语音识别纠错方法、相关设备及可读存储介质与流程
本申请涉及语音识别技术领域,更具体的说,是涉及一种语音识别纠错方法、相关设备及可读存储介质。
背景技术:
近几年来,人工智能设备逐渐走入普通大众的生活、工作中,成为不可或缺的一部分,这些都得力于人工智能技术的飞速发展。而语音交互作为最自然的一种人机交互方式,广泛应用于各种人工智能设备中,使得人类与机器可以进行无障碍交流。语音交互过程中,基于语音识别技术,可以让机器“听懂”人类的语言,进而为人类提供服务。
目前,基于深度学习的语音识别技术已经日趋成熟,传统语音识别模型在通用场景下的识别准确率已经达到令人满意的效果,但是在一些特殊场景(例如专业领域)下的语音内容中,通常存在一些专业词汇,这类词汇在通用场景下出现的频率较小,导致传统语音识别模型对该类词汇的覆盖较差。在一些特殊场景下,待识别语音中包含该类词汇,采用传统语音识别模型对待识别语音进行识别,非常容易出现识别错误的情况,导致语音识别准确率低下。
因此,在一些特殊场景(例如专业领域)下,如何提升语音识别准确率,成为本领域技术人员亟待解决的技术问题。
技术实现要素:
鉴于上述问题,提出了本申请以便提供一种语音识别纠错方法、相关设备及可读存储介质。具体方案如下:
一种语音识别纠错方法,所述方法包括:
获取待识别的语音数据及其第一次识别结果;
从所述第一次识别结果中提取关键词,所述关键词是具有领域特性的专业词汇;
参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果;
根据所述第二次识别结果,确定最终的识别结果。
可选地,所述参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果,包括:
获取所述语音数据的声学特征;
将所述语音数据的声学特征、所述第一次识别结果以及所述关键词,输入预先训练的语音纠错识别模型,得到第二次识别结果,所述语音纠错识别模型是利用纠错训练数据集对预设模型进行训练得到的;
其中,所述纠错训练数据集中包括至少一组纠错训练数据,每组纠错训练数据包括一条语音数据对应的声学特征、所述一条语音数据对应的文本、所述一条语音数据对应的第一次识别结果以及所述第一次识别结果中的关键词。
可选地,所述将所述语音数据的声学特征、所述第一次识别结果以及所述关键词,输入预先训练的语音纠错识别模型,得到第二次识别结果,包括:
利用所述语音纠错识别模型对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,并基于计算结果,得到第二次识别结果。
可选地,所述利用所述语音纠错识别模型对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,并基于计算结果,得到第二次识别结果,包括:
利用所述语音纠错识别模型的编码层和注意力层,分别对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,得到所述计算结果;
利用所述语音纠错识别模型的解码层,对所述计算结果进行解码,得到第二次识别结果。
可选地,所述利用所述语音纠错识别模型对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,并基于计算结果,得到第二次识别结果,包括:
对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行合并,得到合并向量;
利用所述语音纠错识别模型的编码层和注意力层,对所述合并向量进行编码以及注意力计算,得到所述计算结果;
利用所述语音纠错识别模型的解码层,对所述计算结果进行解码,得到第二次识别结果。
可选地,所述利用所述语音纠错识别模型的编码层和注意力层,分别对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,得到所述计算结果,包括:
利用所述语音纠错识别模型的编码层,分别对每一目标对象进行编码,得到所述每一目标对象的声学高级特征;
利用所述语音纠错识别模型的注意力层,分别对所述每一目标对象相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果,进行注意力计算,得到所述每一目标对象相关的隐层状态;
利用所述语音纠错识别模型的注意力层,分别对所述每一目标对象的声学高级特征以及所述每一目标对象相关的隐层状态,进行注意力计算,得到所述每一目标对象相关的语义向量;
其中,所述目标对象包括所述语音数据的声学特征、所述第一次识别结果以及所述关键词。
可选地,所述利用所述语音纠错识别模型的编码层和注意力层,对所述合并向量进行编码以及注意力计算,得到所述计算结果,包括:
利用所述语音纠错识别模型的编码层,对所述合并向量进行编码,得到所述合并向量的声学高级特征;
