一种与人协作的人工智能机器人及通信方法与流程
本发明涉及一种与人协作的人工智能机器人及通信方法,属于人工智能技术领域。
背景技术:
机器人可代替人去危险的地方执行各种任务,如,在传染病场所,如此可避免人受传染。而现有技术提供的机器人与远程的用户终端进行交互时需要占用大量的无线频谱。
技术实现要素:
为实现所述发明目的,本发明提供一种与人协作的人工智能机器人及通信方法,其大大节省了宝贵的无线频谱资源。
为实现所述发明目的,本发明提供一种与人协作的人工智能机器人,其特征在于,包括语音识别模块、第一编码模块和图像识别模块,所述语音识别模块将接收的语音数据或音频波形生成文本单元串,第一编码模块用于对文本单元串和中的每个文本单元进行编码生成用于控制机器人伺服机构的二进制指令;所述图像识别模块通过卷积神经网络进行图像识别,其通过如下步骤实现,根据输入的图像生成分辨率随着从第1级向第n级而变低的特征图,使用第n级特征图生成第一特征图;检测上述图像中拍摄的关注对象,获取关注对象在所述第一特征图上的位置信息;校正所述位置信息,使得位置信息对应于第二特征图的分辨率,第二特征图是在第n级之前生成的特征图上的包含关注对象图像的区域范围;在所述第一特征图上设置位于由校正后的位置信息表示的位置的关注区域,从所述关注区域中提取与关注对象有关的特征信息。
优选地,语音识别模块至少包括卷积神经网络,变换模块将待发送的语音数据或音频波形生成时间-频率-强度3d谱图;卷积神经网络包括多个卷积层,其根据3d谱图中的时间-频率2d谱图,将语音数据或音频波形分成多个词形成文本单元串。
优选地,语音识别模块被配置为根据语音数据或音频波形的至少一个采样段训练卷积神经网络每个通道的权重。
优选地,人工智能机器人还包括第二编码模块,其对特征信息编码生成待发送的二进制字符串。
优选地,机器人伺服机构每个机械臂通过无轴承电机驱动,所述无轴承电机使用了具有生成转矩和磁支持力两种机能的绕组,通过对应转子转角选择性地使其生成支持力或转矩。
为实现所述发明目的,本发明还提供一种通信方法,其包括利用所述语音识别模块将接收的语音数据或音频波形生成文本单元串,利用第一编码模块对文本单元串中的每个文本单元进行编码生成待发送的第一二进制字符串;利用所述图像识别模块将所摄取的图像生成特征信息,利用第二编码器对特征信息进行编码生成第二二进制字符串,所述图像识别模块使用卷积神经网络进行图像识别,其通过如下步骤实现,根据输入的图像生成分辨率随着从第1级向第n级而变低的特征图,使用第n级特征图生成第一特征图;检测上述图像中拍摄的关注对象,获取关注对象在所述第一特征图上的位置信息;校正所述位置信息,使得位置信息对应于第二特征图的分辨率,第二特征图是在第n级之前生成的特征图上的包含关注对象图像的区域范围;在所述第一特征图上设置位于由校正后的位置信息表示的位置的关注区域,从所述关注区域中提取与关注对象有关的特征信息。
优选地,语音识别模块至少包括卷积神经网络,变换模块将待发送的语音数据或音频波形生成时间-频率-强度3d谱图;卷积神经网络包括多个卷积层,其根据3d谱图中的时间-频率2d谱图,将语音数据或音频波形分成多个词形成文本单元串。
优选地,语音识别模块被配置为根据语音数据或音频波形的至少一个采样段训练卷积神经网络每个通道的权重。
与现有技术相比,本发明提供的与人协作的人工智能机器人及通信方法,由于发信端先将语音分成文本单元,对文本单元进行编码生成待发送的二进制码串,从待发送的图像信息生成关注区域,从修正后的关注区域中提取的与关注对象有关的特征信息,而后对与关注对象有关的特征信息的编码信息,如此,需要发送的码流大大减少,从而降低了语音、视频编码速率,大大节省了宝贵的无线频谱资源。
附图说明
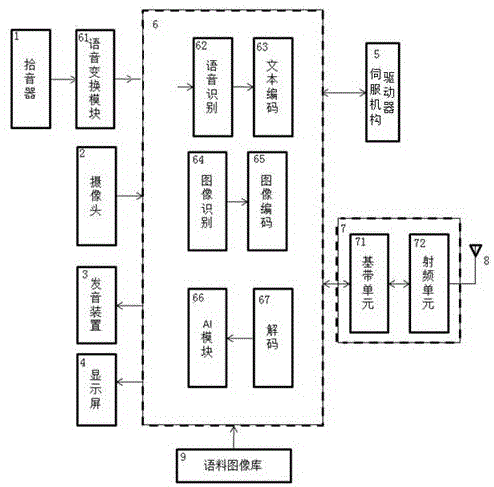
图1是本发明提供的与人协作的人工智能机器人电控系统的组成框图;
图2是本发明提供的时间-频率-强度3d图谱;
图3是本明提供的语音识别模块的组成框图;
图4是本发明提供图像识别模块的工作流程图;
图5是具有关注对象图像范围的第一特征图;
