一种POC对讲的语音去噪增强系统及语音去噪增强方法与流程
本发明涉及语音处理技术领域,具体为一种POC对讲的语音去噪增强系统及语音去噪增强方法。
背景技术:
随着移动4G网络普及,POC对讲业务也兴起。POC对讲是单工方式实时集群通话(在某一时刻,群组内在只有一个人在讲话,其他人只听),但POC对讲与传统电话系统差异较大,POC对讲的背景噪音随着用户的移动而不停变化,需要一种方法来不停调整降噪参数来适配这变化。另外POC对讲经常在室外路面使用,背景噪音较大,对声音要求是听得清楚比声音还原准确要求来的高。所以需要一种针对POC对讲的语音去噪增强的方法。
技术实现要素:
本发明的目的在于提供一种POC对讲的语音去噪增强系统及语音去噪增强方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种POC对讲的语音去噪增强系统,包括
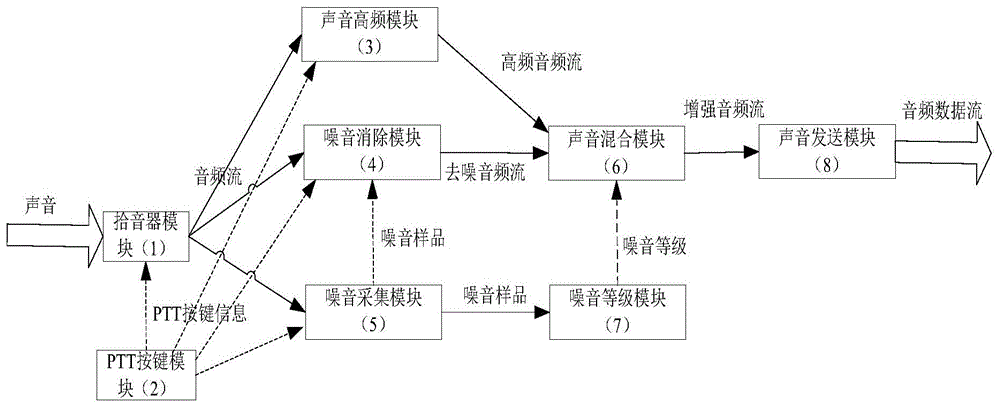
拾音器模块(1):拾音器模块(1)负责把POC对讲终端接收的声音转换为音频流;
POC对讲业务开启后,拾音器模块(1)一直处于工作状态;接收PTT按键模块(2)的PTT按键信息判断用户是否在喊话;在用户进行POC对讲喊话前,拾音器模块(1)把音频流发送个噪音采集模块(5),用于评估噪音;在用户进行POC对讲喊话后,拾音器模块(1)把音频流发送给噪音消除模块(5)获取去噪音频流,拾音器模块(1)把音频流发送声音高频模块(3)获取声音的高频音频流;
PTT按键模块(2):用户在喊话时,按下PTT按键,停止喊话时,释放PTT按键;PTT按键模块(2)捕获按键事件通知拾音器模块(1)、声音高频模块(3)和噪音清除模块(4);
声音高频模块(3):当接收到PTT按键模块(2)的按下PTT按键信息开始工作,接收拾音器模块(1)的音频流,使用滤波器去除低频部分,保留高频声音,最终形成高频音频流,发送给声音混合模块(6);
噪音清除模块(4):当接收到PTT按键模块(2)的按下PTT按键信息开始工作,接收噪音采集模块(5)的噪音样品,根据噪音样品能量平均值发生变化,则对噪音滤波器的滤噪的参数进行重新训练。当接收拾音器模块(1)的音频流使用噪音滤波器进行去除噪音处理得到去噪音频流;噪音清除模块(4)把去噪音频流发送给声音混合模块(6);
噪音采集模块(5):接收到PTT按键模块(2)的释放PTT按键信息,开始收集用户喊话前的周边声音,使用声音能量阀值检测算法取出噪音部分,生成噪音样品,当接收到PTT按键模块(2)的按下PTT按键信息,则开始发送给噪音清除模块(4)与噪音等级模块(7);
声音混合模块(6):接收噪音清除模块(4)的去噪音频流,接收声音高频模块(3)的高频音频流,接收噪音等级模块(7)的噪音等级信息,设置高频音频流与去噪音频流混合比例,如果噪音等级模块(7)噪音小于下限阀值时,噪音清除模块(4)的去噪对声音破坏小,则高频音频流比例低,如果噪音等级模块(7)噪音大于上限阀值时,优先保证听的清楚,则高频音频流比例高,避免噪音消除影响声音清晰度问题;声音混合模块(6)混合得到增强音频流发送给声音发送模块(8);
噪音等级模块(7):接收噪音采集模块(5)的噪音样本,计算噪音的能量值生成噪音等级信息,噪音等级模块(7)把噪音等级信息发送给声音混合模块(6);
声音发送模块(8):接收声音混合模块(6)的增强音频流,通过网络形式发送POC服务器。
本发明还提供一种POC对讲的语音去噪增强方法,包括如下步骤:
步骤1、在用户进行POC对讲喊话前,拾音器模块(1)把音频流发送个噪音采集模块(5),用于评估噪音;
步骤2、噪音采集模块(5)收集用户喊话前的周边声音,使用声音检测算法取出噪音部分,生成噪音样品;
步骤2.1、接收到PTT按键模块(2)的释放PTT按键信息,对采集周边声音按照时间分片(如20ms一个分片),周期性处理的分片音频数据,对每个分片的音频数据的绝对值进行累加,累加值除于分片大小得到分片的平均值;
步骤2.2、把过去时间t(如:1分钟)内所有检测有声音分片的平均值进行累加求平均值,得到时间t的所有语音的平均数;平均数除以2为判断门噪音阀值T,判断阀值T低于噪音检测最低值,则设置阀值T为最低值,避免周边声音一直是稳定噪音时采集不到噪音,判断阀值T低于噪音检测最高值,则设置阀值T为最高值,避免把用户声音误认为噪音;
步骤2.3、分片包的平均值小于阀值T则认为判断噪音分片,拼接噪音分片形成噪音样本,噪音采集模块(5)保持最近10秒噪音样本;
步骤2.4、接收到PTT按键模块(2)的按下PTT按键信息,则把噪音样本发送噪音清除模块(4);
步骤3、在用户进行POC对讲喊话后,拾音器模块(1)接收到PTT按键模块(2)的按下PTT按键信息,拾音器模块(1)把音频流发送给噪音消除模块(5)获取去噪音频流,拾音器模块(1)把音频流发送声音高频模块(3)获取声音的高频音频流;
步骤4、噪音清除模块(4)消除噪音的方法;
步骤4.1、噪音清除模块(4)当接收到PTT按键模块(2)的按下PTT按键信息开始工作,接收噪音采集模块(5)的噪音样本;
步骤4.2、噪音清除模块(4)对噪音样本进行噪音变化判断;如果噪音样本的所有数据的绝对值进行平均值处理得到A1,与上次滤噪参数训练的噪音样本的平均值NAVG进行相减,后取绝对值得到DA,DA与门限值AT进行比较,如果DA大于AT则进行滤噪参数训练,如果DA小于AT则丢弃该噪音样本,使用之前滤噪参数进行去除噪音处理;
步骤4.3、噪音清除模块(4)进行噪音滤波器的滤噪参数训练,如对维纳滤波器(噪音滤波器)的滤波器系数训练,并保存A1为平均值NAVG;传统噪音滤波器通常把首先接收到声音做噪音样本样本,训练获取滤噪参数,后续使用该滤噪参数对声音进行降噪,这个会带来噪音样本不够准确,POC对讲场景用户不停移动,背景噪音不停在变化,使用固定滤噪参数难以适应;本专利方法使用用户每次按下PTT按键时候进行判断噪音变化,来适配外界参数变化;
步骤4.4、噪音清除模块(4)接收拾音器模块(1)的音频流进行使用滤噪参数去除噪音处理,得到去噪音频流;噪音清除模式(4)把去噪音频流发送给声音混合模块(6);
步骤5、背景噪音过大时,噪音清除模块(4)的噪音滤波器的去噪出现两个问题,一:去噪效果减低导致噪音残留,二:去噪对原始声音破坏导致声音模糊;而人声500Hz以上为声音轮廓影响声音清晰度,500Hz以下为人声的力道影响听感;所以,声音高频模块(3)过滤500Hz以上声音,噪音等级模块(7)监控噪音情况,声音混合模块(6)根据噪音情况控制高频音频流与去噪音频流混合比例;具体流程:
步骤5.1、声音高频模块(3)当接收到PTT按键模块(2)的按下PTT按键信息开始工作,接收拾音器模块(1)的音频流;
步骤5.2、声音高频模块(3)使用FFT滤波器对音频流去除500Hz以下低频部分,保留500Hz以上高频声音,最终形成高频音频流;
步骤5.3、声音高频模块(3)发送给声音混合模块(6);
步骤5.4、噪音等级模块(7)接收噪音采集模块(5)的噪音样本;
