一种基于多模态交互的分布式物联网设备协同方法及其系统与流程
本发明涉及人工智能技术领域,具体为一种基于多模态交互的分布式物联网设备协同方法及其系统。
背景技术:
随着人工智能领域技术的不断发展,语音识别和人脸检测的准确率不断得到提升,使我们日常生活中出现了很多智能语音设备。智能语音设备中内置麦克风或麦克风阵列,可以实现让用户与智能设备进行近距离或具有一定距离的远场交互,但超过该距离范围,语音交互准确率会下降或甚至无法实现。现在很多带语音交互的智能设备分布在我们的家庭环境中,如智能语音音箱放在客厅、智能台灯放在卧室等,设备间呈分布式放置,随着物联网的快速发展,多种语音智能设备实现多设备互联是一个必然的技术趋势和智慧家庭的生活需求,在该场景下需要一种分布式物联网设备协同交互的方法。现有技术中,分布式的物联网设备使用同一个唤醒词,当用户语音唤醒后,所有设备都响应了,无法判断应该由哪个设备响应用户的请求,严重影响了用户的使用体验。
技术实现要素:
本发明的目的在于提供一种基于多模态交互的分布式物联网设备协同方法及其系统,能够降低网络延迟,提高响应速度,解决多设备同步唤醒的凌乱结果,而且多模态交互提高了分布式物联网设备的响应准确率和稳定性,有效解决家庭场景中多个分布式物联网语音设备互联、协同工作的问题,提高了物联网环境下的用户体验,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于多模态交互的分布式物联网设备协同方法,包括以下步骤:
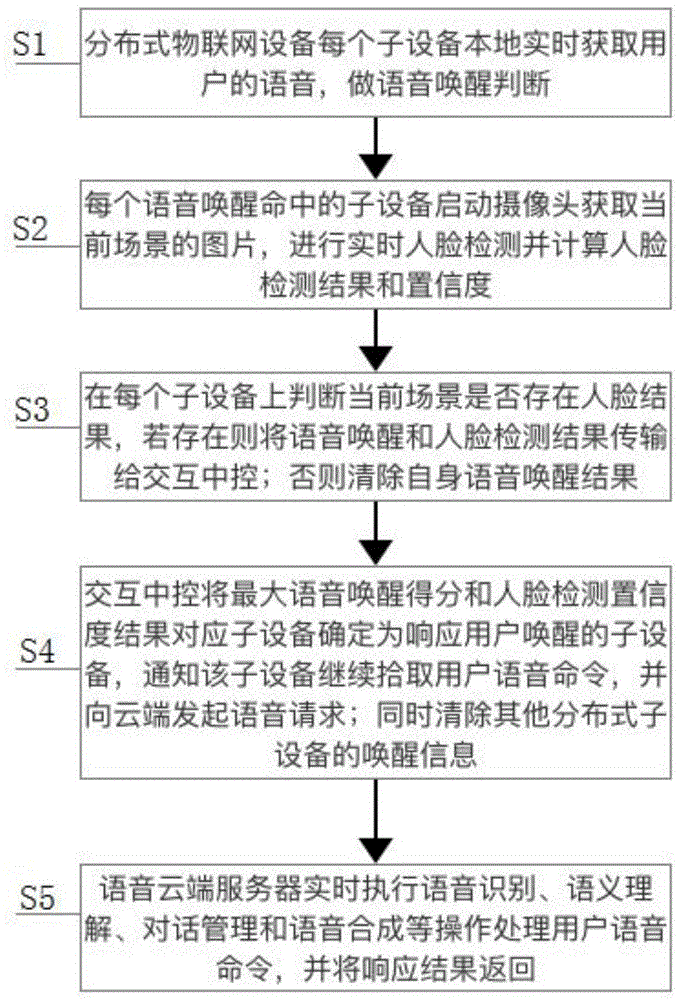
s1:分布式物联网设备每个子设备本地实时采集用户的语音,做语音唤醒判断;
s2:每个语音唤醒命中的子设备启动摄像头获取当前场景的图片,进行实时人脸检测,并计算人脸检测的结果和置信度;
s3:在每个子设备上当判断当前场景中存在人脸时,立即向交互中控传输该子设备上的语音唤醒结果和人脸检测结果,该结果包括但不限于语音唤醒和人脸唤醒的置信度;若当判断当前场景中不存在人脸时,则清除设备自身的语音唤醒结果并不向交互中控上报语音唤醒与人脸检测结果;
s4:交互中控根据接收到的各个子设备的语音唤醒结果和人脸检测结果,将最大语音唤醒得分和人脸检测置信度结果对应的子设备确定为响应用户唤醒的子设备,并通知该子设备进行响应提示,继续拾取用户语音命令,并持续将该子设备的用户语音命令向语音云端服务器发起语音处理请求,同时清除其他分布式子设备的唤醒信息;
s5:语音云端服务器实时执行语音识别、语义理解、对话管理和语音合成操作处理用户语音命令,并将响应结果返回。
更进一步地,s1中,分布式物联网设备表征多个智能终端,每个智能终端都有其麦克风阵列,包括但不限于线性2麦、线性4麦、线性6麦、环形4麦或非规则麦克风阵列。
更进一步地,s2中,人脸检测方法包括图片的预处理操作和基于mtcnn的人脸检测算法两个步骤,mtcnn在网络结构上由3个轻量级的cnn组成,分别是p-net、r-net和o-net,对输入的预处理后的图片,先后经过这3个网络的处理,最终输出人脸检测和关键点检测的结果。
更进一步地,s2中,实时人脸检测功能采用基于多任务级联卷积神经网络-mtcnn的人脸检测算法。