图6是校正了关注对象位置信息的第一特征图。
具体实施方式
下面结合附图详细地说明本发明。
本发明中,单数形式“一”,“一个”,“所述”和“该”包括复数引用,除非上下文另外明确指出。除非另有定义,本文所用的所有技术和科学术语具有与本领域普通技术人员通常理解的相同的含义。本发明中,术语"包括"是指"包括但不限于",除非另有定义。
术语"语音识别模块"、“编码模块”、“解码模块”、“图像识别模块“和"ai模块"中的每一个都指被配置可通过为具有编程功能的集成电路硬件或者软件来实现,集成电路"包含半导体材料(例如硅)上的电子电路,用于执行某些功能。例如,集成电路可以是微处理器,可编程阵列逻辑(pal)器件、专用集成电路(asic)或其它。
图1是本发明提供的与人协作的人工智能机器人电控系统的组成框图,如图1所示,与人协作的人工智能机器人的电控系统包括拾音器1、摄像头2、处理器6、伺服机构驱动器5、通信子系统7、存储器、发音装置3和显示屏4,其中,拾音器1用于将音频信息转换为音频波形电信息,其例如为麦克风。摄像头2为将光信息转换为电图像,其例如可以为红外摄像头。存储器用于存储程序、数据和语料图像数据库9。处理器9调用程序并实现语音识别、文本编码、图像识别、图像编码、解码、语音合成、图像合成的功能。与人协作的人工智能机器人的电控系统还包括语音变换模块61,其用于将拾音器产生的音频波形或从存储器中取出语音数据转换为时间-频率-强度3d图谱语音数据,即语音变换模块61对语音源的时域信号进行分帧、加窗、傅里叶变换、取对数得到3d图谱。语音识别模块62根据3d图谱中的时间-频率2d图谱生成独立的文本单元串,文本编码模块63用于对文本单元串中的每个文本单元进行编码生成非二进制码串,而后将非二进制码串转换成待发送的二进制字符串和用于控制机器人伺服机构驱动器5指令信息。图像识别模块64将所摄取的图像生成关注对象的特征信息。图像编码模块65对关注对象的特征信息进行编码生成待发送二进制字符串或用于控制伺服机构驱动器5的指令信息。解码模块67用于对用户终端发送来的二进制信息进行译码生成图像的特征信息及对应于文本的编码信息,ai模块66根据图像的特征信息和从语料图像库中取出的背景图像信息进行合成生成图像信息并通过显示屏显示图像,还根据编码信息从语料图像库中取出语音信息合成音频信息通过发音装置3发出声音以与现场的人员进行交流;ai模块66还根据语音识别模块62的语音识别结果从语料图像库9中合成回应现场人员的音频信息并通过发音装置3发出声音。
本发明中,机器人伺服机构每个机械臂通过无轴承电机驱动,所述无轴承电机使用了具有生成转矩和磁支持力两种机能的绕组,通过对应转子转角选择性地使其生成支持力或转矩。
与人协作的人工智能机器人的电控系统还包括通信子系统7,其包括基带单元71和射频单元72,基带单元将待发送的二进制字符串进行信道编码,变换为待发送的二进制序列,使待发送的二进制序列的各码元所载荷的平均信息量最大,同时又能保证正确地传递信息,其还将接收的二进制序列进行信道译码转换为用户终端发送的二进制信息并提供给处理器6。所述射频单元72包括用于将基带单元输出的信号调制到高频率上的调制器、用于放大调制器所输出的信号的末级功率放大器、用于对末级功率放大器的输出阻抗与天线8的输入阻抗进行匹配的输出滤波器和用于将经末级功率放大的电信号变成磁信号并发射到空间的天线;射频单元还包括用于将天线8所接收的电信号进行放大的小信号放大器,用于将小信号放大器所放大的信号与本级振荡器所产生的本振信号进行下变频形成中频信号的混频器,用于将中频信号进行模数变换形成数据信号的模数变换器。
根据本发明一个实施例,语音识别模块62至少包括卷积神经网络(cnn),卷积神经网络包括多个卷积层,其根据3d谱图中的时间-频率2d谱图,将待发送的语音数据或音频波形转换成多个词形成文本单元串。
本发明中,发送设备利用语音变换模块61将收到的语音生成时间-频率-强度3d序列。例如,每个时间-频率-强度3d序列可以是谱图。3d谱图可以包括像素(x,y,z)的阵列。
