一种基于音频技术的肉鸡呼吸道疾病自动识别装置的制作方法
本发明涉及音频技术、无线传感网、数据转换、数据可视化、语音识别等技术领域,是多学科交叉共融的结果,是一种结合了音频技术的无线传感网在智慧农业领域的发明应用。
背景技术:
目前,在国家政策的正确引导下,我国肉鸡养殖行业正处于蓬勃发展期,生产技术突飞猛进。据统计,我国鸡肉年总产量已超过1000万吨,仅次于美国,是世界第二大鸡肉生产国。因此,肉鸡的健康养殖将直接关系到整个社会的食品安全。
但是,在养殖企业的集约化生产过程中任存在着诸多亟待解决的问题。企业过分的追求利润,不断增大肉鸡饲养密集度,不愿投入资金改善肉鸡养殖环境,加上管理不善,致使鸡舍环境恶劣,出现大量病死鸡,其中呼吸道疾病是影响肉鸡生长的几类主要疾病之一。肉鸡在患有呼吸道疾病时,会出现咳嗽、甩鼻、打喷嚏等异常行为。现阶段判断肉鸡是否患有呼吸道疾病,主要是通过饲养员夜间巡舍时听音识别,这种方式不仅浪费人力,效率低下,而且存在较强的主观性,很容易形成错误判断,不能及时处理患病肉鸡。因此,本专利提出的基于音频技术的自动监测装置有更好的应用前景,是未来肉鸡养殖行业发展的趋势。
cn109243470a公开了一种基于音频技术的肉鸡咳嗽监测方法,位于采音室的拾音器将实时采集其发声信息,并通过数据线传输至音频存储单元保存;pc上位机定时读取存储单元里的音频数据,并对读取的音频数据进行预处理;通过人工选取音频中鸡只咳嗽状态的时间段,对时间段内的肉鸡咳嗽声数据进行特征提取,采用svm分类器训练决策模型;肉鸡声音在经过模型分类后若识别为咳嗽且达到程序设定的预警值时,pc端将发出肉鸡异常警告。本发明通过对肉鸡的咳嗽声音进行分析实现肉鸡呼吸道疾病自动识别报警,为肉鸡呼吸系统疾病的早期发现及处理提供了自动化判断方法,一定意义上实现了肉鸡自动化养殖。
但是,根据动医专家研究,肉鸡在发生呼吸道疾病时,除了咳嗽声还伴有啰音(呼噜声),该专利并未针对两种异常声音做出综合的研究,属不严谨、不准确。
技术实现要素:
技术方案:
一种基于音频技术的肉鸡呼吸道疾病自动识别装置,它包括音频采集装置、传输装置、处理装置、预警装置,音频采集装置采集整个鸡舍的实时音频数据,音频数据基于传输装置输入处理装置,处理装置发送处理结果至预警装置;其中:处理装置执行以下步骤:
s1、筛选整理采集到的音频数据并分类标记:采用人工试听方法对样本辨别干扰声、肉鸡异常声音,并进行样本分类标记;其中,肉鸡异常声音包括肉鸡的呼噜声和咳嗽声;
s2、对采集到的音频数据进行预处理;
s3、采用基于小波变换的mfcc特征优化方法对预处理输出数据进行特征参数提取;
s4、分别建立干扰声、呼噜声、咳嗽声的隐马尔可夫hmm模型,分别对特征参数进行训练、识别,选择输出概率最大的模型对应的声音分类作为输出结果。
优选的,它还执行步骤s5、呼吸道疾病的预测:
i5min内发出的异常声音数量为[0,50)次,判定肉鸡情况正常;
ii5min内发出的异常声音数量为[51,100)次,判定肉鸡患有慢性呼吸道疾病;
iii5min内发出的异常声音数量为[101,150)次,判定肉鸡患有传染性支气管炎;
iv5min内发出的异常声音数量为[151,200)次,判定肉鸡患有新城疫;
v5min内发出的异常声音数量为[201,+∞)次,判定肉鸡患有禽流感。
优选的,音频采集装置采用cc3200lp+cc3200bp套件组合成音频采集节点的形式进行音频数据采集,多个音频采集节点均匀分布在鸡舍环境内;音频录制参数为采样精度16位、采样频率48khz,保存格式wav;在鸡舍关灯的时间段内,进行音频数据采集。
优选的,传输装置为路由器建局域网进行无线传输。
优选的,s2中,所述预处理包括预加重、分帧加窗、滤波去噪、端点检测,具体的:
预加重:
使用数字滤波器实现预加重,预加重处理输入和输出的关系为:
h(z)=1-αz-1,0.9≤α≤1.0
式中:α为预加重系数;
分帧加窗:
选用汉明窗,表达式如下:
式中:n为窗长;
滤波去噪:
采用改进后的mmse谱减法进行去噪,得到最终的信号估计器为:
式中,
端点检测:
采用基于倒谱距离的端点检测算法,对于不同的信号s0(n)和s1(n),倒谱距离dc表示为:
c0(n)和c1(n)分别对应s0(w)和s1(w)的倒谱系数;
然后逐帧计算dc值,并利用判决门限进行判断当前帧是否为有声帧,采用动态门限的方式进行判决,设定两个门限t1和t2:
ti=dcepsil×ki,i=1,2
式中:dcepsil为背景噪声倒谱距离的估计值,ki分别为两个门限的系数,并且使k2>k1,以保证t2大于t1,k1取1.5,k2取2.0;
采用自适应的方法对向量c0和dcepsil进行更新,更新方法如下:
c0=γc0+(1-γ)c1
dcepsil=γdcepsil+(1-γ)dc
式中:γ为更新系数,本文取0.9;同时为了防止截取声音段过长,减少误判的情况发生,设定有效声音段最大长度lmax=3630ms。
优选的,s3中,利用小波变换替换mfcc提取过程中的傅里叶变换,对帧数据进行顺序处理如下:离散小波变换、分层fft、频率合成、mei滤波、取对数、dct,获得mfcc特征;其中,离散小波变换通过下式进行:
式中:a0是尺度因子,b0是位移因子,ψ*(t)是小波函数的共轭形式。
选取贡献率高的mfcc特征分量并乘以对应的贡献率作为特征参数,贡献率使用fisher准则进行评价,fisher准则的f比定义为:
式中:rfisher为特征分量的f比;σwithin为特征分量的类内离散度,即同一类声音特征分量方差的平均值;σbetween为类间离散度,即不同类声音分量均值的方差;其中,σwithin和σbetween通过下式获得:
式中:k为mfcc特征的维数;μk为所有声音类别的特征参数第k个分量的均值;
优选的,s4中,采用隐马尔可夫模型hmm对干扰声、呼噜声、咳嗽声进行训练、识别,训练时采用十折交叉验证的方法验证模型。
优选的,预警装置采用的是32位的arm-jq8900-16p语音模块,采样率为48khz,该模块选用的是soc方案,集成了一个专门针对音频解码的adsp,采用硬解码的方式,更加保证了系统的稳定性和音质,能够根据pc端处理识别的结果,并结合疾病预测标准实现的语音播报预警功能。
本发明的有益效果
(1)本系统对肉鸡呼吸道异常声音进行实时监测,多节点设计的群智感知方法可以保证数据来源的可靠性、完整性,wifi传输介质可以实现远程控制、灵活布局,web端软件可以实时、直观的反应肉鸡呼吸道异常声监测情况,方便鸡场管理人员及时发现异常并作出应对。
(2)采用融合了mfcc特征参数两种优化方法的hmm模型,可以显著的提高肉鸡异常声音的识别率,进而判断出肉鸡的呼吸道疾病,提高肉鸡生产率。
(3)通过使用肉鸡呼吸道疾病自动监测系统,不仅节省人力成本,而且提高了识别效率,避免时有人为误判情况的发生,为肉鸡生产提供一种科学、准确的方法,促进智慧农业发展。
附图说明
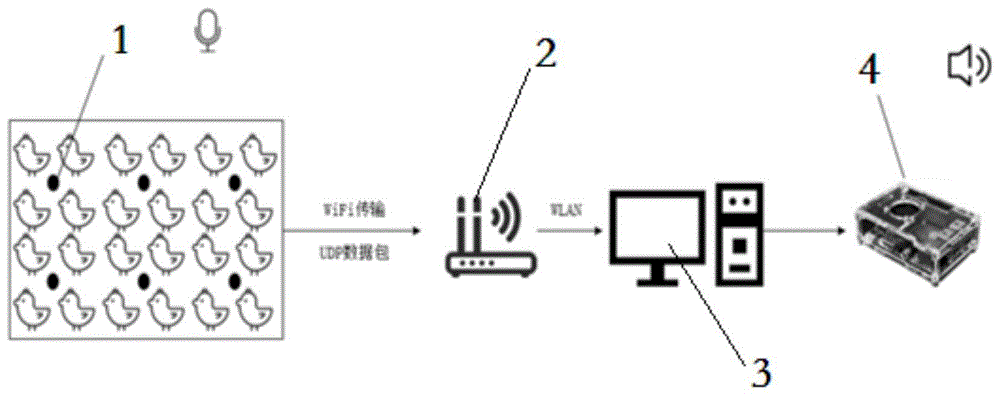
图1为本发明的系统结构图
图2为倒谱提取流程图
图3为端点检测流程图
图4为wmfcc特征提取过程图
图5为hmm识别分类流程图
图6为实施例中wmfcc混合参数f比
图7为实施例中wmfcc混合参数cdf比
具体实施方式
下面结合实施例对本发明作进一步说明,但本发明的保护范围不限于此:
