一种演唱歌曲的评价系统及方法与流程
本发明涉及歌曲演唱评价技术领域,尤其涉及一种演唱歌曲的评价系统及方法。
背景技术:
歌词作为一种表述方式特殊的文本,通过赋予不同的节奏和音律结合歌词内容表达出不同的情感和心境。对于歌词的处理,往往是根据歌词内容制作匹配的节奏,以形成歌曲。也即是说,先制作歌词,再根据歌词制作对应曲风的音律。最终形成的歌曲,歌词本身表达是否到位,歌词与曲调是否匹配等歌词评价在音乐中尤为重要。
然而现有技术中,对演唱歌曲的评价分数都是针对所有歌曲以同样的标准统一评价分数,无法处理每种歌曲唱法不同、要求情感不同的复杂情况,并且标准单一,无法适应艺术多样性,且仅仅是得出分数,并无评价后对每一首歌每一个节拍的音调、音速、强度等纬度给出详细建议,无法让中小学生清楚自己的错误点和薄弱点,无法帮助学生有针对性或方向性提高。因此,针对上述问题,成为本领域技术人员亟待解决的难题。
技术实现要素:
针对现有技术中存在的上述问题,现提供一种旨在便于对演唱歌曲进行评价的演唱歌曲的评价系统及方法。
具体技术方案如下:
本发明包括一种演唱歌曲的评价系统,其特征在于,包括:
一处理模块,用于对每首原唱歌曲的类型进行处理,以提取所述原唱歌曲的一第一特征参数;
一训练模块,所述训练模块连接所述处理模块,用于对每首所述原唱歌曲的每一分段音频的音速和声音强度变化分别进行训练,以分别提取出每一所述分段音频的所述音速和所述声音强度变化的第二特征参数;
一算法模块,所述算法模块分别连接所述处理模块和所述训练模块,用于根据所述第一特征参数以及所述第二特征参数与一演唱音频对应时段的第三特征参数,计算出一最后分值;
一评价模块,所述评价模块连接所述算法模块,根据所述最后分值以提出相应的评价。
优选的,所述处理模块包括:
一收集单元,用于收集每首所述原唱歌曲;
一分类单元,所述分类单元连接所述收集单元,用于对收集后的每首所述原唱歌曲的所述类型进行分类;
一第一训练单元,所述第一训练单元连接所述分类单元,用于将分类后的所述原唱歌曲进行训练;
一第一提取单元,所述第一提取单元连接所述第一训练单元,根据所述第一训练单元的训练结果以提取出一第一特征参数;
一第一计算单元,所述第一计算单元连接所述第一提取单元,用于将所述第一特征参数与所述演唱音频对应时段的所述第三特征参数进行计算,以得出一演唱类型匹配率。
优选的,所述训练模块包括:
一分段单元,用于将每首所述原唱歌曲按照乐谱节拍进行分段,以形成所述分段音频;
一第二训练单元,所述第二训练单元连接于所述分段单元,用于对所述分段音频中的所述音速和所述声音强度变化分别进行训练,以分别提取出每一所述分段音频的所述音速和所述声音强度变化的所述第二特征参数。
优选的,所述算法模块包括:
一第一对比单元,用于将所述音速和所述声音强度变化的所述第二特征参数与所述演唱音频对应时段的所述第三特征参数进行对比,以获取一音速匹配率和一声音强度变化匹配率;
一第二计算单元,用于计算出所述演唱音频的每节拍的音高值;
一第二对比单元,所述第二对比单元连接于所述第二计算单元,用于将所述演唱音频的每节拍的音高值与所述原唱歌曲的每节拍的音高值进行对比,以获取音高正确分值;