图2是本发明提供的时间-频率-强度3d图谱,如图2所示,x表示音频波形的段中的时间,y表示音频波形的段中的频率,z表示每个像素(x,y)具有表示音频波形的段在时间x和频率y处的音频强度的值。另外,可选地,本发明提供的语音识别模块可以基于时间-频率阵列生成梅尔频率倒谱(mfc),使得时间-频率阵列中的每个像素变为mfc系数(mfcc),即z值。在一些情况下,mfcc阵列可以为数据编码提供均匀分布的功率谱,这可以允许语音别模块提取独立于说话者的特征。每个时间-频率2d阵列可以表示在时间步长处的语音信号的2d谱图。在声音场景中,在语音识别中,时间-频率2d阵列序列中的每个时间步长可以被选择为较小,以捕获语音信号的某些瞬态特性。
本发明在非限制性示例中,在语音应用中,时间-频率2d谱图中时间轴x的时间步长可以相等地间隔,例如10ms或50ms,换句话说,序列中的每个2d谱图可以表示10ms或50ms跨度中的时间-频率阵列。该持续时间表示语音信号的音频波形中的时间周期。时间-频率2d阵列的序列可以被加载到语音识别模块的cnn的第一层。强度轴z中的时间步长可以允许cnn中的第一层能够在小时间窗口中看到更多样本。然而,序列中的每个时间-频率2d阵列可以具有低分辨率,这将允许cnn层包括覆盖音频波形中的较长时间跨度的数据,结果是,可以提高语音识别的精度。因为cnn中的滤波器能够覆盖较长的时间帧,所以它可以捕获语音的一些瞬态特性,例如"音调",短或长的声音等。
本发明中,cnn训练方法可以包括:接收一组样本训练语音数据,其可以包括一个或多个片段音频波形;以及使用该组样本训练语音数据来生成样本3d时间-频率-强度的一个或多个序列。cnn训练过程还可以包括:使用样本3d谱图的一个或多个序列来训练cnn的一个或多个权重,经训练的权重将用于生成语音识别结果。在训练cnn的一个或多个权重时,识别方法可以包括:对于每组样本训练语音数据,接收所述样本训练语音数据所属类别的指示。类的类型和类的数量取决于语音识别任务。例如,被设计成识别语音是来自男性还是女性说话者。语音识别任务可以包括将任何输入数据分配给男性或女性说话者类别的二进制分类器,相应地,训练过程可以包括接收每个训练样本的样本是来自男性还是女性说话者的指示。语音识别任务还可以被设计成基于说话者的语音来验证说话者身份。语音识别任务可以被设计成识别语音输入的内容,例如音节、单词、短语或句子。在这些情况的每一种中,cnn可以包括将每个输入语音数据段分配到多个类别之一中的多类别分类器。
可替换地,在一些场景中,语音识别任务可以包括特征提取,其中语音识别结果可以包括向量,该向量对于给定类别的样本可以是不变的。在cnn中,训练和识别都可以使用类似的方法。例如,该系统可以使用cnn中的任何完全连接层。
本发明的语音识别模块可以采用现有技术中的任一语音识别模块,图3是本明提供的语音识别模块的组成框图,如图3所示,语音识别模块包括卷积神经网络(cnn),其利用时间-频率2d谱图作为输入,通过较多的卷积层和池化层的组合,实现对整个语句的建模以将语音片段分解成文本单元串。
卷积神经网络(cnn)具有五个卷积层、三个池化层、两个全连接层和回归层,第一卷积层21-1使用con3×3的卷积核对2d谱图进行卷积,其具有32个滤波器,输出32个特征,然后使用第一最大池化22-1提取最大参数;第二卷积层22-1使用con3×3的卷积核对第一最大池化层输出的谱图进行卷积,其具有64个滤波器,输出64个特征,然后使用第二最大池化22-2提取最大参数;第三卷积层23-1使用con3×3的卷积核对第二最大池化层输出的谱图进行卷积,其具有128个滤波器,输出128个特征;第四卷积层23-2使用con3×3的卷积核对第三卷积层输出的谱图进行卷积,其具有128个滤波器,输出128个特征;第五卷积层23-3使用con3×3的卷积核对第四卷积层输出的谱图进行卷积,其具有128个滤波器,输出128个特征,然后使用第三最大池化23-4提取最大参数,最后接入依次相连的两个全连接层24-1和24-2,最后进入回归层25回归进行文本单元区分。语音识别模块62可以使用最后一完全连接层来存储特征向量。根据特征向量的大小可以有各种配置。大的特征向量可能导致分类任务的大容量和高精度,而过大的特征向量可能降低执行语音识别任务的效率。
