一种基于声纹识别的个性化智能家居安全控制系统及方法与流程
本发明属于智能家居技术领域,具体涉及一种基于声纹识别的个性化智能家居安全控制系统及方法的设计。
背景技术:
智能家居(smarthome)是以住宅为平台,利用综合布线技术、网络通信技术、安全防范技术、自动控制技术、音视频技术将家居生活有关的设施集成,构建高效的住宅设施与家庭日程事务的管理系统,提升家居安全性、便利性、舒适性、艺术性,并实现环保节能的居住环境。
现有智能家居的语音控制系统大多单纯基于语义识别技术,该技术缺乏对家居安全性的保障,且容易受用户方言,语气,语言的影响,导致系统普适性差,识别误差大等问题。同时,现有智能家居中的语音安全认证仅把说话人识别和说话人认证纳入安全认证范围,只有事先录入语音且具有使用权限的施令者才能对智能家电实施操作。该方式存在明显的缺点,无法对说话人属性(年龄以及性别)进行分类,缺乏提供个性化服务的能力。现实情况下,一般将系统的终端用户分为房屋主人以及客人,往往客人也应当具有对某些家电的操作权限,且需要根据客人的属性分类细分权限范围。此外,现有的智能家居系统普遍缺乏对复杂背景下语音识别的考虑,当室内背景噪音较大时,将极大地影响后续说话人识别的准确度及系统处理响应速度;在强噪音情况下,说话人发出的指令语音甚至会被完全淹没。
技术实现要素:
本发明的目的是为了解决现有智能家居的语音控制系统存在的易受用户个人语音特质影响导致识别误差较大,无法对用户属性分类导致难以提供个性化服务能力以及在复杂背景环境下识别准确率低下,系统响应速度慢和用户指令易丢失等问题,提出了一种基于声纹识别的个性化智能家居安全控制系统及方法。
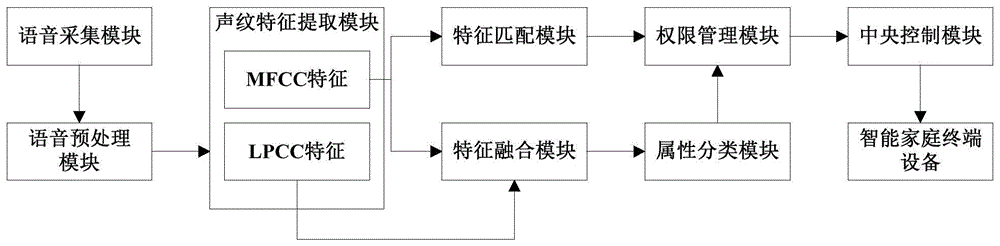
本发明的技术方案为:一种基于声纹识别的个性化智能家居安全控制系统,包括语音采集模块、语音预处理模块、声纹特征提取模块、特征匹配模块、特征融合模块、属性分类模块、权限管理模块、中央控制模块和智能家庭终端设备。
语音采集模块用于采集家居环境中的语音信息。
语音预处理模块用于对语音采集模块采集到的语音信息进行预处理。
声纹特征提取模块用于提取预处理后的语音信息中基于声道模型的lpcc特征以及基于人耳听觉特性的mfcc特征,并根据mfcc特征构建mfcc声纹模型。
特征匹配模块用于对mfcc声纹模型和声纹库中的用户声纹模型进行特征匹配,并计算得到两者的相似度得分。
特征融合模块用于对lpcc特征和mfcc特征进行特征融合,得到混合特征向量。
属性分类模块用于将混合特征向量输入分类模型,得到说话人的年龄及性别属性。
权限管理模块用于将lpcc特征及mfcc特征与语义文字库中的指令文字进行语义匹配,并将语义匹配结果与权限规则库中的规则进行匹配,判断说话人是否具备执行词条指令的权限。
中央控制模块用于将具有权限的用户指令转换为对应的机器指令,并发送给指定智能家庭终端设备。
本发明还提供了一种基于声纹识别的个性化智能家居安全控制方法,包括以下步骤:
s1、通过语音采集模块采集家居环境中的语音信息,并将60hz~6khz范围内的语音流作为原始语音信息发送至语音预处理模块。
s2、通过语音预处理模块对原始语音信息进行预处理。
s3、通过声纹特征提取模块分别提取预处理后的语音信息中基于声道模型的lpcc特征以及基于人耳听觉特性的mfcc特征。
s4、加载通过resnet训练好的声纹模型,并基于声纹模型和mfcc特征构建mfcc声纹模型。
s5、在特征匹配模块中,采用特征匹配算法对mfcc声纹模型和声纹库中的用户声纹模型进行特征匹配,并计算得到两者的相似度得分。
s6、判断相似度得分是否大于预设阈值,若是则进入步骤s9,否则进入步骤s7。
s7、在特征融合模块中,根据fisher准则对lpcc特征和mfcc特征进行特征融合,得到混合特征向量。
s8、加载通过高斯混合模型训练好的分类模型,并将混合特征向量输入分类模型,得到说话人的年龄及性别属性。
s9、将lpcc特征及mfcc特征与语义文字库中的指令文字进行语义匹配,得到指令语义。
s10、在权限管理模块中,将特定属性说话人的指令语义与权限规则库中的规则进行匹配,判断说话人是否具备执行词条指令的权限,若是则进入步骤s11,否则向用户反馈一条无权限消息,结束控制流程。
s11、将具有权限的用户指令传输给中央控制模块。
s12、通过中央控制模块将具有权限的用户指令转换为对应的机器指令,并发送给指定智能家庭终端设备,结束控制流程。