步骤5.5、噪音等级模块(7)对噪音样本的所有数据的绝对值进行平均值处理得到A1;
步骤5.6、噪音等级模块(7)对A1使用查表法确定噪音0~9噪音等级AL;噪音等级表使用噪音样本均值划分不同区间来确认等级;
步骤5.7、噪音等级模块(7)把噪音等级信息发送给声音混合模块(6);
步骤5.8、声音混合模块(6)接收噪音清除模块(4)的去噪音频流,接收声音高频模块(3)的高频音频流,接收噪音等级模块(7)的噪音等级信息.
步骤5.9、声音混合模块(6)设置高频音频流与去噪音频流混合比例,高频音频流混合比例为AL/10,去噪音频流混合比例为(10-AL)/10,AL为噪音等级;所以噪音等级模块(7)噪音能量小于下限阀值1L时,噪音清除模块(4)的去噪对声音破坏小,则高频音频流比例低,如果噪音等级模块(7)噪音大于上限阀值10L时,优先保证听的清楚,则高频音频流比例高,避免噪音消除影响声音清晰度问题;
步骤5.10、声音混合模块(6)混合得到增强音频流发送给声音发送模块(8);
步骤6、声音发送模块(8)接收声音混合模块(6)的增强音频流,通过网络形式发送POC服务器。
其中:POC是一种一对多双向单工对讲机通,浏览器的HTML5定义音视频规范,但仍然缺少POC在HTML应用的方案;POC(Push To Talk Over Cellular):进行“一对多”双向单工对讲机通讯。
与现有技术相比,本发明的有益效果是:
现有声音去噪算法,采用通话开始部分作为噪音样本,使用噪音样本训练噪音滤波器的滤波参数,难以适用POC业务的背景噪音随着用户的移动而不停变化,本发明采用每次按下PTT按键,都进行一次背景噪音变化检测,如果背景噪音发生变化则重新训练噪音滤波器的滤波参数,以适应POC业务的背景噪音快速变化。POC业务为声音要求是听得清楚比声音还原准确要求来的高,当检测噪音大于阀值时,噪音滤波器对原始声音破坏过大,混入原始声音的高频部分提高声音的可识别度,优先保证POC声音的听得清楚。
附图说明
图1为本发明整体功能框架结构示意图;
图中:拾音器模块(1),PTT按键模块(2),声音高频模块(3),噪音清除模块(4),噪音采集模块(5),声音混合模块(6),噪音等级模块(7),声音发送模块(8)
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供如下技术方案:一种POC对讲的语音去噪增强系统,包括:拾音器模块(1):拾音器模块(1)负责把POC对讲终端接收的声音转换为音频流;POC对讲业务开启后,拾音器模块(1)一直处于工作状态;接收PTT按键模块(2)的PTT按键信息判断用户是否在喊话;在用户进行POC对讲喊话前,拾音器模块(1)把音频流发送个噪音采集模块(5),用于评估噪音;在用户进行POC对讲喊话后,拾音器模块(1)把音频流发送给噪音消除模块(5)获取去噪音频流,拾音器模块(1)把音频流发送声音高频模块(3)获取声音的高频音频流;
PTT按键模块(2):用户在喊话时,按下PTT按键,停止喊话时,释放PTT按键;PTT按键模块(2)捕获按键事件通知拾音器模块(1)、声音高频模块(3)和噪音清除模块(4);
声音高频模块(3):当接收到PTT按键模块(2)的按下PTT按键信息开始工作,接收拾音器模块(1)的音频流,使用滤波器去除低频部分,保留高频声音,最终形成高频音频流,发送给声音混合模块(6);
