一种基于卷积神经网络的变压器故障声音识别方法与流程
本发明涉及的是一种基于卷积神经网络的变压器故障声音识别方法,属于变压器故障在线监测领域。
背景技术:
现代社会中大多数生产生活都伴随着电力的使用,一旦供电中断将给国民经济和人民生活带来重大的损失。减少停电事故,保持电力系统安全可靠运行是生产生活活动顺利进行的重要基础。电力系统中任何一个关键设备的停摆都将引起生产中断,影响人民生活活动的展开。变压器作为升降压,换流等角色广泛的出现在电网的各个角落,是电网中最重要的设备之一,它的可靠性与稳定性直接关系到电网能否安全,长效,经济地运行。据研究调查表明,每次停电每丢失的1千瓦时负荷都将造成约47元的经济损失,一次中小规模的停电就可能造成几十万甚至上百万的损失,供电企业也须为此向用户支付赔偿。如果停电范围涉及医院等重要设施还可能引起人员伤亡和重大事故。在此基础上,可以说变压器故障监测技术的每一点提高在其广泛的应用下都会有巨大的意义,相比出现故障带来的经济损失和可能的人员伤亡,在故障识别上投入无疑划算得多。
随着电力系统向特高压,大容量发展,变压器发生故障的概率与危害性也大大增加。在长期高强度的运行下,变压器可能出现的故障部位和故障种类都呈现多样化,包括缺相,部件松动,绝缘油过热,分接开关故障,局部放电,绕组故障等等。变压器自投运起就不可避免地开始老化,随着时间推移,绝缘层的绝缘性能逐渐变弱,轴承等部件开始磨损,各项指标逐渐劣化,各种因素综合起来最终就会引起故障。相当数量的故障类别如部件松动,异物落入等在线路上并没有明显的电信号改变,传统的保护装置也难以检测,但这些故障在早中期未造成严重后果前就会发出一定的声音信号,如果能捕捉这些信号并识别,将大大提高变压器运行的稳定性和安全性。因此提出了一种基于卷积神经网络的变压器故障声音识别方法,通过将声音信号预处理后提取mfcc特征构成声谱图,可以使用卷积神经网络实现良好的识别。
技术实现要素:
为解决上述问题,本发明提出一种基于卷积神经网络的变压器故障声音识别方法。
本发明是通过以下技术方案实现的:基于卷积神经网络的变压器故障声音识别方法其中:使用静音剪切,分帧,z-score标准化等手段对音频进行预处理,在预处理后提取mfcc特征参数构成声谱图,将声谱图送入卷积神经网络进行识别并得到识别结果
一种基于卷积神经网络的变压器故障声音识别方法,其特点在于:包括如下步骤:
s1.对音频信号进行预处理,包括采用静音剪切处理非平稳信号、对音频信号统一采用分帧处理、z-score标准化处理;
s2.对预处理后的音频信号提取相同形状的mfcc特征参数作为特征矩阵,将特征矩阵增加一维,形成单声道的声谱图;
s3.将声谱图送入训练后卷积神经网络进行识别并得到识别结果。
所述步骤s1中采用静音剪切处理非平稳信号,具体是:
①采用变压器及环境声音,计算各音频片段的平均能量ev,公式如下:
其中:d(n)表示第n个采样点,ev为截取的包括m个采样点的音频片段的平均能量
②计算整段音频的平均能量emean,公式如下:
其中:l表示音频采样总点数;
③当音频片段的平均能量ev小于整段音频的平均能量emean的40%时,则该音频片段作为无效噪声段进行删除。
所述步骤s1中z-score标准化处理,公式如下:
其中:μ为每一帧的均值,σ为每一帧的方差,x表示各个采样点的原始值。
所述的训练后卷积神经网络是由变压器故障声音与各类环境噪声经过上述处理变成声谱图输入卷积神经网络训练而成。
所述的卷积神经网络的结构为一层卷积层,两层全连接层与一层输出层,卷积层包括n个滤波器,全连接层均为n个神经元,输出层神经元个数与要分类的声音类别对应相同。
与现有技术技术相比,本发明具有的有益效果是:
1)摆脱了对电气巡检人员个人经验的依赖,能够在线自动识别变压器的故障声音,大大提高了反应速度,降低了人工成本;
2)减轻巡检负担,有效监控变压器的工作状态,提升工作安全性。
3)基于声音的识别技术可以覆盖一些传统保护装置无法监测的故障类型。
附图说明
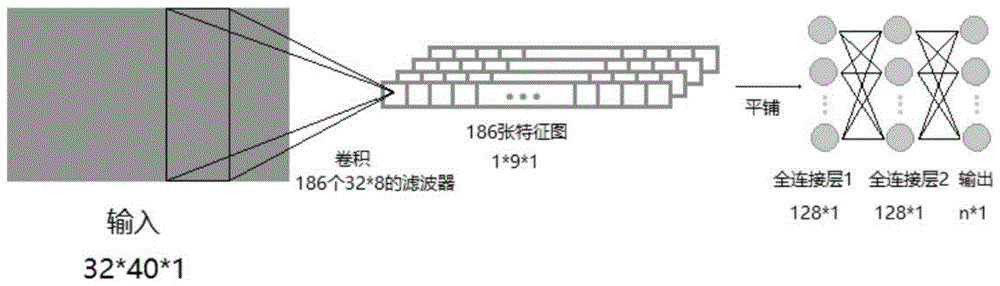
图1为卷积神经网络的结构图;
图2为基于卷积神经网络的变压器故障声音识别流程图。
具体实施方式
下面结合实施例和附图对本发明作详细说明:本实施例在以本发明方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
请参阅图2,图2为基于卷积神经网络的变压器故障声音识别流程图,如图所示,一种基于卷积神经网络的变压器故障声音识别方法,包括如下步骤:
使用录音笔收录变压器声音,网络收集环境噪声,对其中的非平稳信号首先使用静音剪切处理,删去无效噪声段:
其中:l表示音频总采样点数,d(n)表示第n个采样点,emean为整段音频的平均能量,ev为截取的包括m个采样点的音频片段的平均能量,当其小于总的平均能量的40%时就将该段删去。
对音频文件以帧长335ms,帧移45ms进行分帧,对每一帧进行z-score标准化:
其中:μ为每一帧的均值,σ为每一帧的方差,x表示各个采样点的原始值,经标准化后变为x*。
之后mfcc内部以25ms帧长,10ms帧移进行fft,设置一组40个三角滤波器并返回40个倒谱值,每帧提取形状为(32,40)的特征矩阵,将特征矩阵增加一维,形状变为(32,40,1),由此形成声谱图结构,最后一维对应普通图片的rgb通道,不同之处仅在于声谱图是单颜色通道。
卷积神经网络的结构为一层卷积层,两层全连接层与一层输出层,卷积层包括186个(32,8)的滤波器,全连接层均为128个神经元。输出层神经元个数与要分类的声音类别对应相同。激活函数使用relu,对输出层以外的所有神经元作dropout处理,概率为0.5,结构如图1所示。使用声谱图训练和测试卷积神经网络。
将变压器故障声音与各类环境噪声经过上述处理变成声谱图后供卷积神经网络作训练,收录要识别的声音后经过相同的处理输入训练好的卷积神经网络即可得到输出层神经元的输出,输出层神经元个数与做训练的声音类别对应相同,其中哪个输出层神经元的输出最大即说明输入样本属于哪一类。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!