一种基于模式识别的英语单词发音学习系统的制作方法
本发明涉及一种基于模式识别的英语单词发音学习系统,属于计算机类模式识别具体应用的技术领域。
背景技术:
随着经济发展的国际化,英语在经济生活中的作用越来越重要。大学作为教授专业英语的重要阵地,教学方法和手段的创新显得尤为重要。由于英语教学是一项系统工程,单词是该系统的根基之一,不同学生的单词基础和学习能力也有或多或少的差距,尤其是在实际的单词教学实践中,学生的单词发音存在不规范、纠正困难等问题,若采用常规教学方法,很难使全部学生达到既定的教学目标,学生的学习效果更多的取决于教师的教学强度与学生自身吸收能力之间的协调程度。如何定量评价学生的单词发音水平及其学习能力,成为英语教学的关键之一。
而随着人工智能技术的发展,给英语教学带来了新的契机。例如,现在已经存在多种app软件,实现用户发音的识别和评价功能,经过使用后用户反馈其评价效果和评价效率都不具有突出的技术优势。
模式识别技术主要由数据获取、预处理、特征提取和选择、分类器设计和分类决策等组成,主要应用于图像分析与处理、语音识别、声音分类、通信、计算机辅助诊断、数据挖掘等。因此,怎样有效利用模式识别在语音识别、声音分类、数据挖掘等方面的优势,将之应用于英语单词发音水平及学习能力评估系统的研发中,成为本技术领域新的研究方向。
通过采集学生的口语发音的相关数据,定量评估其英语单词发音水平和学习能力,对于提升英语教学水平和学生学习效率有重要意义。
技术实现要素:
针对现有技术的不足,本发明公开一种基于模式识别的英语单词发音学习系统。
本发明通过对大量的标准发音进行建库、分析,可以对采集到的学习者单词发音进行处理,并利用模式识别技术确定学习者发音的缺陷,最终对所述的发音缺陷和不足进行技术量化。上述量化结果还可以为后续的教学研究提供基础客观依据。
具体来说,本发明所要解决的技术问题是提供一种基于模式识别的英语发音学习系统,用以采集和分析学生的口语发音的相关数据,为定量评估学生的英语口语水平和学习能力提供有效工具。
本发明的技术方案如下:
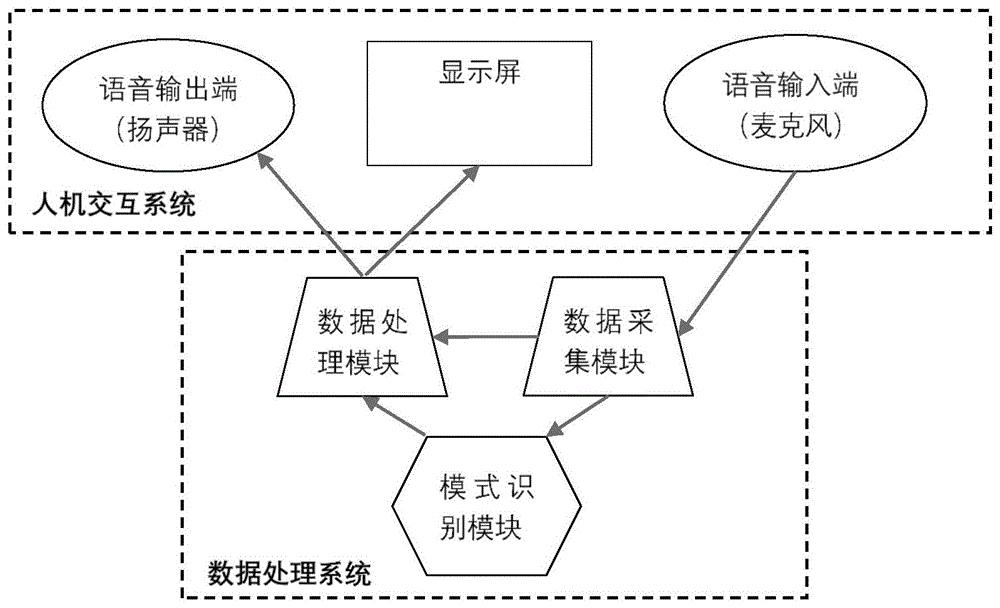
一种基于模式识别的英语单词发音学习系统,其特征在于,包括:人机交互系统和数据处理系统;
所述人机交互系统用于采集用户的英语单词语音、向用户发出交互指令,“例如:请跟读上述单词”;还用于通过显示屏进行文字互动;所述人机交互系统包括:语音输入端、语音输出端和显示屏。
根据本发明优选的,在所述数据处理模块中对采集到的英语单词语音数据进行预处理的方法包括降噪处理步骤和关键参数提取步骤:
其中,进行降噪处理用于过滤环境噪声,依据人声频率范围80-1000hz,采用滤波方式进行降噪处理,提取有效的人声,其具体方法如下:
1)将采集到的英语单词语音数据转化为声波时域信号a(t),并对所述时域信号a(t)进行傅里叶变换,转换为频域信号f(f);如图4所示;
2)根据公式80hz=f(low)<f(f)<f(high)=1000hz筛选有效人声,即f(valid),其中,f(low)代表有效人声频率下限,f(high)代表有效人声频率上限;
3)将f(valid)进行傅里叶变换,得到有效人声信号的时域图,时域范围为t0~tt;如图3(b)所示;
其中,所述关键参数提取为:在有效人声信号,即包含时域图a(valid)和频域图f(valid)的基础上,提取至少重音、音调、语速三个关键声音参数信息,具体步骤如下:
4)重音,缩写为zy:定义a(t)为t时刻声波振幅,若存在a(t)<△a,其中,t∈[t1,t2],△a根据设备误差选取,一般小于1db,且t2-t1>0.01s,则重音在t2时刻;否则,所述英语单词语音的重音在t=0时刻;