利用所述语音纠错识别模型的注意力层,对所述合并向量相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果,进行注意力计算,得到所述合并向量相关的隐层状态;
利用所述语音纠错识别模型的注意力层,对所述合并向量的声学高级特征以及所述合并向量相关的隐层状态,进行注意力计算,得到所述合并向量相关的语义向量。
可选地,所述根据所述第二次识别结果,确定最终的识别结果,包括:
获取所述第一次识别结果的置信度,以及,所述第二次识别结果的置信度;
从所述第一次识别结果以及所述第二次识别结果中,确定置信度高的识别结果为最终的识别结果。
一种语音识别纠错装置,所述装置包括:
获取单元,用于获取待识别的语音数据及其第一次识别结果;
关键词提取单元,用于从所述第一次识别结果中提取关键词,所述关键词是具有领域特性的专业词汇;
语音识别单元,用于参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果;
识别结果确定单元,用于根据所述第二次识别结果,确定最终的识别结果。
可选地,所述语音识别单元,包括:
声学特征获取单元,用于获取所述语音数据的声学特征;
模型处理单元,用于将所述语音数据的声学特征、所述第一次识别结果以及所述关键词,输入预先训练的语音纠错识别模型,得到第二次识别结果,所述语音纠错识别模型是利用纠错训练数据集对预设模型进行训练得到的;
其中,所述纠错训练数据集中包括至少一组纠错训练数据,每组纠错训练数据包括一条语音数据对应的声学特征、所述一条语音数据对应的文本、所述一条语音数据对应的第一次识别结果以及所述第一次识别结果中的关键词。
可选地,模型处理单元,包括:
编码及注意力计算单元,用于利用所述语音纠错识别模型对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算;
识别单元,用于基于计算结果,得到第二次识别结果。
可选地,所述编码以及注意力计算单元包括第一编码以及注意力计算单元,所述识别单元包括第一解码单元;
所述第一编码以及注意力计算单元,用于利用所述语音纠错识别模型的编码层和注意力层,分别对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,得到所述计算结果;
所述第一解码单元,用于利用所述语音纠错识别模型的解码层,对所述计算结果进行解码,得到第二次识别结果。
可选地,所述模型处理单元还包括合并单元,所述编码以及注意力计算单元包括第二编码以及注意力计算单元,所述识别单元包括第二解码单元:
所述合并单元,用于对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行合并,得到合并向量;
所述第二编码以及注意力计算单元,用于利用所述语音纠错识别模型的编码层和注意力层,对所述合并向量进行编码以及注意力计算,得到所述计算结果;
所述第二解码单元,用于利用所述语音纠错识别模型的解码层,对所述计算结果进行解码,得到第二次识别结果。
可选地,所述第一编码以及注意力计算单元,包括:
第一编码单元,用于利用所述语音纠错识别模型的编码层,分别对每一目标对象进行编码,得到所述每一目标对象的声学高级特征;
第一注意力计算单元,用于利用所述语音纠错识别模型的注意力层,分别对所述每一目标对象相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果,进行注意力计算,得到所述每一目标对象相关的隐层状态;以及,利用所述语音纠错识别模型的注意力层,分别对所述每一目标对象的声学高级特征以及所述每一目标对象相关的隐层状态,进行注意力计算,得到所述每一目标对象相关的语义向量;其中,所述目标对象包括所述语音数据的声学特征、所述第一次识别结果以及所述关键词。
可选地,所述第二编码以及注意力计算单元,包括:
第二编码单元,用于利用所述语音纠错识别模型的编码层,对所述合并向量进行编码,得到所述合并向量的声学高级特征;
第二注意力计算单元,用于利用所述语音纠错识别模型的注意力层,对所述合并向量相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果,进行注意力计算,得到所述合并向量相关的隐层状态;以及,利用所述语音纠错识别模型的注意力层,对所述合并向量的声学高级特征以及所述合并向量相关的隐层状态,进行注意力计算,得到所述合并向量相关的语义向量。
可选地,所述识别结果确定单元,包括:
置信度获取单元,用于获取所述第一次识别结果的置信度,以及,所述第二次识别结果的置信度;
确定单元,用于从所述第一次识别结果以及所述第二次识别结果中,确定置信度高的识别结果为最终的识别结果。
一种语音识别纠错系统,包括存储器和处理器;
所述存储器,用于存储程序;
所述处理器,用于执行所述程序,实现如上所述的语音识别纠错方法的各个步骤。