结合图1,一种基于音频技术的肉鸡呼吸道疾病自动识别装置,它包括音频采集装置1(采用cc3200lp+cc3200bp套件组合成音频采集节点,多个音频采集节点均匀分布在鸡舍环境内;音频录制参数为采样精度16位、采样频率48kh,保存格式wav)、传输装置2(路由器建局域网进行无线传输)、处理装置3、预警装置4(32位的arm-jq8900-16p语音模块,采样率为48khz,该模块选用的是soc方案,集成了一个专门针对音频解码的adsp,采用硬解码的方式,更加保证了系统的稳定性和音质,能够根据pc端处理识别的结果,并结合疾病预测标准实现的语音播报预警功能),音频采集装置1采集整个鸡舍的实时音频数据,音频数据基于传输装置2输入处理装置3,处理装置3发送处理结果至预警装置4;其中:处理装置3执行以下步骤:
s1、筛选整理采集到的音频数据并分类标记:采用人工试听方法对样本辨别干扰声、肉鸡异常声音,并进行样本分类标记;其中,肉鸡异常声音包括肉鸡的呼噜声和咳嗽声;
s2、对采集到的音频数据进行预处理;所述预处理包括预加重、分帧加窗、滤波去噪、端点检测。
本申请之所以采取频域分析,未选用时域分析,是因为:
时域分析包括短时能量ei、teo能量eteo、短时平均过零率zn三个声音信号时域特征,其中:
短时能量ei通过下式获得:
式中,xi(n)为声音样本经分帧处理后的第i帧,n为声音帧的第n个点;n为一帧的长度;
teo(teagerenergyoperator)能量也能很好地表征声信号幅度随时间的变化情况。teager能量算子在连续域可以定义为信号x(t)的一阶和二阶导数的函数,即:
ψ[x(t)]=(x′(t))2-x(t)x″(t)
短时平均过零率zn通过下式获得:
式中,xn(m)表示第m帧声信号;sgn[x]是符号函数:
频域分析中:首先用离散傅里叶变换求得声信号的频谱,通过下式获得第m帧声信号频率范围fb至fe的功率wm:
式中,fr为频率分辨率;pi为频率i处的功率谱密度。
申请人研究5000hz以下频谱图。分析结论为:鸣叫声(干扰声的一种)频率主要集中在400hz和850hz两处;咳嗽和呼噜声频率分布则是比较宽泛,在低于3000hz部分都有分布。咳嗽声的频率峰值位于1300hz处,整体分布驼峰状。呼噜声的频率峰值位于900hz处,集中分布在600hz至1700hz部分。分析结果是:时域特征下不能很好的区分三种声音;而通过频域分析,发现干扰声、呼噜声、咳嗽声有着较大的差异,可以用来作区分。
在频域分析中,对采集到的音频数据进行预处理;所述预处理包括预加重、分帧加窗、滤波去噪、端点检测。
其中,滤波去噪方案的原理如下:
在采集肉鸡呼吸道异常声音过程中,因为通风设备、控温控湿设备的使用,使得采集到的音频数据中存在干扰信息,会对后续的端点检测、特征提取等工作造成影响,进而影响最终的识别率。因此需要进行滤波去噪的处理,减少声信号中的干扰频率波段。在众多语音增强的方法中,谱减法是最常用的方法,这种方法简单快速,实用性很强。不过传统的谱减法存在“音乐噪声”的缺点,因此使用改进后的mmse谱减法,能够在均方误差意义下最优地选择减法参数。谱减法的基本公式为:
y(i)=x(i)+n(i)
式中:y(i)为带噪音的声音;x(i)为噪声。对其进行傅里叶变换后得到的频域表示为:
yω=xω+nω
因为背景噪声为加性噪声,所以x(i)与n(i)相互独立,可得谱减法的通用形式:
式中:
式中:δp对于给定的p为常数(p等于1/2/3时,δp分别对应0.2146/0.5/0.7055);ξp(ω)是先验信噪比,对应信号能量与噪声能量的比值,近似于:
式中:η为平滑系数(设为0.96),
若纯净语音信号估计谱增强后的频谱值小于μy(ω),则将其设为
式中:μ为频谱下限常数,本文设为0.12。
端点检测方案的原理如下:
本设计中,在对声音进行预加重和分帧加窗后,进行端点检测。端点检测主要是用来准确定位一段音频数据中有声段的起始位和终止位,从而将剩余的大量无用干扰信息删除,以起到缩短后续信号处理时间、提高算法效率和准确率的作用。相比基于声音时域特征的短时能量、短时平均过零率的端点检测算法,本专利采用基于倒谱距离的端点检测算法。倒谱在定义上是对信号傅里叶变换后经过对数运算后再进行傅里叶反变换得到的谱,他的计算流程如图2所示。
