根据本发明的一些实施例包含具有电子可读控制信号的非暂时性数据载体,这些电子可读控制信号能够与可编程计算机系统协作,使得执行本文中所描述的方法中的一个。
大体而言,本发明的实施例可实施为具有程序代码的计算机程序产品,当计算机程序产品执行于计算机上时,程序代码操作性地用于执行这些方法中的一个。程序代码可(例如)储存于机器可读载体上。
其他实施例包含储存于机器可读载体上的用于执行本文中所描述的方法中的一个的计算机程序。
换言之,因此,本发明方法的实施例为具有程序代码的计算机程序,当计算机程序执行于计算机上时,该程序代码用于执行本文中所描述的方法中的一个。
因此,本发明方法的另一实施例为包含记录于其上的,用于执行本文中所描述的方法中的一个的计算机程序的数据载体(或数字储存媒体,或计算机可读媒体)。
因此,本发明方法的另一实施例为表示用于执行本文中所描述的方法中的一个的计算机程序的数据串流或信号序列。数据串流或信号序列可例如用于经由数据通信连接(例如,经由因特网)而传送。
另一实施例包含用于或经调适以执行本文中所描述的方法中的一个的处理构件,例如,计算机或可编程逻辑器件。
另一实施例包含安装有用于执行本文中所描述的方法中的一个的计算机程序的计算机。
在一些实施例中,可编程逻辑器件(例如,场可编程门阵列)可用于执行本文中所描述的方法的功能性中的一些或所有。在一些实施例中,场可编程门阵列可与微处理器协作,以便执行本文中所描述的方法中的一个。大体而言,较佳地由任何硬件装置执行这些方法。
上文所描述的实施例仅仅说明本发明的原理。应理解,对本文中所描述的配置及细节的修改及变型对本领域技术人员而言将是显而易见。因此,仅意欲由待决专利的权利要求的范围限制,而不由通过本文的实施例的描述及解释而提出的特定细节限制。
参考文献
[3gp09a]3gpp;technicalspecificationgroupservicesandsystemaspects,extendedadaptivemulti-rate-wideband(amr-wb+)codec,3gppts26.290,3rdgenerationpartnershipproject,2009.
[3gp09b]extendedadaptivemulti-rate-wideband(amr-wb+)codec;floating-pointansi-ccode,3gppts26.304,3rdgenerationpartnershipproject,2009.
[3gp09c]speechcodecspeechprocessingfunctions;adaptivemulti-rate-wideband(amrwb)speechcodec;transcodingfunctions,3gppts26.190,3rdgenerationpartnershipproject,2009.
[3gp12a]adaptivemulti-rate(amr)speechcodec;errorconcealmentoflostframes(release11),3gppts26.091,3rdgenerationpartnershipproject,sep2012.
[3gp12b]adaptivemulti-rate(amr)speechcodec;transcodingfunctions(release11),3gppts26.090,3rdgenerationpartnershipproject,sep2012.[3gp12c],ansi-ccodefortheadaptivemulti-rate-wideband(amr-wb)speechcodec,3gppts26.173,3rdgenerationpartnershipproject,sep2012.
[3gp12d]ansi-ccodeforthefloating-pointadaptivemulti-rate(amr)speechcodec(release11),3gppts26.104,3rdgenerationpartnershipproject,sep2012.
[3gp12e]generalaudiocodecaudioprocessingfunctions;enhancedaacplusgeneralaudiocodec;additionaldecodertools(release11),3gppts26.402,3rdgenerationpartnershipproject,sep2012.
[3gp12f]speechcodecspeechprocessingfunctions;adaptivemulti-rate-wideband(amr-wb)speechcodec;ansi-ccode,3gppts26.204,3rdgenerationpartnershipproject,2012.
[3gp12g]speechcodecspeechprocessingfunctions;adaptivemulti-rate-wideband(amr-wb)speechcodec;errorconcealmentoferroneousorlostframes,3gppts26.191,3rdgenerationpartnershipproject,sep2012.