一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上所述的语音识别纠错方法的各个步骤。
借由上述技术方案,本申请公开了一种语音识别纠错方法、相关设备及可读存储介质,首先,获取待识别的语音数据及其第一次识别结果;然后,从第一次识别结果中提取关键词,关键词是具有领域特性的专业词汇;并参考第一次识别结果的上下文信息以及关键词,对语音数据进行第二次识别,得到第二次识别结果;最后,根据第二次识别结果,确定最终的识别结果。上述方案中,在参考第一次识别结果的上下文信息以及关键词,对语音数据进行第二次识别,充分考虑了识别结果的上下文信息以及语音数据的适用场景,如果第一次识别结果有误,即可利用第二次识别对其进行纠错,因此,能够提升语音识别准确率。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本申请的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
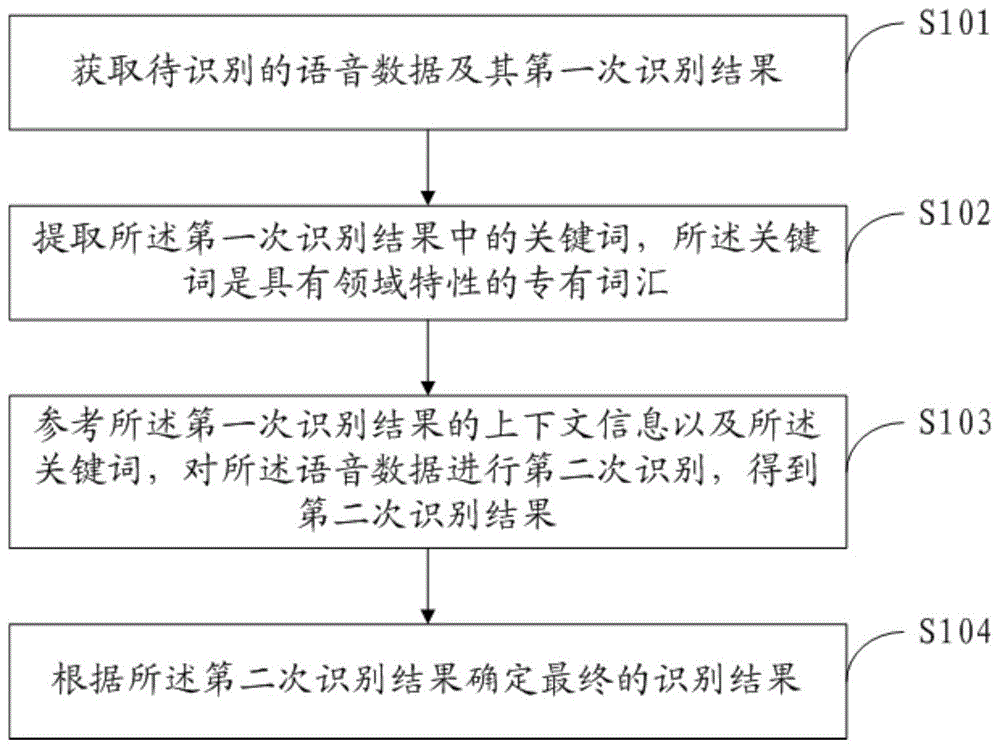
图1为本申请实施例公开的一种语音识别纠错方法的流程示意图;
图2为本申请实施例公开的一种用于训练语音纠错识别模型的预设模型的拓扑结构示意图;
图3为本申请实施例公开的又一种用于训练语音纠错识别模型的预设模型的拓扑结构示意图;
图4为本申请实施例公开的一种语音识别纠错装置结构示意图;
图5为本申请实施例公开的一种语音识别纠错系统的硬件结构框图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为了提升在特殊场景(例如专业领域)下的语音识别准确率,本案发明人进行研究,起初的思路为:
搜集特殊场景下的包含专业词汇的文本作为语料,对传统语音识别模型做针对性优化和定制,采用经过定制和优化后的模型,对该特殊场景下的待识别语音进行识别,能够达到较高的准确率,但是,采用经过定制和优化后的模型,对通用场景下的待识别语音进行识别,准确率相对于传统语音识别模型却有所下降。
为兼顾通用场景下以及特殊场景下的语音识别准确率,在对待识别语音进行识别之前,需要预先确定待识别语音是在通用场景下产生的,还是在特殊场景下产生的,如果确定待识别语音是在通用场景下产生的,则采用传统语音识别模型对其进行识别,如果确定待识别语音是在特殊场景下产生的,则采用经过定制和优化后的模型对其进行识别,这样,才能既保证在通用场景下的语音识别准确率,又能保证在特殊场景下的语音识别准确率。但是,对于实现语音识别的系统来说,在对待识别语音进行识别之前,是无法预先确定待识别语音是在通用场景下产生的,还是在特殊场景下产生的。
鉴于上述思路存在的问题,本案发明人进行了深入研究发现,现有语音识别技术,通常根据语音数据流给出对应的识别结果,一旦给出识别结果后,不会再去修正。但是,实际应用中会有这种情况,对语音数据流中的第一个子句识别时,由于上下文信息不够充分,导致第一个子句识别错误,而对第一个子句后面的子句识别时,由于上下文信息较为充分,则可以对第一个子句后面的子句识别正确。也就是说,同一个词语,可能在第一个子句中出现时识别错误,在第二个子句中出现时识别正确。
示例如:待识别语音内容为“来自加州索克研究所的科学家们发现,自噬反应可以抑制癌症的发生着和过去,许多人的认知恰好相反,因此那些用来抑制自噬反应的疗法可能反而会带来不好的后果。”,被识别成“来自加州索克研究所的科学家们发现,此时反应可以抑制癌症的发生着和过去,许多人的认知恰好相反,因此那些用来抑制自噬反应的疗法可能反而会带来不好的后果。”。
上述示例中,由于自噬反应第一次出现时,上文并没有太多相关内容,而自噬反应又属于较为生僻的专业词汇,导致识别错误,而自噬反应第二次出现时,上文是抑制,抑制自噬反应这个组合语言模型得分较高,因此识别正确。
基于以上研究,本案发明人发现,识别结果本身携带的上下文信息,对识别结果的正确与否有一定的影响。
基于以上,本案发明人提出一种语音识别纠错方法。接下来,通过下述实施例对本申请提供的语音识别纠错方法进行介绍。
请参阅图1,图1为本申请实施例公开的一种语音识别纠错方法的流程示意图,该方法可以包括:
s101:获取待识别的语音数据及其第一次识别结果。
本实施例中,待识别的语音数据为用户根据应用需求说出的语音数据,如用户发短信或聊天时使用语音输入法输入的语音数据。待识别的语音数据可以为通用领域的语音数据,也可以为特殊场景(如专业领域)的语音数据。
本申请中,可以采用多种方式获取待识别语音数据的第一次识别结果。比如,可以基于神经网络模型实现。当然,其他的获取待识别的语音数据的第一次识别结果的方式也在本申请的保护范围之内。示例如,可以预先将待识别的语音数据的第一次识别结果进行存储,当需要时,从存储介质中直接获取即可。
s102:提取所述第一次识别结果中的关键词,所述关键词是具有领域特性的专有词汇。
