一种基于固定时长语音情感识别序列分析的测谎方法与流程
本发明属于非接触式测谎,尤其涉及一种基于固定时长语音情感识别序列分析的测谎方法,属于测谎技术领域。
背景技术:
声音是人们最直接、最方便的交流方式,基于语音的测谎是非接触式的,录音设备简单,不需要很复杂的设备,准备时间很短,受试者不会有很大的心理压力,从而提高了分析的准确性。这是本文所进行的研究的重要意义。语音中包含着说话人的很多信息,如说话者的身份、性别和年龄,甚至性格。早期的研究显示语音中包含着说话者的情绪状态,隐含许多可靠的语音特征与特定情绪间的关系。当人们紧张害怕时,基频和语速会上升,而当人们慌乱时,基频和语速会下降。说谎是一种复杂的心理生理过程,说话时伴随着明显的情绪变化,因此,利用声学特征(基频,语音持续时间和共振峰频率等)可以获知大量的心理和情绪信息。专注以语音特征为线索的测谎技术的研究起步相对较晚,多数人关注声学特征对语音测谎的影响,但是至今为止,并没有哪一个特征能单独有效的直接用于测谎。
技术实现要素:
针对现有技术存在的以上问题,本发明旨在提供一种基于固定时长语音情感识别序列分析的测谎方法,根据语音的时频特性,提取语音情感特征,基于决策树进行特征选择,最终形成一个14维的特征向量,然后在自建的汉语测谎语料库下,使用SVM完成对语料库的训练和预测,并根据语音时长输出一个语音情感序列,使用HMM模型研究该序列与谎言检测之间的联系。
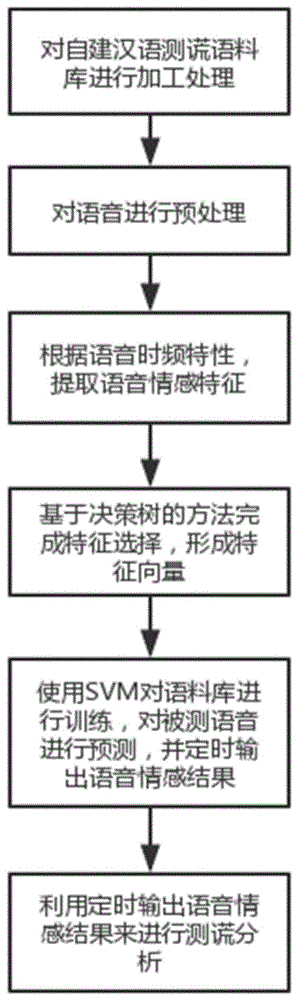
为实现本发明的目的,本发明所采用的技术方案如下:一种基于固定时长语音情感识别序列分析的测谎方法,其特征在于:该方法包括以下几个步骤:
步骤1:建立汉语测谎语料库,并加工处理;
步骤2:对语音进行预处理;
步骤3:根据语音时频特性,提取语音情感特征;
步骤4:基于决策树的方法完成特征选择,形成特征向量;
步骤5:使用SVM对语料库进行训练,对被测语音进行预测,并定时输出语音情感结果;
步骤6:利用定时输出语音情感结果来进行测谎分析。
作为本发明的一种改进,所述步骤1:建立汉语测谎语料库,并加工处理;具体如下:
步骤1.1:建立汉语测谎语料库;
步骤1.2:将谎话语料中的真话片段提出;
步骤1.3:将真话和谎话切分成等时长的语料段,并贴好标签,方便后续实验。
作为本发明的一种改进,所述步骤2:对语音进行预处理,具体如下:
步骤2.1:对语音信号离散化,使用一阶高通滤波器进行预加重,一阶高通滤波器的表达式如下:
H(z)=1-αz-1,0.9<α<1.0
步骤2.2:对信号进行分帧,帧长为30ms,帧移为10ms;
步骤2.3:选择汉明窗函数,其计算公式如下:
作为本发明的一种改进,步骤3:提取语音情感特征,具体如下,
步骤3.1:提取短时能量,短时能量是指一帧语音的能量,设语音信号为x(n)、加窗函数ω(n)分帧处理后的第i帧语音信号为yi(n),则yi(n)满足:
yi(n)=ω(n)*x((f-1)*inc+n),1≤n≤L,1≤i≤fnω(n)为窗函数;yi(n)是一帧的数值;inc为帧移长度;fn为分帧后的总帧数,则第i帧的语音信号的短时能量为
步骤3.2:提取短时平均过零率,它表示一帧语音中信号的波形穿过零电平的次数。对于离散信号来说,相邻数据改变一次符号就算做一次过零,设语音信号为x(n),分帧后第i帧语音信号为yi(n),短时平均过零率为
步骤3.3:提取基音频率,基音周期是声带开启和闭合一次说用的时长,基音频率是其倒数,当信号序列为x(n)时,它的傅里叶变换为
X(ω)=FFT[x(n)]
则序列
称为倒频谱,简称为倒谱,这里FFT和FFT-1分别为傅里叶变换和傅里叶反变换,的实际单位是时间s。
语音x(n)是由声门脉冲激励u(n)经声道响应V(n)滤波而得,即
x(n)=u(n)*v(n)
则这三个量的倒谱有
在倒频谱中,声门脉冲激励和声道响应是相对分离的,因此从中可以分离恢复出声门脉冲激励,从而得到基音周期;
步骤3.4:共振峰是指在声音的频谱中能量相对集中的一些区域,用LPC法进行提取,语音信号的一帧信号x(n)可由差分方程表示为
相应的声道传递函数为
取功率谱模值,用P(f)表示
P(厂)=|H(f)|2
其中
z-1=e-jωT
利用FFT可对任意频率求得它的功率谱幅值响应,并从幅值响应中找到共振峰的信息;
步骤3.5:提取MFCC参数,首先进行预处理,原信号x(n)经预处理后变为xi(m),i表示第i帧,对信号进行FFT