进一步地,步骤s2包括以下分步骤:
s21、对原始语音信息中的语音信号进行预加重,提升语音信号的高频分量。
s22、对语音信号进行分帧加窗,并通过fft变换获得每一帧信号的频谱。
s23、计算得到每一帧信号的谱能量,并根据每一帧信号的谱能量计算得到fft中每个频谱分量的概率密度函数。
s24、根据每个频谱分量的概率密度函数计算每一帧信号的谱熵值。
s25、通过预设的判决门限来检测每一帧的谱熵值,将谱熵值小于判决门限对应帧作为语音信息的边界端点,完成对原始语音信息的预处理。
进一步地,步骤s24中计算每一帧信号的谱熵值的公式为:
其中h(i)表示第i帧信号的谱熵值,p(n,i)表示第i帧信号第n个频谱分量的概率密度,n表示fft中频率成分的所有分量数。
进一步地,步骤s5中声纹库中的用户声纹模型的获取方法为:
a1、在安静的环境下,通过语音采集模块采集用户的语音信息。
a2、通过语音预处理模块对用户的语音信息进行预处理。
a3、通过声纹特征提取模块提取预处理后的语音信息中基于人耳听觉特性的mfcc特征。
a4、加载通过resnet训练好的声纹模型,并基于声纹模型和mfcc特征构建mfcc声纹模型,并将该mfcc声纹模型作为用户声纹模型存入声纹库。
进一步地,步骤s7包括以下分步骤:
s71、将lpcc特征和mfcc特征转化为两个特征矩阵。
s72、对两个特征矩阵进行拼接,得到拼接向量。
s73、依次选取拼接向量中的各维特征,并按照年龄和性别的不同组成构建观测样本集合。
s74、通过fisher准则计算得到观测样本集合中各维特征的判决函数值。
s75、比较各维特征判决函数值的大小,选取预设数量的最大特征维数组成混合特征向量。
进一步地,步骤s74中判决函数值的计算公式为:
其中rfisher表示判决函数值,
进一步地,步骤s10中权限规则库中的规则的设定方法为:
b1、指定已录入用户对智能家居的使用权限。
b2、指定特定属性的客人所具有的使用权限。
本发明的有益效果是:
(1)本发明可以基于用户声纹判定该用户是否为家庭合法用户,并且基于声纹的指令检测免去了用户语言、语气和方言所带来的干扰,使得控制系统的普适性和鲁棒性都有了较大的提升。
(2)本发明提供的属性分类功能扩充了智能家居安全系统的个性化服务功能,使得非认证用户也能享受主人预设的家居模块。
(3)本发明在语音预处理中给出的措施大大减少了环境噪音给语音识别带来的干扰,使用户指令能更高效准确的被系统识别。
附图说明
图1所示为本发明实施例一提供的一种基于声纹识别的个性化智能家居安全控制系统框图。
图2所示为本发明实施例二提供的一种基于声纹识别的个性化智能家居安全控制方法流程图。
具体实施方式
现在将参考附图来详细描述本发明的示例性实施方式。应当理解,附图中示出和描述的实施方式仅仅是示例性的,意在阐释本发明的原理和精神,而并非限制本发明的范围。
实施例一:
本发明实施例提供了一种基于声纹识别的个性化智能家居安全控制系统,如图1所示,包括语音采集模块、语音预处理模块、声纹特征提取模块、特征匹配模块、特征融合模块、属性分类模块、权限管理模块、中央控制模块和智能家庭终端设备。
其中,语音采集模块用于采集家居环境中的语音信息。
语音预处理模块用于对语音采集模块采集到的语音信息进行预处理。
本发明实施例中,如果是在安静的家居环境中采集得到的语音信息,使用常规的预处理方法对用户语音信息进行处理即可,不必过多考虑对环境噪音的特殊处理;如果是在噪声较大的家居环境中采集得到的语音信息,则需要对语音信息进行预加重、加窗、分帧、基于谱熵的端点检测等处理,以降低语音噪声,得到更均匀平滑的语音信号,提高后续操作的准确率。
声纹特征提取模块用于提取预处理后的语音信息中基于声道模型的lpcc特征以及基于人耳听觉特性的mfcc特征,并根据mfcc特征构建mfcc声纹模型。
特征匹配模块用于对mfcc声纹模型和声纹库中的用户声纹模型进行特征匹配,并计算得到两者的相似度得分。
特征融合模块用于对lpcc特征和mfcc特征进行特征融合,得到混合特征向量。
属性分类模块用于将混合特征向量输入分类模型,得到说话人的年龄及性别属性。
权限管理模块用于将lpcc特征及mfcc特征与语义文字库中的指令文字进行语义匹配,并将语义匹配结果与权限规则库中的规则进行匹配,判断说话人是否具备执行词条指令的权限。