本实施例中,所述关键词是在第一次识别结果中出现的跟领域相关的词汇,通常是具有领域特性的专业词汇。示例如:医疗领域中的自噬反应、骨牵引、肾活检等词汇;计算机领域中的前馈神经网络、池化层等。
s103:参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果。
本实施例中,参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果的实现方式可以有多种。比如,可基于神经网络模型实现。
当然,其他的实现方式也在本申请的保护范围之内。示例如:可以确定所述第一次识别结果中与所述关键词匹配的词语,并将匹配度低于预设阈值的词语替换为所述关键词,得到第二次识别结果。
s104:根据所述第二次识别结果确定最终的识别结果。
在本申请中,可以直接将所述第二次识别结果确定为最终的识别结果。但是,某些情况下,可能第二次识别结果未必优于第一次识别结果,如果直接将第二次识别结果确定为最终的识别结果,反而会降低识别准确率。因此,这种情况下,可以从第一次识别结果以及第二次识别结果中确定一个最优的识别结果作为最终的识别结果。
从第一次识别结果以及第二次识别结果中确定一个最优的识别结果的方式可以有多种,作为一种可实施方式,可以获取所述第一次识别结果的置信度,以及,所述第二次识别结果的置信度;从所述第一次识别结果以及所述第二次识别结果中,确定置信度高的识别结果为最终的识别结果。
当然,其他方式也在本申请保护范围内,示例如,可以采用人工核查的方式从第一次识别结果以及第二次识别结果中确定一个最优的识别结果。
本实施例中公开了一种语音识别纠错方法,首先,获取待识别的语音数据及其第一次识别结果;然后,从第一次识别结果中提取关键词,关键词是具有领域特性的专业词汇;并参考第一次识别结果的上下文信息以及关键词,对语音数据进行第二次识别,得到第二次识别结果;最后,根据第二次识别结果,确定最终的识别结果。上述方法中,在参考第一次识别结果的上下文信息以及关键词,对语音数据进行第二次识别,充分考虑了识别结果的上下文信息以及语音数据的适用场景,如果第一次识别结果有误,即可利用第二次识别对其进行纠错,因此,能够提升语音识别准确率。
本申请中,当获取待识别的语音数据的第一次识别结果的方式为基于神经网络模型实现时,可以将所述语音数据输入预先训练的语音识别模型,得到第一次识别结果。预先训练的语音识别模型具体可以为传统语音识别模型。也可以为基于识别训练数据集对预设模型进行训练生成的语音识别模型。识别训练数据集中包括至少一组识别训练数据,每组识别训练数据中包括一条语音数据对应的文本,以及,该条语音数据的声学特征。预设模型可以为任意神经网络模型,对此,本申请不进行任何限定。
需要说明的是,当预先训练的语音识别模型为基于识别训练数据集对预设模型进行训练生成的语音识别模型时,识别训练数据集中的每个识别训练数据可以通过以下方式得到:获取一条语音数据,对该语音数据进行人工标注,得到与该语音数据对应的文本;提取该语音数据的声学特征;生成一个识别训练数据,所述识别训练数据中包括语音数据对应的文本以及该语音数据的声学特征。
在本申请中,获取语音数据的方式可以有多种,比如可以通过智能终端的麦克风接收语音数据,所述智能终端为具有语音识别功能的电子设备,如智能手机、电脑、翻译机、机器人、智能家居、智能家电等。也可以获取预先存储的语音数据。当然,获取语音数据的其他方式也在本申请的保护范围之内,对此,本申请不进行任何限定。
在本申请中,每个语音数据的声学特征可以为语音数据的频谱特征,如mfcc(mel-frequencycepstralcoefficients,梅尔频率倒谱系数),或者,fbank特征等。本申请中,可以采用主流的任一声学特征提取方法提取每个语音数据的声学特征,对此,本申请不进行任何限定。
在本申请中,训练语音识别模型时采用的预设模型可以为传统的基于attention的第三编码模块-decoder(基于注意力机制的编码解码)模型结构,也可以为其他模型结构,对此,本申请不进行任何限定。
在本申请中,基于识别训练数据对预设模型进行训练时,是以每个识别训练数据中的语音数据的声学特征作为预设模型的输入,以每个识别训练数据中的语音数据对应的文本为训练目标,对预设模型的参数进行训练的。
在本申请中,可以采用ner(namedentityrecognition,命名实体识别)技术提取第一次识别结果中的关键词。当然,其他的提取第一次识别结果中的关键词的方式也在本申请的保护范围之内。示例如,可以采用人工的方式从第一次识别结果中提取关键词。
目前,ner(namedentityrecognition,命名实体识别)技术可以基于神经网络模型实现。这种情况下,提取第一次识别结果中的关键词的实现方式具体可以如下:将第一次识别结果输入预先训练的关键词提取模型,得到所述第一次识别结果中的关键词。