一第三计算单元,所述第三计算单元连接所述第二对比单元,用于根据所述演唱类型匹配率、所述音速匹配率、所述声音强度变化匹配率以及所述音高正确分值,计算出所述最后分值。
优选的,还包括一建议模块,所述建议模块连接所述评价模块,用于根据所述演唱类型匹配率、所述音速匹配率、所述声音强度变化匹配率以及所述音高正确分值提出评价之后,给演唱者相应的建议。
本发明还提供一种演唱歌曲的评价方法,包括如上述中的任一所述的演唱歌曲的评价系统,所述评价方法包括:
步骤s1、采用一处理模块,对每首原唱歌曲的类型进行处理,以提取所述原唱歌曲的一第一特征参数;
步骤s2、采用一训练模块,用于对每首所述原唱歌曲的每一分段音频的音速和声音强度变化分别进行训练,以分别提取出每一所述分段音频的所述音速和所述声音强度变化的第二特征参数;
步骤s3、采用一算法模块,用于根据所述第一特征参数以及所述第二特征参数与一演唱音频对应时段的第三特征参数,计算出一最后分值;
步骤s4、采用一评价模块,用于根据所述最后分值以提出相应的评价。
优选的,于所述步骤s1中,包括:
步骤s10、采用一收集单元,用于收集每首所述原唱歌曲;
步骤s11、采用一分类单元,用于对收集后的每首所述原唱歌曲的所述类型进行分类;
步骤s12、采用一第一训练单元,用于将分类后的所述原唱歌曲进行训练;
步骤s13、采用一第一提取单元,用于根据所述第一训练单元的训练结果以提取出一第一特征参数;
步骤s14、采用一第一计算单元,用于将所述第一特征参数与所述演唱音频对应时段的所述第三特征参数进行计算,以得出一演唱类型匹配率。
优选的,于所述步骤s2中,包括:
步骤s20、采用一分段单元,用于将每首所述原唱歌曲按照乐谱节拍进行分段,以形成所述分段音频;
步骤s21、采用一第二训练单元,用于对所述分段音频中的所述音速和所述声音强度变化分别进行训练,以分别提取出每一所述分段音频的所述音速和所述声音强度变化的所述第二特征参数。
优选的,于所述步骤s3中,包括:
步骤s30、采用一第一对比单元,用于将所述音速和所述声音强度变化的所述第二特征参数与所述演唱音频对应时段的所述第三特征参数进行对比,以获取一音速匹配率和一声音强度变化匹配率;
步骤s31、采用一第二计算单元,用于计算出所述演唱音频的每节拍的音高值;
步骤s32、采用一第二对比单元,用于将所述演唱音频的每节拍的音高值与所述原唱歌曲的每节拍的音高值进行对比,以获取音高正确分值;
步骤s33、采用一第三计算单元,用于根据所述演唱类型匹配率、所述音速匹配率、所述声音强度变化匹配率以及所述音高正确分值,计算出所述最后分值。
优选的,还包括步骤s5,采用一建议模块,用于根据所述演唱类型匹配率、所述音速匹配率、所述声音强度变化匹配率以及所述音高正确分值提出评价之后,给演唱者相应的建议。
本发明的技术方案的有益效果在于:提供一种演唱歌曲的评价系统及方法,通过算法模块根据处理模块获取的第一特征参数和训练模块对每首原唱歌曲的分段音频的音速和声音强度变化分别进行训练后获取的第二特征参数与演唱音频对应时段的第三特征参数计算出一最后分值后,再针对学生练习或考试所唱歌曲进行评价,且相应的给学生提供量身定制的建议,帮助学生提高演唱水平。
附图说明
参考所附附图,以更加充分的描述本发明的实施例。然而,所附附图仅用于说明和阐述,并不构成对本发明范围的限制。