根据本发明一个实施例,人工智能机器人电控系统还包括使用卷积神经网络(cnn)的图像识别模块,图像识别模块使用摄像头输入的图像帧作为图像im,检测在图像im中示出的关注对像,并且估计检测到的关注对像位置,根据关注对像的位置生成特征信息。
图4是本发明提供图像识别模块的工作流程图,如图4所示,所述识别模块至少包括使用卷积神经网络的图像识别模块,所述图像识别模块至少包括:生成单元、获取单元、校正单元和提取单元,其中,生成单元根据输入的图像生成分辨率随着从第1级向第n级而变低的特征图,使用第n级特征图生成第一特征图;获取单元,检测上述图像中拍摄的关注对象,获取关注对象在所述第一特征图上的位置信息;校正单元,其校正所述位置信息,使得位置信息对应于第二特征图的分辨率,第二特征图是在第n级之前生成的特征图上的关注对象图像的范围;提取单元,用于在所述第一特征图上设置位于由校正后的位置信息表示的位置的关注区域,从所述关注区域中提取与关注对像相关的特征信息。
例如,生成单元包括输入层51及n级特征提取单元,所述n大于等于2,例如n=5,卷积层52-1和池化层53-1的组成第1级,卷积层52-1对输入层51输入的图像进行卷积生成10个特征图m1-m10,这些特征图的尺寸与图像im的尺寸1024像素×1024像素相同,池化层53-1分别对10个特征图进行池化生成1o个特征图m11-m20,这些特征图的尺寸比特征图m1-m10要小,为512像素×512像素;卷积层52-2和池化层53-2的组成第2级,卷积层52-2分别对10个特征图m11-m20进行卷积处理,生成10个特征图m21-m30,尺寸为512像素×512像素,池化层53-2分别对10个特征图m21-m30进行池化生成1o个的特征图m31-m40,尺寸为256像素×256像素;卷积层52-3和池化层53-3的组成第3级,卷积层52-3分别对10个特征图m31-m40进行卷积处理,生成10个特征图m41-m50,尺寸为256像素×256像素,池化层53-3分别对10个特征图m41-m50进行池化生成1o个特征图m51-m60,尺寸为128像素×128像素;卷积层52-4和池化层53-4的组成第4级,卷积层52-4分别对10个特征图m51-m60进行卷积处理,生成10个特征图m61-m70,尺寸为128像素×128像素,池化层53-4分别对10个特征图m61-m70进行池化生成10特征图为m71-m80,尺寸为64像素×64像素;卷积层52-5和池化层53-5的组成第5级,卷积层52-5分别对10个特征图m71-m80进行卷积处理,生成10个特征图m81-m90,尺寸为64像素×64像素,池化层53-5分别对10个特征图m81-m90进行池化生成10个特征图m91-m100,尺寸为32像素×32像素。在可选的实施例中,可不具有池化层53。随着从第1级到第5级,特征图m的分辨率变低,如果特征图m的纵向尺寸和横向尺寸变为一半,则范围s的纵向尺寸和横向尺寸变为一半。
rpn层54根据特征图m91-m100的特征,检测出的关注对象及其位置信息p。rpn层54具有获取单元的功能,使用在多级中的最后一级生成的第一特征图,检测上述图像im中拍摄的人物ob,获取人物在所述第一特征图上的位置信息p。在实施方例中,第一特征图是特征图m91-m100。
参照图4,选择单元59从除了在最后级获得的第一特征图之外的级获得第二特征图。更具体地,第二特征图是在位于第5级之前的级中生成的特征图m上的关注对象图像范围s。选择单元59通过切换开关,由第1级的池化层53-1得到的特征图m11-m20上的关注对象图像范围s(48像素×48像素),第2级的池化层53-2得到的特征图m31-m40上的关注对像图像范围s(24像素×24像素),第3级的池化层53-3得到的特征图m51-m60的关注对象图像范围s(12像素×12像素),以及第4级的池化层53-4得到的特征图m71-m80上的关注图像范围s(6像素×6像素)。
