一种基于双机器识别的语音识别系统及方法与流程
本发明涉及语音识别技术领域,具体是一种基于双机器识别的语音识别系统及方法。
背景技术:
语音识别是一门交叉学科。近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。语音识别听写机在一些领域的应用被美国新闻界评为1997年计算机发展十件大事之一。很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一。语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
现有语音识别方法中,可根据已有的声学模型进行语音识别,但是其仍然存在着识别效率低下的问题,基于此,本申请提出了一种基于双机器识别的语音识别系统及方法。
技术实现要素:
本发明的目的在于提供一种基于双机器识别的语音识别系统及方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于双机器识别的语音识别方法,包括以下步骤:
s1,去噪模型接收语音采集模块采集到的语音信息,按照设定的参数对语音信息进行去噪;
s2,去噪后的语音信息被输入到语音识别模型内按照设定的参数进行语音识别;
s3,语音识别完成后,结果识别模块对识别结果进行判定,当识别结果的准确率小于设定的阈值时,检测去噪模型与语音识别模型的准确性;
s4,对去噪模型和/或语音识别模型的参数进行反向训练更新。
作为本发明进一步的方案:步骤s1中,去噪模型首先对得到的语音段落分割成连续的特性向量,形成特征向量序列,然后为每段所述赋予标签序号,形成标签序列,之后再对形成的特征向量序列执行去噪。
作为本发明再进一步的方案:步骤s2中,去噪后的语音信息至少包括特征向量序列和与其关联的标签序列。
作为本发明再进一步的方案:步骤s3中,当识别结果的准确率小于设定的阈值时,数据分析模块对识别结果进行分析,获取识别错误的语音段落及该语音段落对应的特征向量和标签序号,判定准确率低的原因是在去噪阶段和/或语音识别阶段,进而对去噪模型和/或语音识别模型的参数进行反向训练更新。
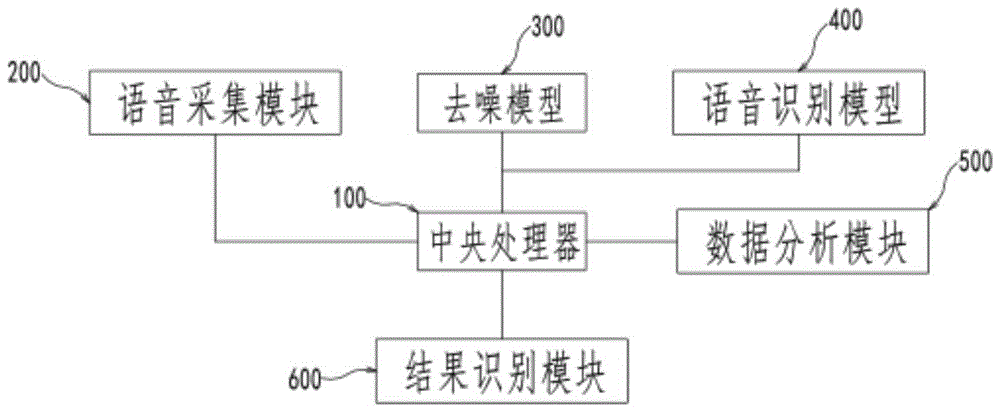
一种基于双机器识别的语音识别系统,包括与中央处理器通讯的去噪模型和语音识别模型,其中:
所述去噪模型,用于将得到的语音段落分割成连续的特性向量,形成特征向量序列,然后为每段所述赋予标签序号形成标签序列,之后再对特征向量序列执行去噪;
语音识别模型,为经过去噪后的特性向量按照设定的参数进行语音识别,并输出识别结果。
作为本发明进一步的方案:还包括语音采集模块,用于接收或采集语音信息,供中央处理器调用。
作为本发明进一步的方案:还包括与中央处理器通讯的数据分析模块和结果识别模块,其中,所述结果识别模块用于对识别结果进行判定,检测识别结果的准确率是否小于设定的阈值;所述数据分析模块用于在检测识别结果准确率小于设定的阈值时,获取识别错误的语音段落及该语音段落对应的特征向量和标签序号,判定准确率低的原因是在去噪阶段和/或语音识别阶段,然后向中央处理器发送信号,进而对去噪模型和/或语音识别模型的参数进行反向训练更新。
与现有技术相比,本发明的有益效果是:由于去噪模型在先已经将语音段落分割成特性向量,来执行去噪,在进入到语音识别模型内无需再次生成特征向量,语音识别效率高,同时由于特征向量序列具有与其匹配的标签序列,在后续识别结果不够精确时,能够方便的找出问题所在,及时的更改参数或重新进行训练等,以保证结果的准确性。
附图说明
图1为一种基于双机器识别的语音识别系统的结构示意图。