本发明提供另一种技术方案:一种基于多模态交互的分布式物联网设备协同系统,由分布式物联网设备、交互中控和语音云端服务器组成,所述分布式物联网设备带有麦克风阵列音频采集模块和摄像头图像采集模块,麦克风阵列音频采集模块实时采集语音信号并做信号处理运算和语音唤醒处理,分布式物联网子设备在语音唤醒后启动摄像头图像采集模块实时采集图片并做人脸检测处理,在判断存在人脸时通过通信连接将语音唤醒和人脸检测的多模态数据传输给交互中控,所述分布式物联网设备还设有语音回复与播报模块;所述交互中控根据每个所述分布式物联网设备上传的内容,其包括语音唤醒仲裁模块、语音代理服务模块和网络通信模块,通过语音唤醒仲裁模块、语音代理服务模块和网络通信模块确定出需要进行唤醒响应的分布式物联网子设备并让其继续监听用户语音命令,同时清除其他分布式子设备的唤醒信息,并将该用户语音命令通过网络通信实时请求语音云端服务器进行语音识别、语义理解,语音实时处理后下达相对应的控制命令和语音回复内容给到该唤醒响应的物联网子设备;所述语音云端服务器包括执行语音识别模块、语义理解模块、对话管理模块、语音合成模块和网络通信模块,通过网络通信模块将响应结果返回给交互中控。
与现有技术相比,本发明的有益效果是:
1、本发明提供的一种基于多模态交互的分布式物联网设备协同方法及其系统,交互中控通过在本地局域网与各个分布式物联网设备进行连接,并根据接收到的唤醒信息和人脸检测结果进行仲裁决策,并快速决定与通知需进行唤醒响应的设备,降低网络延迟,提高了响应速度,同时解决多设备同步唤醒的凌乱结果。
2、本发明公开的一种基于多模态交互的分布式物联网设备协同方法及其系统,通过多模态交互提高了分布式物联网设备的响应准确率和稳定性,同时有效解决家庭场景中多个分布式物联网语音设备互联、协同工作的问题,提高了物联网环境下的用户体验。
附图说明
图1为本发明的方法流程图;
图2为本发明的人脸检测方法流程图;
图3为本发明的人脸检测方法效果图;
图4为本发明的系统框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明实施例中:提供一种基于多模态交互的分布式物联网设备协同方法,包括以下步骤:
步骤1:分布式物联网设备每个子设备本地实时获取用户的语音,做语音唤醒判断;该步骤中,分布式物联网设备表征多个智能终端,每个智能终端都有其麦克风阵列,包括但不限于线性2麦、线性4麦、线性6麦、环形4麦或其他非规则麦克风阵列;当用户发出唤醒语音信号后,此时分布式物联网设备都可能接收到来自用户的唤醒语音信号,当子设备执行语音唤醒命令后,这时如果多个子设备同时响应用户,会极大影响用户体验和语音交互质量,此时需要对用户的语音唤醒行为做决策,即对多个子设备的唤醒行为做仲裁,决定出真正需要对用户的唤醒行为作出响应的物联网子设备或智能终端,即最适合与用户交互的唤醒设备,同时清除其他子设备的唤醒响应。
步骤2:每个语音唤醒命中的子设备启动摄像头获取当前场景的图片,进行实时人脸检测,并计算人脸检测的结果和置信度;
步骤3:在每个子设备上当判断当前场景中存在人脸时,立即向交互中控传输该子设备上的语音唤醒结果和人脸检测结果,该结果包括但不限于语音唤醒和人脸唤醒的置信度;若当判断当前场景中不存在人脸时,则清除设备自身的语音唤醒结果并不向交互中控上报语音唤醒与人脸检测结果;