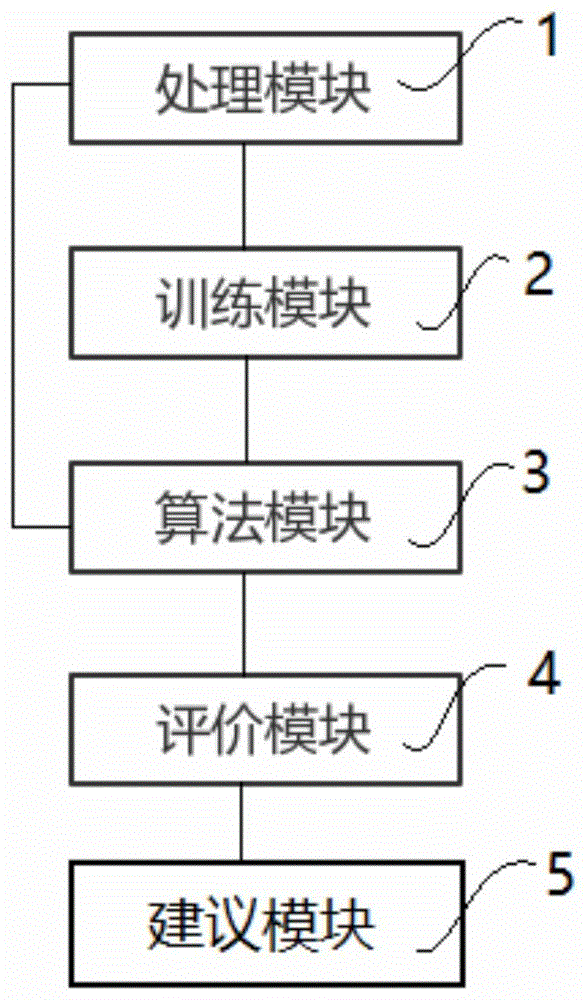
图1为本发明的实施例的评价系统的整体原理框图;
图2为本发明的实施例中的处理模块的原理框图;
图3为本发明的实施例中的训练模块的原理框图;
图4为本发明的实施例中的算法模块的原理框图;
图5为本发明的实施例中的评级方法的整体步骤流程图;
图6为本发明的实施例中的步骤s1的步骤流程图;
图7为本发明的实施例中的步骤s2的步骤流程图;
图8为本发明的实施例中的步骤s3的步骤流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
本发明提供一种演唱歌曲的评价系统,其中,包括:
一处理模块1,用于对每首原唱歌曲的类型进行处理,以提取原唱歌曲的一第一特征参数;
一训练模块2,训练模块2连接处理模块1,用于对每首原唱歌曲的每一分段音频的音速和声音强度变化分别进行训练,以分别提取出每一分段音频的音速和声音强度变化的第二特征参数;
一算法模块3,算法模块3分别连接处理模块1和训练模块2,用于根据第一特征参数以及第二特征参数与一演唱音频对应时段的第三特征参数,计算出一最后分值;
一评价模块4,评价模块4连接算法模块3,根据最后分值以提出相应的评价。
通过上述提供的评价系统,如图1所示,首先通过处理模块1将所有的原唱歌曲进行分类,可获取每首原唱歌曲的类型节拍为,例如,2/4、4/4、3/4、3/8、6/8、9/8、2/2、1/4,也可获取每首原唱歌曲的类型速度,如50-140拍每分钟(其中每10拍为一个分类),从而可以获得每首原唱歌曲的类型或者风格为:欢快或流畅或缓和或舒缓或高亢或热烈或静谧或激烈或火热等,例如原唱歌曲《让世界充满爱》的类型节拍为4/4,其类型速度为76(70-79)拍每分钟,从而获取该原唱歌曲的类型或者风格为舒缓,再进一步处理以提取原唱歌曲的一第一特征参数,以供后续计算评分。
进一步地,通过训练模块2对每首原唱歌曲的每一分段音频的音速和声音强度变化分别进行单独训练,本实施例中,采用的训练方法为cnn(convolutionalneuralnetworks卷积神经网络)和resnet(residualneuralnetwork残差网络),从而来分别提取出大量的每一分段音频的音速和声音强度变化的第二特征参数。
进一步地,通过算法模块3将处理模块1获取的第一特征参数和训练模块2获取的第二特征参数与演唱音频对应时段的第三特征参数,三者进行运算,从而获得现场演唱歌曲的最后分值。
进一步地,通过评价模块4根据算法模块3获取的总分值来给予演唱者相应的评价,帮助学生提高演唱水平。
另外,需要说明的是,本发明中的第一特征参数、第二特征参数以及第三特征参数均为高维特征参数。
在一种优选的实施例中,处理模块1包括:
一收集单元10,用于收集每首原唱歌曲;
一分类单元11,分类单元11连接收集单元10,用于对收集后的每首原唱歌曲的类型进行分类;
一第一训练单元12,第一训练单元12连接分类单元11,用于将分类后的原唱歌曲进行训练;
一第一提取单元13,第一提取单元13连接第一训练单元12,根据第一训练单元12的训练结果以提取出一第一特征参数;
