一种基于集成学习的混合模型语音情感识别方法及系统与流程
本发明涉及语音情感识别技术领域,具体而言,涉及一种基于集成学习的混合模型语音情感识别方法及系统。
背景技术:
语音识别技术是人机交互中重要的方式和手段之一,语音情感识别可以帮助机器更好的理解人的感情变化从而提升用户体验,给出更完美的解决方案,使机器更加智能。语音情感识别技术可以应用在很多场景中。如:工作中电话客服服务态度监测;生活中司机驾驶疲劳情感监控;教学上可进行教师在线课程情感监控;在医疗中可检测患者情感变化从而进行辅助诊断和治疗。
现有的基于深度学习的神经网络方法可以达到很好的识别效果,但是其网络结构复杂,时间复杂度低,这将导致算法时延高、落地难度大等一系列问题。基于统计学的机器学习方法在算法复杂度上有一定优势,但识别精度较低。本方案基于多集成学习模型及岭回归混合模型,与目前的通用方法相比,可以提升语音情感识别的精度,特别是对于不同情感类型的混淆区分。
技术实现要素:
为解决上述问题,本发明的目的在于提供一种基于多集成学习模型及岭回归混合模型的,对于不同情感类型识别精度高的语音情感识别方法和系统。
为了实现上述目的,本发明提供了一种基于集成学习的混合模型语音情感识别方法,该方法包括以下步骤:
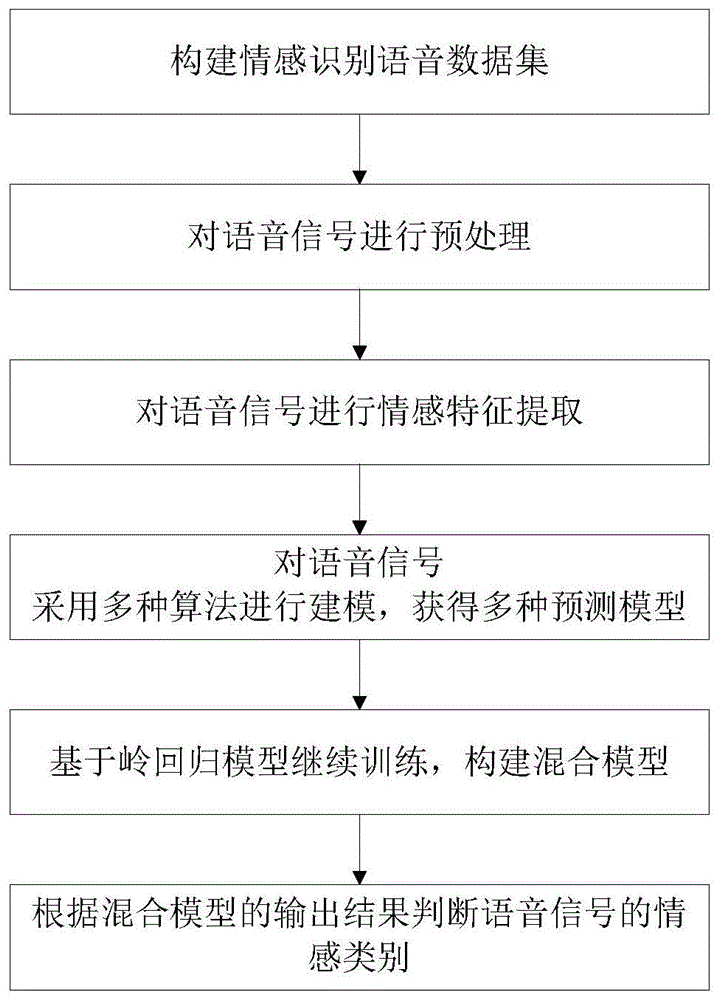
步骤1:构建情感识别语音数据集;
步骤2:对语音信号进行预处理;
步骤3:从步骤2预处理过后的语音信号中提取帧级别具有时序信息的语音信号特征;
步骤4:利用步骤3提取到的语音信号特征分别采用多种算法进行建模,获得多种预测模型;
步骤5:利用步骤4生成的多种预测模型对语音信号进行预测,得到一组预测概率值,将得到的一组预测概率值作为输入数据加入岭回归模型继续训练,构建混合模型;
步骤6:待测语音信号经过步骤2~5处理后,根据混合模型的输出结果判断语音信号的情感类别。
作为本发明进一步的改进,步骤2中,预处理包括以下步骤:
步骤s201:对标准化后的数字信号进行端点检测,去除音频的首尾静音片段;
步骤s202:对语音信号进行预加重;
步骤s203:对步骤s202得到的信号进行分帧处理;
步骤s204:将步骤s203分帧后的每一帧信号进行加窗处理。
作为本发明进一步的改进,步骤4中,采用四种算法建模,包括:基于bagging的rf算法,基于boosting的adaboost算法,基于boosting的gbdt算法,以及基于boosting的xgb算法,生成的四种预测模型为rf模型、adaboost模型、gbdt模型和xbg模型。
作为本发明进一步的改进,步骤5中,构建混合模型具体包括:
步骤s501:将情感识别语音数据集分成训练集和测试集,多种预测模型均使用该训练集训练,分别得到多个预测模型的预测概率值,形成一组预测概率值;
步骤s502:将步骤s501得到的一组预测概率值作为训练数据输入岭回归模型重新训练,构建混合模型。
作为本发明进一步的改进,步骤s201中,使用vad算法语音信号进行端点检测。
作为本发明进一步的改进,步骤s204中,使用汉明窗对信号进行加窗处理,汉明窗函数w(n)如下:
其中,n是窗的宽度。
本发明中,构建情感识别语音数据集包括以下分类方式:
方式一:愤怒和随和;
方式二:中性、生气、悲伤和高兴;
方式三:中性、生气、害怕、高兴、悲伤、厌恶和无聊。
本发明还提供了一种基于集成学习的混合模型语音情感识别系统,该系统包括:
预处理模块,用于对语音信号进行预处理;
信号处理模块,从预处理过的语音信号中提取帧级别具有时序信息的语音信号特征;