步骤4:交互中控根据接收到的各个子设备的语音唤醒结果和人脸检测结果,将最大语音唤醒得分和人脸检测置信度结果对应的子设备确定为响应用户唤醒的子设备,并通知该子设备进行响应提示,继续拾取用户语音命令,并持续将该子设备的用户语音命令向语音云端服务器发起语音处理请求,同时清除其他分布式子设备的唤醒信息;
步骤5:语音云端服务器实时执行语音识别、语义理解、对话管理和语音合成操作处理用户语音命令,并将响应结果返回。
由上述实施例可见,在确定响应用户唤醒的子设备的过程中,在每个语音唤醒的子设备上进行人脸检测,根据人脸检测的结果确定当前场景下是否有用户的存在,判断用户是否对着此分布式物联网子设备进行语音唤醒或下发语音命令,本实施例通过语音与视觉的多模态信息再次确认用户的身份,从而提高了分布式物联网设备协同响应的准确率和可靠性。
在上述实施例中,步骤2中涉及的实时人脸检测功能采用基于多任务级联卷积神经网络(multi-taskconvolutionalneuralnetworks,mtcnn)的人脸检测算法,这是一种由粗到细的方法,具有实时处理的能力,速度快效果好的优点,可以在智能终端上运行,解决了传统人脸检测算法对环境要求高、人脸要求高、检测耗时高的不足。
在上述实施例中,人脸检测方法包括图片的预处理操作和基于mtcnn的人脸检测算法两个步骤,mtcnn在网络结构上是由3个轻量级的cnn组成,分别是p-net、r-net和o-net,对输入的预处理后的图片,先后经过这3个网络的处理,最终输出人脸检测和关键点检测的结果。
为了进一步更好的解释说明上述发明,其中涉及的人脸检测算法流程,请参阅图2,具体包括以下步骤:
步骤21:摄像头采集的图片输入,首先经过图片大小变换的预处理操作,即将输入的图片缩放到不同尺度形成图像金字塔,以达到尺度不变的要求;
步骤22:预处理后的图像金字塔输入到mtcnn网络中进行处理,分别经过3个子网络有粗到细的处理,具体过程如下:
步骤221,预处理后的图像金字塔输入到p-net中,输出人脸分类结果、图像候选窗和人脸地标定位结果,p-net是一个全卷积网络,用来生成候选框和边框回归向量,使用边框回归方法来校正这些候选窗,使用非极大值抑制处理进行合并重叠的候选框;
具体的,输入是一个12*12大小的图片,训练前需要把生成的训练数据(通过生成边框,然后把该边框剪切成12*12大小的图片),转换成12*12*3的结构;通过10个3*3*3的卷积核,3*3的最大池化操作,生成10个5*5的特征图;再通过第二层的16个3*3*10的卷积核,生成16个3*3的特征图;接着通过第三层的32个3*3*16的卷积核,生成32个1*1的特征图;最后针对32个1*1的特征图,p-net前馈后输出3个向量,其中,通过2个1*1*32的卷积核,生成2个1*1的特征图用于人脸二分类结果,即输出人脸分类的概率;通过4个1*1*32的卷积核,生成4个1*1的特征图用于边界框回归判断;还有一个输出是通过10个1*1*32的卷积核,生成10个1*1的特征图用于人脸地标定位判断,即人脸轮廓点信息。
步骤222中,将p-net的输出确定的图像候选窗输入r-net进行更进一步的分类,这个步骤相当于精挑的过程;