5)音调,缩写为yd:此处音调是指单词发音的音准程度,至少包括两个参数进行表征,为声波幅值随时间的变化值amax(t)和单词发音的频率曲线f(t);首先,取a(valid)时域图中每个时刻对应的峰值,得到amax(t),即声波幅值随时间的变化;其次,以△t为步长,将时域图分为若干片段,利用傅里叶变换,得到片段△ti的平均频率fi,则若干个fi组成单词发音的频率曲线f(t);其中,优选的,所述△t=10ms;amax(t)和f(t)如图5、图6所示;
6)语速,缩写为ys:根据所述关键参数提取中步骤4)的判断,若英语单词重音在t=0时刻,则语速为人声有效信号的时长tt;若单词重音在t=t2时刻,则语速参数有两个,分别为:t1-t0和tt-t2;
在所述数据处理系统内置有英语单词的标准声音所对应的参数信息也分别是:重音、音调和语速。
根据本发明优选的,在所述数据处理模块中所述模式识别方法,将所述步骤4)-6)提取到的参数信息与系统内置的标准声音所对应的参数信息进行模式识别分析,最终确定用户发音与标准英语单词发音的契合度,给出评估得分,具体方法如下:
7)建立系统内置标准:录制标准英语单词发音数据,由专业英语老师根据四级、六级和专业八级词汇表录制;按所述步骤1)-6)对录制标准英语单词发音数据进行处理和关键参数提取;建立标准数据库,将英语单词、英语单词的标准发音、所述标准英语单词对应的参数信息储存于系统的数据库中;
8)归一化处理:将重音、音调和语速三个参数进行归一化处理,具体方法如下:
i.重音的归一化处理:
ii.音调的归一化处理:
iii.语速的归一化处理:
按照步骤i-iii,将系统内置标准的参数信息进行归一化处理,得到标准的zyt、ydt和yst,它们与单词、原始读音和原始参数信息一起储存于系统数据库中;
9)对采集到的人声信息,通过步骤1-6后,提取对应的关键参数信息后,按照所述步骤i-iii对其进行归一化处理,得到相应的zyr、ydr和ysr:
10)契合度计算:计算用户实际英语单词发音对应参数信息与标准英语单词发音参数信息之间的偏差分别如下,
针对重音参数:该参数属于定值参数,t=0时,需满足zyr=zyt,即重音偏差ezy=0;当t≠0时,重音偏差ezy=|zyr-zyt|;
针对音调参数:以△t=10ms为步长,将图4、图5所示曲线(系统内置标准曲线和实际人声曲线)均等分,对每一个微元进行音调偏差计算,则音调总偏差:
针对语速参数:该参数属于定值参数,t=0时,需满足ysr=yst=1,即语速偏差e=0;当t≠0时,语速偏差eys=max[|ys1r-ys1t|,|ys2r-ys2t|];
其中,ys1r和ys2r分别指重音在t=t2时刻时,实际人声对应的语速归一化处理结果ys1和ys2;ys1t和ys2t分别指重音在t=t2时刻时,系统内置标准对应的语速归一化处理结果ys1和ys2;
10)评估判断:对用户的英语单词发音进行评估得分,
在所述系统内预置评估等级,该评估等级与英语单词难度等级库相对应,例如,本发明按照英语等级考试四、六、八级单词库分别对应为:
英语等级考试四级词汇表对应“难度等级1级”;
英语等级考试六级词汇表对应“难度等级2级”;
英语等级考试八级词汇表对应“难度等级3级”;
当然,本发明并不限于采用上述方式确定英语单词难度等级,例如,还可先将英语单词按发音习惯或者音节数量进行难度分类等等,此划分难度的方法并不属于本发明所要保护的内容,但是针对不同英语单词难度等级数据库均可采用本发明所述的系统及方法进行高效训练用户的英语单词发音;
若评估得分未达到对应的预置评估等级,则系统自动降低难度等级对用户重新进行测试评估得分,直到达到系统预置评估等级。
根据本发明优选的,所述预置评估等级的标准如下:
本发明的技术优势在于:
1、本发明针对英语发音的特点,利用计算机技术提取单词发音的重音、音调和语速特征参数,并通过归一化处理、模式识别等方法分析实际人声发音与系统内置标准之间的契合程度。本发明具有单词发音特征识别率高、计算机处理效率高等优势。