一第一计算单元14,第一计算单元14连接第一提取单元13,用于将第一特征参数与演唱音频对应时段的第三特征参数进行计算,以得出一演唱类型匹配率。
具体地,如图2所示,处理模块1首先通过收集单元10收集所有的原唱歌曲,再对收集后的每首原唱歌曲的类型进行分类,通过获取每首歌曲的节拍、速度,从而得知每首原唱歌曲为哪一种类型或风格;
进一步地,通过第一训练单元11将上述分类好的原唱歌曲采用cnn(convolutionalneuralnetworks卷积神经网络)和resnet(residualneuralnetwork残差网络)算法进行训练,再通过第一提取单元13提取出大量的第一特征参数。
进一步地,通过第一计算单元14将第一特征参数与演唱音频对应时段的第三特征参数进行余弦距离计算,以得出演唱类型匹配率从而得出风格建议。
在一种优选的实施例中,训练模块2包括:
一分段单元20,用于将每首原唱歌曲按照乐谱节拍进行分段,以形成分段音频;
一第二训练单元21,第二训练单元21连接于分段单元20,用于对分段音频中的音速和声音强度变化分别进行训练,以分别提取出每一分段音频的音速和声音强度变化的第二特征参数。
具体地,如图3所示,训练模块2首先通过其中的分段单元20将每首原唱歌曲按照乐谱节拍进行分段,形成每一小分段音频,再通过第二训练单元21分别对每一小分段音频的音速和声音强度变化分别进行单独训练来分别提取出每一分段音频的音速和声音强度变化的大量的第二特征参数。
在一种优选的实施例中,算法模块3包括:
一第一对比单元30,用于将音速和声音强度变化的第二特征参数与演唱音频对应时段的第三特征参数进行对比,以获取一音速匹配率和一声音强度变化匹配率;
一第二计算单元31,用于计算出演唱音频的每节拍的音高值;
一第二对比单元32,第二对比单元32连接于第二计算单元31,用于将演唱音频的每节拍的音高值与原唱歌曲的每节拍的音高值进行对比,以获取音高正确分值;
一第三计算单元33,第三计算单元33连接第二对比单元32,用于根据演唱类型匹配率、音速匹配率、声音强度变化匹配率以及音高正确分值,计算出一最后分值。
具体地,如图4所示,算法模块3首先通过第一对比单元30将音速和声音强度变化的第二特征参数与演唱音频对应时段的第三特征参数进行对比,从而获取音速匹配率和声音强度变化匹配率。
进一步地,通过第二计算单元31采用fft(fastfouriertransform快速傅里叶变换)计算出演唱音频的每节拍的音高值,再通过第二对比单元32将演唱音频的每节拍的音高值与原唱歌曲的每节拍的音高值进行对比,若演唱音频的每节拍的音高值正确则得分1,错误则得分0,从而计算出音高正确分值,再采用第三计算单元33根据下述公式来获取最后分值:
其中,s表示最后分值;
maxs表示总分;
o表示音速匹配率;
p表示声音强度变化匹配率;
n表示音高正确分值;
x表示歌曲的小节数量;
y表示歌曲的节拍数量;
i表示音速与声音强度变化的得分权值;
j表示音高正确分值的得分权值。
在一种较优的实施例中,还包括一建议模块5,建议模块5连接评价模块4,用于根据演唱类型匹配率、音速匹配率、声音强度变化匹配率以及音高正确分值提出评价之后,给演唱者相应的建议。