噪音清除模块(4):当接收到PTT按键模块(2)的按下PTT按键信息开始工作,接收噪音采集模块(5)的噪音样品,根据噪音样品能量平均值发生变化,则对噪音滤波器的滤噪的参数进行重新训练。当接收拾音器模块(1)的音频流使用噪音滤波器进行去除噪音处理得到去噪音频流;噪音清除模块(4)把去噪音频流发送给声音混合模块(6);
噪音采集模块(5):接收到PTT按键模块(2)的释放PTT按键信息,开始收集用户喊话前的周边声音,使用声音能量阀值检测算法取出噪音部分,生成噪音样品,当接收到PTT按键模块(2)的按下PTT按键信息,则开始发送给噪音清除模块(4)与噪音等级模块(7);
声音混合模块(6):接收噪音清除模块(4)的去噪音频流,接收声音高频模块(3)的高频音频流,接收噪音等级模块(7)的噪音等级信息,设置高频音频流与去噪音频流混合比例,如果噪音等级模块(7)噪音小于下限阀值时,噪音清除模块(4)的去噪对声音破坏小,则高频音频流比例低,如果噪音等级模块(7)噪音大于上限阀值时,优先保证听的清楚,则高频音频流比例高,避免噪音消除影响声音清晰度问题;声音混合模块(6)混合得到增强音频流发送给声音发送模块(8);
噪音等级模块(7):接收噪音采集模块(5)的噪音样本,计算噪音的能量值生成噪音等级信息,噪音等级模块(7)把噪音等级信息发送给声音混合模块(6);
声音发送模块(8):接收声音混合模块(6)的增强音频流,通过网络形式发送POC服务器。
本发明还提供一种POC对讲的语音去噪增强方法,包括如下步骤:
步骤1、在用户进行POC对讲喊话前,拾音器模块(1)把音频流发送个噪音采集模块(5),用于评估噪音;
步骤2、噪音采集模块(5)收集用户喊话前的周边声音,使用声音检测算法取出噪音部分,生成噪音样品;
步骤2.1、接收到PTT按键模块(2)的释放PTT按键信息,对采集周边声音按照时间分片(如20ms一个分片),周期性处理的分片音频数据,对每个分片的音频数据的绝对值进行累加,累加值除于分片大小得到分片的平均值;
步骤2.2、把过去时间t(如:1分钟)内所有检测有声音分片的平均值进行累加求平均值,得到时间t的所有语音的平均数;平均数除以2为判断门噪音阀值T,判断阀值T低于噪音检测最低值,则设置阀值T为最低值,避免周边声音一直是稳定噪音时采集不到噪音,判断阀值T低于噪音检测最高值,则设置阀值T为最高值,避免把用户声音误认为噪音;
步骤2.3、分片包的平均值小于阀值T则认为判断噪音分片,拼接噪音分片形成噪音样本,噪音采集模块(5)保持最近10秒噪音样本;
步骤2.4、接收到PTT按键模块(2)的按下PTT按键信息,则把噪音样本发送噪音清除模块(4);
步骤3、在用户进行POC对讲喊话后,拾音器模块(1)接收到PTT按键模块(2)的按下PTT按键信息,拾音器模块(1)把音频流发送给噪音消除模块(5)获取去噪音频流,拾音器模块(1)把音频流发送声音高频模块(3)获取声音的高频音频流;
步骤4、噪音清除模块(4)消除噪音的方法;
步骤4.1、噪音清除模块(4)当接收到PTT按键模块(2)的按下PTT按键信息开始工作,接收噪音采集模块(5)的噪音样本;
步骤4.2、噪音清除模块(4)对噪音样本进行噪音变化判断;如果噪音样本的所有数据的绝对值进行平均值处理得到A1,与上次滤噪参数训练的噪音样本的平均值NAVG进行相减,后取绝对值得到DA,DA与门限值AT进行比较,如果DA大于AT则进行滤噪参数训练,如果DA小于AT则丢弃该噪音样本,使用之前滤噪参数进行去除噪音处理;