需要说明的是,关键词提取模型可以基于提取训练数据集对预设模型结构进行训练生成,其中,提取训练数据集中包括至少一组提取训练数据,每组提取训练数据中包括一个文本,该文本中出现的具有领域特性的专业词汇已被标注。每个文本可以为特殊场景下的文本,具体可以采用人工标注的方法将每个文本中出现的具有领域特性的专业词汇打上标签实现标注。
预设模型可以为基于深度学习的bilstm_crf(双向长短时记忆模型_条件随机场)模型等。
示例如,第一次识别结果为“自噬反应可以抑制癌症的发生和过去,许多人的认知正好相反,因此那些用来抑制自噬反应的疗法可能反而会带来不好的后果”,将第一次识别结果输入关键词提取模型之后,关键词提取模型即可输出关键词:自噬反应、癌症、疗法。
另外,ner(namedentityrecognition,命名实体识别)技术,也可以基于统计模型实现。这种情况下,提取第一次识别结果中的关键词的实现方式具体可以如下:将第一次识别结果输入统计模型,得到所述第一次识别结果中的关键词。统计模型的构建方式为目前成熟技术,对此,本申请不再赘述。
在本申请中,当参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果的实现方式是基于神经网络模型时,可以将所述语音数据的声学特征、所述第一次识别结果以及所述关键词,输入预先训练的语音纠错识别模型,得到第二次识别结果,所述语音纠错识别模型是利用纠错训练数据集对预设模型进行训练得到的;所述纠错训练数据集中包括至少一组纠错训练数据,每组纠错训练数据包括一条语音数据对应的声学特征、所述一条语音数据对应的文本、所述一条语音数据对应的第一次识别结果以及所述第一次识别结果中的关键词。
需要说明的是,在训练语音纠错识别模型时,所述一条语音数据对应的声学特征、所述一条语音数据对应的第一次识别结果以及所述第一次识别结果中的关键词为所述预设语音纠错识别模型结构的输入,所述一条语音数据对应的文本为所述预设语音纠错识别模型结构的训练目标。
其中,每组纠错训练数据可以通过以下方式得到:获取一条语音数据。对该语音数据进行人工标注,得到与该语音数据对应的文本。提取该语音数据的声学特征。将该语音数据输入预先训练的语音识别模型,得到该语音数据对应的第一次识别结果,将第一次识别结果输入预先训练的关键词提取模型,得到该第一次识别结果中的关键词。
在本申请中,将所述语音数据的声学特征、所述第一次识别结果以及所述关键词,输入预先训练的语音纠错识别模型,得到第二次识别结果的具体实现方式可以为:利用所述语音纠错识别模型对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,并基于计算结果,得到第二次识别结果。
请参阅图2,图2为本申请实施例公开的一种用于训练语音纠错识别模型的预设模型的拓扑结构示意图,该模型包含三层,分别是编码层、注意力层、解码层。编码层的功能是提取高级特征,注意力层的功能是计算该层的输入与最终输出结果的相关性,解码层的输入为注意力层的输出,解码层的输出为当前时刻的输出结果。解码层的具体形式可以是带有softmax的单层神经网络,本申请中不进行任何限定。
编码层可以进一步划分为三个部分,分别是第一编码模块、第二编码模块、第三编码模块。
第一编码模块、第二编码模块,第三编码模块的具体结构可以是倒金字塔结构的双向rnn(recurrentneuralnetwork,递归神经网络),也可以是cnn(convolutionalneuralnetworks,卷积神经网络),本申请中不进行任何限定。
注意力层也可以进一步划分为三个部分,分别是第一注意力模块,第二注意力模块,第三注意力模块。第一注意力模块,第二注意力模块,第三注意力模块的具体结构可以是双向rnn(recurrentneuralnetwork,递归神经网络),也可以是单向rnn,本申请中不进行任何限定。
解码层的输入为注意力层的输出,解码层的输出为当前时刻的输出结果。decode的具体形式可以是带有softmax的单层神经网络,本申请中不进行任何限定。
第一编码模块的输入是待识别的语音数据对应的声学特征x,输出是声学的高级特征ha,第二编码模块的输入是待识别的语音数据对应的第一次识别结果的表征p,输出是待识别的语音数据的第一次识别结果的表征p的高级特征hw,第三编码模块的输入是待识别的语音数据的第一次识别结果中的关键词的表征q,输出是待识别的语音数据的第一次识别结果中的关键词的表征q的高级特征hr。
上一时刻的输出结果yi-1是第一注意力模块,第二注意力模块,第三注意力模块的一个公共的输入,除此之外,每个部分还有不同的输入和输出,其中,第一注意力模块的输入是ha,输出是语音相关的隐层状态sai和语义向量cai,第二注意力模块的输入是hw,输出是第一次识别结果相关的隐层状态swi和语义向量cwi,第三注意力模块的输入是hr,输出是第一次识别结果中的关键词相关的隐层状态sri和语义向量cri。
解码层的输入为注意力层的输出sai、cai、swi、cwi、sri、cri,解码层的输出为当前时刻的输出结果yi,yi为待识别的语音数据的识别结果。