[bjh06]i.batina,j.jensen,andr.heusdens,noisepowerspectrumestimationforspeechenhancementusinganautoregressivemodelforspeechpowerspectrumdynamics,inproc.ieeeint.conf.acoust.,speech,signalprocess.3(2006),1064–1067.
[bp06]a.borowiczanda.petrovsky,minimacontrollednoiseestimationforklt-basedspeechenhancement,cd-rom,2006,italy,florence.
[coh03]i.cohen,noisespectrumestimationinadverseenvironments:improvedminimacontrolledrecursiveaveraging,ieeetrans.speechaudioprocess.11(2003),no.5,466–475.
[cpk08]choongsangcho,naminpark,andhongkookkim,apacketlossconcealmentalgorithmrobusttoburstpacketlossforcelp-typespeechcoders,tech.report,koreaenectronicstechnologyinstitute,gwanginstituteofscienceandtechnology,2008,the23rdinternationaltechnicalconferenceoncircuits/systems,computersandcommunications(itc-cscc2008).
[dob95]g.doblinger,computationallyefficientspeechenhancementbyspectralminimatrackinginsubbands,inproc.eurospeech(1995),1513–1516.
[ebu10]ebu/etsijtcbroadcast,digitalaudiobroadcasting(dab);transportofadvancedaudiocoding(aac)audio,etsits102563,europeanbroadcastingunion,may2010.
[ebu12]digitalradiomondiale(drm);systemspecification,etsies201980,etsi,jun2012.
[eh08]jans.erkelensandrichardsheusdens,trackingofnonstationarynoisebasedondata-drivenrecursivenoisepowerestimation,audio,speech,andlanguageprocessing,ieeetransactionson16(2008),no.6,1112–1123.
[em84]y.ephraimandd.malah,speechenhancementusingaminimummean-squareerrorshort-timespectralamplitudeestimator,ieeetrans.acoustics,speechandsignalprocessing32(1984),no.6,1109–1121.
[em85]speechenhancementusingaminimummean-squareerrorlog-spectralamplitudeestimator,ieeetrans.acoustics,speechandsignalprocessing33(1985),443–445.
[gan05]s.gannot,speechenhancement:applicationofthekalmanfilterintheestimate-maximize(emframework),springer,2005.
[he95]h.g.hirschandc.ehrlicher,noiseestimationtechniquesforrobustspeechrecognition,proc.ieeeint.conf.acoustics,speech,signalprocessing,no.pp.153-156,ieee,1995.
[hhj10]richardc.hendriks,richardheusdens,andjesperjensen,mmsebasednoisepsdtrackingwithlowcomplexity,acousticsspeechandsignalprocessing(icassp),2010ieeeinternationalconferenceon,mar2010,pp.4266–4269.
[hjh08]richardc.hendriks,jesperjensen,andrichardheusdens,noisetrackingusingdftdomainsubspacedecompositions,ieeetrans.audio,speech,lang.process.16(2008),no.3,541–553.
[iet12]ietf,definitionoftheopusaudiocodec,tech.reportrfc6716,internetengineeringtaskforce,sep2012.
[iso09]iso/iecjtc1/sc29/wg11,informationtechnology–codingofaudio-visualobjects–part3:audio,iso/iecis14496-3,internationalorganizationforstandardization,2009.
[itu03]itu-t,widebandcodingofspeechataround16kbit/susingadaptivemulti-ratewideband(amr-wb),recommendationitu-tg.722.2,telecommunicationstandardizationsectorofitu,jul2003.
[itu05]low-complexitycodingat24and32kbit/sforhands-freeoperationinsystemswithlowframeloss,recommendationitu-tg.722.1,telecommunicationstandardizationsectorofitu,may2005.
[itu06a]g.722appendixiii:ahigh-complexityalgorithmforpacketlossconcealmentforg.722,itu-trecommendation,itu-t,nov2006.
[itu06b]g.729.1:g.729-basedembeddedvariablebit-ratecoder:an8-32kbit/sscalablewidebandcoderbitstreaminteroperablewithg.729,recommendationitu-tg.729.1,telecommunicationstandardizationsectorofitu,may2006.