2、本发明利用人机交互系统,实现集“采集人声、实时对比分析和评估判断”为一体的英语单词发音学习系统,可以高效率的评估学生英语发音的准确性并给出量化评估结果,有利于学生有针对性的对发音进行练习、改进和完善。
附图说明
图1为本发明基于模式识别的英语单词发音学习系统组成示意图;
图2为本发明基于模式识别的英语单词发音学习系统工作原理示意图;
图3是本发明所述系统采集到的原始信号和降噪处理后信号时域图;
图4是本发明所述原始信号的频域图;
图5是本发明声波幅值随时间的变化曲线;
图6是本发明平均频率随时间的变化曲线;
图7是本发明系统内置单词discovery声波幅值随时间的变化曲线;
图8是本发明系统内置单词discovery平均频率随时间的变化曲线。
具体实施方式
下面结合实施例和说明书附图对本发明做详细的说明,但不限于此。
如图1-8所示。
实施例、
一种基于模式识别的英语单词发音学习系统,其特征在于,包括:人机交互系统和数据处理系统;所述人机交互系统用于采集用户的英语单词语音、向用户发出交互指令,“例如:请跟读上述单词”;还用于通过显示屏进行文字互动;所述人机交互系统包括:语音输入端、语音输出端和显示屏。
其中,显示屏提示词,系统内置不同标准难度的多套单词,初测的学生可根据自身情况选择难度标准。
难度等级按照从容易到困难的顺序分为3级,分别是1级、2级和3级。其中,1级对应大学英语四级难度,所选词汇、短语和句子均来自大学英语四级范畴;2级对应大学英语六级难度,所选词汇、短语和句子均来自大学英语六级范畴;3级对应大学英语专业八级难度,所选词汇、短语和句子均来自大学英语专业八级范畴。
同时,语音输入端输入音频。学生根据显示屏的提示,点击相应单词、短语或句子,通过系统麦克风进行朗读,完成声音数据的输入。
根据人声的频率,选择采样频为100k的高速数据采集卡,采集声音的时域信号a(t),如图3(a)所示。
以单词discovery为例,选择难度等级1进行测试,采集信号、处理后信号以及对应单词音标解析如图3所示。
对关键参数提取:
①重音:
实际人声:t0=0,t1=325ms,t2=894ms,tt=2216ms。a(t1~t2)=0.32db<△a=1db,且t2-t1=894ms-325ms=589ms>0.01s,则zyr=0.894s。
②音调:
实际人声如图5、图6所示。
③语速:
实际人声:t1-t0=0.325s,tt-t2=1.322s。
模式识别:
①系统内置标准:t0=0,t1=308ms,t2=869ms,tt=2149ms。
重音:zyt=0.78s。
音调:如图7、图8所示。
语速:t1-t0=0.308s,tt-t2=1.28s
②归一化处理:
系统内置标准:
i.重音:
ii.音调:此参数的归一化处理是将参数值的范围统一转化成[0,1],即最大值为1,转变过程不影响图7、图8中曲线的变化规律,变化规律见图7、图8所示;
iii.语速:
实际人声:
i.重音:
ii.音调:此参数的归一化处理是将参数值的范围统一转化成[0,1],即最大值为1,转变过程不影响图5、图6中曲线的变化规律,变化规律见图5、图6所示;
iii.语速:
③契合度计算
i.重音,偏差ezy=|zyr-zyt|=|0.403-0.404=0.001;
ii.音调,
iii.语速,偏差eys=max[|ys1r-ys1t|,|ys2r-ys2t|]=0.003。
评估判断:评估得分
评估结果:g<0.1,满足所选难度等级1级的评估判断标准,系统给出学生发音所对应的关键声音参数与标准声音参数之间的对比数据,即偏差ezy=0.001、eyd(amax)=0.028、eyd(f)=0.033、eys=0.003、图5、图6、图7、图8,该图像可以作为后续研究的图例数据做保存,为后续系统的升级做数据保障和技术支持,由此能延伸设计出更为直观或量化的练习效果提示,使用户对自身发音有更深入的认识,更有利于进一步对发音进行改进和完善。
- 还没有人留言评论。精彩留言会获得点赞!