X(i,k)=FFT[xi(m)]
进行Mel滤波器组处理,对每一帧FFT后的数据计算谱线能量
E(i,k)=X(i,k)2
计算在Mel滤波器组(选取三角形的滤波器)的能量
对能量取对数,并经过离散余弦变换(DCT),得到MFCC参数;
作为本发明的一种改进,所述步骤4:基于决策树的方法完成特征选择,形成特征向量,具体如下,输入:训练数据集D,特征集A,阈值e;输出:决策树T;
步骤4.1:如果D中所有实例属于同一类Ck,则置T为单结树,并将Ck作为该结点的类,返回T;
步骤4.2:如果A是空集,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
步骤4.3:否则,计算A中各特征对D的信息增益比,选择信息增益比最大的特征Ag;
步骤4.4:如果Ag的信息增益比小于阈值e,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
步骤4.5:否则,对Ag的每一个可能值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
步骤4.6:对结点i,以Di为训练集,以A-{Ag}为特征集,递归调用上述步骤,得到子树Ti。
作为本发明的一种改进,所述步骤5:使用SVM对语料库进行训练,对被测语音进行预测,并定时输出语音情感结果,具体如下,
步骤5.1:基于自建测谎语料库,使用SVM完成测谎实验,得到一段语音的测谎结果;
步骤5.2:基于CASIA标准情感库,定时输出语音情感预测结果,这个结果是一个维数与语音时长相关的序列,每秒钟输出一个语音情感识别结果,那么一个60s的语音得到一个60维的向量。
作为本发明的一种改进,所述步骤6:利用定时输出语音情感结果来进行测谎分析,具体如下,
步骤6.1:将语料库样本的80%分为训练样本,20%分为测试样本;
步骤6.2:将训练样本按标签分类,真话部分为1,谎话部分为一1;
步骤6.3:将训练样本的语料,按照上述步骤1-5操作,生成语音情感序列;
步骤6.4:用五个元素来描述HMM模型,隐含状态S(说谎情况),可观测状态O(语音情感序列),隐含状态转移概率矩阵A,观测状态转移矩阵B,初始状态概率矩阵Π;
步骤6.5:利用训练样本训练HMM模型。即从训练样本中选择几组观测序列O(语音情感序列),利用Baum-Welch方法求模型λ=(A,B,Π)中的参数;具体方法是随机初始化模型参数A,B,Π,用样本0计算寻找更合适的参数,更新参数,再用样本拟合参数,直至参数收敛;
步骤6.6:得到了HMM模型λ=(A,B,Π),使用测试样本来进行预测;从中选取一个语音情感序列,利用Viterbi方法求解背后的状态序列,得到预测的测谎结果。
相对于现有技术,本发明的有益效果效果如下:
1、语音情感特征多种多样,包括声学、韵律和谱特征等,但并不是每一种都对测谎工作有益,无效的特征加入,只会浪费训练时间,并且可能会降低识别率,本发明采用机器学习的方法进行特征选择(决策树),能够寻得对于识别谎言权重最大、最优的特征。
2、考虑语音情感对测谎的影响,生成与时长相关的语音情感序列,并利用HMM模型研究语音情感序列与谎言检测的关系。
附图说明
图1是本发明一种基于固定时长语音情感识别序列分析的测谎方法流程图;
具体实施方式
下面结合附图和实施例对本发明的技术方案作进一步的说明。
实施例1:如图1所示,本发明提出了一种基于固定时长语音情感识别序列分析的测谎方法,该方法的详细步骤为:
步骤1:建立汉语测谎语料库,并加工处理;
步骤1.1:建立汉语测谎语料库;
步骤1.2:将谎话语料中的真话片段提出;
步骤1.3:将真话和谎话切分成等时长的语料段,并贴好标签,方便后续实验;
步骤2:对语音进行预处理;
步骤2.1:对语音信号离散化,使用一阶高通滤波器进行预加重,一阶高通滤波器的表达式如下:
H(z)=1-αz-1,0.9<α<1.0;
步骤2.2:对信号进行分帧,帧长为30ms,帧移为10ms;
步骤2.3:选择汉明窗函数,其计算公式如下:
步骤3:提取语音情感特征;
步骤3.1:提取短时能量,短时能量是指一帧语音的能量,设语音信号为x(n)、加窗函数ω(n)分帧处理后的第i帧语音信号为yi(n),则yi(n)满足:
yi(n)=ω(n)*x((i-1)*inc+n),1≤n≤L,1≤i≤fnω(n)为窗函数;yi(n)是一帧的数值;inc为帧移长度;fn为分帧后的总帧数,则第i帧的语音信号的短时能量为
步骤3.2:提取短时平均过零率,它表示一帧语音中信号的波形穿过零电平的次数。对于离散信号来说,相邻数据改变一次符号就算做一次过零,设语音信号为x(n),分帧后第i帧语音信号为yi(n),短时平均过零率为
步骤3.3:提取基音频率,基音周期是声带开启和闭合一次说用的时长,基音频率是其倒数,当信号序列为x(n)时,它的傅里叶变换为
X(ω)=FFT[x(n)];
则序列
称为倒频谱,简称为倒谱,这里FFT和FFT-1分别为傅里叶变换和傅里叶反变换,的实际单位是时间s。
语音x(n)是由声门脉冲激励u(n)经声道响应V(n)滤波而得,即
x(n)=u(n)*v(n);
则这三个量的倒谱有
在倒频谱中,声门脉冲激励和声道响应是相对分离的,因此从中可以分离恢复出声门脉冲激励,从而得到基音周期;
步骤3.4:共振峰是指在声音的频谱中能量相对集中的一些区域,用LPC法进行提取,语音信号的一帧信号x(n)可由差分方程表示为
相应的声道传递函数为
取功率谱模值,用P(f)表示
P(f)=|H(f)|2;
其中
z-1=e-jωT;
利用FFT可对任意频率求得它的功率谱幅值响应,并从幅值响应中找到共振峰的信息;
步骤3.5:提取MFCC参数,首先进行预处理,原信号x(n)经预处理后变为xi(m),i表示第i帧,对信号进行FFT
X(i,k)=FFT[xi(m)];
进行Mel滤波器组处理,对每一帧FFT后的数据计算谱线能量
E(i,k)=X(i,k)2;
计算在Mel滤波器组(选取三角形的滤波器)的能量
对能量取对数,并经过离散余弦变换(DCT),得到MFCC参数;
步骤4:基于决策树的方法完成特征选择,形成特征向量,输入:训练数据集D,特征集A,阈值e;输出:决策树T;
步骤4.1:如果D中所有实例属于同一类Ck,则置T为单结树,并将Ck作为该结点的类,返回T;
步骤4.2:如果A是空集,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
步骤4.3:否则,计算A中各特征对D的信息增益比,选择信息增益比最大的特征Ag;
步骤4.4:如果Ag的信息增益比小于阈值e,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
步骤4.5:否则,对Ag的每一个可能值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
步骤4.6:对结点i,以Di为训练集,以A-{Ag}为特征集,递归调用上述步骤,得到子树Ti;
步骤5:使用SVM对语料库进行训练,对被测语音进行预测,并定时输出语音情感结果;
步骤5.1:基于自建测谎语料库,使用SVM完成测谎实验,得到一段语音的测谎结果;
步骤5.2:基于CASIA标准情感库,定时输出语音情感预测结果,这个结果是一个维数与语音时长相关的序列,每秒钟输出一个语音情感识别结果,那么一个60s的语音得到一个60维的向量;
步骤6:利用定时输出语音情感结果来进行测谎分析;
步骤6.1:将语料库样本的80%分为训练样本,20%分为测试样本;
步骤6.2:将训练样本按标签分类,真话部分为1,谎话部分为-1;
步骤6.3:将训练样本的语料,按照上述步骤1-5操作,生成语音情感序列;
步骤6.4:用五个元素来描述HMM模型,隐含状态S(说谎情况),可观测状态O(语音情感序列),隐含状态转移概率矩阵A,观测状态转移矩阵B,初始状态概率矩阵Π;
步骤6.5:利用训练样本训练HMM模型。即从训练样本中选择几组观测序列O(语音情感序列),利用Baum-Welch方法求模型λ=(A,B,Π)中的参数;具体方法是随机初始化模型参数A,B,Π,用样本O计算寻找更合适的参数,更新参数,再用样本拟合参数,直至参数收敛;
步骤6.6:得到了HMM模型入=(A,B,Π),使用测试样本来进行预测;从中选取一个语音情感序列,利用Viterbi方法求解背后的状态序列,得到预测的测谎结果。
需要说明的是上述实施例仅仅是本发明的较佳实施例,并没有用来限定本发明的保护范围,在上述技术方案的基础上做出的等同替换或者替代均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!