例如,选择由第3级的池化层53-3得到的特征图m51-m60上的关注图像范围s(12像素×12像素)作为第二特征图,记为关注区域r。如果关注区域r的尺寸过小,则在特征信息f中不包含与位置相关的信息,所以预先决定关注区域r的尺寸的下限值,使得与位置相关的信息包含在特征信息f中。随着从第1级朝向第5级,特征图m的分辨率变低,因此在图像im中拍摄的关注对象的范围s(成为检测对象的范围)也随着从第1级朝向第5级而变小。
参照图5,校正单元58修正rpn层54生成的位置信息p。原因如下:位置信息p为特征图m91-m100上的关注对象图像范围s的位置信息。位置信息p例如设为坐标c1、c2、c3和c4。
在实施方式中,特征图m51-m60的分辨率高于特征图m91-m100。因此,图4所示的校正单元58修正第一特征图上的位置信息p,使其与特征图m51-m60上的人物图像范围(第二特征图)的分辨率对应。m11-m20特征图上关注对象图像范围分辨率为48像素×48像素;m31-m40特征图上关注对象图像范围s的分辨率为24像素×24像素;m51-m60特征图上关注对象图像范围s的分辨率为12像素×12像素;m71-m80特征图上关注对象图像范围s的分辨率为6像素×6像素;m91-m100特征图像上关注图像范围的分辨率为3像素×3像素。
校正单元58对第一特征图上的位置信息p进行校正,使得由位置信息p表示的关注区域r的面积扩大到4倍,如图6所示。具体而言,修正单元58将坐标c1修正为坐标c5,将坐标c2修正为坐标c6,将坐标c3修正为坐标c7,将坐标c4修正为坐标c8。由坐标c5、c6、c7和c8确定位置的关注区域r以由坐标c1、c2、c3和c4所形成的位置区域为中心。
校正单元58将修正了位置信息p的第一特征图向roi池化层55输送。roi池化层55作为提取单元发挥功能,从所述关注区域r中提取与关注对象的特征信息f。
roi池化层55通过对关注区域r分别进行池化,来表示与关注对象相关的特征信息f1-f10,通过池化处理被整形为全部相同的尺寸,如都是4像素×4像素。
进一步详细说明以上说明的roi池化。如上所述,roi池化是提取关注区域r,将其作为固定尺寸(例如4像素×4像素)的特征图的处理,该特征图m成为特征信息f。例如,在关注区域r的尺寸为12像素×12像素,将其设为4像素×4像素的特征图(特征信息f)的情况下,roi池化层55将12像素×12像素的关注区域r分割为3×3的网格。在关注区域r的尺寸不能被网格的尺寸整除的情况下,也进行同样的处理。
参照图4,roi池化层55将特征信息f1-f10送往全结合层56。全结合层56对特征信息f1-f10进行回归分析,生成回归结果rr,而后送往输出层57。输出层57将回归结果rr送往图1所示的图像编码模块65。
本发明中,第二特征图的分辨率比第一特征图上的关注对象范围s的分辨率高。因此,从设定在第二特征图上的关注区域r中抽出的特征信息f,与从设定在第一特征图上的关注对象图像范围s中抽出特征信息f相比,包含更多的与位置相关的信息。因此,如果使用从设定在第一特征图中的关注区域r中提取出的特征信息f,则能够估计现场人员的每个部位精确位置信息。
本发明中,由于机器人给远程用户终端传送的是文本编码信息和关注区域中提取的与关注对象有关的特征信息的编码信息,因此需要传送的二进制码流大大减小,从而节省了无线频谱资源。
容易理解的是,本发明在说明书和附图的总体描述总体解决方案可以被设计成多种不同的结构。因此,如说明书和附图中所表示的各种实现方式更详细的描述并非旨在限制本公开的范围,而仅表示各种示例性的实现方式。虽然在附图中示出了本解决方案的各个方面,但是除非特别指出,否则附图不必按比例绘制。本发明所描述的实施例在所有方面都被认为仅仅是说明性的而不是限制性的。因此,本发明的保护范围是:由权利要求而不是该说明书的详细描述确定。在权利要求的等同物的含义和范围内的所有改变都包括在其范围内。
- 还没有人留言评论。精彩留言会获得点赞!