一般情况下,在训练阶段,p(yi)大于预设阈值时,即可认为训练结束,p(yi)表示当前时刻输出结果是yi的概率,p(yi)=decode(sai,swi,sri,cai,cwi,cri)。
基于上述模型,作为一种可实施方式,在本申请中,利用所述语音纠错识别模型对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,并基于计算结果,得到第二次识别结果的具体实现方式可以为:利用所述语音纠错识别模型的编码层和注意力层,分别对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码和注意力计算,得到所述计算结果;利用所述语音纠错识别模型的解码层,对所述计算结果进行解码,得到第二次识别结果。
其中,利用所述语音纠错识别模型的编码层和注意力层,分别对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,得到所述计算结果的实现方式可以如下:利用所述语音纠错识别模型的编码层,分别对每一目标对象进行编码,得到所述每一目标对象的声学高级特征;利用所述语音纠错识别模型的注意力层,分别对所述每一目标对象相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果,进行注意力计算,得到所述每一目标对象相关的隐层状态;
利用所述语音纠错识别模型的注意力层,分别对所述每一目标对象的声学高级特征以及所述每一目标对象相关的隐层状态,进行注意力计算,得到所述每一目标对象相关的语义向量;
其中,所述目标对象包括所述语音数据的声学特征、所述第一次识别结果以及所述关键词。
具体过程如下:
利用第一编码模块对所述语音数据的声学特征进行编码,得到所述语音数据的声学高级特征;利用第一注意力模块对与所述语音数据相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果进行注意力计算,得到所述与所述语音数据相关的隐层状态;利用第一注意力模块对所述语音数据的声学高级特征以及所述与所述语音数据相关的隐层状态进行注意力计算,得到所述与所述语音数据相关的语义向量。
利用第二编码模块对所述第一次识别结果进行编码,得到所述第一次识别结果的高级特征;利用第二注意力模块对与所述第一次识别结果相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果进行注意力计算,得到所述与所述第一次识别结果相关的隐层状态;利用第二注意力模块对所述第一次识别结果的高级特征以及所述与所述第一次识别结果相关的隐层状态进行注意力计算,得到所述与所述第一次识别结果相关的语义向量。
利用第三编码模块对所述关键词进行编码,得到所述关键词的高级特征;利用第三注意力模块对与所述关键词相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果进行注意力计算,得到所述与所述关键词相关的隐层状态;利用第三注意力模块对所述关键词的高级特征以及所述与所述关键词相关的隐层状态进行注意力计算,得到所述与所述关键词相关的语义向量。
请参阅图3,图3为本申请实施例公开的又一种用于训练语音纠错识别模型的预设模型的拓扑结构示意图,该模型包含三层,分别是编码层、注意力层、解码层。encode层的功能是提取高级特征,注意力层的功能是计算该层的输入与最终输出结果的相关性,解码层的输入为注意力层的输出,解码层的输出为当前时刻的输出结果。decode的具体形式可以是带有softmax的单层神经网络,本申请中不进行任何限定。
编码层的输入是由待识别的语音数据对应的声学特征x、待识别的语音数据对应的第一次识别结果的表征p以及待识别的语音数据的第一次识别结果中的关键词的表征q组成的合并向量[x,p,q]。编码层的输出是由声学特征的高级特征ha、待识别的语音数据的第一次识别结果的表征p的高级特征hw以及待识别的语音数据的第一次识别结果中的关键词的表征q的高级特征hr组成的合并向量[ha,hw,hr]。
编码层的输出以及模型上一时刻的输出结果yi-1是注意力层的输入,注意力层的输出是由语音相关的隐层状态sai和语义向量cai、第一次识别结果相关的隐层状态swi和语义向量cwi、第一次识别结果中的关键词相关的隐层状态sri和语义向量cri组成的向量[sai,cai,swi,cwi,sri,cri]。
解码层的输入为注意力层的输出,解码层的输出为当前时刻的输出结果yi,yi为待识别的语音数据的识别结果。
基于上述模型,作为一种可实施方式,在本申请中,利用所述语音纠错识别模型对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,并基于计算结果,得到第二次识别结果的具体实现方式可以为:对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行合并,得到合并向量;利用所述语音纠错识别模型的编码层和注意力层,对所述合并向量进行编码以及注意力计算,得到所述计算结果;利用所述语音纠错识别模型的解码层,对所述计算结果进行解码,得到第二次识别结果。