具体地,如图1所示,在根据演唱类型匹配率、音速匹配率、声音强度变化匹配率以及音高正确分值提出评价之后,再相应地对演唱者给出建议,例如通过歌曲《北京欢迎你》中的第18小节第2拍为例,原唱歌曲的音频本应该是由低到高,但是演唱者可能会唱错成由高到低,因此,可建议该演唱者注意声音强度的掌握,从而针对第18小节第2拍反复练习,使得演唱者的演唱水平提高。
本发明还提供一种演唱歌曲的评价方法,包括如上述中的任一所述的演唱歌曲的评价系统,评价方法包括:
步骤s1、采用一处理模块1,对每首原唱歌曲的类型进行处理,以提取原唱歌曲的一第一特征参数;
步骤s2、采用一训练模块2,用于对每首原唱歌曲的每一分段音频的音速和声音强度变化分别进行训练,以分别提取出每一分段音频的音速和声音强度变化的第二特征参数;
步骤s3、采用一算法模块3,用于根据第一特征参数以及第二特征参数与一演唱音频对应时段的第三特征参数,计算出一最后分值;
步骤s4、采用一评价模块4,用于根据最后分值以提出相应的评价。
通过上述提供的评价方法,如图5所示,首先采用处理模块1将所有的原唱歌曲进行分类,可获取每首原唱歌曲的类型节拍为,例如,2/4、4/4、3/4、3/8、6/8、9/8、2/2、1/4,也可获取每首原唱歌曲的类型速度,如50-140拍每分钟(其中每10拍为一个分类),从而可以获得每首原唱歌曲的类型或者风格为:欢快或流畅或缓和或舒缓或高亢或热烈或静谧或激烈或火热等,例如原唱歌曲《让世界充满爱》的类型节拍为4/4,其类型速度为76(70-79)拍每分钟,从而获取该原唱歌曲的类型或者风格为舒缓,再进一步处理以提取原唱歌曲的一第一特征参数,以供后续计算评分。
进一步地,采用训练模块2对每首原唱歌曲的每一分段音频的音速和声音强度变化分别进行单独训练,本实施例中,采用的训练方法为cnn(convolutionalneuralnetworks卷积神经网络)和resnet(residualneuralnetwork残差网络),从而来分别提取出大量的每一分段音频的音速和声音强度变化的第二特征参数。
进一步地,采用算法模块3将处理模块1获取的第一特征参数和训练模块2获取的第二特征参数与演唱音频对应时段的第三特征参数,三者进行运算,从而获得现场演唱歌曲的最后分值。
进一步地,采用评价模块4根据算法模块3获取的总分值来给予演唱者相应的评价,帮助学生提高演唱水平。
另外,需要说明的是,本发明中的第一特征参数、第二特征参数以及第三特征参数均为高维特征参数。
在一种较优的实施例中,于步骤s1中,包括:
步骤s10、采用一收集单元10,用于收集每首原唱歌曲;
步骤s11、采用一分类单元11,用于对收集后的每首原唱歌曲的类型进行分类;
步骤s12、采用一第一训练单元12,用于将分类后的原唱歌曲进行训练;
步骤s13、采用一第一提取单元13,用于根据第一训练单元12的训练结果以提取出一第一特征参数;
步骤s14、采用一第一计算单元14,用于将第一特征参数与演唱音频对应时段的第三特征参数进行计算,以得出一演唱类型匹配率。
具体地,如图6所示,步骤s1中,首先采用收集单元10收集所有的原唱歌曲,再对收集后的每首原唱歌曲的类型进行分类,通过获取每首歌曲的节拍、速度,从而得知每首原唱歌曲为哪一种类型或风格;