图2为一种基于双机器识别的语音识别系统的工作流程图。
图3为一种基于双机器识别的语音识别方法的流程图。
图中:100-中央处理器、200-语音采集模块、300-去噪模型、400-语音识别模型、500-数据分析模块、600-结果识别模块。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本实施例公开的一些方面相一致的装置和方法的例子。
实施例1
请参阅图1~2,本发明实施例中,一种基于双机器识别的语音识别系统,包括与中央处理器100通讯的语音采集模块200、去噪模型300和语音识别模型400,其中:
语音采集模块200,用于接收或采集语音信息,来供中央处理器100调用,实际应用时,其可以直接采集语音信息(如拾音器等),或接收已经采集好的语音信息,此处,语音采集模块200不限于使用网络传输等方式获得;
所述去噪模型300,用于将得到的语音段落分割成连续的特性向量,形成特征向量序列,然后为每段所述赋予标签序号形成标签序列,之后再对特征向量序列执行去噪;
语音识别模型400,为经过去噪后的特性向量按照设定的参数进行语音识别,并输出识别结果。
本实施例中,由于去噪模型300在先已经将语音段落分割成特性向量,来执行去噪,在进入到语音识别模型400内无需再次生成特征向量,语音识别效率高,同时由于特征向量序列具有与其匹配的标签序列,在后续识别结果不够精确时,能够方便的找出问题所在,及时的更改参数或重新进行训练等。
具体的来说,还包括与中央处理器100通讯的数据分析模块500和结果识别模块600,其中,所述结果识别模块600用于对识别结果进行判定,检测识别结果的准确率是否小于设定的阈值,其具体识别方式可以为将识别结果与标准结果进行比对来实现;而所述数据分析模块500用于在检测识别结果准确率小于设定的阈值时,获取识别错误的语音段落及该语音段落对应的特征向量和标签序号,判定准确率低的原因是在去噪阶段和/或语音识别阶段,然后向中央处理器100发送信号,进而对去噪模型300和/或语音识别模型400的参数进行反向训练更新。
实施例2
请参阅图3,本发明实施例中,一种基于双机器识别的语音识别方法,包括以下步骤:
s1,去噪模型接收语音采集模块采集到的语音信息,按照设定的参数对语音信息进行去噪,具体的方式为,首先对得到的语音段落分割成连续的特性向量,形成特征向量序列,然后为每段所述赋予标签序号,形成标签序列,之后再对形成的特征向量序列执行去噪;
s2,去噪后的语音信息(标签序列及已经完成去燥的特征向量序列)被输入到语音识别模型内按照设定的参数进行语音识别;
s3,语音识别完成后,结果识别模块对识别结果进行判定,当识别结果的准确率小于设定的阈值时,检测去噪模型与语音识别模型的准确性;
s4,对去噪模型和/或语音识别模型的参数进行反向训练更新。
当识别结果的准确率小于设定的阈值时,数据分析模块对识别结果进行分析,获取识别错误的语音段落及该语音段落对应的特征向量和标签序号,判定准确率低的原因是在去噪阶段和/或语音识别阶段,进而对去噪模型和/或语音识别模型的参数进行反向训练更新;当准确率大于设定的阈值时,那么直接输出识别结果即可。
需要特别说明的是,本技术方案中,由于去噪模型300在先已经将语音段落分割成特性向量,来执行去噪,在进入到语音识别模型400内无需再次生成特征向量,语音识别效率高,同时由于特征向量序列具有与其匹配的标签序列,在后续识别结果不够精确时,能够方便的找出问题所在,及时的更改参数或重新进行训练等,以保证结果的准确性。
本领域技术人员在考虑说明书及实施例处的公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!