由图2得到如下公式:
式中:c(n)表示倒谱系数,且c(n)=c(-n),为实数。其中:
根据parseval定理,对于两个不同信号s0(n)和s1(n),其倒谱距离表示为:
式中:c0(n)和c1(n)分别对应s0(w)和s1(w)的倒谱系数。上式可以近似为:
之后逐帧计算dc值,并利用判决门限进行判断当前帧是否为有声帧,采用动态门限的方式进行判决,设定两个门限t1和t2:
ti=dcepsil×ki,i=1,2
式中:dcepsil为背景噪声倒谱距离的估计值,ki分别为两个门限的系数,并且使k2>k1,以保证t2大于t1,本文经过多次实验k1取1.5,k2取2.0。同时因为背景噪声变化无规律,因此采用自适应的方法对向量c0和dcepsil进行更新,更新方法如下:
c0=γc0+(1-γ)c1
dcepsil=γdcepsil+(1-γ)dc
式中:γ为更新系数。同时为了防止截取声音段过长,减少误判的情况发生,设定有效声音段最大长度lmax=3630ms。确定有声段起点和终点的具体过程如图3所示。
s3、利用小波变换替换mfcc提取过程中的傅里叶变换。
传统的mfcc特征使用傅里叶变换对信号进行时频域转换,但是傅里叶本身是一种将信号当做稳定信号处理的方法,而声音信号是一种典型的非平稳信号,因此,使用傅里叶变换进行mfcc参数提取本身就是存在一定的缺陷的,其会使声音的细节特征模糊。
针对此mfcc特征的缺陷,本专利将从两个方面对mfcc特征进行优化、融合:
(一)是利用小波变换替换mfcc提取过程中的傅里叶变换,从提取方式上进行优化。将优化后的mfcc命名为wmfcc特征。
一维连续小波变换定义如下:
式中:a是尺度因子;b是位移因子,ψ(t)是小波函数,ψ∧*(t)是它的共轭形式。连续小波变换中a和b两个因子都是连续变换的,这是利用计算机无法做到的,因此在此基础上通过对这两个因子进行离散化处理即可得到离散小波变换,其定义为:
使用小波变换提取mfcc特征的过程如图4所示。
(二)是利用特征选择的方法选取贡献率高的特征分量作为特征参数,并将其乘以对应的贡献率,从而提高贡献率高的特征分量在分类时的重要性,降低贡献率低的特征分量的影响,以从排除冗余信息的角度对mfcc特征进行优化。
目前常使用fisher准则评价mfcc特征各分量参数对模型分类识别的贡献率,fisher准则的f比定义为:
式中:rfisher为特征分量的f比;σwithin为特征分量的类内离散度,即同一类声音特征分量方差的平均值;σbetween为类间离散度,即不同类声音分量均值的方差。σwithin和σbetween定义如下:
式中:k为mfcc特征的维数;μk为所有声音类别的特征参数第k个分量的均值;
cdf比定义为:
式中:d为相关距离,ffisher为特征分量的f比。
对本文声音样本的48维mfcc混合特征参数利用fisher准则和基于相关距离的fisher准则分别计算f比和cdf比。
通过实验发现,小波变换优化mfcc参数在45维时获得最优的综合识别率,因此说明该特征具有很深的优化潜力。所以本文将两者结合起来,试验两者融合后改进的mfcc参数对模型的优化能力。选用48维wmfcc特征进行测试。计算的每维特征分量的贡献率如图6-图7所示。
从图7可以发现,贡献率较高的特征分量主要集中在25维至32维。通过统计cdf比,仍然分别选取f比与cdf比前一半特征分量进行测试,试验结果如表4-8所示。
表4-8不同wmfcc混合特征的声音识别试验结果
tab.4-8testresultsofdifferentdimensionsofwmfcc+wmfcc′+wmfcc″