集成学习模型构造模块,对信号处理模块处理后的语音信号进行建模,生成多种预测模型;
混合模型构造模块,利用集成学习模型构造模块生成的多种模型对语音信号进行预测,将预测概率值作为输入数据加入岭回归模型继续训练,构建混合模型;
情感识别模块,待测语音信号经过预处理模块、信号处理模块、集成学习模型构造模块和混合模型构造模块处理后,根据混合模型的输出结果判断语音信号的情感类别。
作为本发明进一步的改进,预处理模块包括:
端点检测模块,对采样标准化模块标准化后的数字信号进行端点检测,去除音频的首尾静音片段;
信号预加重模块,对语音信号进行预加重;
分帧处理模块,对信号预加重模块处理后的信号进行分帧处理;
加窗处理模块,对分帧处理模块处理后的每一帧信号进行加窗处理。
作为本发明进一步的改进,采用四种算法建模,包括:基于bagging的rf算法,基于boosting的adaboost算法,基于boosting的gbdt算法,以及基于boosting的xgb算法,生成的四种预测模型为rf模型、adaboost模型、gbdt模型和xbg模型。
作为本发明进一步的改进,混合模型构造模块包括:
模型训练模块,将情感识别语音数据集分成训练集和测试集,多种预测模型均使用该训练集训练,分别得到多个预测模型的预测概率值;
岭回归模型训练模块,将多种预测模型的预测概率值作为训练数据输入岭回归模型重新训练,构建混合模型。
本系统中,语音情感识别分类形式包括:
形式一:愤怒和随和;
形式二:中性、生气、悲伤和高兴;
形式三:中性、生气、害怕、高兴、悲伤、厌恶和无聊。
本发明的有益效果为:通过利用多个集成模型构建混合模型,其鲁棒性更强,算法识别精度更高;同时,将多个集成模型的预测结果利用岭回归模型重新训练,可以更好的削弱不同情感间相互影响,提高语音情感识别的效果。
附图说明
图1为本发明实施例所述的一种基于集成学习的混合模型语音情感识别方法的流程图;
图2为本发明实施例所述的一种基于集成学习的混合模型语音情感识别方法的情感识别分类方式图;
图3为本发明实施例所述的一种基于集成学习的混合模型语音情感识别方法的混合模型结构示意图;
图4为本发明实施例所述的一种基于集成学习的混合模型语音情感识别系统的系统流程图。
具体实施方式
下面通过具体的实施例并结合附图对本发明做进一步的详细描述。
实施例1
如图1-3所示,本发明实施例所述的一种基于集成学习的混合模型语音情感识别方法,该方法包括以下步骤:
步骤1:构建情感识别语音数据集;
对情感识别语音数据集进行划分,语音情感识别分类形式包括二分类,四分类和七分类,如图3所示:
二分类:愤怒和随和;
四分类:中性、生气、悲伤和高兴;
七分类:中性、生气、害怕、高兴、悲伤、厌恶和无聊。
其中四分类和七分类均使用的公开数据集,二分类是基于四分类数据集而来,将四分类数据集中的中性和高兴归纳为随和,生气和悲伤归纳为愤怒,从而得到二分类数据集。
步骤2:对语音信号进行预处理;
预处理包括以下步骤:
步骤s201:使用vad算法对语音信号进行端点检测,去除音频的首尾静音片段;
步骤s202:对语音信号进行预加重,提升高频部分能量,减轻低频干扰;
通过下面的方法进行预加重:
y(t)=x(t)-αx(t-1),0.95<α<0.99
其中,x(t)是t时刻语音信号的幅值,x(t-1)是t-1时刻语音信号的幅值,y(t)是预加重后信号t时刻的幅值,α是差分系数,本实施例中,α=0.97。
语音信号往往会有频谱倾斜现象,一般高频部分的幅度会低于低频部分的幅度,预加重可以增大高频部分的幅度,从而达到平衡频谱的作用。
步骤s203:对步骤s202得到的信号进行分帧处理;