其中,利用所述语音纠错识别模型的编码层和注意力层,对所述合并向量进行编码以及注意力计算,得到所述计算结果的实现方式可以如下:
利用所述语音纠错识别模型的编码层,对所述合并向量进行编码,得到所述合并向量的声学高级特征;
利用所述语音纠错识别模型的注意力层,对所述合并向量相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果,进行注意力计算,得到所述合并向量相关的隐层状态;
利用所述语音纠错识别模型的注意力层,对所述合并向量的声学高级特征以及所述合并向量相关的隐层状态,进行注意力计算,得到所述合并向量相关的语义向量。
需要说明的是,传统语音识别模型,注意力层的主要关注点是传统语音识别模型的输出结果和语音数据的声学特征的相关性,本申请语音纠错识别模型中将语音数据的第一次识别结果和第一次识别结果中的关键词融入注意力层,使得语音纠错识别模型的输出结果可以关注到识别结果的纠错信息和识别结果的上下文信息。之所以这么做是希望语音纠错识别模型可以学习到输出结果与上下文信息相关的注意力机制、以及,输出结果与纠错相关的注意力机制,通过上述两个注意力机制找到当前语音数据需要关注的上下文信息和纠错信息,即根据输入语音数据能够自动选择是否需要关注第一次识别结果和第一次识别结果中的关键词信息,也就是相当于语音纠错识别模型具有了根据第一次识别结果和第一次识别结果中的关键词自动纠正错误的能力。
另外,本申请还给出了一种生成识别训练数据集以及纠错训练数据集的实现方式,具体如下:
收集用于训练语音识别模型以及语音纠错识别模型的语音数据,这部分语音数据可以通过智能终端的麦克风接收到,智能终端为具有语音识别功能的电子设备,如智能手机、电脑、翻译机、机器人、智能家居(家电)等。再由人工标注每条语音数据,即将每条语音数据通过人工转写成对应的文本数据。再提取每条语音数据的声学特征,所述声学特征一般为语音数据的频谱特征,如mfcc或者fbank等特征,该声学特征的具体获取方法为现有方法,这里不再赘余介绍。最终,得到语音数据的声学特征以及语音数据对应的人工标注文本。
将上述步骤得到的语音数据的声学特征以及语音数据对应的人工标注文本分为两部分,在本申请中,第一部分用a集表示,第二部分用b集表示。示例如,上述步骤得到的语音数据的声学特征以及语音数据对应的人工标注文本共有100万组,随机将这100万组分成等量的两个集合,分别为a集和b集。a集和b集中均包括多组训练数据,每组训练数据包括一条语音数据对应的声学特征以及该语音数据对应的人工标注文本。
使用a集作为识别训练数据集,训练得到语音识别模型。
将b集输入训练好的语音识别模型,得到b集对应的识别结果,再将b集对应的识别结果输入关键词提取模型,得到b集对应的识别结果中的关键词;b集对应的声学特征、人工标注文本、识别结果以及关键词组成c集,c集中包括多组训练数据,每组训练数据包括一条语音数据对应的声学特征、该语音数据对应的人工标注文本、该语音数据对应的识别结果以及该识别结果中的关键词。
使用c集作为纠错训练数据集,训练得到为语音纠错识别模型。
进一步需要说明的是,还可以将b集输入训练好的语音识别模型,得到b集对应的nbest的识别结果,再将每个识别结果输入关键词提取模型,得到每个识别结果中的关键词。如果b集数据有n条语音数据,每条语音均有nbest识别结果,最终能获取到n*n组训练数据。这样处理,能够使纠错训练数据集更为丰富,提升语音纠错识别模型的覆盖度。
下面对本申请实施例公开的语音识别纠错装置进行描述,下文描述的语音识别纠错装置与上文描述的语音识别纠错方法可相互对应参照。
参照图4,图4为本申请实施例公开的一种语音识别纠错装置结构示意图。如图4所示,该语音识别纠错装置可以包括:
获取单元41,用于获取待识别的语音数据及其第一次识别结果;
关键词提取单元42,用于从所述第一次识别结果中提取关键词,所述关键词是具有领域特性的专业词汇;
语音识别单元43,用于参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果;
识别结果确定单元44,用于根据所述第二次识别结果,确定最终的识别结果。
可选地,所述语音识别单元,包括:
声学特征获取单元,用于获取所述语音数据的声学特征;
模型处理单元,用于将所述语音数据的声学特征、所述第一次识别结果以及所述关键词,输入预先训练的语音纠错识别模型,得到第二次识别结果,所述语音纠错识别模型是利用纠错训练数据集对预设模型进行训练得到的;
其中,所述纠错训练数据集中包括至少一组纠错训练数据,每组纠错训练数据包括一条语音数据对应的声学特征、所述一条语音数据对应的文本、所述一条语音数据对应的第一次识别结果以及所述第一次识别结果中的关键词。