中央控制模块用于将具有权限的用户指令转换为对应的机器指令,并发送给指定智能家庭终端设备。
实施例二:
本发明实施例提供了一种基于声纹识别的个性化智能家居安全控制方法,如图2所示,包括以下步骤s1~s12:
s1、通过语音采集模块采集家居环境中的语音信息,并将60hz~6khz范围内的语音流作为原始语音信息发送至语音预处理模块。
s2、通过语音预处理模块对原始语音信息进行预处理。
通常在真实环境下会存在环境噪声,包括设备音、白噪声、多说话人等情况,需要对原始语音信息进行预加重、加窗、分帧、基于谱熵的端点检测等处理,以降低语音噪声,得到更均匀平滑的语音信号,提高后续操作的准确率。因此,步骤s2包括以下分步骤s21~s25:
s21、对原始语音信息中的语音信号进行预加重,提升语音信号的高频分量。
s22、对语音信号进行分帧加窗,并通过fft变换获得每一帧信号的频谱。
s23、计算得到每一帧信号的谱能量,并根据每一帧信号的谱能量计算得到fft中每个频谱分量的概率密度函数。
s24、根据每个频谱分量的概率密度函数计算每一帧信号的谱熵值,计算公式为:
其中h(i)表示第i帧信号的谱熵值,p(n,i)表示第i帧信号第n个频谱分量的概率密度,n表示fft中频率成分的所有分量数。
s25、通过预设的判决门限来检测每一帧的谱熵值,将谱熵值小于判决门限对应帧作为语音信息的边界端点,完成对原始语音信息的预处理。
s3、通过声纹特征提取模块分别提取预处理后的语音信息中基于声道模型的lpcc特征以及基于人耳听觉特性的mfcc特征。
s4、加载通过resnet训练好的声纹模型,并基于声纹模型和mfcc特征构建mfcc声纹模型。
s5、在特征匹配模块中,采用特征匹配算法对mfcc声纹模型和声纹库中的用户声纹模型进行特征匹配,并计算得到两者的相似度得分。
本发明实施例中,声纹库中的用户声纹模型的获取方法为:
a1、在安静的环境下,通过语音采集模块采集用户的语音信息。
a2、通过语音预处理模块对用户的语音信息进行预处理。
由于录制环境较为安静,且用户靠近语音采集模块,因此步骤a2中采用常规的预处理方法对用户的语音信息进行处理即可,不必过多考虑对环境噪音的特殊处理。
a3、通过声纹特征提取模块提取预处理后的语音信息中基于人耳听觉特性的mfcc特征。
a4、加载通过resnet训练好的声纹模型,并基于声纹模型和mfcc特征构建mfcc声纹模型,并将该mfcc声纹模型作为用户声纹模型存入声纹库。
s6、判断相似度得分是否大于预设阈值,若是则说明在声纹库中匹配到了预先录入的说话人,进入步骤s9,否则说明没有在声纹库中匹配到对应的说话人,进入步骤s7。
本发明实施例中,若存在多个相似度得分大于预设阈值的情况,则将最高相似度得分的用户作为目标说话人。
s7、在特征融合模块中,根据fisher准则对lpcc特征和mfcc特征进行特征融合,得到混合特征向量。
步骤s7包括以下分步骤s71~s75:
s71、将lpcc特征和mfcc特征转化为两个特征矩阵。
s72、对两个特征矩阵进行拼接,得到拼接向量。
s73、依次选取拼接向量中的各维特征,并按照年龄和性别的不同组成构建观测样本集合。
s74、通过fisher准则计算得到观测样本集合中各维特征的判决函数值,计算公式为:
其中rfisher表示判决函数值,
s75、比较各维特征判决函数值的大小,选取预设数量的最大特征维数组成混合特征向量。
s8、加载通过高斯混合模型训练好的分类模型,并将混合特征向量输入分类模型,得到说话人的年龄及性别属性。
s9、将lpcc特征及mfcc特征与语义文字库中的指令文字进行语义匹配,得到指令语义。
s10、在权限管理模块中,将特定属性说话人的指令语义与权限规则库中的规则进行匹配,判断说话人是否具备执行词条指令的权限,若是则进入步骤s11,否则向用户反馈一条无权限消息,结束控制流程。
本发明实施例中,权限规则库中的规则的设定方法为:
b1、指定已录入用户对智能家居的使用权限,例如家庭中老人和小孩具有使用电视和空调的权限,不具有使用厨房家电的权限等。
b2、指定特定属性的客人所具有的使用权限,例如年龄在18岁以上的客人具有使用电灯的权限等。
s11、将具有权限的用户指令传输给中央控制模块。
s12、通过中央控制模块将具有权限的用户指令转换为对应的机器指令,并发送给指定智能家庭终端设备,结束控制流程。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!