由于语音信号的频率是随时间变化而变化的非平稳信号,信号的频率轮廓会随着时间的推移而丢失,为了提取信号的频域特征,需要对信号进行分帧处理,分帧后的帧信号可以看作是平稳信号,进而提取频域上的特征。本实施中,帧长为30ms,帧移为15ms。
步骤s204:将步骤s203分帧后的每一帧信号进行加窗处理。
为了让帧信号两端平滑的衰减,提高频谱的质量,本实施例中使用汉明窗,汉明窗函数如下:
其中,n是窗的宽度,本实施例中,n=512。
步骤3:从步骤2预处理过后的语音信号中提取帧级别具有时序信息的语音信号特征;
具体的,对预处理后的信号,提取其韵律学特征:基频、能量,和频域特征:mfcc特征,特征取平均后并拼接起来。本实施例中,mfcc的特征维度取26,加上基频和能量后,最终的特征维度为28。
步骤4:利用步骤3提取到的语音信号特征分别采用多种算法进行建模,获得多种预测模型;
步骤5:利用步骤4生成的多种预测模型对语音信号进行预测,得到一组预测概率值,将得到的一组预测概率值作为输入数据加入岭回归模型继续训练,构建混合模型;
构建混合模型具体包括:
步骤s501:将情感识别语音数据集分成训练集和测试集;多种预测模型均使用该训练集训练,由于预测模型的不同,在同一数据集上可以得到不同的预测结果,形成一组预测概率值。
也可以将情感识别语音数据集分成多份,每一份数据分别作为多种预测模型的预测数据,多种预测模型的预测数据互斥,除作为多种预测模型各自的一组预测数据外,其余几份数据作为多种预测模型各自的训练数据,分别得到多个预测模型的预测概率值,形成一组预测概率值。
步骤s502:将步骤s501得到一组预测概率值的作为训练数据输入岭回归模型重新训练,构建混合模型。
步骤6:待测语音信号经过步骤1~5处理后,根据混合模型的输出结果判断语音信号的情感类别。混合模型输出待测语音信号为各自情绪的概率值,概率值最高的情绪即为该待测语音信号的情感类别。例如:
二分类,对于某待测语音信号,经过预处理,特征提取,输入四种预测模型,得到一组预测概率值,输入混合模型得到最终的预测概率值为[0.33,0.67],第一个值表示该条语音为愤怒的概率,第二个值表示该条语音为随和的概率,则该条语音信号的情绪被识别为随和。
进一步的,步骤4中,采用四种算法建模,包括:
1)基于bagging的随机森林(randomforests,rf)算法。rf为以决策树为基学习器的bagging算法,在rf中构建决策树时,按照以下方法进行节点的属性化分:首先选出具有k个属性的子集,每个属性来自于该决策树节点;然后从该子集中选出一个最优属性进行划分,给出决策结果。
2)基于boosting的自适应增强(adaptiveboosting,adaboost)算法。adaboost通过提高基分类器的错误分类样本权值,降低正确分类样本权值来进行模型训练。
3)基于boosting的梯度提升决策树(gradientboostingdecisiontrees,gbdt)算法。gbdt也以决策树为基分类器,但其利用损失函数的负梯度值作为提升树算法中残差的近似值,从而拟合一颗决策树。
4)基于boosting的(extremegradientboosting,xgb)算法。xgb优化了解析稀疏数据方案,并使用加权分位数图进行有效训练。
生成的四种预测模型为rf模型、adaboost模型、gbdt模型和xbg模型。相应的,将情感识别语音数据集分成训练集和测试集后,四种预测模型均使用该训练集训练,得到不同的预测结果。预测模型的输出是输出了各种情绪的概率值,例如:二分类实验:对于某条输入语音,
预测模型1输出[0.3,0.7]