具体的,根据p-net输出的坐标,去原图上截取出图片(根据最大边长的正方形截取方法,避免形变和保留更多细节),并且重新进行图片大小变换,生成24*24大小的边框,转换成24*24*3的结构输入到r-net,通过28个3*3*3的卷积核,3*3的最大池化操作,生成28个11*11的特征图;再通过第二层的48个3*3*28的卷积核,3*3的最大池化操作,生成48个4*4的特征图;接着通过第三层的64个2*2*48的卷积核,生成64个3*3的特征图;最后经过128个神经元的全连接层,输出3个结果,其一是用于人脸二分类的2维数据结果,即输出人脸分类的概率;一个是候选边界框回归判断的4个坐标偏移量;还有一个输出是用于人脸地标定位判断的10个人脸轮廓点信息。
步骤s223中,将上一步骤中r-net的输出候选窗的信息在原图上截出的图片输入o-net进行最终的人脸框和特征点位置的确定,输出是否存在人脸的判断、人脸框定位和人脸5个特征点位置;
具体的,根据r-net输出的信息在原图上截取出图片(跟r-net的输入数据处理相同,根据最大边长的正方形截取方法,避免形变和保留更多细节),并且重新进行图片大小变换,生成48*48大小的边框,转换成48*48*3的结构输入到o-net,通过32个3*3*3的卷积核,3*3的最大池化操作,生成32个23*23的特征图;通过第二层的64个3*3*32的卷积核,3*3的最大池化操作,生成64个10*10的特征图;再通过第三层的64个3*3*64的卷积核,2*2的最大池化操作,生成64个4*4的特征图;接着通过第四层的128个2*2*64的卷积核,生成128个3*3的特征图;最后经过256个神经元的全连接层,输出3个结果,其一是用于人脸二分类的2维数据结果,即输出人脸分类的概率;一个是候选边界框回归判断的4个坐标偏移量;还有一个输出是用于人脸地标定位判断的10个人脸轮廓点信息。
步骤23,根据s22中的mtcnn网络的输出确定人脸检测结果和5个人脸关键点,在原图上5个特征点通过仿射变换对齐到图片的特定位置上,并框出人脸位置进行检测结果显示;
在本实施例中,mtcnn网络中三个子网络的输出都会对候选的人脸边框进行处理,即根据人脸二分类结果的概率得分,采用重叠度评价公式(iou)和非极大值抑制(nms)进行候选框筛选,筛掉大部分不是人脸的候选框;
具体的,针对候选边框,对候选框的精度采用一个定位精度评价公式,即定义了两个候选边框的重叠度(iou),判断两个候选矩形框的重叠面积占的两个候选边框并集的面积比例。
本实施例中,还采用了非极大值抑制(nms)方法对候选框进行筛选,非极大值抑制(nms)方法本质上抑制不是极大值的元素,搜索局部的极大值,这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小;具体的,将候选边框按照结果置信度进行排序,选中置信度中最高的候选框a,如果剩下的框中与该框a的重叠面积大于一个阈值,则删除该候选框,留下框a,以此类推,最终筛选出重叠面积较少、且置信度较高的候选框。
在本实施例中的mtcnn人脸检测方法中,在检测阶段之前,需要进行神经网络的训练,需要实现3个任务的学习,即人脸与非人脸的分类,边界框回归和人脸特征点定位(或者说人脸地标定位):
1)人脸/非人脸分类器的设计根据公式:
这是为人脸分类的交叉熵损失函数,pi为是人脸的概率,
