一种基于GAN的说话人语音特征训练方法、装置和设备与流程
本申请涉及语音处理技术领域,尤其涉及一种基于gan的说话人语音特征训练方法、装置和设备。
背景技术:
语音识别是同一说话人鉴定的重要手段,现有的说话人声纹鉴定是获取说话人语音数据,对说话人语音数据进行去噪处理之后,进行语音特征提取,然后通过预设语音识别模型进行语音识别,但是现有的语音识别方式识别准确率不高,因此,进一步提高说话人语音识别的准确率仍是本领域技术人员亟待解决的技术问题。
技术实现要素:
本申请提供了一种基于gan的说话人语音特征训练方法、装置和设备,用于解决现有的语音识别方式识别准确率不高的技术问题。
有鉴于此,本申请第一方面提供了一种基于gan的说话人语音特征训练方法,包括:
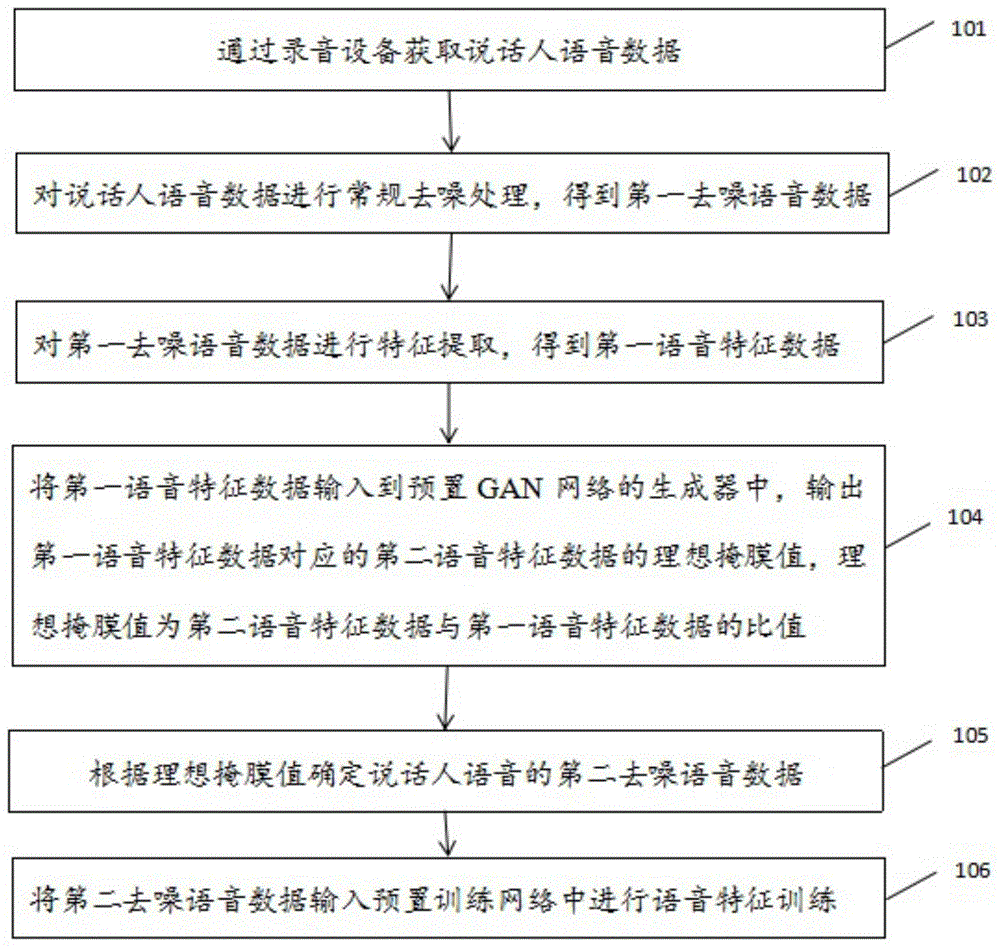
通过录音设备获取说话人语音数据;
对所述说话人语音数据进行常规去噪处理,得到第一去噪语音数据;
对所述第一去噪语音数据进行特征提取,得到第一语音特征数据;
将所述第一语音特征数据输入到预置gan网络的生成器中,输出所述第一语音特征数据对应的第二语音特征数据的理想掩膜值,所述理想掩膜值为所述第二语音特征数据与所述第一语音特征数据的比值;
根据所述理想掩膜值确定所述说话人语音的第二去噪语音数据;
将所述第二去噪语音数据输入预置训练网络中进行语音特征训练。
可选地,所述对所述说话人语音数据进行常规去噪处理,得到第一去噪语音数据,包括:
对所述说话人语音数据进行基于深度循环神经网络的语音去噪处理,得到第一去噪语音数据。
可选地,所述对所述第一去噪语音数据进行特征提取,得到第一语音特征数据,包括:
对所述第一去噪语音数据进行mfcc特征提取,得到第一语音特征数据。
可选地,所述对所述第一去噪语音数据进行特征提取,得到第一语音特征数据之后,所述将所述第一语音特征数据输入到预置gan网络的生成器中,输出所述第一语音特征数据对应的第二语音特征数据的理想掩膜值之前,还包括:
计算所述第一语音特征数据的均方差归一化处理值;
相应地,所述将所述第一语音特征数据输入到预置gan网络的生成器中,输出所述第一语音特征数据对应的第二语音特征数据的理想掩膜值,包括:
将所述第一语音特征数据的均方差归一化处理值输入到预置gan网络的生成器中,输出所述第一语音特征数据对应的第二语音特征数据的理想掩膜值。
可选地,所述将所述第一语音特征数据输入到预置gan网络的生成器中,输出所述第一语音特征数据对应的第二语音特征数据的理想掩膜值,之前还把包括:
对初始gan网络进行训练和测试,直到所述初始gan网络收敛,得到所述预置gan网络。
本申请第二方面提供了一种基于gan的说话人语音特征训练装置,包括:
获取单元,用于通过录音设备获取说话人语音数据;
第一去噪单元,用于对所述说话人语音数据进行常规去噪处理,得到第一去噪语音数据;
特征提取单元,用于对所述第一去噪语音数据进行特征提取,得到第一语音特征数据;
掩膜单元,用于将所述第一语音特征数据输入到预置gan网络的生成器中,输出所述第一语音特征数据对应的第二语音特征数据的理想掩膜值,所述理想掩膜值为所述第二语音特征数据与所述第一语音特征数据的比值;
第二去噪单元,用于根据所述理想掩膜值确定所述说话人语音的第二去噪语音数据;
第一训练单元,用于将所述第二去噪语音数据输入预置训练网络中进行语音特征训练。
可选地,所述特征提取单元具体用于:
对所述第一去噪语音数据进行mfcc特征提取,得到第一语音特征数据。
可选地,还包括:
第二训练单元,用于对初始gan网络进行训练和测试,直到所述初始gan网络收敛,得到所述预置gan网络;
归一化单元,用于计算所述第一语音特征数据的均方差归一化处理值;
相应地,所述掩膜单元具体用于:
将所述第一语音特征数据的均方差归一化处理值输入到预置gan网络的生成器中,输出所述第一语音特征数据对应的第二语音特征数据的理想掩膜值。
本申请第三方面提供了一种基于gan的说话人语音特征训练方法设备,所述设备包括处理器和存储器;
所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
所述处理器用于根据所述程序代码中的指令执行第一方面任一种所述的基于gan的说话人语音特征训练方法。
从以上技术方案可以看出,本申请实施例具有以下优点:
本申请中提供了一种基于gan的说话人语音特征训练方法,包括:通过录音设备获取说话人语音数据;对说话人语音数据进行常规去噪处理,得到第一去噪语音数据;对第一去噪语音数据进行特征提取,得到第一语音特征数据;将第一语音特征数据输入到预置gan网络的生成器中,输出第一语音特征数据对应的第二语音特征数据的理想掩膜值,理想掩膜值为第二语音特征数据与第一语音特征数据的比值;根据理想掩膜值确定说话人语音的第二去噪语音数据;将第二去噪语音数据输入预置训练网络中进行语音特征训练。本申请中在对说话人语音数据进行常规去噪处理之后,对得到的第一去噪语音数据济宁特征提取,再将得到的第一语音特征数据输入到预置gan网络的生成器中,利用掩膜值对语音第一去噪语音数据进行二次去噪,得到第二去噪语音数据,利用第二去噪语音数据进行语音特征训练和识别,有效提高了说话人语音识别的准确率,解决了现有的语音识别方式识别准确率不高的技术问题。
附图说明
图1为本申请实施例中提供的一种基于gan的说话人语音特征训练方法的一个流程示意图;
图2为本申请实施例中提供的一种基于gan的说话人语音特征训练装置的结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为了便于理解,请参阅图1,本申请提供了一种基于gan的说话人语音特征训练方法的一个实施例,包括:
步骤101、通过录音设备获取说话人语音数据。
需要说明的是,本申请实施例中,首先需要获取说话人语音数据,说话人语音数据的获取可以通过录音设备获取,也可以以网络爬虫的方式从网络中已有的说话人语音数据进行获取。
步骤102、对说话人语音数据进行常规去噪处理,得到第一去噪语音数据。
需要说明的是,在获取到说话人语音数据之后,先对说话人语音数据进行常规去噪处理,常规去噪处理方式可以优先选择基于深度循环神经网络的语音去噪处理方式,得到第一去噪语音数据。
步骤103、对第一去噪语音数据进行特征提取,得到第一语音特征数据。
需要说明的是,对第一去噪语音数据进行特征提取可以是mfcc特征提取,也可以是plp特征提取。
步骤104、将第一语音特征数据输入到预置gan网络的生成器中,输出第一语音特征数据对应的第二语音特征数据的理想掩膜值,理想掩膜值为第二语音特征数据与第一语音特征数据的比值。
步骤105、根据理想掩膜值确定说话人语音的第二去噪语音数据。
需要说明的是,在将第一语音特征数据输入到预置gan网络的生成器中之前,需要对初始gan网络进行训练和测试,得到预置gan网络。对于第一语言特征数据,可以计算第一语音特征数据中每个维度元素的均值和方差,并对每个维度的均值和方差分别进行归一化处理,形成第一语音数据的每个维度特征数据的均方差归一化处理值,从而有效保留有价值的语音,抑制噪声。将第一语音特征数据的均方差归一化处理值输入到预置gan网络的生成器中,预置gan网络的生成器根据第一语音特征数据的均方差归一化处理值对第一语音特征数据进行去噪,生成第一语音特征数据对应的第二语音特征数据的理想掩膜值,并输出。由于理想掩膜值为第二语音特征数据与第一语音特征数据的比值,所以根据理想掩膜值和第一语音特征数据计算出第二语音特征数据,再对第二语音特征数据进行特征提取的反变换即可得到第二去噪语音数据。