通过表4-8,可以看出将两种识别方法融合使用时,识别率的提升非常理想。在使用cdf比的24维wmfcc混合参数时相比48维wmfcc混合特征参数时有4.8%的识别率提升。在使用cdf比加权的wmfcc混合特征时总识别率最高,可以达到93.8%,对比48维wmfcc特征,识别率提升了8.8%,对比wmfcc最优识别率提升6.6%,对比48维mfcc特征参数,识别率提升了12.5%,对比mfcc最优识别率提升11.2%。这种识别率已经可以满足实际使用需要。
s4、结合图5,分别建立干扰声、呼噜声、咳嗽声的隐马尔可夫hmm模型,分别对mfcc特征参数进行训练(训练时采用十折交叉验证的方法验证模型)、识别,选择输出概率最大的模型对应的声音分类作为输出结果;
在对声信号进行特征提取后,需要对肉鸡呼吸道异常声音识别的hmm进行训练建模。在训练前需要确定声音隐状态数n,以及模型参数[a,b,π]初始化:根据先验知识将隐藏状态数设为5;hmm模型中的初始状态概率和状态转移矩阵的初始值对模型的训练影响不大,因此使用随机生成的非0数;参数b则使用高斯混合分布来描述,高斯分布数量为3,并使用训练数据的全局均值和方差对其进行初始化。
训练时使用十折交叉验证的方法验证模型,为咳嗽声、呼噜声和干扰声分别建立一个hmm模型。对于一个待识别声音样本,肉鸡呼吸道异常声音识别的hmm模型的分类策略是通过计算模型得分来实现的,即判断当前输入声信号在各模型的输出概率,然后选择概率最大的模型作为分类结果。肉鸡呼吸道异常声音识别模型hmm识别分类流程如图5所示。
为了优化hmm模型对肉鸡咳嗽声、呼噜声、干扰声等三种异常声音的识别能力,本专利将基于小波变换优化的mfcc参数和基于特征加权优化的mfcc参数进行融合,可以显著提升识别效果。
s5、呼吸道疾病的预测:
常见的肉鸡呼吸道疾病分为细菌性疾病和病毒性疾病。其中,细菌性疾病中的慢性呼吸道疾病,病毒性疾病中的传染性支气管炎、新城疫、禽流感,病发症状皆有咳嗽声和呼噜声(啰音),而不同病发出异常声程度是不同的。
因此,本专利将根据肉鸡异常声发生的急促度(单位时间内发出的异常声次数,这里采用单位:次/min)来作为肉鸡是否患有某种呼吸道疾病预测的标准。为了准确反映肉鸡发出异常声的急促度,本专利将对5min内的异常声次数进行统计并取平均值,然后根据得到的平均每分钟发出异常声次数,也就是急促度,来预测肉鸡是否患有某种呼吸道疾病。最终,系统将根据预测判断的结果,进行语音播报提醒。优选的,报警装置采用的是32位的arm-jq8900-16p语音模块,采样率为48khz,该模块选用的是soc方案,集成了一个专门针对音频解码的adsp,采用硬解码的方式,更加保证了系统的稳定性和音质,能够根据pc端处理识别的结果,并结合疾病预测标准实现的语音播报预警功能。
具体的预测标准为:如果在5min内发出异常声(包括咳嗽声、呼噜声)的急促度低于10次/分钟,则预测为情况正常;急促度在11~20次/分钟,则预测为慢性呼吸道疾病;急促度在21~30次/分钟,则预测为传染性支气管炎;急促度在31~40次/分钟,则预测为新城疫;急促度高于41次/分钟,则预测为禽流感。
最终得到结论为:
i5min内发出的异常声音数量为[0,50)次,判定肉鸡情况正常;
ii5min内发出的异常声音数量为[51,100)次,判定肉鸡患有慢性呼吸道疾病;
iii5min内发出的异常声音数量为[101,150)次,判定肉鸡患有传染性支气管炎;
iv5min内发出的异常声音数量为[151,200)次,判定肉鸡患有新城疫;
v5min内发出的异常声音数量为[201,+∞)次,判定肉鸡患有禽流感。
本文中所描述的具体实施例仅仅是对本发明精神做举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!