2)边界框回归是通过欧氏距离计算的回归损失。
其中,
3)人脸地标定位,和边界框回归一样,还是通过计算网络预测得到的地标位置和实际真实地标的欧式距离,并最小化该距离。
其中,
在本实施例中,mtcnn整个的训练学习过程就是最小化下面公式中的这个函数:
p-net,r-net(αdet=1,αbox=0.5,αlandmark=0.5)
o-net(αdet=1,αbox=0.5,αlandmark=1)
其中,n为训练样本数量,αj表示任务的重要性,
在本实施例中,人脸检测算法的各个阶段的效果图如图3所示,输入的图片经过图片预处理,即图片大小变换,输出不同尺度形成图片金字塔;预处理后的图像输入p-net网络中,经过非极大值抑制和边框回归方法,输出人脸的候选边界框;仅将候选边界框框出的图片输入r-net网络中,同样采用非极大值抑制和边框回归方法,得到更少但逐渐精确地人脸的候选边界框;在o-net网络中,输入比较少的人脸候选图片,输出人脸边界框和人脸特征点结果。
请参阅图4,本发明还提供另一种技术方案:一种基于多模态交互的分布式物联网设备协同系统,由分布式物联网设备、交互中控和语音云端服务器组成,所述分布式物联网设备带有麦克风阵列音频采集模块和摄像头图像采集模块,麦克风阵列音频采集模块实时采集语音信号并做信号处理运算和语音唤醒处理,分布式物联网子设备在语音唤醒后启动摄像头图像采集模块实时采集图片并做人脸检测处理,在判断存在人脸时通过通信连接将语音唤醒和人脸检测的多模态数据传输给交互中控,所述分布式物联网设备还设有语音回复与播报模块;所述交互中控根据每个所述分布式物联网设备上传的内容,其包括语音唤醒仲裁模块、语音代理服务模块和网络通信模块,通过语音唤醒仲裁模块、语音代理服务模块和网络通信模块确定出需要进行唤醒响应的分布式物联网子设备并让其继续监听用户语音命令,同时清除其他分布式子设备的唤醒信息,并将该用户语音命令通过网络通信实时请求语音云端服务器进行语音识别、语义理解,语音实时处理后下达相对应的控制命令和语音回复内容给到该唤醒响应的物联网子设备;所述语音云端服务器包括执行语音识别模块、语义理解模块、对话管理模块、语音合成模块和网络通信模块,通过网络通信模块将响应结果返回给交互中控。
综上所述:本发明提供的一种基于多模态交互的分布式物联网设备协同方法及其系统,用于解决分布式智能语音设备的交互体验差的技术问题,由分布式物联网各个子设备分别通过麦克风或麦克风阵列实时采集语音信号做语音唤醒判断,在语音唤醒的设备上启动摄像头实时采集人脸图像做人脸检测,当语音唤醒的子设备同时检测人脸存在时,通过网络通信或广播发送到交互中控,交互中控根据各子设备上报的语音唤醒和人脸检测的多模态结果进行仲裁和协同,确定真正响应用户唤醒的设备并继续监听语音命令,同时清除其他分布式物联网子设备的唤醒信息,并将该用户语音命令通过通信实时请求语音云端服务器进行语音识别、语义理解等语音实时处理后下达相对应的控制命令和语音回复内容给到该唤醒响应的物联网子设备,本发明通过分布式物联网设备和交互中控根据多模态结果进行仲裁和协同,提高了分布式物联网设备协同交互和响应的准确率。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!