预测模型2输出[0.25,0.75]
预测模型3输出[0.35,0.65]
预测模型4输出[0.45,0.55]
第一个值表示该条语音为愤怒的概率,第二个值表示该条语音为随和的概率。两者相加为1。
同理:四分类实验:对于某条输入语音,
预测模型1输出[0.1,0.7,0.1,0.1]
预测模型2输出[0.1,0.6,0.2,0.1]
预测模型3输出[0.2,0.5,0.25,0.05]
预测模型4输出[0.3,0.6,0.04,0.06]
第一个值表示该条语音为中性的概率,第二个值表示该条语音为生气的概率,第三个值表示该条语音为悲伤的概率,第四个值表示该条语音为高兴的概率。四者相加为1。七分类实验同理。
进一步的,将四种预测模型的预测概率值作为训练数据输入岭回归模型重新训练,构建混合模型,从而根据混合模型的输出结果判断语音信号的情感类别。
实施例2
如图4所示。本发明实施例所述的一种基于集成学习的混合模型语音情感识别系统,该系统包括:
预处理模块,用于对语音信号进行预处理;
信号处理模块,从预处理过的语音信号中提取帧级别具有时序信息的语音信号特征;
集成学习模型构造模块,对信号处理模块处理后的语音信号进行建模,生成多种预测模型;
混合模型构造模块,利用集成学习模型构造模块生成的多种预测模型对特征进行预测,将预测概率值作为输入数据加入岭回归模型继续训练,构建混合模型;
情感识别模块,将待测语音信号输入到混合模型,根据混合模型的输出结果判断语音信号的情感类别。
其中,预处理模块包括:
端点检测模块,对语音信号进行端点检测,去除音频的首尾静音片段;
信号预加重模块,对语音信号进行预加重;
分帧处理模块,对信号预加重模块处理后的信号进行分帧处理;
加窗处理模块,对分帧处理模块处理后的每一帧信号进行加窗处理。
混合模型构造模块包括:
模型训练模块,将情感识别语音数据集分成训练集和测试集,多种预测模型均使用该训练集训练,分别得到多个预测模型的预测概率值;
岭回归模型训练模块,将多种预测模型的预测概率值作为训练数据输入岭回归模型重新训练,构建混合模型。
本实施例中采用四种算法建模,包括:基于bagging的rf算法,基于boosting的adaboost算法,基于boosting的gbdt算法,以及基于boosting的xgb算法,生成的四种预测模型为rf模型、adaboost模型、gbdt模型和xbg模型。
该系统通过预处理模块对语音信号进行预处理,预处理时,对语音信号使用vad算法进行端点检测,去除音频的首尾静音片段;然后对语音信号进行预加重;并对预加重处理后的信号进行分帧处理(帧长为30ms,帧移为15ms),最后对分帧处理后的每一帧信号采用汉明窗进行加窗处理。进一步的,信号处理模块从预处理过的语音信号中提取帧级别具有时序信息的语音信号特征,集成学习模型构造模块通过四种算法对信号处理模块处理后的语音信号进行建模,生成rf模型、adaboost模型、gbdt模型和xbg模型四种模型;进一步的,混合模型构造模块中将情感识别语音数据集分成训练集和测试集,四种预测模型均使用该训练集训练,由于预测模型的不同,在同一数据集上可以得到不同的预测结果,最后通过岭回归模型将四种预测模型的预测结果作为训练数据输入岭回归模型重新训练,构建混合模型;识别时,待测语音信号经过预处理模块、信号处理模块、集成学习模型构造模块和混合模型构造模块处理后,根据混合模型的输出结果判断语音信号的情感类别,情感识别模块根据混合模型的输出结果判断语音信号的情感类别。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!