进一步地,采用第一训练单元11将上述分类好的原唱歌曲采用cnn(convolutionalneuralnetworks卷积神经网络)和resnet(residualneuralnetwork残差网络)算法进行训练,再采用第一提取单元13提取出大量的第一特征参数。
进一步地,采用第一计算单元14将第一特征参数与演唱音频对应时段的第三特征参数进行余弦距离计算,以得出演唱类型匹配率从而得出风格建议。
在一种较优的实施例中,于步骤s2中,包括:
步骤s20、采用一分段单元20,用于将每首原唱歌曲按照乐谱节拍进行分段,以形成分段音频;
步骤s21、采用一第二训练单元21,用于对分段音频中的音速和声音强度变化分别进行训练,以分别提取出每一分段音频的音速和声音强度变化的第二特征参数。
具体地,如图7所示,于步骤s2中,首先采用分段单元20将每首原唱歌曲按照乐谱节拍进行分段,形成每一小分段音频,再采用第二训练单元21分别对每一小分段音频的音速和声音强度变化分别进行单独训练来分别提取出每一分段音频的音速和声音强度变化的大量的第二特征参数。
在一种较优的实施例中,于步骤s3中,包括:
步骤s30、采用一第一对比单元30,用于将音速和声音强度变化的第二特征参数与演唱音频对应时段的第三特征参数进行对比,以获取一音速匹配率和一声音强度变化匹配率;
步骤s31、采用一第二计算单元31,用于计算出演唱音频的每节拍的音高值;
步骤s32、采用一第二对比单元32,用于将演唱音频的每节拍的音高值与原唱歌曲的每节拍的音高值进行对比,以获取音高正确分值;
步骤s33、采用一第三计算单元33,用于根据演唱类型匹配率、音速匹配率、声音强度变化匹配率以及音高正确分值,计算出最后分值。
具体地,如图8所示,与步骤s3中,首先采用第一对比单元30将音速和声音强度变化的第二特征参数与演唱音频对应时段的第三特征参数进行对比,从而获取音速匹配率和声音强度变化匹配率。
进一步地,采用第二计算单元31采用fft(fastfouriertransform快速傅里叶变换)计算出演唱音频的每节拍的音高值,再通过第二对比单元32将演唱音频的每节拍的音高值与原唱歌曲的每节拍的音高值进行对比,若演唱音频的每节拍的音高值正确则得分1,错误则得分0,从而计算出音高正确分值,再采用第三计算单元33根据下述公式来获取最后分值:
其中,s表示最后分值;
maxs表示总分;
o表示音速匹配率;
p表示声音强度变化匹配率;
n表示音高正确分值;
x表示歌曲的小节数量;
y表示歌曲的节拍数量;
i表示音速与声音强度变化的得分权值;
j表示音高正确分值的得分权值。
在一种较优的实施例中,还包括步骤s5,采用一建议模块5,用于根据演唱类型匹配率、音速匹配率、声音强度变化匹配率以及音高正确分值提出评价之后,给演唱者相应的建议。
具体地,如图5所示,在根据演唱类型匹配率、音速匹配率、声音强度变化匹配率以及音高正确分值提出评价之后,采用建议模块5相应地对演唱者给出建议,例如通过歌曲《北京欢迎你》中的第18小节第2拍为例,原唱歌曲的音频本应该是由低到高,但是演唱者可能会唱错成由高到低,因此,可建议该演唱者注意声音强度的掌握,从而针对第18小节第2拍反复练习,使得演唱者的演唱水平提高。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!