一种基于目标适应子空间学习的跨库语音情感识别方法与流程
本发明属于语音识别领域,特别涉及了一种跨库语音情感识别方法。
背景技术:
语音情感识别在娱乐、教育、医疗等领域的应用越来越广泛。比如,在娱乐领域,智能语音助手的出现,使得智能机器的功能得到完善,从而广泛应用;在教育领域,可通过语音中情感的识别来判断学生的上课情况,以此来监测学生的上课热情;在医疗领域,如对于抑郁症患者的治疗,可有效的解决因人力资源缺乏所引起的患者交流困难的问题。
传统的语音情感识别研究都是基于单一的数据库领域的研究,而在实际场景中的语音数据通常由于其采集条件及背景等的不同造成训练数据集和测试数据集之间的差异较大,而跨数据库的语音情感识别更符合实际应用场景中的研究,因此对于跨数据库的语音情感识别研究意义重大。
技术实现要素:
为了解决上述背景技术提到的技术问题,本发明提出了一种基于目标适应子空间学习的跨库语音情感识别方法。
为了实现上述技术目的,本发明的技术方案为:
一种基于目标适应子空间学习的跨库语音情感识别方法,首先,分别提取源数据库和目标数据库中语音样本的特征;其次,采用提取到的特征训练目标适应子空间学习模型,该模型的目标在于寻找一个投影空间使得目标数据库中的语音样本能够被源数据库中的语音样本表示,同时通过学习投影矩阵来预测目标数据库中语音样本的情感种类并减小源域与目标域之间的特征分布差异;最后,对训练好的模型进行测试并得到最终的语音情感识别结果。
进一步地,所述目标适应子空间学习模型的目标函数如下:
上式中,ls为标签矩阵,是一个c×m的矩阵,其元素使用二进制值表示,c为情感种类,m为源数据库中语音样本的个数;c为回归系数,是一个d×c的矩阵,d为特征维度,上标t表示转置;ds为源数据库的特征矩阵;
进一步地,所述目标适应子空间学习模型的求解方法如下:
(a)固定z,更新回归系数c:
(b)固定回归系数c,更新z:
上式中,
进一步地,在步骤(a)中,采用交替方向迭代法求解回归系数c的更新值。
进一步地,在步骤(b)中,采用lasso回归法求解zi的更新值。
采用上述技术方案带来的有益效果:
本发明为满足实际情景中语音情感识别技术的研究并有效减少不同数据库之间数据特征分布与边缘分布的不同,提出一种减小不同数据库之间的特征分布差异的模型,即目标适应子空间学习模型,此模型的主要思想是找到一个投影的子空间使得目标语音样本能够被源语音样本表示,同时通过学习一个回归投影矩阵来预测目标样本的情感种类并减小源域与目标域之间的特征分布的差异,以此来实现跨数据库语音情感的识别。
附图说明
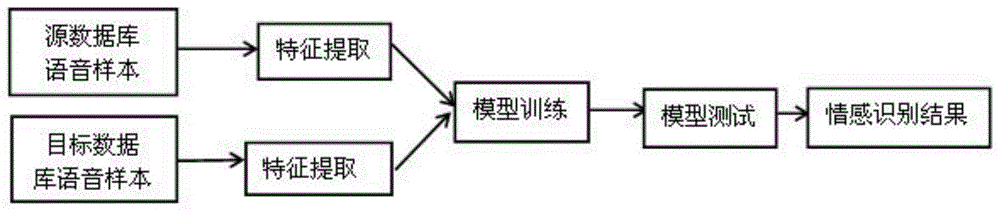
图1是本发明的方法流程图。
具体实施方式
以下将结合附图,对本发明的技术方案进行详细说明。
本发明设计了一种基于目标适应子空间学习的跨库语音情感识别方法,如图1所示,首先,分别提取源数据库和目标数据库中语音样本的特征;其次,采用提取到的特征训练目标适应子空间学习模型,该模型的目标在于寻找一个投影空间使得目标数据库中的语音样本能够被源数据库中的语音样本表示,同时通过学习投影矩阵来预测目标数据库中语音样本的情感种类并减小源域与目标域之间的特征分布差异;最后,对训练好的模型进行测试并得到最终的语音情感识别结果。
在本实施例中,所述目标适应子空间学习模型的目标函数如下:
上式中,ls为标签矩阵,是一个c×m的矩阵,其元素使用二进制值表示,c为情感种类,m为源数据库中语音样本的个数;c为回归系数,是一个d×c的矩阵,d为特征维度,上标t表示转置;ds为源数据库的特征矩阵;
在本实施例中,求解上述模型,可以分为以下两步:
第1步、固定z,更新回归系数c:
此更新选用交替方向迭代(adm)法来求得最优化回归系数,为方便求解,可将此目标方程改写为等价的方程:
上式中,q为引入的换算变量,
上式中,s和l是拉格朗日乘子,其中l>0,tr为矩阵的迹。
上述方程的求解算法如下:
①固定z、c、s、l,然后更新q:
②固定z、q、s、l,然后更新c:
c可由定理求解得到,然后求解可得ci如下:
其中,
③更新s和l:
s=s+l(q-c),l=min(ρl,lmax)
其中,ρ>0为方程的超参,lmax为拉格朗日求解过程中矩阵l的最大值。
④检验收敛条件:
||q-c||∞<ε
其中,ε是一个极小的正数,其值趋近于0。
第2步、固定回归系数c,更新z:
此项更新采用lasso回归的方法来求解。
首先选取三个公共的数据库作为实验数据库:berlin数据库,enterface数据库和afew4.0数据库,然后选取其中的音频样本对其分别进行特征提取,使用提取的特征对模型进行训练,然后将训练后的模型进行测试,最后使用此模型对其进行六组对比实验,实验结果表明此模型相比其他方法都可取得有效的结果,最后的实验结果采用uar作为最终的评价指标。基于此模型,还将其与其他域适应方法及最小二乘回归方法进行对比,最终证明其实验结果的有效性,结果如表1所示(b代表berlin数据库;e代表enterface数据库;a代表afew4.0数据库;btoe表示源数据库为berlin数据库,目标数据库为enterface数据库)。
表1
实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!