步骤4.3、噪音清除模块(4)进行噪音滤波器的滤噪参数训练,如对维纳滤波器(噪音滤波器)的滤波器系数训练,并保存A1为平均值NAVG;传统噪音滤波器通常把首先接收到声音做噪音样本样本,训练获取滤噪参数,后续使用该滤噪参数对声音进行降噪,这个会带来噪音样本不够准确,POC对讲场景用户不停移动,背景噪音不停在变化,使用固定滤噪参数难以适应;本专利方法使用用户每次按下PTT按键时候进行判断噪音变化,来适配外界参数变化;
步骤4.4、噪音清除模块(4)接收拾音器模块(1)的音频流进行使用滤噪参数去除噪音处理,得到去噪音频流;噪音清除模式(4)把去噪音频流发送给声音混合模块(6);
步骤5、背景噪音过大时,噪音清除模块(4)的噪音滤波器的去噪出现两个问题,一:去噪效果减低导致噪音残留,二:去噪对原始声音破坏导致声音模糊;而人声500Hz以上为声音轮廓影响声音清晰度,500Hz以下为人声的力道影响听感;所以,声音高频模块(3)过滤500Hz以上声音,噪音等级模块(7)监控噪音情况,声音混合模块(6)根据噪音情况控制高频音频流与去噪音频流混合比例;具体流程:
步骤5.1、声音高频模块(3)当接收到PTT按键模块(2)的按下PTT按键信息开始工作,接收拾音器模块(1)的音频流;
步骤5.2、声音高频模块(3)使用FFT滤波器对音频流去除500Hz以下低频部分,保留500Hz以上高频声音,最终形成高频音频流;
步骤5.3、声音高频模块(3)发送给声音混合模块(6);
步骤5.4、噪音等级模块(7)接收噪音采集模块(5)的噪音样本;
步骤5.5、噪音等级模块(7)对噪音样本的所有数据的绝对值进行平均值处理得到A1;
步骤5.6、噪音等级模块(7)对A1使用查表法确定噪音0~9噪音等级AL;噪音等级表使用噪音样本均值划分不同区间来确认等级;
步骤5.7、噪音等级模块(7)把噪音等级信息发送给声音混合模块(6);
步骤5.8、声音混合模块(6)接收噪音清除模块(4)的去噪音频流,接收声音高频模块(3)的高频音频流,接收噪音等级模块(7)的噪音等级信息.
步骤5.9、声音混合模块(6)设置高频音频流与去噪音频流混合比例,高频音频流混合比例为AL/10,去噪音频流混合比例为(10-AL)/10,AL为噪音等级;所以噪音等级模块(7)噪音能量小于下限阀值1L时,噪音清除模块(4)的去噪对声音破坏小,则高频音频流比例低,如果噪音等级模块(7)噪音大于上限阀值10L时,优先保证听的清楚,则高频音频流比例高,避免噪音消除影响声音清晰度问题;
步骤5.10、声音混合模块(6)混合得到增强音频流发送给声音发送模块(8);
步骤6、声音发送模块(8)接收声音混合模块(6)的增强音频流,通过网络形式发送POC服务器。
其中:POC是一种一对多双向单工对讲机通,浏览器的HTML5定义音视频规范,但仍然缺少POC在HTML应用的方案;POC(Push To Talk Over Cellular):进行“一对多”双向单工对讲机通讯。
现有声音去噪算法,采用通话开始部分作为噪音样本,使用噪音样本训练噪音滤波器的滤波参数,难以适用POC业务的背景噪音随着用户的移动而不停变化,本发明采用每次按下PTT按键,都进行一次背景噪音变化检测,如果背景噪音发生变化则重新训练噪音滤波器的滤波参数,以适应POC业务的背景噪音快速变化。POC业务为声音要求是听得清楚比声音还原准确要求来的高,当检测噪音大于阀值时,噪音滤波器对原始声音破坏过大,混入原始声音的高频部分提高声音的可识别度,优先保证POC声音的听得清楚。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!