步骤106、将第二去噪语音数据输入预置训练网络中进行语音特征训练。
需要说明的是,将第二去噪语音数据输入预置训练网络中进行语音特征训练,将训练语音数据用于说话人语音识别,可有效提高说话人识别的准确率。
本申请实施例中提供的基于gan的说话人语音特征训练方法,在对说话人语音数据进行常规去噪处理之后,对得到的第一去噪语音数据济宁特征提取,再将得到的第一语音特征数据输入到预置gan网络的生成器中,利用掩膜值对语音第一去噪语音数据进行二次去噪,得到第二去噪语音数据,利用第二去噪语音数据进行语音特征训练和识别,有效提高了说话人语音识别的准确率,解决了现有的语音识别方式识别准确率不高的技术问题。
为了便于理解,请参阅图2,本申请中提供了一种基于gan的说话人语音特征训练装置的实施例,包括:
获取单元,用于通过录音设备获取说话人语音数据;
第一去噪单元,用于对说话人语音数据进行常规去噪处理,得到第一去噪语音数据;
特征提取单元,用于对第一去噪语音数据进行特征提取,得到第一语音特征数据;
掩膜单元,用于将第一语音特征数据输入到预置gan网络的生成器中,输出第一语音特征数据对应的第二语音特征数据的理想掩膜值,理想掩膜值为第二语音特征数据与所述第一语音特征数据的比值;
第二去噪单元,用于根据理想掩膜值确定说话人语音的第二去噪语音数据;
第一训练单元,用于将第二去噪语音数据输入预置训练网络中进行语音特征训练。
进一步地,第一去噪单元具体用于:
对说话人语音数据进行基于深度循环神经网络的语音去噪处理,得到第一去噪语音数据。
进一步地,特征提取单元具体用于:
对所述第一去噪语音数据进行mfcc特征提取,得到第一语音特征数据。
进一步地,还包括:
第二训练单元,用于对初始gan网络进行训练和测试,直到初始gan网络收敛,得到预置gan网络;
归一化单元,用于计算所述第一语音特征数据的均方差归一化处理值;
相应地,掩膜单元具体用于:
将第一语音特征数据的均方差归一化处理值输入到预置gan网络的生成器中,输出第一语音特征数据对应的第二语音特征数据的理想掩膜值。
本申请中提供了一种基于gan的说话人语音特征训练方法设备的实施例,设备包括处理器以及存储器:
存储器用于存储程序代码,并将程序代码传输给处理器;
处理器用于根据程序代码中的指令执行前述的基于gan的说话人语音特征训练方法实施例中的基于gan的说话人语音特征训练方法。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统和方法,可以通过其它的方式实现。例如,以上所描述的系统实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机系统(可以是个人计算机,服务器,或者网络系统等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(英文全称:read-onlymemory,英文缩写:rom)、随机存取存储器(英文全称:randomaccessmemory,英文缩写:ram)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!