[itu07]g.722appendixiv:alow-complexityalgorithmforpacketlossconcealmentwithg.722,itu-trecommendation,itu-t,aug2007.
[itu08a]g.718:frameerrorrobustnarrow-bandandwidebandembeddedvariablebit-ratecodingofspeechandaudiofrom8-32kbit/s,recommendationitu-tg.718,telecommunicationstandardizationsectorofitu,jun2008.
[itu08b]g.719:low-complexity,full-bandaudiocodingforhigh-quality,conversationalapplications,recommendationitu-tg.719,telecommunicationstandardizationsectorofitu,jun2008.
[itu12]g.729:codingofspeechat8kbit/susingconjugate-structurealgebraic-code-excitedlinearprediction(cs-acelp),recommendationitu-tg.729,telecommunicationstandardizationsectorofitu,june2012.
[ls01]pierrelauberandralphsperschneider,errorconcealmentforcompresseddigitalaudio,audioengineeringsocietyconvention111,no.5460,sep2001.
[mar01]rainermartin,noisepowerspectraldensityestimationbasedonoptimalsmoothingandminimumstatistics,ieeetransactionsonspeechandaudioprocessing9(2001),no.5,504–512.
[mar03]statisticalmethodsfortheenhancementofnoisyspeech,internationalworkshoponacousticechoandnoisecontrol(iwaenc2003),technicaluniversityofbraunschweig,sep2003.
[mc99]r.martinandr.cox,newspeechenhancementtechniquesforlowbitratespeechcoding,inproc.ieeeworkshoponspeechcoding(1999),165–167.
[mca99]d.malah,r.v.cox,anda.j.accardi,trackingspeech-presenceuncertaintytoimprovespeechenhancementinnonstationarynoiseenvironments,proc.ieeeint.conf.onacousticsspeechandsignalprocessing(1999),789–792.
[mep01]nikolausmeine,berndedler,andheikopurnhagen,errorprotectionandconcealmentforhilnmpeg-4parametricaudiocoding,audioengineeringsocietyconvention110,no.5300,may2001.
[mpc89]y.mahieux,j.-p.petit,anda.charbonnier,transformcodingofaudiosignalsusingcorrelationbetweensuccessivetransformblocks,acoustics,speech,andsignalprocessing,1989.icassp-89.,1989internationalconferenceon,1989,pp.2021–2024vol.3.
[nmr+12]maxneuendorf,markusmultrus,nikolausrettelbach,guillaumefuchs,julienrobilliard,jérémielecomte,stephanwilde,stefanbayer,saschadisch,christianhelmrich,rochlefebvre,philippegournay,brunobessette,jimmylapierre,kristopfer
[pkj+11]naminpark,hongkookkim,minajung,seongrolee,andseunghochoi,burstpacketlossconcealmentusingmultiplecodebooksandcomfortnoiseforcelp-typespeechcodersinwirelesssensornetworks,sensors11(2011),5323–5336.
[qd03]schuylerquackenbushandpeterf.driessen,errormitigationinmpeg-4audiopacketcommunicationsystems,audioengineeringsocietyconvention115,no.5981,oct2003.
[rl06]s.rangachariandp.c.loizou,anoise-estimationalgorithmforhighlynon-stationaryenvironments,speechcommun.48(2006),220–231.
[sfb00]v.stahl,a.fischer,andr.bippus,quantilebasednoiseestimationforspectralsubtractionandwienerfiltering,inproc.ieeeint.conf.acoust.,speechandsignalprocess.(2000),1875–1878.
[ss98]j.sohnandw.sung,avoiceactivitydetectoremployingsoftdecisionbasednoisespectrumadaptation,proc.ieeeint.conf.acoustics,speech,signalprocessing,no.pp.365-368,ieee,1998.
[yu09]rongshanyu,alow-complexitynoiseestimationalgorithmbasedonsmoothingofnoisepowerestimationandestimationbiascorrection,acoustics,speechandsignalprocessing,2009.icassp2009.ieeeinternationalconferenceon,apr2009,pp.4421–4424.
- 还没有人留言评论。精彩留言会获得点赞!