可选地,模型处理单元,包括:
编码及注意力计算单元,用于利用所述语音纠错识别模型对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算;
识别单元,用于基于计算结果,得到第二次识别结果。
可选地,所述编码以及注意力计算单元包括第一编码以及注意力计算单元,所述识别单元包括第一解码单元;
所述第一编码以及注意力计算单元,用于利用所述语音纠错识别模型的编码层和注意力层,分别对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行编码以及注意力计算,得到所述计算结果;
所述第一解码单元,用于利用所述语音纠错识别模型的解码层,对所述计算结果进行解码,得到第二次识别结果。
可选地,所述模型处理单元还包括合并单元,所述编码以及注意力计算单元包括第二编码以及注意力计算单元,所述识别单元包括第二解码单元:
所述合并单元,用于对所述语音数据的声学特征、所述第一次识别结果以及所述关键词进行合并,得到合并向量;
所述第二编码以及注意力计算单元,用于利用所述语音纠错识别模型的编码层和注意力层,对所述合并向量进行编码以及注意力计算,得到所述计算结果;
所述第二解码单元,用于利用所述语音纠错识别模型的解码层,对所述计算结果进行解码,得到第二次识别结果。
可选地,所述第一编码以及注意力计算单元,包括:
第一编码单元,用于利用所述语音纠错识别模型的编码层,分别对每一目标对象进行编码,得到所述每一目标对象的声学高级特征;
第一注意力计算单元,用于利用所述语音纠错识别模型的注意力层,分别对所述每一目标对象相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果,进行注意力计算,得到所述每一目标对象相关的隐层状态;以及,利用所述语音纠错识别模型的注意力层,分别对所述每一目标对象的声学高级特征以及所述每一目标对象相关的隐层状态,进行注意力计算,得到所述每一目标对象相关的语义向量;其中,所述目标对象包括所述语音数据的声学特征、所述第一次识别结果以及所述关键词。
可选地,所述第二编码以及注意力计算单元,包括:
第二编码单元,用于利用所述语音纠错识别模型的编码层,对所述合并向量进行编码,得到所述合并向量的声学高级特征;
第二注意力计算单元,用于利用所述语音纠错识别模型的注意力层,对所述合并向量相关的上一时刻的语义向量以及所述语音纠错识别模型上一时刻的输出结果,进行注意力计算,得到所述合并向量相关的隐层状态;以及,利用所述语音纠错识别模型的注意力层,对所述合并向量的声学高级特征以及所述合并向量相关的隐层状态,进行注意力计算,得到所述合并向量相关的语义向量。
可选地,所述识别结果确定单元,包括:
置信度获取单元,用于获取所述第一次识别结果的置信度,以及,所述第二次识别结果的置信度;
确定单元,用于从所述第一次识别结果以及所述第二次识别结果中,确定置信度高的识别结果为最终的识别结果。
图5示出了语音识别纠错系统的硬件结构框图,参照图5,语音识别纠错系统的硬件结构可以包括:至少一个处理器1,至少一个通信接口2,至少一个存储器3和至少一个通信总线4;
在本申请实施例中,处理器1、通信接口2、存储器3、通信总线4的数量为至少一个,且处理器1、通信接口2、存储器3通过通信总线4完成相互间的通信;
处理器1可能是一个中央处理器cpu,或者是特定集成电路asic(applicationspecificintegratedcircuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;
存储器3可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatilememory)等,例如至少一个磁盘存储器;
其中,存储器存储有程序,处理器可调用存储器存储的程序,所述程序用于:
获取待识别的语音数据及其第一次识别结果;
从所述第一次识别结果中提取关键词,所述关键词是具有领域特性的专业词汇;
参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果;
根据所述第二次识别结果,确定最终的识别结果。
可选的,所述程序的细化功能和扩展功能可参照上文描述。
本申请实施例还提供一种存储介质,该存储介质可存储有适于处理器执行的程序,所述程序用于:
获取待识别的语音数据及其第一次识别结果;
从所述第一次识别结果中提取关键词,所述关键词是具有领域特性的专业词汇;
参考所述第一次识别结果的上下文信息以及所述关键词,对所述语音数据进行第二次识别,得到第二次识别结果;
根据所述第二次识别结果,确定最终的识别结果。
可选的,所述程序的细化功能和扩展功能可参照上文描述。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!